 In
questo nummero di MokaByte inizia una serie di articoli che trattano della
programmazione multithread. Inizialmente questi articoli dovevano essere
pubblicati esclusivamente nella rubrica step-to-step e quindi erano stati
concepiti con un taglio strettamente pratico nella seppur breve tradizione
di tale rubrica. In
questo nummero di MokaByte inizia una serie di articoli che trattano della
programmazione multithread. Inizialmente questi articoli dovevano essere
pubblicati esclusivamente nella rubrica step-to-step e quindi erano stati
concepiti con un taglio strettamente pratico nella seppur breve tradizione
di tale rubrica.
Ci siamo resi
conto invece che tale argomento è abbastanza corposo e che fra le
novità introdotte con il linguaggio Java molte di queste sono legate
al concetto di programmazione distribuita e quindi anche alla multiprogrammazione.
Ci è sembrato quindi troppo riduttivo far partire questa nuova miniserie
subito con un approccio pratico senza prma affrontare nessun aspetto teorico
del problema.
Per questo motivo
ho scritto questa introduzione teorica ai threads e alle problematiche
ad essi legate: cercherò quindi di esporre le caratteristiche teoriche
generali della multiprogrammazione e degli aspetti specifici di quello
che si può fare con Java. Questo articolo ha lo scopo di preparare
il terreno per i neofiti di Java, in modo che possano seguire facilmente
il minicorso pratico di Bertoncello.
Per
iniziare ad affrontare un argmento così vasto e delicato, ho pensato
di partire un pò da lontano, cioé dai concetti basilari di
programmazione parallela per poi affrontare le specifiche del linguaggio
Java. Per capire completamente cosa sia un thread è bene iniziare
da quello che potrebbe essere il padre del multithrading, cioé il
multitasking. Molti di voi sicuramente conoscono approfonditamente tale
caratteristica che ormai quasi tutti i sistemi operativi esistenti implementano.
Potremmo dire
che il multitasking permette di eseguire su una macchina non parallela
più processi contemporaneamente in modo del tutto indipendente l'uno
dall'altro.
Questa affermazione
necessita di alcune precisazioni. Prima di tutto cosa si intende per macchina
non parallela: chi ha letto qualcosa sulla teoria fondamentale della computazione
saprà che le macchine comunemente usate (RISC CISC e simili) sono
basate sul modello della macchina di Von Neumann: tale architettura prevede
che in ogni istante (ciclo di clock) sia possibile eseguire una e soltanto
una operazione. Anche se di recente sono state progettate CPU con sistemi
più o meno complessi per simulare una qualche parallelismo (pipeline
singole e multiple, specializzazione di operazioni, architetture superscalari
etc..) si tratta sempre di configurazioni che non si discostano molto da
quella ideata dal noto scienziato tedesco.
Quindi dicendo
che il multitaking permette di far eseguire in parallelo più operazioni
si commette sicuramente un errore in quanto neanche il sistema operativo
più potente del mondo potrà far eseguire in perfetta sincronia
due o più operazioni su una macchina che in ogni istante ne può
eseguire solo una. Il multitasking quindi simula un comportamento parallelo
facendo eseguire dalla CPU, a rotazione, i vari processi per brevi frazioni
di tempo in modo che in generale si abbia l'impressione che tutti stiano
procedendo in parallelo.
I meccanismi
che permettono questo ciclo sono abbastanza complicati in quanto l'algoritmo
gestore del multitasking deve stabilire quanto tempo far eseguire un singolo
processo ed inoltre deve stabilire come quando e perché eseguire
un cambio di programma in esecuzione.
Senza innoltrarsi
troppo nei meandri di questa teoria esporrò brevemente un esempio
di politica di gestione del traffico dentro la CPU.
In genere per
svolgere questo compito il processore viene dato ad un singolo processo
per un quanto di tempo, ed, a rotazione, tutti i processi possono disporre
di questa risorsa: si effettua cioé il cosidetto round robin.
Il fattore più
difficile è stabilire come e perché eseguire un cambio di
processo in esecuzione. Esistono molte possibilità ed ognuna ha
come logico i propri vantaggi e difetti. In genere i sistemi operativi
più evoluti attuano una politica mista delle varie soluzioni. Vediamo
quali sono i fattori che entrano in gioco.
Attesa
di risorse non disponibili: è la casistica più semplice da
risolvere e comporta che ogni qualvolta che un certo processo si trovi
in fase di attesa di una risorsa non disponibile, esso venga subito messo
a riposo e lasci libera la CPU per quei processi che invece sono pronti
per essere eseguiti.
Conflitto
di priorità: spesso ai processi viene assegnata un valore di priorità
in base alla importanza che essi ricoprono nel sistema. Per la nostra trattazione
non ci preoccupiamo di come viene decisa l'importanza di un processo, ma
semplicemente si osserva, che fra due processi pronti per essere eseguiti,
viene in genere scelto quello più importante, cioé quello
a priorità più alta.
In alcuni casi
viene applicato il diritto di prelazione più noto come preemptive
multitasking: in tal caso è possibile interrompere un processo
in fase di run se si viene a trovare un processo in attesa la cui priorità
sia più alta.
Infine
in genere un processo ha a disposizione sempre un periodo di tempo massimo
di occupazione continuativa della CPU, trascorso il quale esso viene messo
a riposo per far spazio a processi più giovani. Il meccanismo del
conteggio del tempo di elaborazione può essere utilizzato in accoppiata
o subordinato al metodo delle priorità.
In
definitiva il multitasking è un modo di gestire i processi in macchina,
che permette di aumentare le potenzialità del sistema sfruttando
tra le altre cose i tempi morti che si creano.
Il
passo successivo per poter arrivare a parlare di thread consiste nel riconsiderare
la definizione vista precedentemente per affrontare il concetto di processo.
Come molti di
voi sicuramente sapranno, esso è definibile come una entità
atomica costituita da codice eseguibile e dall'insieme di variabili di
sistema, variabili di esecuzione, e specifiche tecniche che permettono
di eseguire il processo stesso. Quando un processo prende vita per
esso viene creato un ambiente di esecuzione: a tal punto il processo segue
il suo corso di vita eseguendo le operazioni che deve svolgere: è
importante tenere presente che in un sistema multitasking ogni processo
possiede un ambiente proprio e separato da ogni altro.
A
fronte dei numerosi vantaggi e potenzialità di un sistema a processi
uno degli inconvenienti maggiori è che il parallelismo (fittizio)
a tal punto viene gestito operando sui singoli processi che sono visti
come enitità indivisibili e non ulteriormente parallelizabili: è
impossibile ad esempio che uno di essi esegua due operazioni parallele
se non dando vita a due processi figli indipendenti fra loro. Inoltre
i processi figli di un unico genitore non sono in grado di condividere
variabili o scambiare informazioni se non tramite complicati meccanismi
di colloquio, per cui complessivamente si rende abbastanza difficile gestire
una struttura del genere.
Thread
Un Thread è per definizione
un pezzo di programma in cui le operazioni vengono svolte secondo la modalità
procedurale classica: il grande vantaggio adesso risiede nel fatto che
un processo può essere suddiviso in più thread i quali seguono
la stessa logica del parallelismo fittizio dei processi in un sistema operativo
multithread. Si ottiene quindi che un singolo processo può dar vita
a sotto sezioni parallele che possono facilmente colloquiare fra loro in
quanto condividono le stesse aree di memoria.
Per
far si che una classe sia threadizzata è sufficiente che
essa possieda al suo interno una o più classi derivate dalla classe
Thread oppure che implementi l'interfaccia Runnable.
Per attivare
i thread contenuti nella nostra classe è sufficiente lanciare i
metodi run() che saranno riscritti col codice che vogliamo sia eseguito
in parallelo.
Senza
dilungarci oltre vediamo subito come la JVM gestisce il ciclo della vita
dei vari thread in esecuzione.(si osservi la Fig. 1)
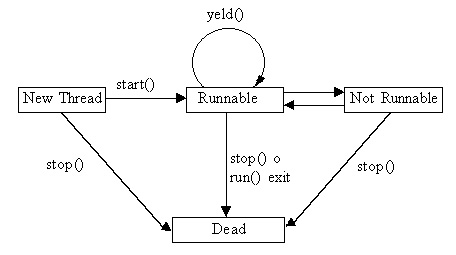
Fig 1
si
parte dalla costruzione di un oggetto thread: in tale stato l'oggetto istaziato
da luogo ad una specie di fantasma in quanto il thread non è ancora
in fase di esecuzione e nessuna risorsa è stata riservata per lui.
Da questa fase solo dopo l'invocazione del metodo start() si ha
un effettivo passaggio di stato: tale metodo riserva le risorse necessarie
per il thread affinché possa essere eseguito correttamente.
Runnable:
quando il thread
diviene Runnable allora significa che è pronto per essere
eseguito. Si noti la scelta della definzione di Runnable al posto
di Running: infatti non è detto che il thread inizi immediatamente
a lavorare sulla CPU, poiché il run time della JVM deve tener conto
di tutti thread che sono nello stesso stato e concorrono per il processore.
Si veda più avanti come lo scheduler gestisce tutti i thread concorrenti.
Not
Runnable:
un thread finisce in questo stato
per varie cause:
viene
esplicitamente sospeso attraverso l'invocazione del metodo suspend()
viene
esplicitamente messo a riposo per un periodo prefissato attraverso l'invocazione
del metodo sleep()
il
thread stesso si mette in attesa attraverso l'invocazione del metodo wait()
di una qualche condizione di sistema.
il
thread finisce in attesa di una risorsa di I/O non immediatamente disponibile.
La cosa importante
da notare è che per ogni entrata nello stato di Not Runnable
esiste una corrispondente uscita, e solo il verificarsi di tale evento
può far ripartire il thread (es. se si invoca il metodo wait(milliseconds)
finché non trascorrono i millisecondi in questione non si può
-neanche forzatamente- far ripartire il thread).
Infine
la condizione di fine thread corrispondente allo stato Dead: in
tale fase finale le risorse allocate vengono rilasciate e tutto viene ristabilito.
Dead
è lo stato finale del thread
in cui esso cessa di esistere: prima che esso scompaia definitivamente
dal sistema, si crea una fase intermedia detta zombie durante la
quale il thread continua ad essere attivo per rilasciare le risorse allocate
per la sua esecuzione. Un thread termina la sua vita o perché termina
naturalmente la sua esecuzione, o perché viene invocato il metodo
stop(): tale chiamata causa una cessazione immediata ed a volta
troppo brusca del thread, ed in genere è preferibile predisporre
un meccanismo che agisca sullo stato delle variabili del metodo run().
Come
si può notare tale ciclo di vita è del tutto equivalente
a quello di un processo in un sistema multitasking.
Priorità
Come si è accennato precedentemente
i thread vengono fatti eseguire a rotazione sulla CPU come un meccanismo
detto di scheduling: il tipo di scheduling implementato dalla
JVM è semplice e si basa sulla differenza di priorità dei
vari thread.
In Java la priorità é
fissa, nel senso che non é implementato un meccanismo che varia
automaticamente tale valore in funzione della anzianità del
thread stesso.
Si può comunque modificare
manualmente tale valore agendo sul metodo setPriority().
Il valore di priorità varia fra MAX_PRIORITY e MIN_PRIORITY.
In
genere la differenza di priorità fra i vari thread permette un usufrutto
equo della CPU, anche se è bene tener presente che il run time di
Java non effettua la cosidetta politica time-slice, attraverso la
quale è possibile gestire equamente anche thread a pari priorità.
In altre parole la JVM non effettua un cambio di contesto forzando la cessione
della CPU fra thread a pari priorità: si può verificare quindi
che un certo thread monopolizzi il processore non dando spazio ad altri
in attesa.
Per evitare
tale situazione si devono mettere nelle zone critiche dei thread (quelle
che possono dar luogo a monopolizzazioni delle risorse, come ad esempio
cicli molto lunghi o infiniti), delle chiamate al metodo yeld(),
il quale permette ai thread a pari priorità di essere eseguiti.
Se non sono presenti, tale chiamata viene ignorata.
Un programma
che preveda l'uso di questa routine implementa un comportamento leale
(fair in inglese), in quanto non da' luogo a monopolizzazione della periferica
più importante del sistema.
Si tenga presente
che la responsabilità di scrivere programmi onesti ricade
completamente sul programmatore.
Programmazione
Multithread e Sincronizzazione
Uno dei problemi maggiori che
si presentano in applicazioni multithread è che spesso, proprio
a causa della loro natura (pseudo) parallela, si possono verificare incongruenze
in riferimento a risorse condivise.
Per chiarire tale problema si pensi
(in onore della originalità) all'ormai famoso problema del produttore/consumatore:
in tale contesto si immagina che un certo soggetto, persona, applicazione
produca una certa risorsa, ad esempio molto semplicemente un numero intero,
e che tale risorsa venga prodotta in maniera continua ad intervalli non
esattamente regolari di tempo.
Si suppone che esista un equivalente
soggetto che debba leggere tutti i valori prodotti dal consumatore: i due
protagonisti per passarsi questa informazione possono ad esempio utilizzare
una area di memoria condivisa.
Dove è il problema? Semplicemente
nel fatto che se il consumatore deve leggere tutti i valori prodotti una
sola volta, si richiede una certa sincronizzazione fra i due affinché
non si perda un valore prodotto o non venga letto due volte lo stesso.
La sincronizzazione su risorse condivise
è un altro problema famoso nel mondo informatico ed in genere si
presenta in ogni ambito dove siano presenti agenti concorrenti che interagiscono
fra loro, ad esempio in un sistema di gestione di database collocato in
un ambito client-server.
Vediamo
come si può risolvere tale problema. La soluzione più semplice
si compone di due parti: la prima consiste nel predisporre un meccanismo
di sicurezza (spesso detto locking) in modo che nel momento in cui
un soggetto agisce sulla risorsa condivisa (ad esempio una area di memora)
sia impedito a chiunque altro di disturbare e/o di modificare la situazione
finché il primo occupante non abbia finito.
La seconda fase
è implementare un sistema di notificazioni che dia il via libero
ai soggetti in attesa quando l'area di memora si rende di nuovo disponibile.
Per meccanismo
di lock si possono usare varie tecniche: Java utilizza quella dei
monitor. Essi possono essere pensati come scatole costruite intorno
alla risorsa condivisa ed il cui compito è quello di chiudersi tutte
le volte che un certo soggetto ne richiede l'uso eslusivo: quando una variabile
è acquisita, in gergo entra nel monitor, nessun altro soggetto
ha la possibilità di modificare tale risorsa (no write),
ma nemmeno di ricavarne il contenuto (no read).
In Java questo
è reso possibile dichiarando un certo oggetto monitorabile, pre
la precisione lo si fa dichiarando la sezione di codice pericolosa syncronized:
in Java un oggetto ha un monitor associato se almeno una porzione di codice
è dichiarata syncronized.
In linea di principio
niente vieta di dichiarare syncronized pezzi di codice più
piccoli di una funzione membro (ad esempio una singola variabile o un ciclo
for), anche se una tale scelta va contro la filosofia della programmazione
ad oggetti, rendendo difficile inoltre la fase di debug.
E
importante notare che per ogni istanza di una classe che possiede metodi
sincronizzati, il run time crea un monitor separato.
Tutte le volte
che un thread invoca un metodo sincronizzato di un certo oggetto, la JVM
crea un monitor per quell'oggetto, per cui nessun altro thread è
in grado di invocare un qualsiasi metodo sincronizzato dell'oggetto.
Questo finchè
il metodo invocato che blocca non finisce la sua esecuzione. In aggiunta
al meccanismo dei monitor, Java mette a disposizione altri due funzionalità
molto importanti, attraverso i metodi notify() e wait().
La prima permette
di notificare a tutti i thread in attesa che la risorsa si è liberata
ed in genere viene invocata come ultima istruzione in un metodo sincronizzato.
Quale thread venga scelta nel caso ce ne sia più di uno non è
possibile dedurlo in automatico. Il metodo wait() invece obbliga
un cetto thread ad attendere finché non riceve un messaggio di notificazione
che la risorsa si è liberata. L'uso dei due metodi permette di gestire
il traffico in un ambiente multithread dove si possono verificare incompatibilità
fra soggetti concorrenti. E' di fondamentale importanza progettare bene
la gestione del traffico in un ambito multithread, o multiprocessing: infatti
una analisi superficiale può portare da un lato, se c'e' poco controllo,
a gravi incongruenze logiche, mentre con una sbagliata gestione dei soggetti
si possono avere sistuazioni due famose situazioni ben note a chi ha studiato
i sistmei operativi: la prima è detta starvation dove più
soggetti passano lunghi periodi di tempo in attesa improduttiva senza che
effettivamente ce ne sia il bisogno, la seconda, più grave viene
detta deadlock, in cui si ha un graduale blocco del programma e/o
del sistema a causa di attese reciproche fra thread concorrenti.
La responsabilità
di costruire un buona gestione dei soggeti in causa è tutta a carico
del programmatore.
Gruppi
di Thread
Come utima nota sulla programmazione
dei thread in Java vorrei analizzare un altro utile costrutto presente
in Java: i gruppi di thread.
Nel caso in cui la frammentazione
del programma principale dia luogo a un numero elevato di thread può
essere utile raggruppare quelli che sono in qualche modo operativamente
simili, per poterli gestire in modo più semplice.
La procedura da seguire prevede prima
la creazione di un gruppo: l'istruzione per far questo sono molto semplici
ThreadGroup
myThreadGroup = new ThreadGroup("Un Nuovo Gruppo di Thread");
e poi aggiungere
un thread nel seguente modo
Thread
myThread = new Thread(ThreadGroup, "Ecco un Thread da aggiungere");
Ogni volta che si
crea un thread, se non si specifica il gruppo di appartenenza, il run time
di Java aggiunge tale nuovo thread ad un gruppo di default detto anche
di sistema.
Quindi non è
necessario specificare obbligatoriamente un gruppo, anche se spesso questo
può facilitare la gesitone della applicazione principale.
Per gestire
tutte le eventualità la classe Thread implementa i seguenti costruttori.
public Thread(ThreadGroup group, Runnable target)
public Thread(ThreadGroup group, String name)
public Thread(ThreadGroup group, Runnable target, String name)
Nel caso in cui
si voglia ignorare la gestione dei gruppi penserà a tutto il sistema
in maniera del tutto trasparente per il programmatore.
Abbiamo
in questa sede esaminato i concetti fondamentali di thread e programmazione:
per chi si conosce gia' questi argomenti si richiederebbe forse una più
approfondita trattazione, ma in questa sede ho ritenuto opportuno semplicemente
esporre in breve i punti salienti per i neofiti. Adesso dovreste essere
capaci di seguire la serie step-to-step di Bertoncello
A tutti buon
lavoro, multithread....
|


