|
MokaByte
Numero 07 - Aprile 1997
|
|||

|
I parte |
||
|
Rafael Andrés Marín de la Cruz |
|
||
|
MokaByte
Numero 07 - Aprile 1997
|
|||
|
|
I parte |
||
|
Rafael Andrés Marín de la Cruz |
|
||
La funzione dellinterprete è quella di accertare la validità delle espressioni e calcolare il risultato di esse. La verifica delle espressioni viene fatta attraverso le diverse fasi di analisi: lessicale, sintattica e semantica; nel calcolo invece intervengono la generazione e lesecuzione di codice. La distribuzione delle diverse fasi nei tre articoli è la seguente:
![]()
![]()
![]()
![]()
![]()
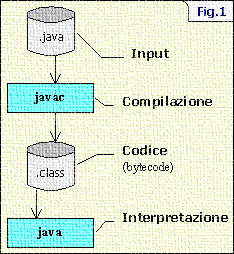 La realizzazione di qualsiasi interprete prevede principalmente due processi
di elaborazione: compilazione e interpretazione.
Nella compilazione si verifica che linput sia conforme alle specifiche
del linguaggio per il quale è stato disegnato, e si genera il codice
che rappresenta questo input. Nel processo di interpretazione viene
eseguito il codice generato in compilazione. Se prendiamo Java come
esempio di interprete, possiamo vedere, nella figura 1, che questi processi
sono ben definiti. La maggioranza degli interpreti seguono questo schema,
solo una minoranza di essi svolgono direttamente le azioni man mano che
analizzano linput. Cè da segnalare che in alcuni interpreti (es.
Java) il codice, prima di venire eseguito, viene verificato contro eventuali
errori o manomissioni.
La realizzazione di qualsiasi interprete prevede principalmente due processi
di elaborazione: compilazione e interpretazione.
Nella compilazione si verifica che linput sia conforme alle specifiche
del linguaggio per il quale è stato disegnato, e si genera il codice
che rappresenta questo input. Nel processo di interpretazione viene
eseguito il codice generato in compilazione. Se prendiamo Java come
esempio di interprete, possiamo vedere, nella figura 1, che questi processi
sono ben definiti. La maggioranza degli interpreti seguono questo schema,
solo una minoranza di essi svolgono direttamente le azioni man mano che
analizzano linput. Cè da segnalare che in alcuni interpreti (es.
Java) il codice, prima di venire eseguito, viene verificato contro eventuali
errori o manomissioni.
Le fasi del processo di compilazione sono le seguenti:
![]()
![]()
![]()
![]()
![]()
In un linguaggio certe combinazioni di caratteri vengono trattate come singole entità. Alcuni esempi di queste possono essere: numeri, identificatori, operatori a più di un carattere come "&&", ecc. Il lavoro di un analizzatore lessicale è quello di estrarre queste singole entità, chiamate tokens, escludendo quei caratteri che non hanno un preciso significato (es. spazi, tabulazioni, ecc.). Le premesse per costruire un analizzatore lessicale sono le seguenti:
Di seguito vengono riportate le definizioni formali di alfabeto e token per queste espressioni.
Alfabeto: [ 0..9 | a..z | A..Z | _ | + | - | * | / | ( | ) | | \t | \r | \n ].Tipi di tokens sopportati:
18 class GenericToken {Allinizio della classe si trovano le costanti che rappresentano i diversi tipi di token. Lidentifcatore EOEci serve per rilevare la fine della espressione. Il metodo toString() ci fornisce una rappresentazione a caratteri del tipo di token, e può essere utilizzato per inserire delle tracce allinterno del programma.19 public static final int SYMBOL = 0;
20 public static final int VARIABLE = 1;
21 public static final int NUMBER = 2;
22 public static final int OPERATOR = 3;
23 public static final int EOE = 4;
25 int tk_type;
26
28 public GenericToken( int _tk_type ) {
29 tk_type = _tk_type;
30 }
32 public int getType() {
33 return tk_type;
34 }
36 public String toString() {
37 String s;
38
39 switch (getType()) {
40 case SYMBOL: s = "SIMBOLO "; break;
41 case VARIABLE: s = "VARIABILE"; break;
42 case NUMBER: s = "NUMERO "; break;
43 case OPERATOR: s = "OPERATORE"; break;
44 case EOE: s = "FINE DI ESPRESSIONE"; break;
45 default: s = "NONE";
46 }
48 return s;
49 }
50 }
Dichiarazione delle classe derivanti da GenericToken.
53 class SymbolToken extends GenericToken {Lunica variabile è un oggetto di tipo StreamTokenizer, il quale ci servirà come analizzatore lessicale primario. Il costruttore della classe riceve un InputStream dal quale verranno letti i caratteri nella classe StreamTokenizer(r.174). Le altre istruzioni servono ad aggiustare alcuni parametri che sono diversi da quelle di default, vediamoli di seguito con più dettaglio.54 char symbol;
55
56 public SymbolToken( char _symbol ) {
57 super(SYMBOL);
58 symbol = _symbol;
59 }
61 public char getSymbol() {
62 return symbol;
63 }
65 public String toString() {
66 return super.toString()+" -> "+"\""+getSymbol()+"\"";
67 }
68 }
71
72 class NumberToken extends GenericToken {
73 double val;
74
75 public NumberToken( double _val ) {
76 super(NUMBER);
77 val = _val;
78 }
80 public double getValue() {
81 return val;
82 }
84 public String toString() {
85 return super.toString()+" -> "+String.valueOf(getValue());
86 }
87 }
89
90 class VariableToken extends GenericToken {
91 String varname;
92
93 public VariableToken( String _varname ) {
94 super(VARIABLE);
95 varname = _varname;
96 }
98 public String getName() {
99 return varname;
100 }
102 public String toString() {
103 return super.toString()+" -> "+getName();
104 }
105 }
107
108 class OperatorToken extends GenericToken {
109 public static final int ADD = 0;
110 public static final int SUB = 1;
111 public static final int MUL = 2;
112 public static final int DIV = 3;
113 public static final int MINUS = 4;
115 int op;
116
117 public OperatorToken( int _op ) {
118 super(OPERATOR);
119 op = _op;
120 }
122 public int getOp() {
123 return op;
124 }
126 public int getArity() {
127 switch (getOp()) {
128 case ADD: return 2;
129 case SUB: return 2;
130 case MUL: return 2;
131 case DIV: return 2;
132 case MINUS: return 1;
133 default: return 0;
134 }
135 }
137 public double doOp( NumberToken left, NumberToken right ) throws ArithmeticException {
138 switch (getOp()) {
139 case ADD: return left.getValue()+right.getValue();
140 case SUB: return left.getValue()-right.getValue();
141 case MUL: return left.getValue()*right.getValue();
142 case DIV:
143 if (right.getValue()==0)
144 throw new ArithmeticException();
145 else
146 return left.getValue()/right.getValue();
147 case MINUS: return -left.getValue();
148 default: return 0;
149 }
150 }
152 public String toString() {
153 String s;
154
155 switch (getOp()) {
156 case ADD : s = "ADD(+)"; break;
157 case SUB : s = "SUB(-)"; break;
158 case MUL : s = "MUL(x)"; break;
159 case DIV : s = "DIV(/)"; break;
160 case MINUS: s = "MINUS(-)"; break;
161 default: s = "NONE"; break;
162 }
164 return super.toString()+" -> "+s;
165 }
166 }
Tutte le classi hanno una rappresentazione a caratteri delle loro proprietà attraverso il metodo toString(). Il metodo OperatorToken.getArity (r.126) fornisce la quantità di argomenti delloperatore. Il metodo OperatorToken.doOp(r.137) realizzerà il calcolo assegnato alloperatore, prendendo come argomenti i valori dei due tokens numerici passati come parametri; nel caso che loperatore sia unitario, il parametro da prendere sarà il primo. E da notare che loperatore MINUSnon ha nessuna rilevanza dal punto di vista lessicale o sintattico, dato che la sua rappresentazione è uguale a SUB; il suo utilizzo sarà necessario nella fase di generazione del codice.Lanalizzatore lessicale è stato implementato in una nuova classe chiamata LexicalAnalizer. La spiegazione di questa classe sarà fatta attraverso i diversi pezzi del suo codice.
169 class LexicalAnalizer {
170 StreamTokenizer st;
172
173 public LexicalAnalizer( InputStream is ) {
174 st = new StreamTokenizer(is);
175 st.lowerCaseMode(true);
176 st.ordinaryChar('/');
177 st.ordinaryChar('+');
178 st.ordinaryChar('-');
179 st.ordinaryChar('*');
180 st.ordinaryChar('.');
181 st.ordinaryChars(124,255);
182 st.wordChars('_','_');
183 st.eolIsSignificant(false);
184 }
185 public GenericToken nextToken()Il metodo StreamTokenizer.nextToken(r.189) ci ritorna il tipo del token appena analizzato. I valori possibili per questo ritorno sono:186 throws IOException, LexicalError {
187 int t;
188
189 t = st.nextToken();
191 switch (t) {
192 case st.TT_EOF: return new GenericToken(GenericToken.EOE);
193 case st.TT_NUMBER: return new NumberToken(st.nval);
194 case st.TT_WORD: return new VariableToken(st.sval);
195 case '+': return new OperatorToken(OperatorToken.ADD);
196 case '-': return new OperatorToken(OperatorToken.SUB);
197 case '*': return new OperatorToken(OperatorToken.MUL);
198 case '/': return new OperatorToken(OperatorToken.DIV);
199 case '(': case ')': return new SymbolToken((char)t);
200 default: throw new LexicalError("Carattere non valido \'"+(char)t+"\' ("+t+").");
201 }
202 }
Oltre allutilizzo
che abbiamo fatto della classe StreamTokenizer, questa ci permette anche
di riconoscere delle stringhe delimitate tra caratteri (es. "Questa è
una stringa"). Per default il carattere delimitante è virgolette
("), ma può essere cambiato con il metodo quoteChar(int carattere).
Quando una stringa viene riconosciuta, nextToken() ritorna il carattere
delimitante e in svalviene depositata la stringa. Di seguito riportiamo
un esempio con le stringhe Pascal (es. apostrofi).
| Standard
Input: questa è una stringa
Inizializzazione: quoteChar(\); Riconoscimento: StreamTokenizer st = new StreamTokenizer(System.in); int t;
t = st.nextToken(); if (t==\)
System.out.println(st.sval);
|
Con i metodi commentChar, slashSlashCommentse slashStarCommentssi può gestire la permissività di commenti allinterno dellinput. Consultare la documentazione dello JDK per un approfondimento di questi metodi.
Lutilizzo della classe LexicalAnalizerverrà esemplificato con lapplet che si trova di fianco. I caratteri di input allanalizzatore devono essere inseriti nella casella di testo sotto "Espressione". Per eseguire lanalisi premere Invionella casella o premere il pulsante "Analisi Lessicale". I token ottenuti ed eventuali messaggi di errore saranno visualizzati nella casella "Risultati". Il sucesso dell'analisi viene notificato con un messaggio nella barra di stato del browser.
Di seguito faremo i commenti ai frammenti più rilevanti dellapplet.
4 public class ex1 extends java.applet.Applet {Nel metodo handleEvent(r.84) vengono catturati gli eventi di pressione del tasto Invioe del pulsante "Analisi Lessicale" per eseguire lanalisi nel metodo doIt (r.61).5 List li;
6 TextField edExpr;
7
8 public void init() {
9 /* Creazione e disposizione dei componenti nell'applet.
10 Il codice non è stato inserito per ragioni di spazio
11 ma i sorgenti completi possono essere scaricati come
12 indicato alla fine dell'articolo. */
40 }
56 void addError( Exception e ) {
57 li.addItem(e.toString());
58 li.select(li.countItems()-1);
59 }
61 void doIt() {
62 LexicalAnalizer la;
63 GenericToken gt;
64 boolean success = false;
65
66 try {
67 la = new LexicalAnalizer(new StringBufferInputStream(edExpr.getText()));
68 li.clear();
69 gt = la.nextToken();
70 while (gt.getType()!=GenericToken.EOE) {
71 li.addItem(gt.toString());
72 gt = la.nextToken();
73 }
74 success = true;
75 }
76 catch (IOException e) getAppletContext().showStatus(e.toString());
77 catch (LexicalError e) addError(e);
78 if (success)
79 getAppletContext().showStatus("Operazione completata con successo");
80 else
81 getAppletContext().showStatus("Operazione interrotta per errore");
82 }
84 public boolean handleEvent(Event evt) {
86 switch (evt.id) {
87 case Event.ACTION_EVENT: {
88 if ("Analisi Lessicale".equals(evt.arg)) doIt();
89 break;
90 }
91 case Event.KEY_PRESS: {
92 if (evt.target instanceof TextField &&
93 evt.key == '\n' ) doIt();
94 break;
95 }
96 }
97 return false;
98 }
99 }
La riga 67 crea una istanza della classe LexicalAnalizer usando come InputStreamil contenuto della casella "Espressione". Nella riga seguente viene pulito il contenuto della casella di elenco "Risultati". Dalla riga 69 alla 73 vengono aggiunti alla casella "Risultati", uno alla volta, tutti i tokens trovati. Se si verifica un errore, questo verrà catturato nelle istruzioni delle righe 76 e 77. La visualizzazione degli errori avviene con laggiunta del testo nella casella "Risultati" (r.57); dopodiché la riga viene selezionata (r.58) per garantire la sua visibilità. Le istruzioni finali del metododoIt(r.78-81) notificano, nella barra di stato, il successo delloperazione.
Come avrete notato, la semplicità e la compattezza di implementazione della classe LexicalAnalizersi deve in grande misura alla classe Java StreamTokenizer, che costituisce un potenziale strumento in compiti di analisi lessicale come quello affrontato nel nostro caso. Nel prossimo articolo potremo vedere lutilizzo, allinterno dellanalizzatore sintattico, della classe LexicalAnalizer.
![]() Download
Download
I sorgenti esposti possono essere scaricati ai seguenti indirizzi:
| Rafael
Andrés Marín de la Cruz
Laureato in Matematica-Cibernetica
allUniversità dellAvana (Cuba) nel 1990, da quattro anni vive
e lavora a Milano. Con la sua società ha sviluppato software per
non vedenti sotto DOS e un tool di installazione per Windows. Svolge inoltre
consulenza, in qualità di progettista, nel campo delle telecomunicazioni.
Può essere contattato tramite la redazione o direttamente all'indirizzo: dialectica.sas@galactica.it |
|
|
||
|
|
||
 |
MokaByte ricerca
nuovi collaboratori
|
 |
|
|
||