|
MokaByte
Numero 09 - Giugno 1997
|
|||

|
II parte |
||
|
Rafael Andrés Marín de la Cruz |
seconda parte |
||
|
MokaByte
Numero 09 - Giugno 1997
|
|||
|
|
II parte |
||
|
Rafael Andrés Marín de la Cruz |
seconda parte |
||
I due passi preliminari da compiere quando si costruisce un analizzatore sintattico sono:
| <Espressione>
::= <Termine> | <Termine> <Operatore> <Espressione>
<Termine> ::= numero | variabile | - <Termine> | ( <Espressione> ) <Operatore> ::= + | * | - | / |
La notazione
utilizzata nella precedente definizione viene chiamata BNF (Backus-Naur
form). I simboli e le parole in grassetto denotano i simboli terminali
(tokens). Le parole tra < e > identificano i non-terminali;
ad ognuno di loro corrisponde una regola grammaticale. La prima è
la regola di partenza della grammatica.
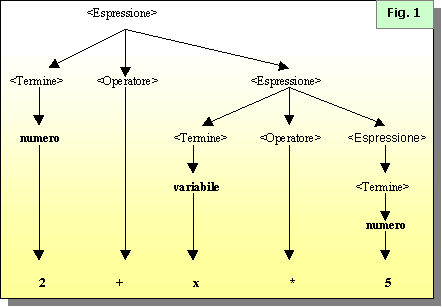
Di seguito è
riportato lalbero sintattico risultante dallapplicazione delle regole
allespressione di esempio 2+x*5.
Nel caso in cui
la regola di partenza non possa essere soddisfatta per tutto linput, si
verifica un errore sintattico. Se assumiamo come esempio lespressione
2+x*+ lalbero sintattico risultante sarebbe il seguente:
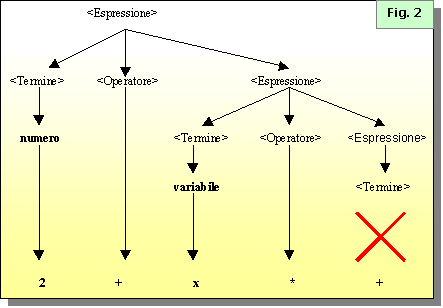
Lerrore in questo
esempio produrrebbe il messaggio"aspetto un termine", o molto più
esplicitamente "aspetto un numero, una variabile, - o (". La
maggioranza degli errori sintattici sono espressi con la formula "aspetto
"+<elenco dei tokens aspettati nella regola irrisolta>.
In questa grammatica,
come si può notare, gli operatori: +-*/ hanno la medesima precedenza.
Per stabilire una gerarchia diprecedenza tra operatori è necessario
creare dei non-terminali intermezzi che spezzino le associazioni tra operatori
e operandi. Nel nostro caso vogliamo dare precedenza agli operatori *,
/ rispetto agli operatori +,- . A tale scopo introdurremo il nuovo non
terminale <Fattore>.
La grammatica
definitiva è la seguente:
| <Espressione>
::= <Termine> | <Termine> <OpAd> <Espressione>
<Termine> ::= <Fattore> | <Fattore> <OpMul> <Termine> <Fattore> ::= numero | variabile | - <Fattore> | ( <Espressione> ) <OpAd> ::= + | - <OpMul> ::= * | / |
Avendo definito in modo coerente la grammatica, passiamo adesso alla scelta dellalgoritmo dellanalizzatore. Ci sono due tipi di analizzatori sintattici a seconda di come gli stessi costruiscono lalbero sintattico.
| void
Espressione() {
Termine(); if (prossimo_simbolo_è_di_addizione_sottrazione()) Espressione(); else rimettere_il_simbolo_nella_coda(); } |
La ricorsività ha dei grandi vantaggi dal punto di vista della logica di programmazione, ma può risultare un metodo molto pesante nellelaborazione. In alcune sintassi, e soprattutto in quelle che rappresentano espressioni, è possibile eliminare alcune ricorsività. Le regole dove è più semplice scoprire ed eliminare ricorsività inutili sono quelle che hanno il seguente schema:
<A> ::= <B> | <B> <T> <A>dove <B> è un qualsiasi non-terminale e <T> contiene soltanto simboli terminali. Nella nostra grammatica esistono due regole che corrispondo allo schema proposto:
<Espressione> ::= <Termine> | <Termine> <OpAd> <Espressione>Leliminazione della ricorsività in questo caso può essere fatta con lanalisi, allinterno della procedura, di unespressione regolare di questo tipo:<Termine> ::= <Fattore> | <Fattore> <OpMul> <Termine>
<A> = <B> [ <T> <B> ]*La conversione delle nostre regole a questa forma sarebbe la seguente:
<Espressione> = <Termine> [ <OpAd> <Termine> ]*e la pseudoprocedura diventerebbe:<Termine> = <Fattore> [ <OpMul> <Fattore> ]*
| void
Espressione() {
Termine(); while(true) { if (prossimo_simbolo_è_di_addizione_sottrazione ()) Termine(); else { rimettere_il_simbolo_nella_coda(); break; } } } |
Con tutti gli elementi che abbiamo possiamo vedere limplementazione in Java della classe SyntaxAnalizer.
19 class SyntaxAnalizer {20 static final String factorErr = "Aspetto un numero, una variabile, \'-\' o \'(\'";
21 LexicalAnalizer la;
22 List li;
23 int indent=0;
24
25 public SyntaxAnalizer( InputStream is, List _li ) {
26 la = new LexicalAnalizer(is);
27 li = _li;
28 }
30 void show(String s) {
31 int i;
32 StringBuffer sb = new StringBuffer(indent);
33
34 for (i=0;i<indent;i++) sb.append(' ');
35
36 li.addItem(sb+s);
37 }
39 public void Parse() throws SyntaxError, LexicalError, IOException {
40 GenericToken gt;
41
42 Expression();
43
44 gt = la.nextToken();
45 if (gt.getType()!=GenericToken.EOE)
46 throw new SyntaxError("Aspetto un operatore.");
47 }
49 void Expression() throws SyntaxError, LexicalError, IOException {
50 GenericToken gt;
51
52 show("<Espressione>");
53 indent++;
54 Term();
55 while (true) {
56 gt = la.nextToken();
57 if (gt.getType()==GenericToken.OPERATOR
58 && (((OperatorToken)gt).getOp()==OperatorToken.SUB ||
59 ((OperatorToken)gt).getOp()==OperatorToken.ADD)) {
60 show(gt.toString());
61 Term();
62 } else {
63 la.pushBack();
64 break;
65 }
66 }
67 indent--;
68 }
70 void Term() throws SyntaxError, LexicalError, IOException {
71 GenericToken gt;
72
73 show("<Termine>");
74 indent++;
75 Factor();
76 while (true) {
77 gt = la.nextToken();
78 if (gt.getType()==GenericToken.OPERATOR
79 && (((OperatorToken)gt).getOp()==OperatorToken.MUL ||
80 ((OperatorToken)gt).getOp()==OperatorToken.DIV)) {
81 show(gt.toString());
82 Factor();
83 } else {
84 la.pushBack();
85 break;
86 }
87 }
88 indent--;
89 }
91 void Factor() throws SyntaxError, LexicalError, IOException {
92 GenericToken gt;
93 OperatorToken ot;
94
95 show("<Fattore>");
96 indent++;
97 gt = la.nextToken();
98 switch (gt.getType()) {
99 case GenericToken.NUMBER:
100 case GenericToken.VARIABLE:
101 show(gt.toString());
102 break;
103 case GenericToken.OPERATOR:
104 if (((OperatorToken)gt).getOp()==OperatorToken.SUB) {
105 ot = new OperatorToken(OperatorToken.MINUS);
106 show(ot.toString());
107 Factor();
108 break;
109 } else
110 throw new SyntaxError(factorErr);
111 case GenericToken.SYMBOL:
112 if (((SymbolToken)gt).getSymbol()=='(') {
113 show(gt.toString());
114 Expression();
115 gt = la.nextToken();
116 if (gt.getType()==GenericToken.SYMBOL
117 && ((SymbolToken)gt).getSymbol()==')') {
118 show(gt.toString());
119 break;
120 } else
121 throw new SyntaxError("Aspetto \')\'");
122 }
123 default:
124 throw new SyntaxError(factorErr);
125 }
126 indent--;
127 }
128
129 }
Il costruttore
SyntaxAnalizer crea unistanza (riga 26) della classe LexicalAnalizer (vedere
[1]) con lInputStream passatole come parametro. Loggetto LexicalAnalizer
nella variabile la ci fornirà i tokens ricavati dallinput scelto
attraverso il metodo nextToken (r. 44, 56, 77, 97, 115). Il parametro li
(r.27) ci servirà per inserire delle traccie in una casella delenco;
questo parametro non ha nessuna rilevanza dal punto di vista dellanalisi
sintattica ed è stato inserito soltanto per scopi dimostrativi.
Il metodo show (r. 30) aggiunge la stringa s nella casella li, inserendole
allinizio indent quantità di spazi.
Lanalisi sintattica
inizia con la chiamata al metodo Parse (r.39) che a sua volta chiama il
non-terminale di partenza Expression (r.42). Per accertare che tutto linput
sia stato analizzato viene verificata la fine dellespressione (r. 44);
un esempio di questa situazione è lespressione x+2y.
I metodi Expression(r.
49) Term (r. 70) e Factor (r. 91) rappresentano rispettivamente i non-terminali
<Espressione>, <Termine> e <Fattore>. Nei metodi Expression e
Term si può osservare leliminazione della ricorsività inutile
della quale abbiamo parlato. Allinterno del metodo Factor (r.104) vediamo
la mutazione delloperatore di sottrazione (token SUB) in operazione di
negazione unitaria (token MINUS) come conseguenza della differenza funzionale
rilevata dallanalisi sintattica.
La rilevazione
di un errore provoca la sollevazione delleccezione SyntaxError (r. 46,
121, 124). Questa eccezione è stata definita come una semplice estensione
di Exception, e ci servirà a distinguere la provenienza degli errori
di compilazione.
Lutilizzo della classe SyntaxAnalizer verrà esemplificato con lapplet che si trova a fianco. Lespressione da analizzare deve essere inserita nella casella di testo sotto "Espressione". Per eseguire lanalisi premere Invio nella casella o premere il pulsante "Analisi Sintattica". I token ottenuti ed eventuali messaggi derrore saranno visualizzati nella casella "Risultati".
Di seguito faremo i commenti ai frammenti più rilevanti dellapplet.
12 public class ex2 extends java.applet.Applet {13 static final String DO_BUTTON = "Analisi Sintattica";
14 List li;
15 TextField edExpr;
16
17 public void init() {
18 /* Creazione e disposizione dei componenti nell'Applet.
19 I sorgenti possono essere scaricati come indicato
20 alla fine dell'articolo */
21 }
62 void addError( Exception e ) {
63 li.addItem(e.toString());
64 li.select(li.countItems()-1);
65 }
67 void doIt() {
68 SyntaxAnalizer ea;
69 boolean success = false;
70
71 try {
72 ea = new SyntaxAnalizer(new StringBufferInputStream(edExpr.getText()),li);
73 li.clear();
74 ea.Parse();
75 success = true;
76 }
77 catch (IOException e) getAppletContext().showStatus(e.toString());
78 catch (LexicalError e) addError(e);
79 catch (SyntaxError e) addError(e);
80 if (success)
81 getAppletContext().showStatus("Operazione completata con successo");
82 else
83 getAppletContext().showStatus("Operazione interrotta per errore");
84 }
86 public boolean handleEvent(Event evt) {
87
88 switch (evt.id) {
89 case Event.ACTION_EVENT: {
90 if (DO_BUTTON.equals(evt.arg)) doIt();
91 break;
92 }
93 case Event.KEY_PRESS: {
94 if (evt.target instanceof TextField &&
95 evt.key == '\n' ) doIt();
96 break;
97 }
98 }
99 return false;
100 }
101 }
Nel metodo
handleEvent (r.84) vengono intercettati gli eventi di pressione del tasto
Invio e del pulsante "Analisi Sintattica " per eseguire lanalisi
nel metodo doIt (r.61).
La riga 72 crea
unistanza della classe SyntaxAnalizer usando come InputStream il contenuto
della casella "Espressione". Nella riga seguente viene pulito il
contenuto della casella delenco "Risultati". Nella riga 74 viene
invocato il metodo Parse per eseguire lanalisi sintattica. Se si verifica
un errore, questo verrà intercettato nelle istruzioni dalla riga
77 alla 79. La visualizzazione degli errori avviene con laggiunta del
testo nella casella "Risultati" (r.63); dopodiché la riga
è selezionata (r.64) per garantire la sua visibilità. Le
istruzioni finali del metodo doIt (r.80-83) notificano, nella barra di
stato, il successo delloperazione.
In questarticolo
abbiamo analizzatomolti elementi che intervengono nella fase di analisi
sintattica, nonché la sua interazione con la fase di analisi lessicale.
Nel prossimo articolo affronteremo le fasi di analisi semantica e di generazione
del codice con lausilio delle classi Java HashTable, Vector eStack.
![]() Download
Download
I sorgenti esposti possono essere scaricati ai seguenti indirizzi:
| Rafael
Andrés Marín de la Cruz
Laureato in Matematica-Cibernetica allUniversità dellAvana (Cuba) nel 1990, da quattro anni vive e lavora a Milano. Con la sua società ha sviluppato software per non vedenti sotto DOS e un tool di installazione per Windows. Svolge inoltre consulenza, in qualità di progettista, nel campo delle telecomunicazioni. Ha programmato un gioco-applet GeniusMind valutato "JARS Top 25%"; la versione italiana può essere vista all'indirizzo http://www.galactica.it/dialectica/genius/geniusmind.html. Il suo sito si trova al seguente indirizzo: http://www.galactica.it/dialectica. Può essere contattato tramite la redazione o direttamente all'indirizzo: dialectica.sas@galactica.it |
|
|
||
|
|
||
 |
MokaByte ricerca
nuovi collaboratori
|
 |
|
|
||