Un sistema documentale
Un sistema di gestione
documentale è un sistema di organizzazione, gestione e aggiornamento
di documenti. La tipologia che questi possono assumere può ricondursi
ai meta-gruppi di seguito elencati:
-
Documenti in formato
elettronico;
-
Forms
-
Documenti non residenti
-
Documenti logici
Le
operazioni che possono essere effettuate sui documenti appartenenti a ciascuna
di queste classi sono le seguenti:
-
Organizzazione :
è possibile organizzare i documenti nella maniera che si ritiene
più consona. Essi infatti vengono raggruppati e registrati in contenitori
elettronici che vengono definiti folders.
-
Attribuzione di
privilegi : ai folders contententi i documenti organizzati è necessario
assegnare dei privilegi. Questo consente infatti, all'interno di uno stesso
folder, di assegnare dei limiti di sicurezza di accesso ad utenti o a gruppi
di utenti nella gestione di un documento. I privilegi infatti riguardano
la vista, la stampa, l'export, la cancellazione e l'attribuzione di documenti.
-
Registrazione dei
documenti : per permettere la gestione completa da parte del sistema documentale
di un documento, è necessario che esso venga registrato. La registrazione
consiste infatti nell'inserimento del documento all'interno di un subfolder
di registrazione. Questo procedimento scatenerà un processo di workflow
di approvazione del documento al termine del quale il documento stesso
verrà rilasciato. I documenti rilasciati vengono ritenuti approvati.
E' possibile che alcuni documenti non richiedano alcun procedimento di
approvazione e possono quindi essere inseriti direttamente tra quelli approvati.
-
Cross Referencing
dei documenti : alcuni documenti possono venire associati ad altri. Tale
processo di associazione viene chiamato cross reference. Agli utenti viene
notificata tale associazione all'atto del check out del documento.
-
Check In e Out dei
documenti : consiste nell'estrazione e nell'inserimento del documento dall'unità
fisica dove esso è immagazzinato, allo scopo di sottoporlo ad una
qualunque lavorazione. L'editing di un documento ne è appunto un
esempio. Il documento viene estratto e gli viene segnato come Checked Out,
modificato e reinserito con l'attributo Check In e con le modifiche effettuate
su di esso. Inoltre gli verrà assegnata una nuova revisione, in
modo da non perdere la revisione precedente.
-
Updating dei documenti
: deve essere automatizzato il processo di trasferimento dei documenti
da una persona all'altra per la modifica, l'aggiornamento il completamento
degli stessi. Questo permette al sistema di tenere traccia dei documenti
durante l'intero processo di modifica. Ogni variazione infatti viene mantenuta
dal sistema.
-
Ricerca dei documenti
: il sistema documentale consente di effettuare ricerche articolate di
documenti in funzione di svariati attributi tra i quali, ad esempio, il
nome o la data di rilascio. E' possibile inoltre effettuare ricerche su
interi documenti attraverso del testo contenuto in essi (ricerca full text),
oppure una combinazione di entrambe le cose.
Sistema documentale
e Java Beans
Lidea per la costruzione
dellapplet è quella di utilizzare set di componenti Java (JavaBeans)
che possono essere collegati agevolmente l'uno all'altro con una tecnica
di wiring (di collegamento), tipica del tool di sviluppo dellIBM denominato
VisualAge for Java.
I Java Beans
( costituiti da file in formato .jar) sono costruiti rispettando i compiti
che il sistema documentale deve svolgere, quindi la gestione delle funzionalità
di workflow, interfaccia grafica e comunicazione.
Il wiring è
il processo di collegamento dei beans all'interno di un aplicazione JAVA,
nel senso che le connessioni tra i beans determinano la modalità
di interazione tra l'uno e l'altro.
VisualAge for
Java utilizza questa tecnica come modello naturale di codifica, tanto è
vero che la connessione avviene infatti all'interno del Visual Composition
Editor.
La connessione
o wiring, solitamente avviene manualmente da parte dello
sviluppatore,
tuttavia è possibile che i beans siano strutturati per operare anche
automaticamente.
I tipi di connessione
manuale possibile riguardano :
-
Property-to-property:
associa una proprietà all'altra rendendola dipendente.
-
Event-to-property:
cambia il valore della proprietà al verificarsi di un evento.
-
Event-to-method:
chiama un metodo al verificarsi di un evento.
-
Property-to-method:
chiama un metodo al variare di una proprietà.
La connessione automatica
è una tecnica di connessione attiva per default in fase di costruzione
dell'applicazione che consente di legare degli oggetti noti, l'uno con
l'altro, senza utilizzare alcuna connessione manuale.
Ogni bean, infatti,
è in grado di registrarsi all'interno di un registry utilizzando
un prefisso ed un suffisso che consente di identificarne la tipologia.
In particolare esistono due tipi di connessione automatica :
-
Automatic Group
Wiring, connette una API, dialog, e relativi bottoni che condividono lo
stesso prefisso. I tre beans, all'interno di una stessa applicazione, sono
in grado di assolvere insieme ad una specifica funzionalità. Generalmente
il prefisso di un bean descrive sommariamente la funzione che assolve.
La connessione manuale può assumere in questa fase un ruolo marginale
o può addirittura essere evitata.
-
Automatic Service
Wiring, connette dinamicamente le proprietà standard di un bean
a determinati servizi quali la variazione del puntatore del mouse (busy),
la gestione delle eccezioni e l'help contestuale.
Poichè
alcuni sistemi di gestione documentale permettono di dialogare, utilizzando
un normale browser attraverso una serie di pagine HTML o addritittura con
un applet, con il fulcro del sistema stesso, Java assolve esclusivamente
funzioni di interfaccia per la navigazione tra i documenti.
L'applet Java
avrà pertanto il compito di presentare in maniera evoluta i dati
che vengono
restituiti dal documentale all'interno della sua interfaccia grafica.
Struttura dellapplicazione
Larchitettura sulla
quale si è basato lo sviluppo dellapplicazione e quella classica
a 3 livelli (3 thiers), quindi un client (lapplet JAVA), un oggetto
remoto (server RMI) e un server (il Web Server), come illustrato nella
figura sottostante:
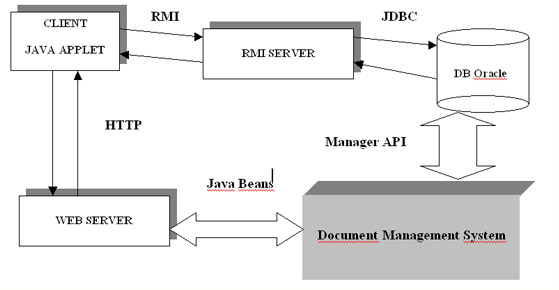
|
Figura
1: struttura dellapplicazione
Come si
può notare, lutente, attraverso lutilizzo di un browser (di solito
Netscape Communicator), scarica dal Web Server lapplet JAVA per la navigazione
allinterno del sistema documentale. Lapplet effettua una lookup verso
un server RMI (opportunamente startato in precedenza) il quale colloquia
direttamente, tramite le API di JDBC, con il Data Base Oracle. Una volta
stabilita la connessione con il server RMI, il client è in grado
sia di effettuare query sulla base dati (ad esempio consultazione di un
qualche dato o proprietà), che di visualizzare i documenti nel loro
formato elettronico.
Il sistema documentale
colloquia con il Web Server, quindi con il client, attraverso i Java Beans
di cui si parlava in precedenza, e con il DB attraverso delle API particolari.
La cosa fondamentale è che questi bean supportano completamente
le funzionalità del sistema documentale, quindi dal client posso
effettuare operazioni quali, ad esempio, il check out ( e quindi il check
in ) di un documento.
Loggetto RMI
viene creato in modo da colloquiare con il DB attraverso la tecnologia
JDBC, in particolare sfruttando il thin driver della Oracle. Tramite un
file di configurazione che viene letto allatto dello startup, il server
individua attraverso una stringa di configurazione il DB e crea una connessione
fissa verso di esso; dopodichè si mette in attesa delle chiamate
da parte del client. Il server è costituito in modo da esporre allesterno
i metodi necessari per il colloquio col DB, quindi un metodo per linterrogazione
(query), un metodo per la modifica (update) e i metodi per la commit e
per la rollback. Inoltre possiede un metodo per linvocazione di store-procedures
in formato PL / SQL sul DB e due metodi, uno per lapertura ed uno per
la chiusura, di una specifica connessione verso il DB per uno determinato
utente, questultimo descritto da uno username e da una password.
Handling dei documenti
Come detto in precedenza,
un documento è costituito da una parte logica, quindi i dati concernenti
i suoi attributi quali la data di registrazione, la grandezza, il formato,
ecc., e da una parte fisica, cioè il file elettronico che lo rappresenta.
Nel caso in
esame, i documenti possono essere di due tipi : file formato Word (.doc)
e file formato Acrobat Reader (.pdf). Quando viene richiesto dallutente
il file elettronico legato ad un documento, il sistema documentale, attraverso
unassociazione tra il formato ed il programma di visualizzazione, restituisce
una URL che punta direttamente al file memorizzato allinterno dellarchivio.
Naturalmente il sistema effettua una copia in locale sul client del file
elettronico, in quanto per effettuare delle modifiche sul documento e necessaria
una doppia operazione di check out e check in del documento.
Un'altra funzionalità
importante è quella della chiamata dell'applet a partire da un hyper-link
contenuto all'interno del file elettronico associato ad un documento. Infatti
un documento può fare riferimento, al suo interno, ad un altro documento
e di quest'ultimo l'utente può volerne conoscere tutte le caratteristiche
e magari modificarne alcune utilizzando l'applet.
Facciamo un
esempio pratico : supponiamo che all'interno di un documento ci sia un
hyper-link del tipo
http://generic_server/pippo/flag_operazione/nome_documento.doc
dove generic_server
è il nome di un generico server, pippo una directory nel suo file
system e flag_operazione un flag che mi dice in che modalità deve
essere richiamato l'applet (quale pagina iniziale deve presentare). Netscape
Web Server può essere configurato, tramite la proprietà style,
in modo che quando gli viene passata una URL di un certo tipo, quest'ultima
viene tradotta in un'altra URL attraverso l'invocazione di una CGI. Quindi,
basta configurare lo style in questo modo :
style
= http://generic_server/pippo/*
Nel caso
in questione, la URL precedente viene tradotta dalla CGI (un piccolo file
in script UNIX) in :
http://phisical_server/nome_servlet
? name = nome_documento & option = flag_operazione
Quindi il
nome del generico server viene tradotto con il nome del server fisico (associato
fisicamente nel DNS server), sul quale gira una servlet che prende come
parametri il nome del documento e la modalità di apertura dell'applet.
Questa servlet
non fa altro che effettuare una ricerca all'interno del sistema documentale
(attraverso un altro oggetto RMI) del documento a partire dal suo nome
(nome_documento.doc) e restituisce una pagina HTML. Questa contiene il
riferimento all'applet il quale prende come parametri il documento (questa
volta in formato logico) e la modalità di visualizzazione dello
stesso. L'oggetto RMI è necessario poiché la servlet non
può direttamente effettuare una ricerca all'interno del sistema
documentale.
Conclusioni
In questo articolo
ho cercato di spiegare cosa sia un sistema documentale, le sue caratteristiche
principali e come un applet JAVA possa interagire direttamente con esso.
Il tutto utilizzando dei JAVA Beans che si interfacciano direttamente col
sistema documentale sfruttando un'architettura a 3 livelli, supportata
dall'utilizzo di una servlet per poter richiamare l'applicazione a partire
da un hyper-link contenuto nel documento. |

