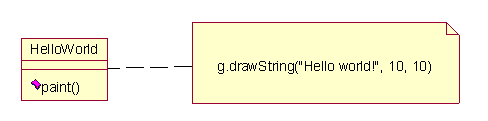|
MokaByte
Numero 34 - Ottobre 99
|
||||
|
|
 |
del software |
||
|
|
|
|
||
|
MokaByte
Numero 34 - Ottobre 99
|
||||
|
|
|
del software |
||
|
|
|
|
||
|
Lobiettivo principale del presente articolo e di quelli che seguiranno, è illustrare lo Unified Modeling Language focalizzando lattenzione sulle tecniche che ne permettono un utilizzo proficuo in tutte le fasi del ciclo di vita del Software. Si tenterà di dare il giusto risalto alla potenza di questo strumento, non trascurando di evidenziare gli inconvenienti in cui si può incorrere. Poiché largomento in questione è intimamente connesso con le problematiche inerenti il processo di analisi del Software, -così come viene avvertito nelle varie realtà aziendali- si è ritenuto doveroso aprire i lavori con una digressione sullargomento: loccasione si presentava talmente favorevole, irripetibile, che darebbe stato un vero peccato non coglierla! |
|||||||||||||||
Introduzione
Qualità di un modello.Quando si esegue un processo di modellazione, è sempre bene tenere a mente le proprietà peculiari che il modello risultante deve possedere.In particolare, deve essere:
UMLLarticolo viene pubblicato dopo circa cinque anni da quando Grady Booch e James Rumbaught iniziarono i loro lavori all Rational Software Comporation. Probabilmente, si è trattato della tecnologia giusta al momento giusto (ciò potrebbe far sbigottire anche il buon Murphy!), visto il gran successo riscosso e le prestigiose collaborazioni che hanno contributo alla realizzazione. Tra tali patner si contano aziende tra le più importanti del settore dell IT, tra le quali: IBM, Oracle, Microsoft, Texas Instruments, MCI Systemhouse, Hewlett-Packard, e così via. Lungi la voglia di ripetere per lennesima volta la storia dellUML, per la quale si rimanda allarticolo XXXXX, va detto che si tratta di uno strumento di analisi molto versatile, nato per risolvere le problematiche connesse con la progettazione del SW Object Oriented ma che ben si adatta ad essere utilizzato negli ambienti tra i più disparati. Per esempio lo si è utilizzato alla Cadence, per la produzione di un dispositivo di compressione vocale, operante a livello di porta fisica. Ancora, nellambito della progettazione di unarma di nuova generazione, una delle aziende fornitrici della US Navy lo ha utilizzato come linguaggio di progettazione del sistema darma. Unazienda sanitaria si è avvalsa dellUML per realizzare un modello per il trattamento dei pazienti, e così via.Visto lenorme successo riscosso, a partire dal mondo reale per poi approdare a quello accademico e del riconoscimento dello standard (UML 1.0 fu proposto al OMG nel gennaio 1997), gli stessi ideatori, i tres amigos (Grady Booch, James Rumbaught e Ivar Jacbson), considerano ormai conclusa la loro esperienza in questo ambito (da dichiarazione degli stessi) e si stanno dedicando a nuove sfide (cè chi può!). Allo stato attuale lo sviluppo dellUML è affidato ad una task force appartenente allOMG, la famosa RTF (Revision Task Force, però che fantasia!), diretta da Cris Kobyrn. Si è giunti al rilascio della versione 1.3. Metodi e linguaggiIn primo luogo è necessario chiarire il rapporto che intercorre tra lUML e i metodi di sviluppo del software, in quanto talune volte si tende a confonderne i ruoli. UML è un linguaggio di progettazione e, come tale, è solo parte di un metodo di sviluppo del Software più generale.In sostanza un metodo è formato, anche, dalle direttive che indicano al progettista cosa fare, quando farlo, dove e perché. Un linguaggio invece è carente di ciò. Esso è costituito da una sintassi, una semantica e da un paradigma. Si analizzi la similitudine (mai incontrata in precedenza) relativa al linguaggio naturale ed ai diagrammi UML. In tale contesto, la sintassi è costituita sia dallinsieme delle parole della lingua utilizzata (i simboli dei diagrammi) e sia dalle regole che specificano come organizzare frasi corrette (come combinare i simboli, quali possono essere associati, come, ecc.). La semantica si occupa del significato delle parole (simboli), sia considerate singolarmente e sia nel contesto nel quale vengono utilizzate (significato dei simboli in un particolare diagramma). Infine, un particolare paradigma potrebbe contenere le direttive atte a conferire al proprio stile di scrittura maggiore chiarezza, eleganza, ecc. (come realizzare modelli chiari, leggibili, eleganti, ecc.). LUML è indipendente dal processo che si decide di utilizzare, sebbene ne esistano alcuni per i quali esso risulta decisamente più idoneo, come use case driven, architetture-centric, iterative, incremental, Aree di intervento.Principalmente, lUML può essere utilizzato per:
Tutti i tecnici
per i quali la fase di disegno e quella di sviluppo coincidono, lutilizzo
di un formalismo per illustrare progetti (punto uno), potrebbe sembrare
un qualcosa di superfluo!
Per ciò
che concerne lutilizzo dellUML per la fase di documentazione, la tentazione
di considerare il tutto fin troppo ovvio è forte; ciò, tra
laltro, potrebbe generare la felicità del redattore.
Struttura dellUMLLUML, analizzato con una metodologia Top-Down, è costituito da:
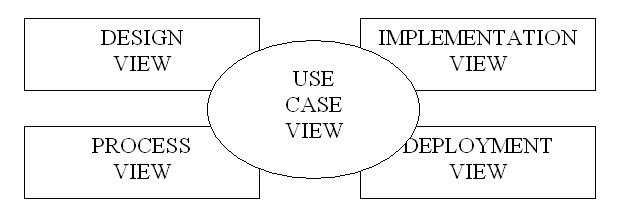
Le vistePer ciò che concerne le viste, ne sono previste quattro, ossia:
In breve, la
prima vista, use case view, serve per analizzare i requisiti utente, ossia,
cosa il sistema dovrà fare. Dunque, si tratta di una vista ad alto
livello di importanza fondamentale, sia perché guida lo sviluppo
delle rimanenti, e sia perché stabilisce le funzionalità
che il sistema dovrà realizzare, quelle per le quali il cliente
paga, per intenderci.
I diagrammiPrima di iniziare la descrizione dei diagrammi è necessario premetterle una breve precisazione: i diagrammi riportati di seguito hanno valore prettamente introduttivo. Non si richiede, pertanto, una loro piena comprensione, per la quale, invece, si rimanda agli articoli successivi. Essi sono stati presentati con lobiettivo di cominciare a famigliarizzare con gli elementi e i diagrammi dellUML, al fine anche di rendere più concreta la trattazione.Vi dice nulla la tanto inflazionata frase la descrizione di tali diagrammi esula dagli obiettivi del presente articolo ecc. ecc. ? I diagrammi dellUML sono dei grafici che visualizzano una particolare proiezione del sistema, analizzato da una specifica prospettiva. Essi sono ben nove e sono:
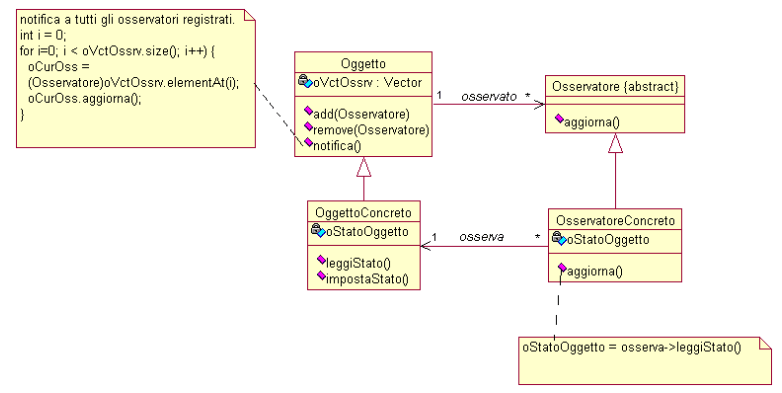
In fig 2. viene riportato un esempio di class diagram, in cui gli adepti del mondo del Design Patterns (anche questo sarà argomento di prossimi articoli) potranno riconoscervi il pattern denominato Observer (Osservatore). Nella figura seguente (fig 1). invece viene proposta una leggenda dei simboli utilizzati per evidenziare la visibilità delle proprietà e dei metodi delle classi; in particolare, i simboli grafici rappresentano la nomenclatura utilizzata alla Rational, mentre i caratteri +, - e # costituiscono quella standard.
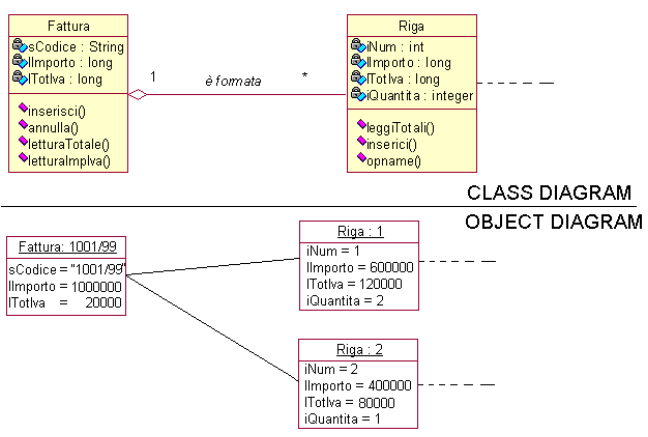
I diagrammi degli
oggetti rappresentano una variante dei precedenti, tanto che anche la notazione
utilizzata è pressoché equivalente, con le sole differenze
che i nomi degli oggetti vengono sottolineati e le relazioni vengono dettagliate.
Gli objects diagrams mostrano un numero di oggetti istanze delle classi
e i relativi legami espliciti. Anche questa tipologia di diagramma si occupa
della parte statica del sistema e mostra un ipotetico esempio di un diagramma
delle classi. Mentre questultimo è sempre valido, un diagramma
degli oggetti rappresenta unipotetica istantanea del sistema. In sostanza
lo si utilizza per esemplificare diagrammi delle classi, o suoi frammenti,
ritenuti poco chiari o particolarmente complicati.
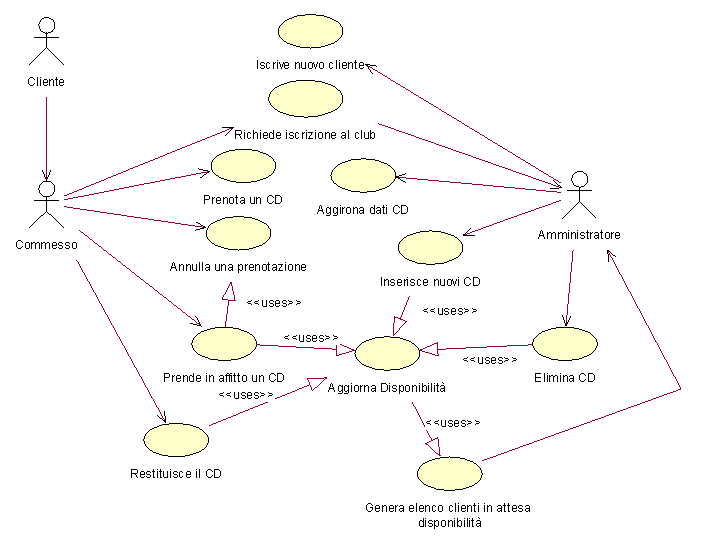
I diagrammi dei
casi duso, mostrano un insieme di attori esterni al sistema e le relative
connessioni con le funzionalità che il sistema dovrà realizzare.
Essi costituiscono il fondamento della use-case view, rappresentandone
la parte statica.
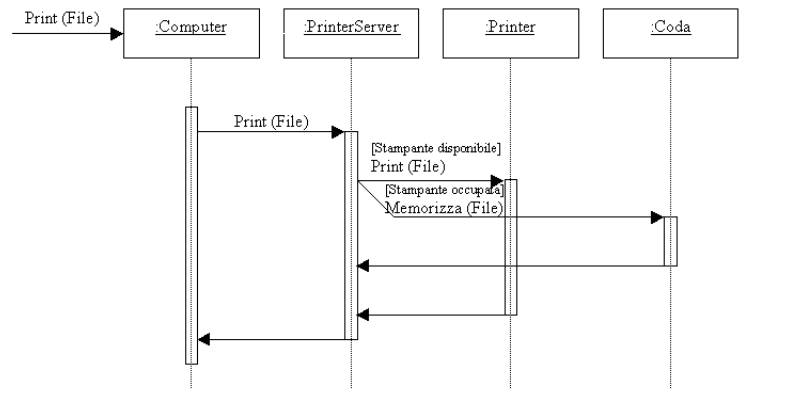
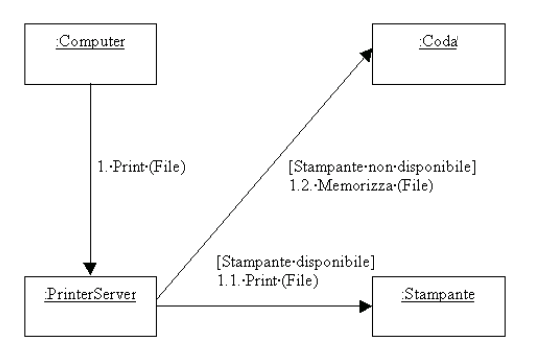
I diagrammi di
sequenza e collaborazione, vengono anche detti di interazione in quanto
mostrano appunto le interazioni tra oggetti del sistema. Pertanto essi
si occupano di modellare il comportamento dinamico del sistema. I due diagrammi
risultano molto simili, si può passare agevolmente dalluna allatra
rappresentazione (sono isomorfi), e si differenziano per via dellaspetto
dellinterazione che enfatizzano. In particolare, i diagrammi di sequenza
evidenziano lordine temporale dello scambio di messaggi, mentre i diagrammi
di collaborazione mettono in risalto lorganizzazione degli oggetti che
si scambiano i messaggi.
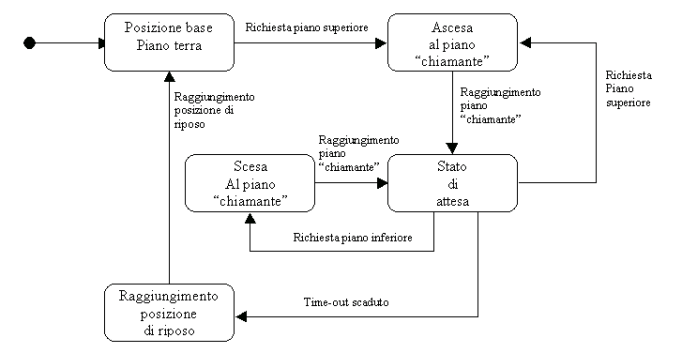
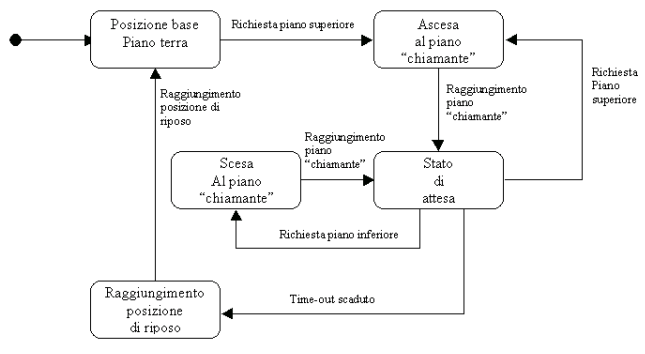
I diagrammi di
stato, arcinoti a tutti (spero), mostrano, in buona sostanza, un automa
a stati finiti, e pertanto sono costituiti da stati, transazioni, eventi
e attività. Essi vengono utilizzati principalmente come completamento
della descrizione delle classi. Anche essi si occupano di modellare la
parte dinamica del sistema, e vengono utilizzati per illustrare in dettaglio
il comportamento delle sole classi che possono transitare per gli elementi
di un ben definito insieme di stati.
I diagrammi di
attività non sono altro che particolari versioni dei paleolitici
flow chart, e, come tali, si occupano di evidenziare il flusso di attività.
Vengono particolarmente utilizzati per mostrare le attività svolte
da una particolare funzione del sistema, ma, nulla vieta di utilizzarli
per mostrare laspetto dinamico di un use case o di uninterazione.
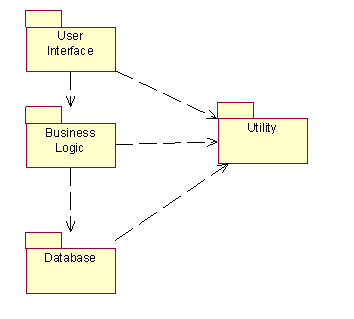
I diagrammi dei
componenti mostrano la struttura fisica del codice in termini di componenti
e di reciproche dipendenze. Essi permettono di illustrare la vista statica
dellimplementazione del sistema, e pertanto, sono strettamente connessi
ai class diagram. Ciascun componente è un contenitore di classi,
interfaccie,
La corrispondenza con i classici package dovrebbe essere
eviente.
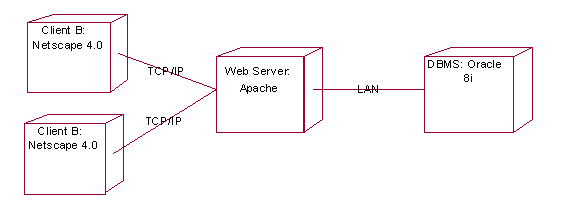
Infine, si incontrano
i diagrammi di dispiegamento che mostrano larchitettura hardware e software
del sistema. In particolare vengono illustrati gli elementi fisici del
sistema (computer, reti, device fisici,
) e i moduli software da installare
su ciascuno di essi.
Meccanismi generaliSebbene gli elementi base dello Unified Modeling Language permettono di formalizzare molti aspetti di un sisema, è impossibile pensare che essi da soli siano sufficienti per illustrarne tutti i dettagli. Come già detto, si sarebbe potuto cercare di raggiungere tali risultato, per esempio inserendo tanti elementi specializzati, ma il costo da pagare sarebbe stato quello di generare un linguaggio molto complesso e troppo rigido.Per evitare ciò, lUML prevede degli elementi base per aggiungere delle informazioni supplementari difficilmente standardizzabili. Lesempio più classico è quello delle note. Queste vengono rappresentate per mezzo di un foglio di carta stilizzato associato, per mezzo di una linea tratteggiata, allelemento che si vuole spiegare.
Altri esempi
di meccanismi generali sono i cosiddetti ornamenti (adornments). Essi permettono
di aggiungere semantica al linguaggio. Un esempio è la cardinalità
delle relazioni in un diagramma delle classi. Si tratta di un numero (o
simbolo) che specifica quante istanze di una classe possono essere coinvolte
in una relazione con unaltra.
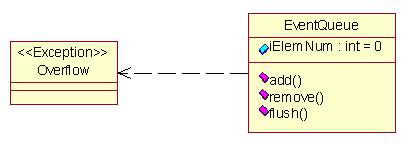
Meccanismi di estensioneTali meccanismi risultano di fondamentale importanza, specie in virtù dellambizione dellUML di esorbitare dal settore specifico dellinformatica. Questi, infatti, gli permettono di essere esteso, per mezzo dellintroduzione di opportuni elementi specifici, per un determinato settore.Il meccanismo di estensione più noto è sicuramente la stereotipizzazione. Si tratta della versione UML del concetto di ereditarietà. Questo permette di definire nuovi elementi a partire da quelli esistenti, al fine di aumentarne la semantica. Chiaramente, lo stereotipo di un elemento può essere utilizzato ogniqualvolta è possibile utilizzare lelemento di partenza. Uno stereotipo viene descritto inserendovi il nome tra parentesi angolari nellelemento base, ma nulla vieta di utilizzare un nuovo elemento grafico appositamente progettato. Un esempio classico di stereotipizzazione è rappresentato da classi eccezione.
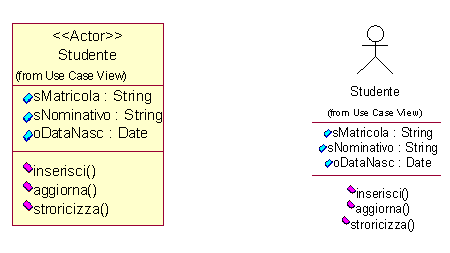
Un altro esempio
è quello delle classi che rappresentano un utente, anchesse vengono
rappresentate attraverso un omino stilizzato, noto in gergo con il nome
di scarabocchio!
Un altro esempio
di meccanismo di estensione sono i tagged values (valori etichettati).
Si tratta di elementi costituiti dalla coppia (nome, valore). Come al solito
ne esistono alcuni predefiniti, ma nulla toglie al progettista di definirsene
altri a proprio piacimento. Con questo meccanismo è possibile impostare
delle informazioni specifiche relative a dei metodi, informazioni relative
allo stato di avanzamento del modello, dati necessari ad altri strumenti
di sviluppo e così via. Per esempio, è possibile specificare
la versione della revisione di un diagramma o di un suo elemento. A tal
fine, è sufficiente impostare sotto il relativo nome la stringa
: {versione = 1.02}.
I processiLUML sia un linguaggio di progettazione indipendente da particolari processi di progettazione, e quindi in grado di adattarsi ai più svariati. Ne esistono però alcuni in grado di trarne il massimo beneficio. Tali processi sono:· Use case driven; · Architetture-centric; · Iterative and incremental. Da tener presente che la Rational, visto il grande successo riscosso con lUML, ha pensato bene di tentare la stessa strategia, anche nel settore dei processi proponendo la Rational Unified Process: chissà che non riescano a fare il bis! Comunque, i tre processi su elencati, si differenziano per via della particolare vista, ritenuta centrale per lintero ciclo di vita. Il primo, come suggerisce il nome, basa tutta la progettazione sugli use-case, i quali vengono utilizzati per stabilire il comportamento del sistema, per verificarne e validarne larchitettura, per eseguire la fase di test, ecc. Il secondo invece, pone in primo piano la progettazione dellarchitettura del sistema, la quale viene considerata lartefatto primario per la concettualizzazione, la costruzione, e la gestione dellevoluzione del sistema in costruzione. Infine, lultimo è basato sulla iterazione incrementale del modello. Un processo di sviluppo iterativo comporta la realizzazione di versioni di eseguibili successivi, quello incrementale richiede continui arricchimenti dellarchitettura del sistema per ottenere le nuove versioni. La fusione delle due modalità di operare genera la metodologia definita risk-driven in quanto, ogni nuova versione è incentrata sullaffrontare e risolvere il fattore di rischio ritenuto più importante al momento per il successo del processo. ConclusioniIn questo articolo si è cercato di introdurre lo Unified Modeling Language senza avere la pretesa di illustrarlo tutto e subito: sarebbe stato necessario disporre di un disco fisso dedicato!LUML è uno strumento molto potente e flessibile; se può sembrare difficile, lo si deve più alla complessità intrinseca del processo di progettazione e alla brevità della presente trattazione, piuttosto che ad una sua reale difficoltà. Si è tentato di rendere il tono meno accademico attraverso il magnifico strumento dellironia. Non se ne abbiamo i geologi. Si volevano evitare gli inflazionati stereotipi Chi meglio di loro che si occupano di pietre? In conclusione, lautore intende porgere le scuse per aver scritto un articolo così prolisso Non cè stato proprio il tempo per scriverne uno breve! Bibliografia
Grady Booch, James Rumbaugh, Ivar Jacobson Addison Wesley Questo libro vanta il primato di essere stato scritto dai progettisti originali del linguaggio, sebbene sia conosciuto come Gradys book, dal nome del suo primo autore. La mancanza di una sua copia (magari autografata!) può generare giudizi di scarsa professionalità per coloro che operano nel settore della progettazione O.O... Ciò però, costituisce una condizione necessaria, ma non sufficiente, in quanto bisogna, assolutamente, aggiungere una copia del [3] e una del [4]. Sono soldi spesi bene! Forse, il limite del libro, se proprio se ne vuole trovare uno, è quello di essere poco accessibile ad un pubblico non espertissimo di progettazione O.O. Un altro piccolo inconveniente è che, probabilmente, taluni esempi possano sembrare di carattere accademico: poco rispondenti alle problematiche del mondo reale. Hans-Erik Eriksson, Magnus Penker Wiley Questo libro si fa particolarmente apprezzare per via del taglio pratico dello stesso. Illustra in modo semplice il linguaggio, attraverso numerosi esempi, limitando le digressioni di carattere teorico. Si suppone infatti, che coloro che si occupano di progettazione O.O. abbiano una certa familiarità con i relativi concetti. Chissà perché si ha la sensazione che non sia sempre così! Naturalmente, studiare libri che illustrano gli aspetti teorici dellinformatica, è sempre qualcosa più che auspicabile. È altresì vero, però, che coloro che non hanno tempo da perdere, alla lettura di concetti arcinoti, gradiscono arrivare rapidamente al nocciolo. Ciò spesso equivale a strappare alle nottate lavorative ore preziose per il sonno. Grady Booch, James Rumbaugh, Ivar Jacobson - Addison Wesley Il commento da riportare per questo libro, noto per come Rumbaughs book, è sostanzialmente equivalente a quanto riportato per il primo. Esso però offre un livello di difficoltà decisamente inferiore, e pertanto dovrebbe essere più accessibile. Come suggerisce il nome, si tratta di un manuale, per cui ne rispetta la tipica struttura. Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides, Grady Booch - Addison Wesley. Si tratta di un ottimo libro che bisogna assolutamente avere se si vuole lavorare nellambito della progettazione O.O. . I pattern riportati, forniscono un ottimo ausilio al processo di disegno del software. Lutilizzo del libro contribuisce ad aumentare la produttività, fornisce soluzioni chiare, efficienti e molto eleganti. La fase di disegno del software, spesso, si riduce ad individuare e personalizzare i pattern che risolvono la problematica specifica. Si è di fronte ad una nuova frontiera della progettazione O.O.: il riutilizzo di parti del progetto. Lunica pecca imputabile, è che i vari diagrammi non sempre rispettano il formalismo UML. Si tratta del sito ufficiale del Object Managment Group.
|
|||||||||||||||
Luca Vetti
Tagliati è nato a Roma il 3 Dicembre del
1972. Ha conseguito il diploma di laurea in Ingegneria Informatica ed
Automatica presso lUniversità Degli Studi di Roma La Sapienza,
nel Dicembre del 1996 con votazione 100/100.
In particolare,
con la I&T SpA collabora alla reingengerizzazione del sistema informatico
della Polizia di stato. Il nuovo sistema prevede: la gestione del protocollo,
la gestione completa dei verbali, la generazione di statistiche, il collegamento
delle sedi periferiche (104 sezioni, 20 compartimenti e 300 unità
operative), lo scambio dati, in tempo reale, con altri enti quali: il P.R.A.,
la Motorizzazione Civile, Poste,
.
Luca Vetti Tagliati
è raggiungibile allindirizzo di e-mail : Luca.VT@usa.net
|
|
|
||
|
|
||
 |
MokaByte ricerca
nuovi collaboratori
|
 |
|
|
||