|
MokaByte
Numero 36 - Dicembre 99
|
|||
|
|
del software |
||
|
|
Fabio Cesari e Massimo Campeggi |
E' possibile scaricare la versione compressa di questa presentazione (375Kb in formato zip). |
|
|
MokaByte
Numero 36 - Dicembre 99
|
|||
|
|
del software |
||
|
|
Fabio Cesari e Massimo Campeggi |
E' possibile scaricare la versione compressa di questa presentazione (375Kb in formato zip). |
|
Questo documento riassume i test eseguiti sul programma DFG per valutarne le prestazioni. I test sono stati eseguiti nel laboratorio LAB2 presso il Dipartimento di Elettronica, Informatica e Sistemistica dell'Università di Bologna. Si sono utilizzati i sistemi operativi:
Si è anche
creata una versione concentrata (chiamata Mand) che non utilizza
una funzione nativa ma esegue tutti i calcoli in Java.
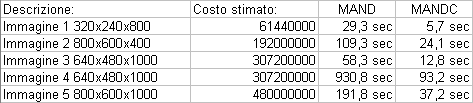
Per effettuare questo test si sono utilizzate macchine il più possibile simili in prestazioni (sparcstation5 per il test effettuato sul sistema operativo Solaris e PentiumII 233Mhz per il test effettuato sul sistema operativo NT) e si è impostato ad un valore comune il parametro "carico di default". Inoltre, durante il test, sulle macchine non erano attivi altri programmi "pesanti" oltre a DFG. In questo modo si è cercato di eliminare possibili fattori esterni che potessero influenzare il risultato del test e quindi le valutazioni che da questo si possono ricavare. I valori riportati nelle tabelle sono la media di una serie di rilevazioni tutte effettuate nelle stesse condizioni. Tabella 1
Osservazioni: Si è effettuato
il calcolo di una serie di immagini diverse non solo nel loro costo (stimato),
ma anche per le loro caratteristiche intrinseche, che ne determinano la
reale complessità di calcolo. Ad esempio, le immagini 3
e 4 hanno lo stesso valore di costo, ma in realtà
i punti dell'immagine 4 richiedono un numero di iterazioni
mediamente molto superiore per essere calcolati (ved. Tabella 1).
Questa considerazione mette in risalto il fatto che per un buon uso delle risorse è necessario impegnare in continuazione tutti gli slaves disponibili. Solo in questo modo è possibile ottenere prestazioni significativamente superiori a quelle ottenibili con un sistema concentrato. In altre parole, il programma DFG non è adatto a calcolare singole immagini, ma a svolgere il calcolo di un numero elevato di immagini contemporaneamente. Esaminando i dati, si nota subito il fatto che DFG, quando c'è un solo slave a disposizione, è sempre più lento di MandC. Questo è ovviamente causato dall'overhead dovuto alla comunicazione tra le entità che costituiscono DFG. All'aumentare
del numero di slaves disponibili, il tempo di calcolo generalmente diminuisce.
Questo però non accade sempre. Si consideri l'immagine
5: il tempo necessario per calcolarla è di soli 25.8sec con
due slaves a disposizione, mentre è di 36.3sec con tre slaves. Questo
è dovuto al fatto che questa immagine è fortemente asimmetrica
per quanto riguarda la complessità di calcolo. La si può
infatti suddividere in tre fasce orizzontali, delle quali quella centrale
è estremamente più complessa da calcolare delle altre.
Nota: E' possibile introdurre ottimizzazioni nella funzione di calcolo dell'insieme di Mandelbrot in modo da ridurre al minimo le disomogeneità alle quali si è accennato. La versione attuale di DFG non adotta alcun tipo di ottimizzazione. L'introduzione di questo tipo di ottimizzazione migliorerebbe notevolmente le prestazioni globali del sistema, sia perchè ridurrebbe il numero di iterazioni necessarie a riconoscere i punti appartenenti all'insieme di Mandelbrot, sia perchè permetterebbe una più equa ripartizione del carico tra gli slaves. Un'altra osservazione importante che si può fare osservando i dati è che il sistema fornisce prestazioni migliori nel calcolo di immagini che hanno un costo molto elevato, perchè nel calcolo di tali immagini l'overhead introdotto dalla comunicazione costituisce una percentuale molto piccola del tempo di risposta totale. Infatti, il miglioramento ottenuto nel calcolo dell' immagine più costosa in assoluto passando da uno a cinque slaves è del 74.9% (immagine 4), mentre i miglioramenti ottenuti per le altre immagini vanno dal 47.2% al 58.3%. Il grafico seguente riporta i dati della Tabella 1: 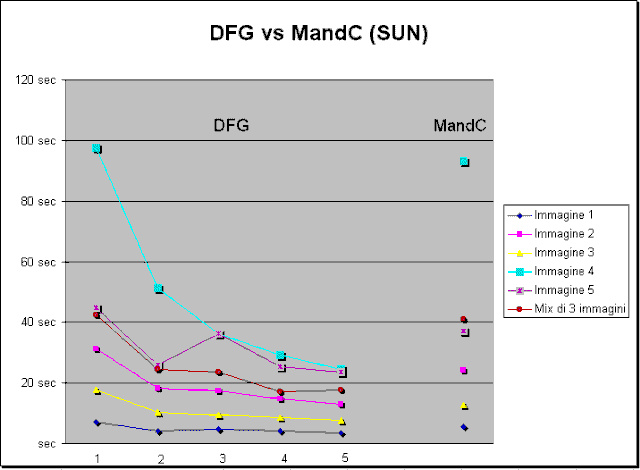 Di seguito sono
riportati i tempi ottenuti sul sistema operativo Windows NT. In queste
prove, il miglioramento delle prestazioni dovuto all'utilizzo di un numero
di slaves maggiore è più marcato. Passando da uno a 4 slaves,
il miglioramento va dal 54.9% (per l'immagine1,
che essendo poco costosa risente maggiormente dell'overhead della comunicazione)
al 76.3% (per le immagini 4 e 5,
che sono le più costose e quindi risentono meno dell'overhead della
comunicazione).
Tabella 2
Le caratteristiche delle immagini calcolate sono le seguenti:
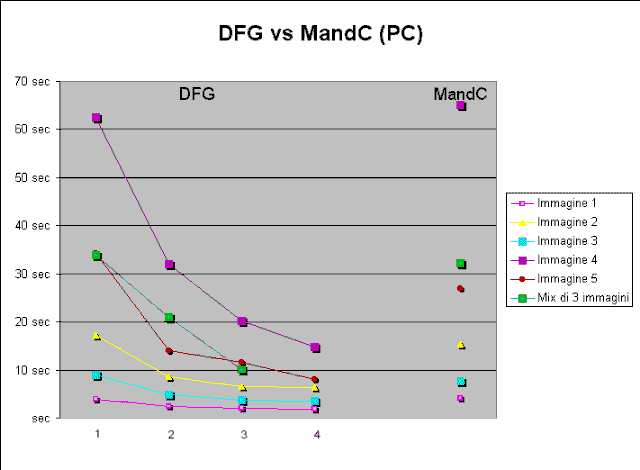
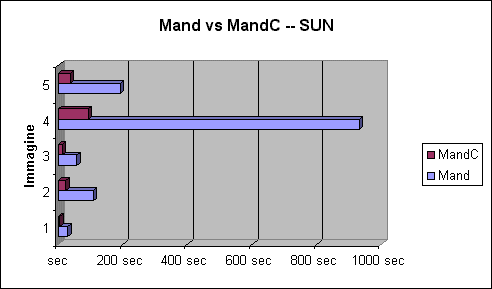
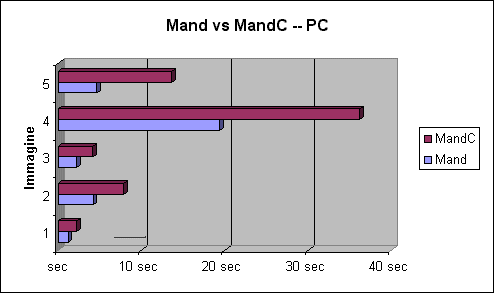
Questo test permette di confrontare i tempi ottenuti con una funzione nativa con quelli ottenuti con codice Java. Per effettuare questo confronto ci si è serviti di due applicazioni concentrate:
L'incremento
delle prestazioni dovuto all'uso di una funzione nativa è notevole.
Nel caso dell'immagine 4, che è la più
complessa da calcolare (nonostante il suo costo stimato non sia il più
elevato), il tempo di generazione con MandC è un decimo di quello
di Mand. Il grafico seguente riporta i dati della Tabella 1:
Di seguito sono
riportati i dati relativi al test effettuato sul sistema operativo NT:
A differenza
del caso precedente, l'uso di una funzione nativa peggiora le prestazioni
del programma. Questo è dovuto al fatto che la versione di Java
utilizzata (1.2beta4) supporta la compilazione JIT dei bytecodes e permette
quindi di ottenere elevate prestazioni dal codice Java. Il grafico seguente
riporta i dati della Tabella 2.
Parametri
delle immagini utilizzate per questo test.
Questo test permette di valutare il costo determinato dall'aver inserito nel sistema una forma di fault-tolerance che pemette di ottenere sempre un risultato anche in presenza di guasti agli host DFGSlave. In particolare, lo scopo di questo test è fornire una misura dell'overhead dovuto ad una ridistribuzione di carico seguita alla caduta di uno o più slaves. Osservazione: se uno slave cade durante il calcolo, il lavoro che aveva svolto fino al momento del guasto viene perso e deve essere ripetuto dagli altri slaves. Visto che ciò che interessa è misurare l'overhead introdotto da una ridistribuzione di carico, è necessario mantenere distinto questo valore dal tempo "perso" dallo slave guasto a calcolare una porzione di immagine che alla fine non viene utilizzata e deve essere ricalcolata. Si è quindi pensato di eseguire il test inserendo nella Tabella mantenuta da DFGServer un numero di slaves superiore a quello realmente disponibile. In questo modo, all'atto di una nuova richiesta, DFGServer è stato costretto ad effettuare immediatamente una o più ridistribuzioni di carico. La descrizione dei passi eseguiti per effettuare il test è riportata di seguito:
L'overhead introdotto è abbastanza modesto. Si consideri però il fatto che il test è stato effettuato senza che fossero in corso altri calcoli, vale a dire nelle condizioni più favorevoli possibili. Osservazione: In una situazione senza guasti, ogni slave utilizza un solo thread per svolgere il calcolo che gli è stato assegnato e al termine del calcolo spedisce il risultato corrispondente a DFGServer. Il tempo di servizio di uno slave è quindi dato dalla somma tra il tempo di calcolo e il tempo di trasmissione del risultatato (che nei nostri test non è mai stato preso in considerazione perchè è molto piccolo rispetto al tempo di calcolo). Nel caso di una ridistribuzione di carico, invece, ogni slave rimasto attivo si trova a calcolare più di una porzione dell'immagine richiesta, e lo fa utilizzando thread distinti. Al termine del calcolo di ciascuna porzione, la spedisce a DFGServer. Durante questa spedizione, però, il calcolo relativo alle altre porzioni dell'immagine continuano e quindi il tempo di trasmissione del risultato è in definitiva limitato all'ultima porzione di immagine trasmessa a DFGServer. In questo senso, si può dire che l'overhead di una ridistribuzione sia parzialmente compensato da una maggiore efficienza nella restituzione del risultato. Il test è stato eseguito in LAB2 sulle macchine lia (si sono utilizzate quattro sparcstation5, tutte inizializzate ad uno stesso valore di carico e sulle quali era attivo solamente il programma DFG) , cercando di eliminare possibili fattori esterni che potessero influenzare i risultati del test. Il test è stato ripetuto varie volte e i valori riportati nella tabella sono valori medi.
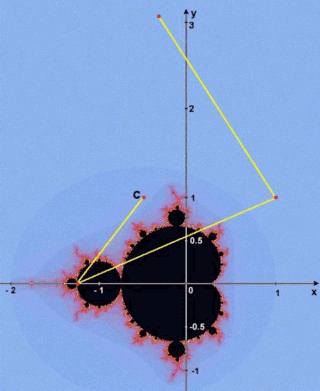
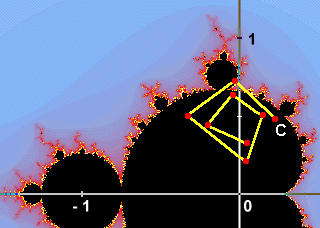
L'insieme di Mandelbrot è l'insieme dei punti C del piano complesso per i quali non è divergente la serie definita dalla legge ricorsiva Iterando la formula per ogni punto del piano complesso, è quindi possibile suddividere i punti in due categorie:
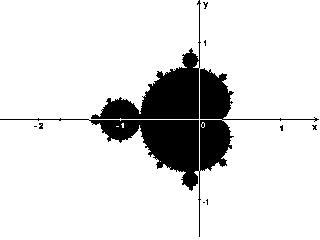
Grazie a questo risultato, è possibile riconoscere i punti che non appartengono all'insieme perchè la loro orbita, dopo un certo numero di iterazioni, esce dal cerchio di raggio 2. Purtroppo, può essere necessario un numero di iterazioni molto elevato prima che l'orbita di un punto non appartenente all'insieme esca dal cerchio. Nel caso di punti appartenenti all'insieme, l'orbita non esce mai dal cerchio, nemmeno dopo un numero infinito di iterazioni. Per questo motivo si fissa un numero massimo di iterazioni, dopo le quali si assume che se l'orbita non è ancora uscita dal cerchio allora non ne uscirà mai e quindi il punto considerato fa parte dell'insieme di Mandelbrot. E' anche possibile assegnare un colore ai punti che non appartengono all'insieme di Mandelbrot. Esistono molti modi per farlo: il più semplice è detto "metodo del tempo di fuga" e consiste nell'assegnare ai punti un colore che dipende dal numero di iterazioni che sono necessarie per capire che non appartengono all'insieme. Si può
dare una spiegazione intuitiva del nome di questo metodo: si immagini che
tutti i punti del piano siano attratti sia dall'insieme di Mandelbrot che
dalla retta impropria. E' quindi facile capire perchè i punti più
vicini all'insieme abbiano orbite che sfuggono all'infinito più
lentamente di quelle relative a punti più lontani dall'insieme.
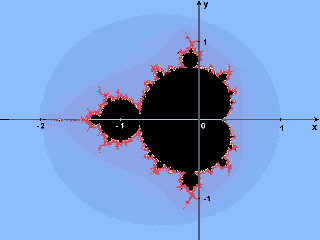 La funzione nativa utilizzata nel programma DFG ha il compito di assegnare un colore ad ogni punto di un'area rettangolare del piano complesso (rappresentata da un array di interi). Per quanto appena detto, le operazioni svolte dalla funzione per ogni punto C dell'immagine sono le seguenti:
Un possibile miglioramento delle prestazioni globali del sistema consiste nell'utilizzare BYTE (che occupano solo 1byte) al posto di INT, ottenendo così un'occupazione di memoria per un'immagine pari a un quarto di quella attuale. Questo è possibile se si trasferisce il compito di trasformare n in una tripla RGB dai DFGSlave al DFGClient. In altre parole, i DFGSlave si limitano a riempire un array di BYTE con valori del tipo n%256, che permettono al client, tramite l'utilizzo di una sottoclasse della classe Palette, di risalire alla tripla RGB di ciascun punto dell'immagine. Questo metodo presenta anche il vantaggio di rendere inutile l'inserimento della palette da utilizzare per la generazione dell'immagine tra i parametri di Messaggio_Mandelbrot, diminuendone fortemente le dimensioni. Esempi:
Alla terza iterazione, il modulo di Zn diventa maggiore di 2. Questo significa che C non appartiene all'insieme di Mandelbrot. Dato che il numero di iterazioni che sono state necessarie per determinarlo è 3, al punto C viene assegnato il colore n.3 della palette. Ripetiamo il
procedimento con un punto appartenente all'insieme di Mandelbrot: C
= 0.2 + i * 0.5. In questo caso, il modulo di Zn non diventerà
mai maggiore di 2 per nessun valore di n. Quando viene raggiunto il numero
massimo di iterazioni, si assume che C appartenga all'insieme di Mandelbrot
e lo si colora di nero.
Per maggiori
informazioni sull'insieme di Mandelbrot: Fractal
Explorer
L'applicazione realizzata, un generatore di frattali, è solo delle possibili applicazioni del sistema progettato, che è facilmente estendibile per trattare problemi di diversa natura nell'ambito del web computing. E' infatti molto semplice introdurre nuovi tipi di Messaggio ed estendere le capacità di DFGServer e dei DFGSlave (introducendo nuove classi Gestori). E' anche semplice modificare le politiche di ripartizione del carico, che sono interamente specificate in un metodo della classe Tabella. L'unica limitazione è costituita del fatto che non è prevista alcuna interazione tra i DFGSlave, quindi il sistema è adatto a svolgere calcoli che possano essere decomposti in parti autonome.
E' anche possibile implementare semantiche diverse da quella adottata,
ad esempio spedendo richieste uguali a vari slaves e attendendo la risposta
dello slave più veloce a terminare (o della maggioranza, o di tutti
con confronto delle risposte).
POSSIBILI MIGLIORAMENTI:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
MokaByte ricerca nuovi collaboratori. Chi volesse mettersi in contatto con noi può farlo scrivendo a mokainfo@mokabyte.it |
 |
|
|
||