Ci siamo tutti
chiesti almeno una volta: ma è possibile che non esistano driver
JDBC nativi per Access ? Risposta: non è che in linea di principio
sia impossibile scrivere dei driver JDBC per Access (ammesso che veramente
non ne esistano), il punto è che Access incarna il teorema del database
standard a modo suo, tantè vero che molte metaproprietà
in genere presenti sulla maggior parte dei database su Access mancano o
sono implementate diversamente. Ma bando alle lamentele e cerchiamo invece
una soluzione quantomeno plausibile.
Le alternative
Intanto è
chiaro che vista la situazione abbiamo comunque bisogno di uno strato intermedio
tra la nostra pagina web e il database ( e dagli con il n-tier !!), si
tratta ora di decidere quale sia la soluzione più adatta.
Per parlare di ciò che è già pronto possiamo subito
dare unocchiata al Remote Scripting. Si tratta di una tecnologia Microsoft,
costituita da un applet Java ( strano ?!) in grado di eseguire delle funzioni
scripting lato server, nel nostro caso interrogazioni a database
e restituire dei dati. Il vantaggio principale rispetto ad esempio alla
tecnologia ASP è che in ASP le elaborazioni server-side avvengono
al momento di creare una pagina, quindi ogni elaborazione richiede il caricamento
di una nuova pagina web. In Remote Scripting invece ce uno scambio di
dati fra client e server senza bisogno di richiedere al server una nuova
pagina html/asp.Le chiamate alle funzioni di Remote Scripting e la manipolazione
dei dati di ritorno avvengono via scripting client.E un sistema ibrido,
che richiede il supporto ASP sul server e non semplicissimo da debuggare
soprattutto per funzioni complesse, però piuttosto comodo.
Riportiamoci
ad un mondo più Java puro; se parliamo di accesso remoto a qualcosa
la prima sigla che ci viene in mente è RMI (Remote Method Invocation).
E luovo di Colombo: il client chiama lesecuzione di metodi sul server,
che svolge il lavoro e restituisce i dati. Problema: poche sono le VM integrate
nei vari browser in grado di gestire RMI in maniera decorosa, per cui o
siamo sicuri della piattaforma client utilizzata, o dobbiamo necessariamente
scartare questa ipotesi a priori, anche perché molti sono quelli
allergici allinterazione con il rmi registry ( abbiamo tutti subito traumi
a causa di qualche registry !!).
Altra ipotesi:
connessione pura TCP/IP fra applet e processo server con interscambio di
dati. Il processo server interpreta le istruzioni che riceve dal client,
interagisce con il database e restituisce i dati al client. A prima vista
sembrerebbe piuttosto complesso, però gli strumenti messici a disposizione
dal nostro linguaggio preferito ci possono venire in aiuto. Per di più
potrebbe essere loccasione per fare un po di ripasso su alcuni fondamenti
delle librerie di Java. In questo primo articolo faremo unanalisi approfondita
dellarchitettura per poi, nei prossimi, lanciarci a capofitto nella scittura
del codice.
Analisi preliminare
Cominciamo a
vedere la struttura generale del nostro progetto, poi vedremo le varie
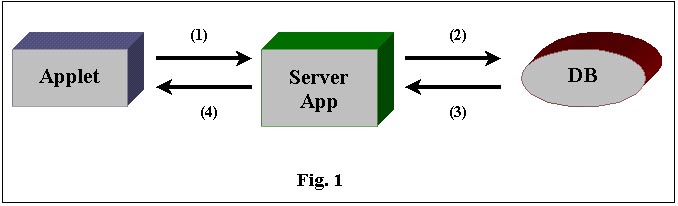
fasi in dettaglio. Come mostrato in figura 1, abbiamo 3 entità distinte
: il nostro applet, un applicativo server e un database.Lapplet viene
naturalmente eseguito sul
client, mentre
lapplicativo server risiede sul web server, e questo obbligatoriamente,
in quanto ricordiamo che un applet generico può instaurare connessioni
tcp/ip solo con il server dal quale è stato scaricato. Per quanto
riguarda il database, per semplicità consideriamo il caso
in cui anchesso si trovi sulla stessa macchina del web server, in modo
da poter utilizzare semplicemente il bridge Jdbc-Odbc ( stiamo ipotizzando
un database Access).
Il percorso
(1) della figura rappresenta il canale attraverso il quale lapplet comunica
allapplicativo server ciò che vuole. A questo fine stabiliremo
dei formalismi comunicativi, in modo che sia possibile per lapplicativo
server riconoscere se i dati inviati dallapplet siano istruzioni o query
sql. Una volta effettuato il parsing del ricevuto, lapplicativo server
si interfaccerà con il database (percorso (2) ) via JDBC, ottenendo
(3) i dati di ritorno. Su questi dati eseguirà le sue elaborazioni
per creare uno streaming di dati che attraverso (4) invierà allapplet
il quale, infine, ne estrarrà ciò che gli serve per eventualmente
visualizzarli.
Concettualmente
i vari passaggi sono abbastanza semplici, ma la loro implementazione richiede
lutilizzo di tutta una serie di concetti e librerie Java, e questo rappresenta
forse il vero valore didattico di questo e dei prossimi articoli della
serie.
In dettaglio
A questo punto
focalizziamoci sulle singole fasi del processo, in modo da individuare
il più precisamente possibile i blocchi funzionali della nostra
architettura. Partiamo dallapplet: in figura 2 vediamo i blocchi funzionali
costitutivi, che ci permettono subito di atomizzare il più possibile
la fase di sviluppo.
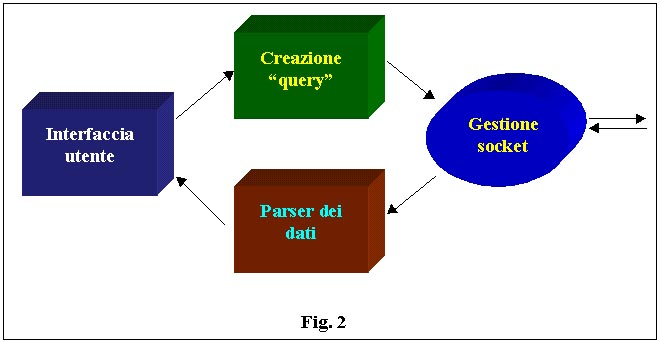
Abbiamo diviso
lapplet in quattro moduli. Tralasciamo per il momento linterfaccia
utente, dato che dei quattro è sicuramente la più banale,
o comunque quella che richiede meno spiegazioni. Il modulo che abbiamo
chiamato creazione query, è quello che si occupa di creare una
stringa, da inviare allapplicativo server, che contenga sia istruzioni
che dati. Facciamo un esempio: supponiamo che si voglia ordinare allapplicativo
server di eseguire la query select * from clienti sul database prova
( prova sarà il nome ODBC del file access). Possiamo pensare di
strutturare la stringa di richiesta in un modo simile a questo: Database:
prova ; Query: select * from clienti ; , dove Database e Query saranno
riconosciute dallapplicativo server come parole chiave, e ciò che
sta fra i due punti e il punto e virgola come dato riferito alla parola
chiave( quindi punto e virgola e due punti saranno riconosciuti come separatori).
Con lo stesso metodo è possibile creare ulteriori parole chiave
che possano essere utili, ad esempio per comunicare il massimo numero di
record da restituire o qualsiasi altra direttiva che istruisca lapplicativo
server su cosa e come fare qualcosa.
Il modulo di
gestione dei socket si occuperà essenzialmente di creare i socket
di input/output e di instradare /ricevere i dati. Il blocco forse più
complesso è quello che si occuperà del parsing dei dati.
Il metodo di funzionamento è speculare rispetto a quello del modulo
di creazione della query; infatti, ricevuto uno streaming di dati, il modulo
cercherà delle parole chiave e i dati ad esse associate. Facciamo
anche in questo caso un esempio; supponiamo di ricevere una stringa di
ritorno di questo tipo: Fields: Nome, Cognome, Indirizzo ; Values: Franco,Bassi,via
Po 12 && Mario,Vecchi,via Tevere 8 && Giulio,Antani,via
Arno 1 ; ". Il metodo è lo stesso visto prima, Fields e Values
sono parole chiave, due punti e punto e virgola sono separatori. Abbiamo
aggiunto un ulteriore separatore , &&, come separatore dei record.
La scelta dei separatori può essere arbitraria a seconde delle esigenze;
questo perché potremmo scontrarci con situazioni in cui allinterno
dei record utilizzati ci siano proprio i caratteri da noi scelti come separatori,
il che porterebbe a risultati imprevedibili. Da qui la necessità
di utilizzare o caratteri stravaganti o addirittura sequenze di caratteri
improbabili ( difficilmente un dato di database conterrà sequenze
tipo &&& o $$$). Una volta stabilite le regole di traduzione
della stringa ricevuta, il modulo parser si occuperà di ottenere
una sequenza di dati utilizzabile per la visualizzazione tramite il modulo
di interfaccia utente.
A questo punto
è plausibile una domanda: ma non sarebbe possibile ( e più
semplice) invece di creare un parser, utilizzare il passaggio di dati tramite
oggetti serializzabili, le cui interfacce siano disponibili sia allapplet
sia allapplicativo server ? Sostanzialmente sì , però abbiamo
lo stesso problema che con RMI : compatibilità allindietro con
i browser precedenti. Allinterno di una intranet o extranet, dove si possa
imporre uno standard tecnologico sicuramente non avremmo alcun problema;
potremmo dotare tutti i browser di plugin Java 2 e a quel punto ci potremmo
sbizzarrire in unorgia tecnologica facendo massiccio uso di quello splendido
( e quasi onnipotente) strumento che è JINI, delizia di qualsiasi
sviluppatore Java evoluto
..
Passiamo allapplicativo
server, del quale possiamo vedere i moduli in figura 3.
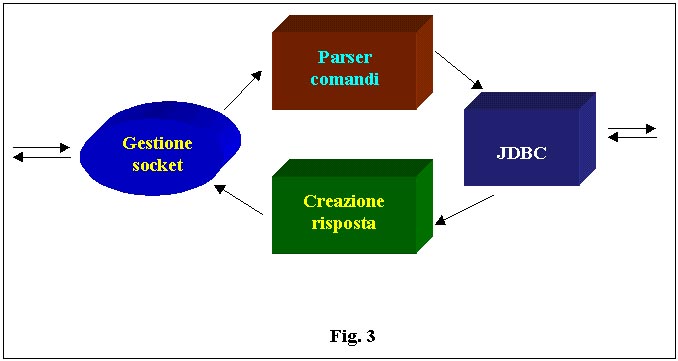 |
Sono evidenti
le analogie con la struttura dellapplet; la gestione dei socket è
quasi la stessa, il parsing viene fatto sui comandi inviati dallapplet
per poter formulare una query che verrà indirizzata al modulo JDBC
e i dati di ritorno verranno assemblati dal modulo creazione risposta
per poi essere instradati allapplet. Valgono anche qui le stesse considerazioni
fatte per lapplet sia in fase di parsing che in fase di creazione dello
streaming di risposta. Il modulo JDBC non fa altro che connettersi al database,
lanciare la query ed ottenere un recordset di risposta.
Unultima nota
sul modulo di gestione dei socket; così come labbiamo delineato
il server è in grado di servire una sola connessione per volta.
Nessun problema: il nostro modulo di gestione del socket provvederà
a creare un thread per ogni richiesta , in modo che possano essere processate
più richieste contemporaneamente.
Conclusioni
Dovremmo aver
toccato tutti i punti che ci servirà esplodere a livello di codice
nella prossima parte dellarticolo. La struttura che abbiamo ipotizzato
è comunque valida per qualsiasi tipo di applet interfacciato con
un application server generico. Utilizzando una grammatica proprietaria
è possibile far fare al server qualsiasi tipo di elaborazione e
poi ottenerne i risultati sullapplet. Non dobbiamo scomodare il registry
rmi , e la soluzione funzionerà su qualsiasi tipo di browser con
supporto Java 1.0.2 ( preistoria !!). Lo so, anche io mi strapperei le
vesti dallo sdegno ogni volta che mi si pongono limiti tecnologici per
mantenere la compatibilità con sistemi dellera mesozoica, però
spesso questo significa anche acquisire una padronanza con meccanismi più
a basso livello del linguaggio utilizzato, e la cosa può non essere
del tutto negativa alla fine, non fosse altro perché ci porta ad
apprezzare di più tutti quegli strumenti che spesso diamo per scontati.
Compitino per
il mese prossimo: ripassiamo bene le varie java.Socket.* e java.util.*,
delle quali faremo massiccio uso nella scrittura del codice sul prossimo
articolo. |

