Introduzione
Quasi tutte
le applicazioni software hanno a che fare con il trattamento dei dati a
prescindere dal linguaggio con cui sono scritte. Per questa ragione Java
è stato presto dotato di una apposita API, detta JDBC, contenuta
nel package java.sql. JDBC è costituito da una serie di interfacce
per l'interrogazione e la manipolazione della base dati e da una classe
DriverManager che gestisce i driver di accesso ai diversi DBMS.
Come vedremo
nel seguito, tutti i driver JDBC hanno una struttura comune
che è
indipendente dal database stesso. Ciò significa che è possibile
realizzare un driver JDBC generico o, in altre parole, una sorta di SDK
che costituisce la base per implementare driver di accesso alle fonti dati
più disparate. Questo è esattamente lo scopo dellarticolo
e come esempio realizzeremo un driver JDBC per Mini SQL. Chi avesse bisogno
di rinfrescare le proprie nozioni JDBC può farlo attraverso [1].
Architettura
di JDBC
La Figura
1 mostra le varie componenti in gioco con JDBC ed è volutamente
ispirata a un precedente articolo su OLE DB [2] apparso sempre su
CP.
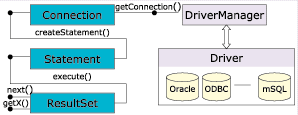 |
Figura 1
- Architettura di JDBC
(Lidea alla
base di questo articolo, infatti, ha diversi punti in comune con larchitettura
OLE DB.) Dalla figura si nota immediatamente una separazione logica piuttosto
netta tra due famiglie di classi: quella di destra riguarda i driver; quella
di sinistra gestisce le connessioni e manipola i dati. DriverManager
crea tutte le connessioni al DBMS utilizzando il driver più adatto
allo scopo. Quando una connessione ha successo esso restituisce al chiamante
un oggetto Connection. Da questo istante è possibile interagire
direttamente con il database, impostando e leggendo le proprietà
della sessione (tipo di transazioni, meta-dati relativi al database) e
creando i vari statement che JDBC consente. Generalmente l'esecuzione
di un'istruzione SQL restituisce un insieme di dati che JDBC vede attraverso
un oggetto ResultSet. Quest'ultimo è corredato di tutti i
metodi necessari per scorrere le righe e ottenere i valori delle colonne.
L'architettura è piuttosto semplice e lineare; l'unico punto un
po' oscuro è il meccanismo mediante il quale DriverManager
individua i driver che sono installati e decide quale tra questi utilizzare.
Durante la propria
inizializzazione, DriverManager carica all'interno della virtual
machine (VM) i driver JDBC elencati dalla proprietà di sistema
jdbc.drivers. Per ognuno di essi crea unistanza e ne memorizza
il riferimento. Questo meccanismo permette di avere sempre a disposizione
i driver JDBC utilizzati dalle proprie applicazioni senza dover scrivere
il codice per caricare un driver piuttosto che un altro. Esiste un secondo
metodo (probabilmente il più utilizzato) che consiste nel caricare
esplicitamente la classe per mezzo del class loader. Generalmente gli oggetti
che implementano java.sql.Driver sono fatti in modo tale per cui
è sufficiente caricare o istanziare la classe per registrare il
riferimento nel DriverManager. L'istruzione seguente, per esempio,
usa il class loader corrente per caricare il driver sun.jdbc.odbc.JdbcOdbc:
Class.forName("sun.jdbc.odbc.JdbcOdbc");
La classe DriverManager
ha anche un'altra importante funzione, cioè quella di instaurare
la connessione con il database. Il servizio è offerto dal metodo
getConnection che nelle sue varie forme richiede di specificare
un URL di connessione. LURL è importante per due motivi: è
linformazione in base a cui viene scelto il driver da utilizzare e specifica
i parametri necessari al driver per aprire la connessione (nome del database,
login, password). DriverManager reagisce a una richiesta di connessione
interrogando tutti i driver noti alla ricerca di quello che può
interpretare correttamente lURL di connessione. Il formato canonico di
un URL di connessione prevede che il protocollo sia "jdbc" e il sottoprotocollo
sia specifico per ogni driver; per esempio il driver JdbcOdbcDriver
risponde allURL:
jdbc:odbc:<DSN>
dove <DSN> è
un Data Source Name ODBC di sistema associato al database. Per esempio:
DriverManager.getConnection("jdbc:odbc:miodb");
Le interfacce
di JDBC
Per quanto riguarda
il ruolo delle varie interfacce di JDBC, la Figura 1 è già
sufficientemente esplicativa. Quando un programma chiede al driver manager
di aprire una connessione, questo invoca il metodo connect del driver.
La classe concreta dell'oggetto Connection restituito deve essere
realizzata dal produttore del driver in base alle specifiche del database;
infatti questo è l'oggetto che incapsula la "conoscenza" di come
interfacciarsi con il DBMS e che mantiene il riferimento alla connessione
aperta. Per esempio potrà utilizzare metodi nativi realizzati sulla
base della API di programmazione del database o, in un ambiente client/server,
aprire una connessione TCP/IP con il server di database. Per espletare
i servizi propri dell'interfaccia Connection, una classe deve implementare
diversi metodi, che è possibile suddividere in tre gruppi:
-
Gestione delle transazioni
-
Creazione degli
statement
-
Interrogazioni e
modifiche dello stato della connessione
Alla prima categoria
appartengono commit, getAutoCommit, rollback, getTransactionIsolation,
setAutoCommit, setTransactionIsolation. La trattazione di
questi metodi esula dagli scopi di questo lavoro e quindi non verranno
ulteriormente approfonditi.
Fanno parte
della categoria b) le funzioni createStatement, nativeSQL,
prepareCall, prepareStatement. Per semplicità nel
seguito considererò la sola createStatement. Infine, nella
categoria c) si trovano clearWarnings, close, getCatalog,
getMetaData, getWarnings, isClose, isReadOnly,
setCatalog, setReadOnly. Di questi tratterò i più
importanti.
I metodi getMetaData
e createStatement hanno una valenza particolare. Il primo fornisce
un oggetto DatabaseMetaData. Questa classe deve fornire tutte le
informazioni che riguardano le caratteristiche del DBMS. Per esempio si
può interrogare un oggetto di questo tipo per conoscere se il motore
SQL supporta le stored procedure o se permette di eseguire certi tipi di
query o ancora per conoscere le tabelle presenti in un particolare database.
Naturalmente una classe DatabaseMetaData non può che essere
specifica per ogni sorgente dati.
Più interessante
è, invece, createStatement perché fornisce un oggetto
che implementa l'interfaccia Statement. Questa è utilizzata
per l'esecuzione dei comandi SQL e per la restituzione dei risultati in
forma di ResultSet. Naturalmente la realizzazione completa di un
oggetto Statement è ancora a carico di chi crea il driver;
tuttavia si noti che questa classe non deve interagire con il DBMS se non
per comandare l'esecuzione di una query, dopodiché deve semplicemente
occuparsi di gestire in modo opportuno altri oggetti di "alto livello",
ossia i ResultSet. Sono infatti questi ultimi che restituiscono
i dati, indipendentemente dall'implementazione di Statement. Una
classe che realizzi ResultSet deve avere diversi metodi che possono
ancora una volta essere suddivisi come segue:
-
Metodi per
lo "scorrimento" delle righe del risultato
-
Metodi per
l'estrazione del valore delle colonne di una riga
L'interfaccia ResultSet
rappresenta due entità nello stesso momento: da un lato è
il corrispettivo JDBC di un cursore di database, cioè di un puntatore
alla riga corrente di un insieme di dati in forma tabellare; dall'altro
astrae il concetto di "riga" della tabella risultante, che può essere
interrogata campo per campo per ottenere i valori di ogni colonna. Come
cursore, un oggetto ResultSet deve implementare i metodi di tipo
a) next e close. Come riga deve invece implementare quelli
di categoria b), cioè la lunga serie di funzioni getXXX.
Ancora una volta si può notare che l'interazione con il database
è necessaria solo per le funzioni di tipo a); al contrario le altre,
una volta ottenuta e memorizzata la riga corrente, non hanno alcun bisogno
di interagire con il motore SQL.
Come un database
fornisce dei meta-dati per descriversi, così a ogni ResultSet
è associato un ResultSetMetaData che dà informazioni
su come è fatta la tabella risultante: numero di campi, tipo, dimensione.
Il fatto che il Resultset sia creato da un database piuttosto che da un
altro, da questo punto di vista, è del tutto irrilevante. Supponendo
di partire da tabelle identiche, risultati uguali creati da database diversi
hanno comunque la stessa struttura e quindi possono avere la medesima descrizione.
Un'ulteriore
considerazione riguarda gli aspetti di multithreading di Java. Dall'architettura
presa in esame si ha piena libertà di implementazione, ma realizzare
un driver JDBC non thread-safe ne limiterebbe fortemente l'utilizzo e l'utilità.
Ancora una volta, però, tutte le problematiche di sincronizzazione
di accesso di più thread alle risorse condivise dagli oggetti Connection,
Statement, ResultSet sono prettamente dominio di Java e non
del DBMS. In altre parole, la gestione della concorrenza sugli oggetti
che costituiscono un driver JDBC può essere affrontata in modo generico
e non dipendente dal database.
Architettura
di un driver JDBC generico
Sulla base di
queste analisi possiamo delineare unarchitettura più generale per
i driver JDBC che sia più svincolata dal DBMS a cui fanno riferimento.
Da questa si può poi partire per creare driver per le fonti dati
più diverse. Un altro modo di vedere la cosa consiste nel considerare
questo driver come un SDK: da solo non è molto utile, ma fornisce
una base per realizzare più velocemente le componenti software per
le quali è pensato. In quest'ottica, i requisiti del JDBC SDK sono
i seguenti:
-
Realizzare un framework
che implementi la maggior parte delle specifiche di JDBC in modo indipendente
dal database;
-
Essere thread-safe;
-
Mantenere la semplicità
e la flessibilità di JDBC;
-
Essere facilmente
estendibile (per realizzare un driver JDBC completo deve essere sufficiente
implementare poche classi e non tutte quelle delle specifiche JDBC).
Una possibile architettura
per realizzare gli obbiettivi preposti è quella illustrata in Figura
2.
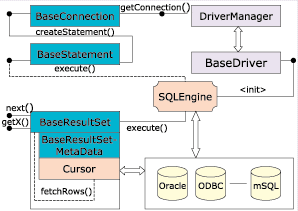 |
Figura
2 -
Architettura del JDBC SDK
Lo scopo principale
è quello di isolare l'accesso ai dati dal modello di dati astratto
realizzato dalle classi di JDBC. Il modello di dati viene realizzato una
volta per tutte e si occupa di implementare le specifiche JDBC che riguardano
la gestione delle connessioni, degli statement e dei resultset, nonché
la restituzione dei dati e dei meta-dati. Tutto questo deve essere realizzato
avendo cura degli aspetti di multithreading.
L'elemento centrale
di questa strategia è l'oggetto SQLEngine che realizza lo
strato intermedio di cui sopra e che fornisce la "vista" SQL della sorgente
dati. Questa classe
deve permettere
di:
-
Aprire e chiudere
una connessione al database;
-
Eseguire statement
SQL;
-
Ottenere le proprietà
di connessione;
-
Ottenere i meta-dati
del database.
Tali compiti sono
codificati nella definizione dell'interfaccia SQLEngine come è
possibile osservare dal Listato 1.
A seconda del tipo di JDBC driver che si vuole realizzare i metodi di SQLEngine
possono essere nativi, completamente in Java o un mix tra i due.
Una seconda
e ultima componente intermedia introdotta dall'SDK è l'interfaccia
Cursor (Listato 2). Questa rappresenta
il comportamento di un cursore di database e viene creata quando l'esecuzione
di una query restituisce un risultato in forma tabellare. L'introduzione
di questo elemento rende meno ambiguo il ruolo di ResultSet in quanto
separa le funzioni di interrogazione dei valori delle colonne della riga
corrente dalla gestione dell'insieme delle righe. In questo modello un
ResultSet è costituito da due elementi: un ResultSetMetaData
che descrive la struttura della tabella e un Cursor che permette
di ottenere le singole righe del risultato. Queste ultime sono incapsulate
in un oggetto di tipo BaseRow avente il compito di nascondere la
struttura dati di memorizzazione dei valori delle colonne di una riga e
di esporre i metodi per estrarli.
Vediamo adesso
il ruolo delle classi del package ste.jdbc.SDK.
JDBC SDK
La realizzazione
di un driver JDBC comporta l'implementazione di diverse interfacce del
package java.sql. Un driver minimale, come quello presentato in
questo articolo, deve creare le classi per almeno le seguenti interfacce:
Driver, Connection, Statement, ResultSet, DatabaseMetaData,
ResultSetMetaData. Data la mole di codice, non è possibile
entrare nel dettaglio delle singole classi e quindi si rimanda ai sorgenti
disponibili sul sito FTP di Infomedia.
Le classi facenti
parte dell'SDK sono generalmente identificate dal prefisso "Base" (BaseDriver,
BaseConnection, BaseStatement ecc.) a indicare che sono i
mattoncini basilari con i quali costruire i propri driver.
È fondamentale
l'installazione del driver. Come già detto, esso si deve "presentare"
al driver manager non appena la classe è caricata nella VM, quindi
le istruzioni di caricamento devono essere poste all'interno di un blocco
di codice di inizializzazione "di classe". Con questa espressione si intende
la parte di codice compresa nello scope di un modificatore static,
ma all'esterno di tutti i metodi. La registrazione del driver avviene grazie
al metodo DriverManager.registerDriver:
public
class BaseDriver implements java.sql.Driver {
...
static
{
try {
DriverManager.registerDriver(new BaseDriver());
}
catch (Exception e) {
/* non può generare eccezioni */
}
}
}
Tra i metodi che
un oggetto Driver deve possedere, i più interessanti sono
acceptsURL e connect. Entrambi sono invocati da DriverManager
quando un programma richiede una connessione al database. L'identificazione
di una risorsa viene effettuata attraverso un URL. acceptsURL deve
verificare se lURL utilizzato per la connessione è in forma comprensibile
dal driver in questione e di conseguenza restituire true o false.
Se il driver manager ottiene una risposta negativa cercherà un altro
driver che possa gestire tale tipo di connessione. Nel caso di BaseDriver,
lURL ha la sintassi:
jdbc:jdbcSDK:<sqlengine>:<parametro1>=<valore>:...:<parametroN>=valore
e quindi
public
boolean acceptsURL(String url) {
return url.startsWith("jdbc:jdbcSDK:");
}
Il driver
manager invoca connect quando acceptsURL restituisce true
e riceve in ingresso lURL di connessione e un oggetto Properties
contenente eventuali proprietà fornite esplicitamente da getConnection.
A queste si devono aggiungere quelle specificate nellURL dalle coppie
<parametro>=<valore>. Inoltre, tra le proprietà incluse di
default da DriverManager nel parametro prpInfo ci sono, se
si usa la chiamata getConnection(URL, user, password), anche lo
username e la password dell'utente con cui l'applicazione si deve presentare
al database server.
Oltre a ciò,
il metodo connect di BaseDriver crea l'oggetto SQLEngine
che finalmente apre la connessione:
public
Connection connect(String stURL, Properties prpInfo) throws SQLException
{
try
{
parseURL(stURL, prpInfo);
}
catch
(MalformedURLWarning muw) {
return null;
}
Class
cls = null; Connection c = null;
try
{
cls = Class.forName(prpInfo.getProperty("source", ""));
SQLEngine sql = (SQLEngine)cls.newInstance();
c = (Connection)sql.connect(prpInfo);
}
catch
(Exception e) { ... }
return
c;
}
Come si vede,
il motore SQL della sorgente dati viene caricato dinamicamente a partire
dal nome della classe. Di fatto, ciò rende indipendente BaseDriver
dalla realizzazione dei metodi di accesso al database che vengono forniti
da una specifica implementazione dell'interfaccia SQLEngine.
Il metodo connect
di SQLEngine deve costruire e restituire un oggetto Connection
che descriva lo stato e le caratteristiche della connessione. Per facilitare
il programmatore, il JDBC SDK ne fornisce una versione pronta all'uso:
BaseConnection. Questa memorizza le proprietà della connessione
e il riferimento all'istanza di SQLEngine che viene utilizzato dai
metodi che interagiscono con il DBMS. Tra questi vi sono i già citati
createStatement() e getMetaData():
public
Statement createStatement() throws SQLException {
return (Statement)new BaseStatement(sql);
}
public
DatabaseMetaData getMetaData() throws SQLException {
return (DatabaseMetaData)sql.getMetaData();
}
Una volta
creato un BaseStatement, questo può essere utilizzato per
eseguire uno o più comandi SQL. È possibile che più
thread di uno stesso programma condividano la stessa istanza di un oggetto
BaseStatement. Inoltre lo stesso oggetto può essere utilizzato
più volte per eseguire query diverse. Per questo BaseStatement
possiede il flag fOccupato che indica che l'oggetto in questione
ha già eseguito una query e i Resultset contenuti nell'array ars
ne costituiscono i risultati. Tali dati vengono liberati alla chiusura
del Resultset.
I metodi per
eseguire gli statement SQL sono executeQuery, executeUpdate
ed execute tutti basati sul metodo execute di SQLEngine.
Uno statement SQL può fornire uno o più risultati nel caso
di executeQuery o il numero di righe interessate dal comando nel
caso di executeUpdate. In entrambi i casi si impostano opportunamente
i valori di ars e iContaRS che vengono poi utilizzati da
getMoreResults, getResultSet, getUpdateCount. I metodi
executeXXX ricevono in ingresso la query da eseguire sotto forma
di stringa. Tale stringa viene passata così comè al motore
SQL. Anche per l'interfaccia ResultSet il JDBC SDK mette a disposizione
una versione base della classe: BaseResultSet. Un Resultset può
essere visto come un ResultSetMetaData associato a un Cursor.
Cursor scorre le righe del result set restituendo quella corrente
attraverso un'operazione di fetch. In realtà, per motivi di efficienza,
molti database permettono di ottenere più righe del risultato con
una sola operazione di fetch. Per questo il metodo fetchRows di
Cursor restituisce un array di righe sotto forma di oggetti BaseRow
anziché una singola riga. Questi oggetti vengono memorizzati nell'apposito
array righe di BaseResultSet così da poter essere
acceduti singolarmente mediante il contatore iRigaCorrente. Il metodo
che permette di scorrere le righe è next:
public
synchronized boolean next() throws SQLException {
if ((iRigaCorrente+1) == righe.length) {
righe = cursore.fetchRows();
iRigaCorrente = -1;
}
++iRigaCorrente;
return (righe.length > iRigaCorrente);
}
next
esegue il fetch solo se l'ultima riga recuperata è l'ultima riga
nel buffer, mentre se fetchRows restituisce un array di dimensione
0 significa che non ci sono più righe.
BaseResultSet,
come tutte le classi di tipo ResultSet, possiede numerosi metodi
getXXX per l'estrazione dei valori delle singole colonne della riga
corrente. Questi non fanno altro che invocare l'analogo metodo dell'oggetto
BaseRow. Per esempio, per ottenere un valore sottoforma di stringa
si usa getString:
public
synchronized String getString(int columnIndex) throws SQLException {
valida(); // il result set e' valido ?
return righe[iRigaCorrente].getString(columnIndex);
}
Un'ultima
importante funzionalità di BaseResultSet è quella
di fornire i meta-dati del result set. Di questo si occupa getMetaData
che non fa altro che restituire l'oggetto ResultSetMetaData fornito
al costruttore. Ancora una volta il JDBC SDK offre un'implementazione di
base di questa classe. Essa è utilizzabile per realizzare SQLEngine
senza nessuna modifica. Infatti non si avvale di funzionalità specifiche
di un database, ma si basa su una descrizione della tabella in termini
di oggetti BaseColumn. In pratica, per rappresentare l'intestazione
del Resultset impiega un array di oggetti BaseColumn, ognuno dei
quali ha tutte le informazioni utili per descrivere un singolo campo della
tabella, cioè nome, etichetta, dimensione di visualizzazione, tipo,
precisione e scala, schema e tabella di appartenenza, attributi.
A questo punto
la domanda è: "Cosa devo fare per realizzare un JDBC driver?"
Basta implementare tre interfacce: SQLEngine, Cursor e DatabaseMetaData.
Nel paragrafo seguente ne verrà data prova concreta realizzando
un driver JDBC per accedere a database Mini SQL.
Un driver
JDBC per Mini SQL
Mini SQL, o
come spesso viene chiamato mSQL, è un DBMS relazionale studiato
per accedere velocemente a dati relazionali, con il minor overhead di sistema
possibile. Esso è costituito da un server al quale le applicazioni
client si possono connettere via socket TCP/IP. mSQL è disponibile
su varie piattaforme tra cui Unix, Windows e OS/2. Maggiori informazioni
sono su www.hughes.com.au.
Il driver di
questo esempio utilizza l'API nativa di mSQL per accedere al DBMS ed è
quindi un quasi-JDBC driver di livello 2. Dico "quasi-JDBC" perché
per conformarsi pienamente alle specifiche, anche il database deve possedere
determinate caratteristiche di base che mSQL non possiede. Inoltre, questa
versione dell'SDK non include alcune specifiche JDBC come i prepared e
i callable statement. Le classi che costituiscono il JDBC driver per mSQL
sono: mSQLEngine, mSQLCursor, mSQLDatabaseMetaData.
Tra queste, l'ultima è la più semplice perché richiede
la realizzazione di una serie di metodi che forniscono informazioni specifiche
sul database. Conoscendo le caratteristiche del database non ci sono particolari
problemi.
La classe mSQLEngine
implementa SQLEngine e quindi realizza lo strato di collegamento
con il DBMS. Oltre a fornire l'implementazione dei metodi dell'interfaccia
(connect, close, execute, getConnectionParameter,
getMetaData), essa fornisce alcuni metodi aggiuntivi di utilità
generale, utilizzati anche da mSQLDatabaseMetaData. Tra questi,
listDB elenca tutti i database presenti, get/setDB restituisce/imposta
il database corrente, listTables restituisce la lista delle tabelle
presenti nel database corrente, listFields fornisce i campi di una
tabella.
Per usare il
driver all'interno del proprio programma basta utilizzare la giusta URL
di connessione:
Connection
conn = null;
String
url = "jdbc:jdbcSDK:ste.jdbc.msql.mSQLEngine:db=test";
try {
conn = DriverManager.getConnection(url, "ste", "stepwd");
}
catch
(Exception e) {
e.printStackTrace();
}
finally
{
if (conn != null) conn.close();
}
Il driver
mSQL richiede che si specifichi nella stringa di connessione il database
sul quale si vuole lavorare (db=test), mentre le informazioni di login
vengono fornite direttamente al metodo getConnection.
In Figura
3 si può vedere il driver all'opera con una semplice applicazione
di esempio fornita con swing (eseguita in ambiente OS/2 Warp con
IBM JVM), la nuova API di componenti GUI che verrà inclusa nella
JDK 1.2.
 |
Figura
3 -
Esempio di utilizzo del driver JDBC per mSQL con swing
Conclusioni
Il semplice
framework presentato in queste colonne è sicuramente a uno stadio
embrionale, ma permette già di realizzare un JDBC driver scrivendo
un numero relativamente basso di linee di codice. Ci si potrebbe chiedere
quale sia l'utilità di creare driver JDBC dal momento che molti
costruttori di database ne forniscono la loro versione ufficiale. Il punto
fondamentale è che non è necessario che un driver JDBC acceda
a un DBMS vero e proprio. In questo articolo si è mostrata la semplicità
con cui si può costruire un driver per l'accesso a svariate fonti
dati. L'unico vincolo è che i dati possano essere rappresentati
in forma tabellare e che si abbia un linguaggio di interrogazione per manipolarli.
Ciò è particolarmente interessante in quanto non è
affatto necessario che tale linguaggio sia un vero e proprio SQL. Il metodo
execute di SQLEngine può, in verità, utilizzare
un proprio parser per interpretare il comando e restituire Resultset. Questo
rende estremamente flessibile il modello di accesso ai dati basato su JDBC,
pur mantenendo un elevato grado di semplicità.
Bibliografia
[1] Michele
Sciabarrà - "Java: il JDBC", Computer Programming, Settembre
1997
[2] Natale Fino
- "Architettura di OLE DB: verso l'accesso unificato ai dati", Computer
Programming, Febbraio 1998
|

