Introduzione
Considerati i molteplici aspetti
coinvolti in questa fase del ciclo di vita del software, e la sua incidenza
sul processo di sviluppo, si è ritenuto opportuno affrontare largomento
in più parti (Dividi Et Impera). In questa prima parte, si focalizzerà
lattenzione sullaspetto statico della Design View, ossia sulle classi,
gli oggetti e le relative relazioni: in poche parole, sui Class Diagram
(diagrammi delle classi).
Sebbene si sia tentato di illustrare
largomento nel modo più semplice possibile, senza dar nulla per
scontato, è opportuno tener presente che il disegno di un sistema
è unattività complessa, la quale richiede una gran quantità
di decisioni che, molto probabilmente, è la più elevata di
qualsiasi altra vista.
Le difficoltà che si incontrano
non sono tanto dovute allUML quanto alla complessità intrinseca
del processo di disegno. Per tanto, è necessario essere consapevoli
che per essere in grado utilizzare proficuamente un linguaggio di progettazione
Object Oriented, quale che sia, è assolutamente indispensabile possedere
una buona padronanza dellargomento. Padronanza che si ottiene con anni
dedicati allo studio e sviluppo di sistemi O. O.
Purtroppo, lesperienza maturata
in settori diversi, non è di grande aiuto. Quando si intraprende
il viaggio verso un nuovo mondo, un nuovo modo di pensare le astrazioni
è necessario modificare i propri schemi mentali iniziando dalla
base: lo studio delle esperienze altrui (libri, libri e poi libri!). Spesso
si verifica che sedicenti tecnici, allo scuro dei principi più basilari
del mondo dellObject Oriented (incapsulamento, ereditarietà, classi
astratte, interfacce, over-loading, overriding, ecc.), si lancino in analisi
O. O. di sistemi informatici: come pretendere che una persona, priva di
dimestichezza con il cambio delle marce, guidi una macchina di formula
uno, oppure che un palazzo venga progettato da un tecnico non a conoscenza
dei calcoli sul cemento armato. Ebbene, nel mondo dellinformatica in Italia,
non è infrequente che gli edifici crollino
Ma tanto si vive nel
paese in cui non esistono mai responsabilità, basta rivolgersi alle
persone giuste, oppure traccheggiare con il cliente ed il problema è
risolto. Come affermano in molti, limportante è curare lesteriorità:
il cliente tende a valutare ciò che riesce a vedere
Molto grossolanamente, si dimentica
che, se è vero, che è la parte esterna a generare laffermazione
iniziale del sistema, è altresì vero che è la sua
struttura interna a determinarne il successo nel tempo. Ma quante persone,
quanti sedicenti project manager sono veramente in grado di capire la bontà
dellorganizzazione interna di un sistema, specie se è O. O.? Lesperienza
reale insegna ad aver terrore di coloro che si proclamano espertissimi,
per i quali tutto è semplice: leccessiva minimizzazione di un problema,
spesso, molto, è tristemente frutto di grande incompetenza!
Design view
La Design View (spesso indicata
anche con il nome di Logical View) è la vista dedicata alle soluzione
tecniche: ambiente naturale di analisti (designer) e programmatori. Dopo
aver lungamente argomentato le funzionalità che il sistema dovrà
realizzare, finalmente ci si concentra su come ottenerle. Da questo punto
di vista, la Design View si contrappone alla Use Case View, in quanto
si guarda il sistema al suo interno, e non lo si considera più
come una scatola nera.
I risultati del processo di analisi
sono tradotti in soluzioni tecniche a bassissimo livello di astrazione,
nelle quali sono condensate sia la struttura statica, sia le collaborazioni
dinamiche del sistema.
Si assiste, dunque, al proliferare
di oggetti informatici, come classi, interfacce, gestori di data base,
ecc.
Le classi dominio del processo
di analisi vengono incastrate in una serie di infrastrutture tecniche,
che rendono possibile realizzare quando stabilito nella Use Case View.
I risultati di questa vista forniscono
la descrizione analitica dellarchitettura software del sistema e, pertanto,
rappresentano il dettaglio delle specifiche per la fase di codifica.
Sebbene esuli completamente dagli
intenti del presente articolo illustrare il paradigma della progettazione
orientata agli oggetti (ci vorrebbe una serie di articoli solo per questo
argomento), si ritiene opportuno riportare un minimo di teoria al fine
di dare la possibilità anche alle persone con minore esperienza
nel settore di poter comprendere quanto riportato.
Oggetti
Un oggetto è un qualcosa
di tangibile che esiste nel mondo reale (o meglio, nella relativa conoscenza
individuale) e, come tale, se ne può parlare, lo si può toccare
o manipolare in qualche modo.
Un oggetto può essere una
parte di un qualsiasi sistema meccanico, organizzativo, industriale, ecc.
Oltre agli oggetti strettamente
materiali, esiste poi tutta unaltra categoria che, pur non esistendo apertamente
nel mondo reale (si provi ad immaginare a cosa si stia facendo riferimento),
possono essere visti come derivati da specifici oggetti reali attraverso
lo studio delle strutture e dei comportamenti,.
Tutti gli oggetti sono istanze
di classi, ove per classe si intende un qualcosa che consenta di descrivere
le proprietà ed il comportamento di tutta una categoria di oggetti
simili.
Si può immaginare il rapporto
che intercorre tra un oggetto e la relativa classe come quello esistente
tra una variabile ed il relativo tipo, in un qualsivoglia linguaggio di
programmazione.
Banalizzando estremamente, con
tutte le inesattezze del caso, si può pensare alle classi come stampino
per statue ed agli oggetti come le statua ottenute.
In questa banale similitudine,
si trascura che anche limpasto ha il suo peso, ma limportante è
cercare di spiegarsi.
Classi
Nellambito della realizzazione
di modelli O. O., classi, oggetti e relative relazioni sono gli elementi
principali.
In particolare, le classi e gli
oggetti permettono di descrivere cosa cè allinterno del sistema,
mentre le relazioni consentono di evidenziarne lorganizzazione.
Una classe è una descrizione
di un insieme di oggetti che condividono gli stessi attributi, operazioni,
relazioni e semantica.
Graficamente è rappresentata
per mezzo di un rettangolo suddiviso in tre sezioni, rispettivamente: il
nome, gli attributi, le operazioni.
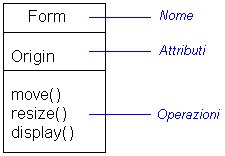 |
Figura
1. Rappresentazione grafica di una classe.
Il nome della classe può
essere semplice, come lesempio riportato in Figura. 1, oppure corredato
dai nomi dei package a cui appartiene dal percorso (path name). Un esempio
di nome esteso potrebbe essere: java::util.::Vector, oppure MyApp::Connection::DataModule.
Tipicamente, il nome di una classe
dovrebbe essere o un sostantivo oppure unespressione appartenente al vocabolario
del sistema che si sta modellando. Le convenzioni impongono che i nomi
di classi siano scritti con le lettere iniziali maiuscole (capitalized).
Per esempio: Cliente, Radar, SensoreDiTemperatura, ecc.
Un attributo è una proprietà
della classe, identificata da un nome, che descrive un intervallo di valori
che le relative istanze possono assumere. Una classe può non avere
attributi o averne un numero qualsiasi. Quando però, il numero degli
attributi supera lordine delle decine, potrebbe essere il caso di verificare
che non si siano inglobate più classi in una sola.
Esempi di attributi sono il colore
di un oggetto grafico, la data di nascita di un impiegato, le dimensioni
di una ruota, e così via.
Un attributo è, a sua volta,
unastrazione di un tipo di dato o di stato che un oggetto di una classe
può assumere.
Per ciò che concerne le
convenzioni sul nome degli attributi, valgono le stesse regole riportate
per i nomi delle classi, con la sola eccezione che la prima lettera viene
scritta in minuscolo.
Spesso, nellattribuire i nomi
alle proprietà, si utilizzata la famosa notazione ungarese (in
onore del programmatore della Microsoft Charles Simonyi
Quel che è
giusto è giusto) che prevede di inserire un prefisso al nome degli
attributi indicante il tipo.
Per esempio, ci si potrebbe riferire
alla matricola di un impiegato con il nome sMatricola, dove il prefisso
s indica che si tratta di una stringa, oppure, il peso di oggetto potrebbe
essere indicato come iPesoOggetto, dove il prefisso i indica che si
tratta di un intero e così via.
Di un attributo è possibile
indicare solo il nome, oppure il nome ed il tipo, oppure la precedente
coppia corredata da un valore iniziale.
Unoperazione può essere
considerata come la trasposizione, in termini informatici, di un servizio
che può essere richiesto da ogni istanza di una classe per modificarne
il comportamento. Pertanto, una operazione (metodo) è unastrazione
di qualcosa che può essere eseguito su tutti gli oggetti di una
classe.
Alcuni esempi di metodi sono isEmpty(),
move(), addElement(), ecc.
Una classe può non disporre
di alcun metodo, oppure averne un numero qualsiasi. Come nel caso degli
attributi, qualora il numero dei metodi superi lordine delle decine è
consigliabile verificare se sia il caso di suddividerla in più classi
di dimensioni ridotte, specializzate
per un singolo compito. Questo modo
di pensare, entro i limiti della razionalità, favorisce la riusabilità
del codice.
Per ciò che concerne le
convenzioni sul nome dei metodi, essi dovrebbero essere costituiti da brevi
frasi contenenti dei verbi che rappresentano qualche comportamento o funzionalità
della classe di appartenenza. La convenzione sul modo di scriverli rispecchia
pienamente quella degli attributi: la prima lettera in minuscolo ed il
resto capitalizzato.
Quando si disegna una classe, non
è assolutamente necessario riportarne tutti gli attributi e/o tutti
i metodi; molto spesso essi sono in numero così considerevole che
non ci sarebbe neanche lo spazio fisico. Ovviamente, è sufficiente
riportare quelli ritenuti più significativi; se poi una sezione
è vuota, ciò non significa che la classe sia priva di metodi
o attributi. Quando non si vogliono specificare gli eleemnti di una sezione,
al fine di evitare ogni possibile ambiguità, è sufficiente
riportare tre puntini..
Se poi, uno degli elenchi (proprietà
o metodi) risulti piuttosto ampio, è possibile organizzare i relativi
elementi introducendo opportuni stereotipi (a proposito dei stereotipi
vedere [6]), come riportato in figura 2.
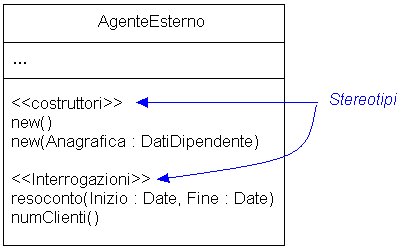 |
Figura
2. Utilizzo degli stereotipi per organizzare lelenco dei metodi di
una classe.
Ai metodi e proprietà presenti
in una classe è possibile illustrarne la visibilità. Essa
specifica se lattributo/metodo è accessibile/invocabile da oggetti
di altre classi.
Le principali tipologie di visibilità
sono 3, e sono:
-
pubblica: lattributo/metodo
è accessibile da qualsiasi altro oggetto che possiede un riferimento
alloggetto che lo contiene;
-
privata: lattributo/metodo
è accessibile solo allinterno della rispettiva classe;
-
protetto: lattributo/metodo
è accessibile da tutte le classi che ereditano da quella che lo
contiene.
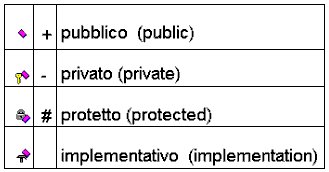 |
Figura 3.
Schema della visibilità dei metodi/proprietà. Nella prima
colonna vi è la
nomenclatura Rational,mentre
nella seconda è illustrata quella standard.
E appena il caso di ricordare che,
nel caso degli attributi, la visibilità pubblica va utilizzata assolutamente
con parsimonia. Facendo riferimento ai principi dellInformation Hiding
e dellIncapsulamento, si ricorda che è necessario che gli attributi
siano manipolati dalle classi proprietarie, giacché esse dovrebbero
essere le uniche a conoscerne la logica; spesso, lattribuzione di un valore
ad un attributo genera la necessità di eseguire una serie di azioni.
Sempre valide sono poi le regole della massima coesione, minimo accoppiamento,
ecc.
Interfacce
Uninterfaccia è una collezione
di operazioni che specificano un servizio generale fornito da una classe
o da un componente. Pertanto esse esprimono il comportamento, parziale
o totale, di un elemento così come è percepito dallesterno.
Da un punto di vista realizzativo,
uninterfaccia è costituita da un insieme di dichiarazione di metodi,
dei quali non viene assolutamente fornita limplentazione. Ne segue che
uninterfaccia non può essere istanziata direttamente; deve necessariamente
esistere una classe che la implementi, la quale ne realizza in comportamento
descritto e quindi può essere istanziata.
Nel linguaggio UML, uninterfaccia
viene rappresentata tramite un cerchio con vicino il nome; nulla vieta
però di rappresentarla come una normale classe.
Limportanza delle interfacce è
che consentendo di stabilire il comportamento degli oggetti, rendono possibile
lo sviluppo parallelo, consentono di trattare un insieme di classi (quelle
che la implementano) in modo del tutto astratto, forniscono le basi per
produrre dei protocolli di comunicazione ecc..
Relazioni
Quando si costruiscono i diagrammi
delle classi, accade molto raramente che le entità coinvolte siano
destinate a rimanere isolate. Tipicamente, tutte le classi identificate
sono connesse con altre secondo precisi criteri. Dunque, quando si modella
un sistema, non è sufficiente identificare le classi di cui è
composto, ma è altresì necessario individuare anche le eventuali
relazioni che le legano tra loro.
Nel mondo Object Oriented, tutte
le relazioni possono essere facilmente ricondotte ai tre tipi fondamentali,
che come tali risultano particolarmente importanti, e sono: dipendenza,
generalizzazione e associazione.
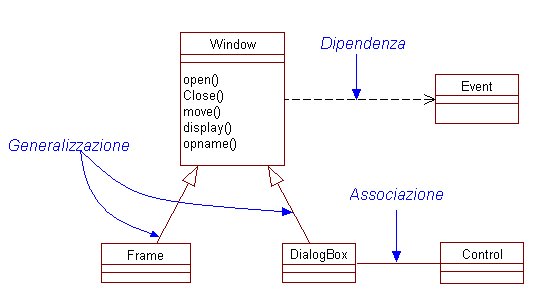 |
Figura
4. Relazioni fondamentali
Ognuna di esse fornisce un criterio
diverso per organizzare le proprie astrazioni, in particolare, una relazione
di dipendenza tra due classi indica che la variazione dello stato di un
oggetto istanza della classe indipendente implica, necessariamente, un
cambiamento di stato nelloggetto istanza della classe dipendente. Per
esempio, nel diagramma in figura 4, la relazione di dipendenza che lega
la classe Window alla classe Event, indica che un cambiamento di stao
delloggetto Event genera un aggiornamento delloggetto Window che
lo utilizza, mentre non è vero il viceversa.
Una relazione di generalizzazione
indica un legame tra una classe generale (denominata super-class o parent),
ed una sua versione più specifica (denominata subclass o childclass).
Pertanto, una classe figlio, specializza il comportamento di quella padre.
Sempre con riferimento alla figura 4, si può notare come la classe
DialogBox va ad aggiungere comportamento specifico alla classe padre
Window.
La relazione di associazione, infine
indica che un oggetto di una classe è connesso ad un altro.
Possono esistere associazioni tra
oggetti di classi diverse, così come tra oggetti della stessa classe
(Self-association).
In figura 4 si vede come un oggetto
DialogBox è associato ad un oggetto Control che ne gestisce
il funzionamento.
Organizzare la struttura interna
del sistema è unoperazione assolutamente complessa e delicata,
in cui lesperienza gioca un ruolo importantissimo. Si ricordi che il successo
nel tempo di un SW, è fortemente legato alla sua struttura interna.
Benché non esistano regole ben precise, si consiglia di prestare
molta attenzione a non commettere gli errori di progettazione noti nella
letteratura informatica con il nome di Over e Under-engineering.
Il primo caso deriva da unorganizzazione
eccessivamente articolata (vedi ingarbugliata/confusionaria) della struttura
interna, che, in ultima analisi, finisce per rendere il modello assolutamente
incomprensibile.
Il secondo problema, chiaramente
in antitesi al primo, è frutto di unanalisi piuttosto approssimativa
eseguita trascurando molti dettagli. Leccessiva superficialità
finisce per rendere incomprensibili le modalità di collaborazione
tra le varie classi.
La necessità e le modalità
che permettono di realizzare sistemi ben bilanciati, sono attitudini che,
ahimè, solo chi ha una ben consolidata esperienza sul campo di
battaglia può capire e quindi attuare.
Dipendenza
Una relazione di dipendenza è
una connessione semantica tra due oggetti di un modello, di cui uno è
lelemento indipendente mentre laltro è quello dipendente. Come
ne suggerisce il nome, essa indica che un cambiamento dello stato dellelemento
indipendente genera degli effetti su quello dipendente. Questi elementi
possono essere Packages, classi, Use Case, ecc.
Un esempio di dipendenza si ha
quando una classe prevede come parametro un oggetto di unaltra classe,
oppure ne accede ad un oggetto, oppure ne invoca un metodo. In tutti questi
casi, esiste una evidente dipendenza tra le classi, sebbene non ci sia
unesplicita associazione.
Graficamente, una relazione di
dipendenza è rappresentata per mezzo di una linea tratteggiata con
una freccia rivolta verso la classe indipendente.
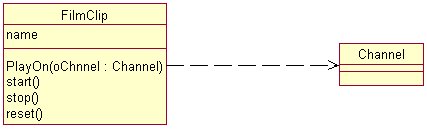 |
Figura
5 Esempio di relazione di dipendenza.
La figura 5 mostra una relazione
di dipendenza tra la classe FilmClip e la classe Channel. Si può
notare che il metodo PlayOn, necessita come parametro, un oggetto di
tipo Channel; ciò genera unevidente dipendenza tra le classi
sebbene non via esista un legame di associazione tra le stesse.
Alle relazioni di dipendenza può
essere associato un nome per poterle individuare e quindi distinguere più
semplicemente.
La tipologia di relazione di dipendenza
più frequente è sicuramente quella che prevede che il riferimento
ad un oggetto venga fornito come parametro ad un metodo di unaltro oggetto.
In casi di questo tipo, se i metodi delle classi vengono forniti con la
segnatura completa, è possibile evitare la visualizzazione graficamente
la relazione.
Generalizzazione
Una relazione di generalizzazione
lega un oggetto generale (detto super-class o parent ) ad uno più
specifico (detto sub-class o child-class) appartenente alla stessa
tipologia.
La relazione di generalizzazione
è spesso indicata anche con la denominazione Is-kind-of (è
di tipo), per indicare che un oggetto specializzato è del tipo
delloggetto più generale.
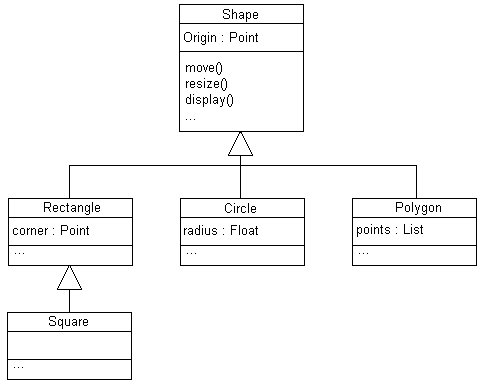 |
Figura
6 Esempio di relazione di Generalizzazione
Per esempio, facendo riferimento
alla figura precedente, è possibile asserire che la classe Rectangle
è del tipo della classe shape, così come lo sono le classi
Circle e Polygon. Per ciò che concerne la classe Sqaure, applicando
un ragionamento ricorsivo, si può tranquillamente asserire che è
anchessa di tipo Shape oltre ad essere di tipo Rectangle.
La proprietà peculiare di
tale relazione prevede che un qualsiasi oggetto istanza di una classe specializzata
possa essere sempre utilizzata ovunque compaia la classe base. Ciò
equivale a dire, per esempio, che un oggetto della classe Rectangle può
essere sempre sostituito ad un oggetto Shape e, ancora, un oggetto della
classe Square può sempre sostituire sia unistanza della classe
Rectangle, sia una della classe Shape.
Tale proprietà può
essere facilmente compresa se si considera che una classe figlio eredita
(opportune/i) proprietà e metodi della classe padre: anche nel caso
limite in cui la classe specializzata non dovesse aggiungere ulteriore
comportamento, conserverebbe, comunque, quello della classe padre.
Quando un metodo di una classe
figlio possiede la stessa segnatura (nome, parametri formali e parametro
di ritorno) di uno della classe padre, si dice che ne effettua la sovrascrittura
(override). Ciò implica che ogni riferimento a tale metodo, eseguito
in un oggetto della classe figlio, farà riferimento al metodo ridefinito
anziché a quello della classe padre. Nel caso in cui invece si abbia
la necessità di riferirsi al metodo originale, quello della classe
padre, è sufficiente premettere un puntatore a tale classe (in Java
è necessario utilizzare la parola chiave super).
Graficamente, una generalizzazione
è rappresentata per mezzo di una linea piena culminante con un triangolo
vuoto nella direzione della classe padre.
Durante il processo di analisi,
spesso si incontrano alcune entità presenti nel dominio del problema,
aventi un comportamento e/o una struttura simile. In tali casi si può
agire secondo due criteri ben distinti:
1. modellare le varie entità
attraverso classi distinte senza alcun legame;
2. estrapolare dalle entità
il comportamento e la struttura comune al fine di realizzare una classe
più generale dalla quale far derivare tutte le altre.
Durante il processo di analisi
delle entità presenti nel dominio del problema, può capitare
di aver la necessità di dover schematizzare determinate relazioni
tra classi per mezzo di eredità multiple, ossia vi è una
classe figlia che eredita da più classi genitore; sebbene ciò
sia assolutamente legittimo, bisogna però utilizzare tali relazioni
con molta cautela.
In primo luogo alcuni linguaggi
Object Oriented, come per esempio Java, non la prevedono, e comunque, si
può facilmente incorrere in errori qualora la classe figlio voglia
ridefinire (override) la struttura e/o il comportamento di una delle classi
genitore.
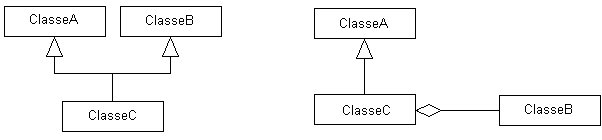
Le relazioni multiple vanno pertanto
opportunamente ponderate, non è infrequente il caso in cui sia consigliabile
sostituirla con uno schema denominato Delegazione. Esso prevede di rimpiazzare
una ereditarietà n-naria, con una singola ed n-1 aggregazioni,
come illustrato nella figura seguente (7).
La selezione della classe destinata
a rimanere genitore unico, è abbastanza delicata. Si consiglia di
optare per quella con maggiore comportamento da estendere o per quella
che più frequentemente è utilizzata da altre classi del sistema.
 |
Figura
7 Normalizzazione di una ereditarietà multipla
Sebbene siano le eredità
multiple quelle più delicate, talune volte anche in quelle singole,
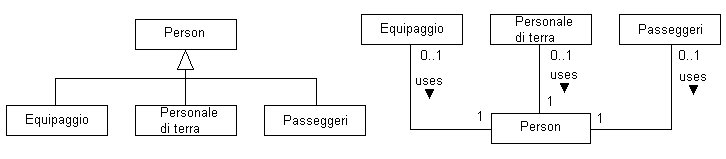
possono risiedere alcuni trabocchetti. Si consideri la figura 8, in cui
sono visualizzate le relazioni che intercorrono tra le entità presenti
in un sistema di memorizzazione delle informazioni relative a voli aerei.
In prima analisi, probabilmente, potrebbe venire in mente di organizzare
il tutto secondo una classica relazione di generalizzazione. Però,
se si analizza più approfonditamente la situazione reale, ci si
accorge che tale organizzazione può generare non pochi problemi.
Un dipendente di una compagnia aerea (istanza della classe Equipaggio
o Personale di terra) spesso può essere anche passeggero. In sostanza,
sono presenti delle entità che potrebbero essere istanza di più
classi. Pertanto, volendo mantenere una relazione di generalizzazione,
bisognerebbe introdurre ulteriori classi combinazioni per annoverare
tutte le possibili casistiche. Si tratterebbe, comunque, di una soluzione
rigida e decisamente poco elegante. Migliore è la soluzione normalizzata
per mezzo di una serie di associazioni come evidenziato in figura 8.
 |
Figura
8 Normalizzazione di una generalizzazione impropria
Associazione
Unassociazione è una relazione
strutturale tra classi, indicante che un oggetto è connesso ad altri.
Gli oggetti legati da unassociazione possono essere istanze di una stessa
classe (self association) o di classi diverse.
Data una relazione di associazione
che connette due classi, è sempre possibile navigare da un oggetto
di una classe a quello di unaltra e viceversa.
Nel caso in cui unassociazione
connetta esattamente due classi si parla di associazione binaria, negli
altri casi (molto rari) viene detta associazione ennaria.
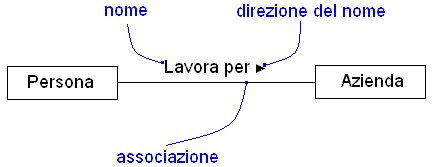 |
Figura
9 Esempio di relazione di associazione.
Dal punto di vista grafico, una
relazione di associazione è rappresentata tramite una linea piena
che connette le classi partecipanti alla relazione.
Spesso, al fine di rendere i diagrammi
più leggibili, è possibile assegnare ad unassociazione un
nome, corredato dalla direzione in cui va letto.
Per esempio, in figura 9 è
stato assegnato il nome lavora per alla relazione di associazione e la
chiave di lettura è (ovviamente) verso destra, pertanto è
la Persona che lavora per unAzienda e non vice versa.
Talune volte, al posto di specificare
il nome della relazione, si preferisce inserire i ruoli che le classi
interpretano in una ben determinata relazione. Questi vanno posti vicino
alla linea che simboleggia la relazione, ognuno in prossimità della
relativa classe, come illustrato in figura 10. La scelta tra quale sistema
utilizzare, dovrebbe essere indirizzata verso la tecnica che, di volta
in volta, fornisce una maggiore chiarezza e leggibilità del diagramma.
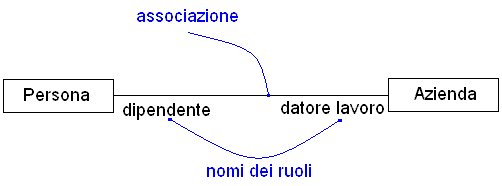 |
Figura
10 Relazione di associazione corredata dai ruoli
Nella fase di implementazione del
diagramma delle classi, risulta di vitale importanza conoscere la molteplicità
con la quale una determinata classe partecipa in una specifica relazione.
In altre parole, è necessario sapere, per ogni oggetto di una classe,
a quanti altri oggetti di unaltra può essere associato; ciò
permette di implementare correttamente le classi. Per esempio, se un determinato
oggetto di una classe è legato ad un solo oggetto dellaltra, allora
è possibile codificare tale relazione per mezzo di una singola proprietà
(puntatore o reference) di tipo della classe coluta. Se invece il numero
di oggetti può essere n, allora è necessario prevedere
strutture quali Array, Vettori, HastTable, ecc.
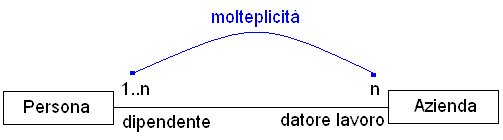 |
Figura
11 Relazione di associazione con molteplicità.
Come da prassi, le molteplicità
vengono scritte vice versa. Con riferimento alla figura 11 è possibile
asserire che una Persona può lavorare in n Aziende, mentre
ciascuna di esse può dare lavoro almeno ad 1 persona, e, in generale,
ad n.
Le molteplicità tipiche
sono : 1, 0..1, n (talvolta indicata con lasterisco *), 0..n,
1..n, ecc.
Nulla vieta però di scriverne
differenti e più specifiche come per esempio 2, 3..10, ecc.
Aggregazione
Unassociazione tra due classi
rappresenta una relazione strutturale paritetica: entrambe sono concettualmente
allo stesso livello, per cui non esiste una di maggiore o minore importanza.
Spesso però è necessario
impostare una relazione tra classi in cui una rappresenti un oggetto più
grande (Whole) e laltra una sua componente (Part), questo tipo di
associazioni prendono il nome di aggregazioni oppure relazioni Whole-Part,
in cui la differenza tra le classi è unicamente concettuale.
Graficamente le aggregazioni sono
rappresentate per mezzo di una linea piena con un rombo rivolto verso la
classe più generale, come illustrato nella figura successiva.
 |
Figura
12 Esempio di una relazione di aggregazione
La figura seguente mostra un esempio
di diagramma delle classi dellorganizzazione di una facoltà universitaria.
Si può notare che lassociazione Insegna, che lega la classe dei
Docenti a quella del Corso, è una relazione assolutamente paritetica,
le due classi, concettualmente, sono poste allo stesso livello. Mentre
per ciò che riguarda la relazione è costituita, si può
notare che si tratta di unaggregazione, infatti unentità più
grande, la Facoltà, è associata ad una più piccola:
il Dipertimento.
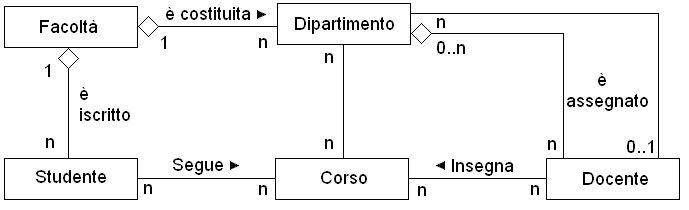 |
Figura
13 Diagramma delle classi di una facoltà universitaria.
Diagrammi
delle classi
Il diagramma delle classi è
probabilmente, tra quelli annoverati dallUML, il più noto: in esso
ci sono alcune varianti presenti in altri linguaggi di modellazione Object
Oriented. Esso è costituito da un insieme di classi, interfacce,
collaborazioni e le relazioni tra di essi. Esistono diverse tipologie di
relazioni, quali, la dipendenza, lassociazione, la specializzazione, il
raggruppamento in package,
.
Coloro che provengono dal mondo
dellanalisi strutturata, potranno notare la stretta somiglianza con i
diagrammi Entità-Relazioni, di cui ne rappresentano levoluzione
O.O.
Lobiettivo di tali diagrammi è
visualizzare la parte statica del sistema.
Di tali diagrammi se ne è
discusso, più o meno esplicitamente, nel corso di tutto larticolo
e si proseguirà anche nei paragrafi successivi.
Diagrammi
degli oggetti
Gli Object Diagram sono una variante
dei Class Diagram, di cui conservano gran parte della propria notazione,
e quindi concorrono a modellare la parte statica della Design View.
La differenza principale è
i diagrammi degli oggetti rappresentano delle istanze delle classi invece
che le classi reali.
Lidea è quella di realizzare
delle istantanee degli oggetti presenti nel sistema in un ben determinato
istante di esecuzione. Si può immaginare come se si congelasse
il sistema, o una sua immagine, in un preciso momento, al fine di analizzarne
gli oggetti presenti, ognuno con il proprio stato di esecuzione, e le proprie
relazioni con gli altri oggetti
Le due principali differenze di
notazione sono:
-
gli oggetti vengono
scritti con i relativi nomi sottolineati;
-
tutte le istanze
delle relazioni vengono mostrate.
Gli Object Diagram non sono di fondamentale
importanza per la progettazione del sistema, però risultano decisamente
utili per esemplificare situazioni complesse presenti in alcuni diagrammi
delle classi.
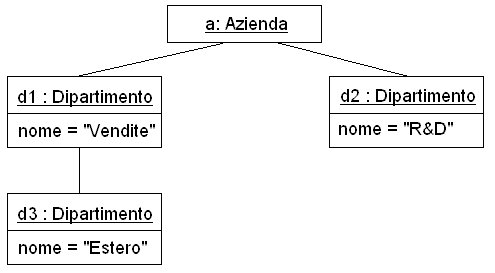 |
Figura
14 Esempio di object diagram
Nella figura successiva viene presentata
una soluzione del classico (sicuramente, per gli studenti universitari
di IT inflazionatissimo) problema degli n-produttori ed n-consumatori.
Nel diagramma degli oggetti, come si può notare, si è deciso
di lasciare tutti gli oggetti anonimi, ossia se è specificata la
classe senza attribuirne il nome.
Il diagramma degli oggetti mostra
una ipotetica situazione con 3 oggetti produttori e 2 consumatori.
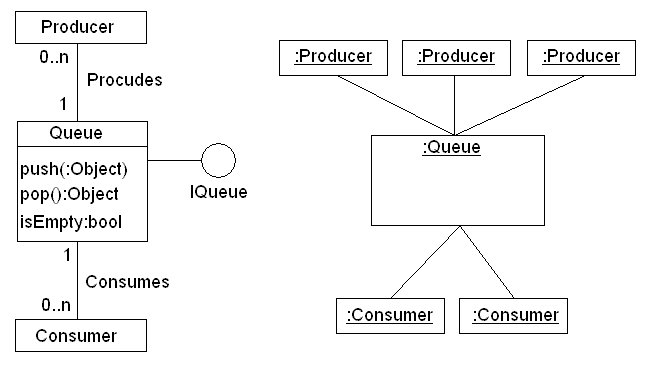 |
Figura
15 Diagramma delle classi e degli oggetti produttori-Consumatori
Design Pattern
Lintroduzione del design pattern
nel settore del software engineering è dovuta al lavoro dellarchitetto
Christopher Alexander, (incredibile che un architetto sia riuscito a tanto
eh?) il quale, inizialmente, definì un pattern language per descrivere
le soluzioni architetturali dimostratesi vincenti nella costruzione di
edifici ed intere città.
Obiettivo di tale linguaggio era
descrivere come costruire architetture di elevato livello qualitativo.
Lidea scaturì dallosservazione
che determinati modelli, con opportune varianti, erano presenti in numerose
architetture di successo.
Il lavoro di alexander non rimase
confinato nel solo ambito delle costruzioni edili, ma invase altre discipline
tra cui linformatica. Nei primi anni 90 molte validi tecnici informatici
furono affascinati dal lavoro di Alexander tanto da giungere nel 1994 alla
Pattern Languages Of Programs (plop). conference.
Si intuì fin da subito che
tale approccio non doveva necessariamente essere confinato al mondo dellObject
Oriented, sebbene ormai la comunità informatica (americana) fosse
orientata in tale direzione. Nel 1995 il gruppo detto Gang of Four (Erich
Gamma, Richard Helm, Ralph Johnson e John Vlissides) pubblicò il
libro Design Patterns: Elements Of Resuable Object-Oriented Sw, contenente
il catalogo dei modelli utilizzabili anche per i nuovi aree di sviluppo.
Da allora, nel corso degli ultimi
anni i patterns sono stati oggetto di notevole interesse nella comunità
dellObject-Oriented, tanto da rappresentare una svolta nel processo di
sviluppo del software.
Si tratta della trasposizione nel
mondo della progettazione del paradigma Object Oriented.
I patterns sono:
-
eleganti: rappresentano
soluzioni particolarmente eleganti alle quali il personale inesperto non
sarebbe portato a pensare.
-
generici: essi sono
indipendenti da un particolare tipo di sistema, da un determinato linguaggio,
o dominio di applicazione. essi rappresentano soluzioni generiche per un
problema specifico.
-
ben-collaudati:
essi sono il risultato della generalizzazione di soluzioni individuate
per problematiche del mondo reale, e non speculazioni di carattere accademico,
pertanto sono modelli utilizzati con successo in molti casi pratici (well
proven).
-
semplici: i pattern
sono tipicamente abbastanza piccoli, e coinvolgono un gruppo limitato di
classi. Per costruire soluzione di livello di complessità superiore,
è possibile (anzi auspicabile) combinare tra loro differenti patterns.
-
riusabili: essi
sono documentati in maniera così estensiva da permetterne un facile
riutilizzo. Essendo generici possono essere riutilizzati per molti tipologie
diverse di sistemi. Da notare che in questo contesto il riutilizzo fa riferimento
alla fase di design e non a quella di codifica, essi non sono (ancora)
presenti in librerie di classi bensì sono soluzioni già pronte
per larchitettura del sistema.
-
object-oriented:
i pattern sono stati progettati rispettando i principi basilari dellObject
Oriented (classi, oggeti, generalizzazione e polimorfismo).
Filter: un
esempio di Pattern
La tentazione di illustrare gli
inflazionatissimi Proxy pattern o Observer era notevole, ma, al fine
di non abusare oltre misura della pazienza dei lettori, si è deciso
di illutrarne un altro molto utile: il filter. Per i più esperti,
si tratta della categoria nota con il nome di Partitioning Pattern.
In molti sistemi vi è la
necessità eseguire delle elaborazioni e/o analisi di un flusso di
dati. Un programma che esegue una semplice elaborazione di un data stream,
è il comando esterno uniq del sistema operativo UNIX.
Tale comando riceve in input un
insieme di linee e le copia in output. Durante tale processo, quando individua
una serie di linee consecutive uguali, ne copia solo la prima.
I compilatori sono programmi di
filtro tra i più complessi. Essi eseguono una serie di analisi e
trasformazioni del codice sorgente fino a trasformarlo in codice eseguibile
(o interpretato).
Le classi che eseguono delle semplici
trasformazioni, e quindi che sono parti dellintero processo, sono, per
loro natura, assolutamente riutilizzabili, e devono, necessariamente, offrire
un elevato grado di flessibilità al fine di consentire ai loro oggetti
di poter essere interconnessi.
Il modo più veloce per ottenere
l flessibilità voluta è quella di definire una super-classe
comune a tutte le altre cosicché ogni istanza può utilizzarne
unaltra senza doverne necessariamente conoscerne ulteriori dettagli.
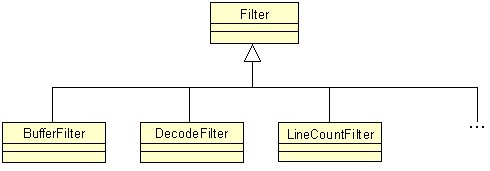 |
Figura
16 File filters
Soluzione
La soluzione proposta è
nota con il nome di Source Filter Pattern, come illustrato nella figura
seguente.
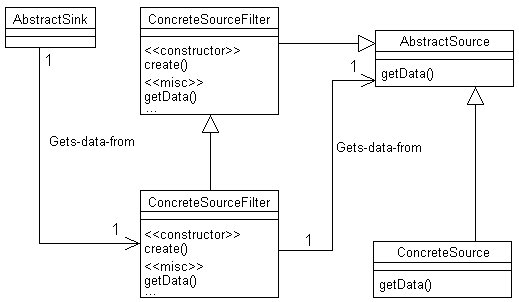 |
Figura
17 Utilizzo degli stereotipi per organizzare lelenco dei metodi di
una classe
Le classi utilizzate
sono:
-
AbtractSource. Si
tratta di una classe astratta che dichiara un solo metodo, getData(),
il quale si occupa di fornite un opportuno dato ogniqualvolta invocato.
-
ConcreteSource.
Questa classe si riferisce ad ogni concreta sottoclasse della precedente
e pertanto ha la primaria responsabilità di provvedere i dati richiesti.
-
AbstractSourceFilter.
Si tratta di unaltra classe astratta che stabilisce il comportamento delle
classi che si occupano di analizzare e trasformare i dati. Il suo costruttore
prevede come parametro un riferimento ad un oggetto istanza di una classe
derivata da AbstractSource. Ciò consente , alle istanze di questa
classe, di ottenere i dati sui quali effettuare gli opportuni processi
di analisi. Poiché le istanze di questa classe sono anche istanze
della classe AbstractSource, gli oggetti istanza della classe AbstractSink
possono agevolmente richiedere i dati agli oggetti della classe ConcreteSourceFilter,
ai quali sono associati. Il metodo getData()presente in questa classe,
e nelle sue derivate, si comporta da ponte verso il relativo metodo della
classe AbstractSource e quindi, in ultima analisi, non fa altro che richiamare
il metodo getData() della calsse ConcreteSource.
-
ConcreteSourceFilter.
Questa classe include ogni classe concreta della AbstractSourceFilter.
Le classi di questa tipologia si dovrebbero occupare di estendere le funzionalità
del metodo getData() ereditata dalla classe AbstractSourceFilter, aggiungendo
le appropriate trasformazioni e operazioni di analisi.
-
AbstractSink. Gli
oggetti istanze delle classi che estendono questa classe, invocano il metodo
getData() della classe AbstractSource. Diversamente dagli oggetti delle
classi ConcreteSourceFilter, le istanze di questa classe utilizzano
i dati senza passarli
Conclusioni
Con il presente articolo si è
dato inizio al viaggio allinterno della Design View (nota anche con
il nome di logical view), la vista dedicata al disegno del sistema. In
particolare si è cominciato ad analizzarne la parte dedicata alla
proiezione statica, costituita dai class e objects diagram.
E sicuramente una delle viste
più sensibili per i sistemi software, in cui è necessario
intraprendere un gran numero di decisioni, che, probabilmente, è
superiore a quello necessario a tutte le altre.
Chiaramente si è cercato
di illustrare le parti di maggiore interesse, tentando di stimolare linteresse
del lettore, senza però avere assolutamente la pretesa di essere
esaustivi.
Il processo di costruzione delle
strutture ad oggetti non è di certo uno schema recente o nato con
linformatica, anzi è conosciuto da centinaia di anni con il nome
di classificazione.
Ciò non ostante, ancora
non sembrerebbe aver riscosso il successo del grande pubblico (chissà
come mai
).
Uno degli esempi più illustri,
citati in quasi ogni libro O. O. (e quindi, per non essere da meno) è
il relativo utilizzo eseguito per lo studio dellereditarietà di
Mendel. Forse, chissà, proprio a lui va attribuita la responsabilità
dei troppi esempi di diagrammi delle classi ed oggetti rappresentanti
fiorellini ed insetti.
Nuovamente, le difficoltà
di condurre analisi (realmente) O. O. sono dovute più alla difficoltà
di astrarsi dal concreto, limite tipico della mente umana, e dalla necessità
di riadeguare i propri schemi mentali, troppo a lungo violentati dalla
programmazione classica, piuttosto che alla complessità offerte
dal linguaggio UML.
Per finire, si è voluto
dedicare qualche paragrafo ad un argomento particolarmente di moda nel
settore della progettazione O. O., i patterns. (Vedere [4]).
Si tratta della trasposizione al
mondo della progettazione delle peculiarità della programmazione
O. O.
La cosa veramente strana è
che lidea, assolutamente semplice e brillante, sia frutto di una splendida
intuizione di un architetto.
Bibliografia
[1] "The Unified Modeling
Language User Guide" di Grady Booch, James Rumbaugh, Ivar Jacobson
- Ed. Addison Wesley
Questo libro vanta il primato di
essere stato scritto dai progettisti originali del linguaggio, sebbene
sia conosciuto come Gradys book, dal nome del suo primo autore. La mancanza
di una sua copia (magari autografata!) può generare giudizi di scarsa
professionalità per coloro che operano nel settore della progettazione
O.O... Ciò però, costituisce una condizione necessaria, ma
non sufficiente, in quanto bisogna, assolutamente, aggiungere una copia
del [3] e una del [4]. Sono soldi spesi bene! Forse, il limite del libro,
se proprio se ne vuole trovare uno, è quello di essere poco accessibile
ad un pubblico non espertissimo di progettazione O.O. Un altro piccolo
inconveniente è che, probabilmente, taluni esempi possano sembrare
di carattere accademico: poco rispondenti alle problematiche del mondo
reale.
[2] "UML Toolkit" di Hans-Erik
Eriksson, Magnus Penker - Ed. Wiley
Questo libro si fa particolarmente
apprezzare per via del taglio pratico dello stesso. Illustra in modo semplice
il linguaggio, attraverso numerosi esempi, limitando le digressioni di
carattere teorico. Si suppone infatti, che coloro che si occupano di progettazione
O.O. abbiano una certa familiarità con i relativi concetti. Chissà
perché si ha la sensazione che non sia sempre così! Naturalmente,
studiare libri che illustrano gli aspetti teorici dellinformatica, è
sempre qualcosa più che auspicabile. È altresì vero
però, che coloro che non hanno tempo da perdere, per la lettura
di concetti arcinoti, gradiscono arrivare rapidamente al nocciolo. Ciò
spesso equivale a strappare alle nottate lavorative ore preziose per il
sonno.
[3] "The Unified Modeling Language
Reference Manual" di Grady Booch, James Rumbaugh, Ivar Jacobson -
Ed. Addison Wesley
Il commento da riportare per questo
libro, noto per come Rumbaughs book, è sostanzialmente equivalente
a quanto riportato per il primo. Esso però offre un livello di difficoltà
decisamente inferiore, e pertanto dovrebbe essere più accessibile.
Come suggerisce il nome, si tratta di un manuale, per cui ne rispetta la
tipica struttura.
[4] "Design Patterns: Elements of
Reusable Object-Oriented Software" Erich Gamma, Richard Helm, Ralph Johnson,
John Vlissides, Grady Booch - Ed. Addison Wesley.
Si tratta di un ottimo libro che
bisogna assolutamente avere se si vuole lavorare nellambito della progettazione
O.O. . I pattern riportati, forniscono un ottimo ausilio al processo
di disegno del software. Lutilizzo del libro contribuisce ad aumentare
la produttività, fornisce soluzioni chiare, efficienti e molto eleganti.
La fase di disegno del software, spesso, si riduce ad individuare e personalizzare
i pattern che risolvono la problematica specifica. Si è di fronte
ad una nuova frontiera della progettazione O.O.: il riutilizzo di parti
del progetto. Lunica pecca imputabile, è che i vari diagrammi non
sempre rispettano il formalismo UML.
[5] www.omg.org
- Si tratta del sito ufficiale del Object Managment Group.
[6] "UML e lo
sviluppo del software" - MokaByte numero 34 (Ottobre 1999)
[7] "Use Case:
lanalisi dei requisiti secondo lU.M.L.." - MokaByte. numero 35 (Novembre
1999)
|


