| Introduzione
Il
problema ha stuzzicato molte persone negli ultimi tempi ed in molti hanno
anche tentato di risolverlo. Una tra le soluzioni proposte prevede la realizzazione
di un agente che, partendo da una banca dati in cui sono mantenute le principali
informazioni sugli utenti di un sito, riesce a capire in anticipo gli interessi
di un utente e lo guida verso linformazione cercata. Per realizzare questo
agente, però, si deve prima avere la banca dati sugli utenti aggiornata.
Dellaggiornamento della banca dati si occupa un altro agente che deve
procurare i dati sugli interessi degli utenti. Il lavoro di tale agente
sarà quello di monitorare i movimenti degli utenti allinterno
del sito Web, analizzarli ed estrapolarne dei dati che indichino quali
sono gli argomenti preferiti da ogni singolo utente.
In
questo articolo descriveremo come realizzare un analizzatore dei movimenti
di un navigatore di Internet. Tale analizzatore spia gli accessi dellutente
ad un preciso sito Web e da essi preleva alcune informazioni che verranno
inserite nella banca dati remota sugli utenti. Lanalizzatore gira insieme
al browser sulla macchina dellutente, che potrà quindi decidere
anche di non utilizzarlo (questo per evitare guai con la legge sulla privacy!!).
Lanalizzatore
ha laspetto di un proxy, che si frappone tra il browser dellutente e
la rete. In questo modo ha la possibilità di ricevere ogni messaggio
che il browser e la rete (ossia il Web server del sito di interesse) si
scambiano ed in particolare può vedere quali sono le pagine HTML
che lutente decide di leggere. Questi documenti vengono analizzati dal
proxy e poi inviati al browser che li può finalmente visualizzare
allutente.
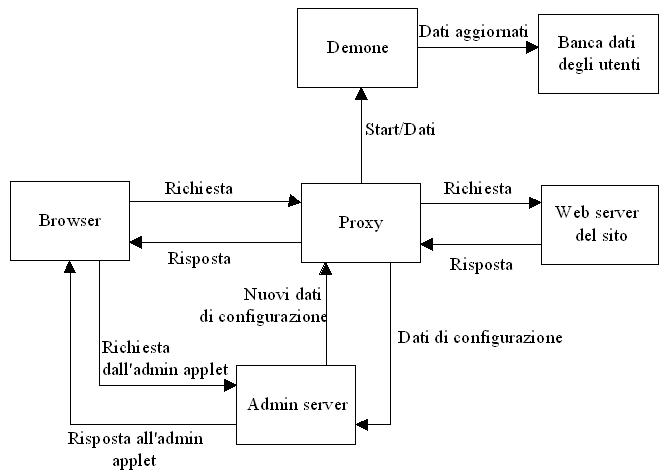
Lo
schema totale che si presenta è descritto in Fig. 1.
 |
Figura
1
Come
si vede dalla figura, si hanno vari moduli per realizzare lanalizzatore
nel suo complesso. Il modulo principale è sicuramente il Proxy,
che si occupa dellintercettazione dei messaggi che transitano tra il browser
e il Web server; il modulo Admin server, invece, si occupa dellamministrazione
del proxy (la configurazione di partenza, la gestione della struttura
dati in memoria in cui il proxy inserisce i dati analizzati
); il modulo
Demone, infine, si occupa dello scambio di dati tra il proxy e la banca
dati che si trova su unaltra macchina (probabilmente, ma non necessariamente,
la stessa in cui si trova il sito Web).
Vediamo
ora un po più in dettaglio il modo in cui operano i suddetti moduli.
Per
quanto riguarda il Proxy, per capire quali devono essere le sue funzioni,
dobbiamo prima capire cosa intendiamo per monitorare i movimenti di un
utente in un sito Web. Quando un utente naviga in un sito Web sceglie
una pagina HTML e la scarica con il proprio browser per leggerla.
Un
primo particolare interessante, che il Proxy deve memorizzare, è
sicuramente lindirizzo Web del documento e quindi il nome del file scaricato.
Il fatto che un utente scelga di esaminare una determinata pagina è
di grande rilevanza per sapere che tipo di informazione sta cercando.
Un
altro aspetto molto importante da considerare è che nel documento
possono essere presenti dei link e che lutente può decidere di
seguirli o no. Questi link sono tipicamente associati ad informazioni legate
in qualche modo a quella contenuta nel documento in cui si trovano: possono
essere dei collegamenti a pagine che approfondiscono il tema trattato nel
documento di partenza (ad es., in un testo che descrive un motore di unautomobile,
vi può essere un link ad un file che descrive il motore diesel),
o che lo generalizzano (da un documento sul motore a scoppio si può
arrivare ad un file che tratta il ciclo a quattro tempi); oppure sono collegamenti
a documenti esplicativi, come figure, filmati o audio; od infine, possono
essere link a documenti che trattano un nuovo tema, che però è
collegato in qualche modo a quello trattato dal testo attuale (ad es.,
in un documento che descrive un motore, vi può essere un link ad
un file che parla della trasmissione).
In
questo modo, seguendo lo spostamento dellutente attraverso i vari link,
si riesce a capire meglio quali siano le informazioni che cerca, ed aggiornare
di conseguenza la banca dati.
 |
Figura
2
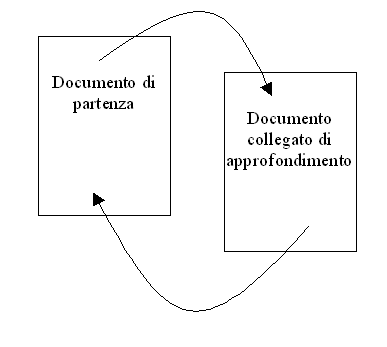
Il
Proxy deve, inoltre, tenere conto di un altro aspetto collegato a questo
discorso: il fatto che un utente segua un certo link, indica sicuramente
che vuole approfondire il tema trattato nel documento collegato a quello
di partenza. Se, però, lutente torna indietro al documento iniziale
(Fig. 2), è un segnale che può significare che linformazione
principale cercata dallutente si trova nel documento di partenza, e il
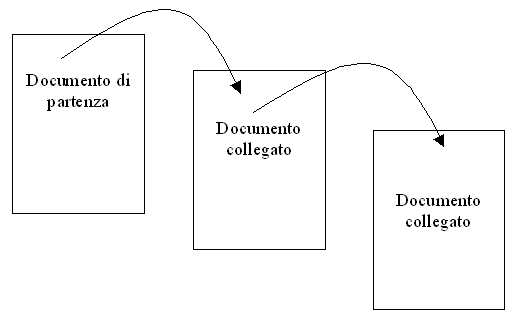
link è stato seguito solo per un approfondimento. Se, invece, lutente
segue i link a cascata, muovendosi in profondità da un file allaltro
(Fig. 3), può significare che linformazione cercata dallutente
non era nel primo documento da lui richiesto, anche se conteneva un argomento
in qualche modo in relazione con linformazione cercata. In questo caso,
infatti, lutente ha deciso di seguire i link che, secondo lui, più
si avvicinano allinformazione voluta, con la speranza di arrivare, alla
fine, al documento desiderato. Da tutto questo si capisce che il modulo
Proxy deve mantenere in memoria una struttura in cui inserisce, per ogni
pagina che analizza, i link che si trovano in essa e, per ognuno di essi,
un flag che indica se lutente li segue o no.
 |
Figura
3
Unaltra
fonte di informazioni interessanti sul comportamento dellutente è
data dal tempo di lettura della pagina Web scaricata, ossia da quanto lutente
si sofferma su essa. Si può infatti immaginare che, più lutente
si sofferma su un preciso documento, più cresce il suo interesse
per il tema in esso trattato.
Bisogna,
però, prestare attenzione ad un problema che deriva da questo ragionamento,
che può diventare troppo semplificativo nel dedurre gli interessi
dellutente. Bisogna tenere conto del fatto che egli può soffermarsi
su un certo documento per leggerlo e studiarlo, nel qual caso le deduzioni
sopra esposte risultano fondate; oppure può succedere che in quel
momento lutente si sia allontanato dalla macchina (fortunatamente anche
i navigatori più incalliti vanno a mangiare
anche se a volte lasciano
il collegamento attivo!!!) e, quindi, la deduzione fatta prima risulta
completamente errata, o comunque priva di fondamento.
Si
può cercare di dedurre comunque qualcosa dallanalisi del tempo
passato da un utente su un certo documento, tenendo conto però,
di queste diverse possibilità. Si può pensare, quindi, di
aggiornare la banca dati dellutente solo se il tempo di lettura non supera
un valore soglia massimo, che indicherebbe il fatto che lutente non
sta effettivamente leggendo il documento, ma è impegnato in qualche
altro compito (è arrivato il panino che aveva ordinato al bar!!!).
Inoltre, si può decidere di memorizzare come letta una pagina,
solo se il suo tempo di lettura supera un altro valore soglia minimo,
sotto il quale si può pensare che lutente abbia scaricato il documento
sperando di trovarci delle informazioni utili, ma si sia subito accorto
di non essere interessato ad esso ed abbia deciso di non leggerlo.
Il
Proxy quindi deve calcolare il tempo che lutente impiega per leggere ogni
pagina che scarica dal sito Web, tenendo presente i due suddetti valori
soglia.
Un
ultimo dato calcolabile dal Proxy è quello che deriva dal conteggio
del numero di volte che un utente apre lo stesso documento. Il fatto che
un file venga scaricato e letto più volte, può indicare un
notevole interesse da parte dellutente verso largomento in esso trattato.
Descriviamo
infine le funzioni svolte dagli altri due moduli.
Il
modulo Admin server si occupa di amministrare lanalizzatore. Tramite
questo modulo si può configurare il Proxy, definendo lindirizzo
del sito Web da analizzare, lindirizzo della banca dati a cui si accede,
i valori soglia descritti prima ed altri dati di configurazione utili
al Proxy. Inoltre il modulo si occupa di gestire la zona di memoria in
cui il Proxy deve inserire i dati che preleva dallanalisi delle pagine
scaricate dal sito. Ogni modulo che deve accedere a tale zona di memoria
deve passare attraverso il modulo Admin server.
Il
modulo Demone, infine, è un modulo che si sveglia una volta al
giorno, accede tramite lAdmin server alla zona di memoria in cui sono
presenti i dati raccolti dal Proxy, li analizza, ne preleva le informazioni
necessarie per aggiornare la banca dati sugli utenti ed invia i suoi risultati
alla banca dati stessa.
Per
ora ci fermiamo qui altrimenti largomento può diventare pesante
e noioso (ho visto già qualche sbadiglio!). Nei prossimi articoli,
se sarete ancora interessati, analizzeremo più in dettaglio i vari
moduli descritti qui e vedremo un modo per realizzarli in Java e per farli
comunicare tra loro.
|


