Come
abbiamo già detto nel precedente articolo, il modulo Proxy intercetta
i messaggi che il browser e la rete si scambiano durante la navigazione
dellutente. Inoltre si occupa dellanalisi dei documenti HTML che lutente
decide di scaricare e leggere, e di immagazzinare i dati prelevati in una
zona di memoria, dove gli altri moduli potranno leggerli per effettuare
altre analisi e, infine, aggiornare la banca dati sullutente.
 |
Figura
1
Il
proxy è realizzato tramite tre classi principali, che a loro volta
utilizzeranno i servizi di altre classi di appoggio :
-
la classe
ProxyServer, che implementa il server per intercettare le richieste in
uscita dal browser;
-
la classe
Proxy, che implementa il thread per la gestione di ogni singola connessione
tra il browser ed un Web server;
-
la classe
Config, in cui vengono memorizzati e gestiti i dati di appoggio del proxy
stesso (lista dei siti da monitorare, movimenti effettuati finora dallutente,
configurazione del proxy stesso
).
Vedremo
ora in particolare la realizzazione di queste tre classi.
Classe ProxyServer
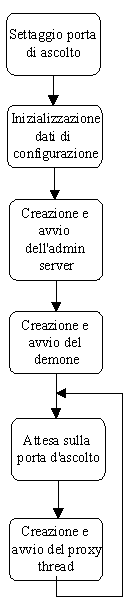
Il
ProxyServer ha una struttura algoritmica molto semplice (Fig. 1): ha una
porta dascolto, che se non è specificato diversamente da linea
di comando, è per default la porta 8080; una volta avviato crea
un oggetto della classe Config che inizializza con i valori mantenuti nel
file Config.txt; inoltre crea e fa partire due thread: ladmin server
e il demone (ossia gli altri due moduli che descriveremo nelle prossime
puntate).
//
Crea e inizializza il Config
//
per configurare il proxy
config=new
Config();
(
)
File
adminDir=new File("");
config.setAdminPath(adminDir.getAbsolutePath());
//Si
crea il thread adminServer
AdminServer
adminSrv=new AdminServer(config);
adminSrv.start();
//Si
caricano i parametri salvati della config
configFile=new
File("Config.txt");
if
(configFile.exists()) {
long
length=configFile.length();
if
(length>0) {
byte
data[]=new byte[(int)length];
FileInputStream
inputFile=new FileInputStream(configFile);
inputFile.read(data,0,(int)length);
String
configParameter=new String(data);
if
(configParameter.length()>0)
config.parse(configParameter);
inputFile.close();
}
}
//Si
crea il daemon-thread
daemonThd=new
DaemonThread(config);
daemonThd.start();
Quindi
si mette in ascolto sulla porta scelta, in attesa di una richiesta da parte
del browser. Quando arriva tale richiesta, il proxy server crea un nuovo
thread (un oggetto della classe Proxy), a cui passa la gestione della richiesta
con il socket di comunicazione e loggetto Config con i parametri di configurazione,
e torna in attesa sulla porta di ascolto.
//
Si crea il socket principale
mainSocket=new
ServerSocket(proxyServerPort);
System.out.println("Proxy
attivo...");
//Main
loop
while(true)
{
//
Si ascolta sul socket
Socket
clientSocket=mainSocket.accept();
//Si
passa la richiesta ad un nuovo proxy thread
Proxy
thd =new Proxy(clientSocket,config);
thd.start();
}
Questo
ciclo continua fino a che il proxy server non viene chiuso dallesterno
o interviene una eccezione. In questo caso, prima di chiudersi, il proxy
server attende che tutti i thread lanciati si siano conclusi e che la configurazione
mantenuta nella classe Config sia stata salvata nel file Config.txt, per
essere recuperabile alla nuova apertura del proxy server stesso.
catch
(Exception e) {
System.out.println(e.toString());
}
finally
{
//Si
aspetta che tutti i proxy-thread terminino
System.out.println("Attesa...");
while(config.getThreads()>0)
{}
config.setServerAlive(false);
System.out.println("Salvataggio
informazioni...e chiusura ProxyServer");
try
{
mainSocket.close();
//
Si salva la configurazione nel file Config.txt
configFile=new File("Config.txt");
FileOutputStream outputFile=new FileOutputStream(configFile);
outputFile.write(config.toString().getBytes());
outputFile.close();
System.out.println("Salvataggio dati nel DB Utenti");
daemonThd.interrupt();
daemonThd.join();
}
catch
(Exception e) {
System.out.println(e.toString());
}
}
Classe Proxy
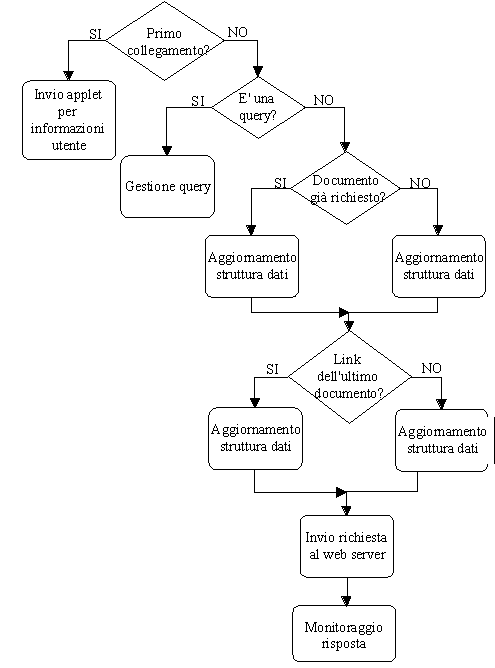
La
classe Proxy rappresenta il proxy vero e proprio che si occupa di gestire
lo scambio di messaggi tra il browser e il Web server. Lalgoritmo seguito
dal proxy è schematizzato in fig. 2.
 |
Figura
2
Dopo
una prima fase di inizializzazione delle variabili, il proxy avvia un parsing
della richiesta che dal browser deve arrivare al Web server. Questo lavoro
viene effettuato tramite i metodi messi a disposizione dalla classe HttpRequestHdr,
che effettua il parsing dellheader del messaggio secondo le specifiche
del protocollo HTTP/1.1[ ], e della quale vi risparmio la descrizione.
Una
volta effettuato il parsing, si controlla di che tipo di richiesta si tratta.
Ci sono due possibilità:
-
la richiesta
è per il proxy stesso: in questo caso si tratta di una richiesta
dellamministratore del proxy per cambiarne la configurazione. Il proxy,
allora, invia come risposta un applet che servirà allutente per
modificarne la configurazione;
//Parsing
dell'header della richiesta del client
request=new
HttpRequestHdr();
request.parse(clientIn);
url=new
URL(request.getUrl());
isLastMessage=request.getIsLastMessage();
//se
è una richiesta dell'amministratore del proxy...
if
(url.getFile().equalsIgnoreCase("/admin")&&
(url.getHost().equalsIgnoreCase(localHostName)||
url.getHost().equalsIgnoreCase(localHostIP)))
{
//...si
manda al client la pagina HTML contenente l'applet
//per
gestire il proxy
sendAdminPage();
}
-
la richiesta
è per un Web server esterno: in tal caso il proxy controlla se il
sito a cui fa riferimento è uno di quelli da monitorare (informazione
mantenuta nella Config), quindi prosegue con una delle due possibili scelte.
Nel caso in cui il sito debba essere monitorato, si controlla se lutente
deve essere registrato per la prima volta nella banca dati, ed eventualmente
si invia al browser un applet per raccogliere i suoi dati personali. Quindi,
se la richiesta riguarda un file, si controlla se questo è già
stato richiesto altre volte dallutente, e si aggiorna di conseguenza la
struttura dati interna alloggetto Config del proxy. Analogamente, si controlla
anche se il file richiesto è un link del documento che stava leggendo
lutente fino a quel momento, e si apportano le relative modifiche alla
struttura dati interna. Quindi si può inviare la richiesta al Web
server, ed attendere la sua risposta.
//è
una richiesta ad un web-server
{
hostIndex=config.isInHostList(url.getHost());
//se
è un sito da monitorare...
if
(hostIndex>-1) {
body=new
HtmlResponseBody(config,url.toString(),hostIndex);
docIndex=-1;
//
...se non è un sito già sotto osservazione...
if
(!config.isObserved(hostIndex)) {
//...si invia la pagina contenente
//l'applet per il riconoscimento dell'utente
sendUserInfoPage(hostIndex,request);
config.setLastSession(hostIndex);
config.setIsObserved(hostIndex,true);
isLastMessage=true;
}
//sito
già sotto monitoraggio
//si
può inviare la richiesta del client
else
{
//se
è una query...
if
((query=getQuery(url.toString())).length()>0) {
(
) //non gestita
}
//non
è una query
//se
è la richiesta di un documento...
else
if(request.getMethod().equalsIgnoreCase("GET")) {
//...si
controlla il file richiesto
docIndex=config.isInDocList(url.toString(),hostIndex);
//se
è un documento già richiesto...
if
(docIndex>-1) {
//...se
si sta tornando indietro da un link...
if
(docIndex==config.getLastFatherDoc(hostIndex))
//...si
apportano le relative modifiche
//alla
struttura dati della sessione attuale
config.updateInterestFactor(hostIndex,docIndex,2);
else
config.updateInterestFactor(hostIndex,docIndex,1);
}
else
//altrimenti
si aggiorna la struttura
//dati
della sessione attuale
docIndex=config.insertIntoDocList(url.toString(),hostIndex);
//
se è un link del documento precedente...
linkIndex=config.isInLinkList(url.toString(),hostIndex);
if
(linkIndex>-1) {
//
...si apportano le relative modifiche al DB Utenti
//si
aggiorna la struttura dati della sessione attuale
config.updateLinkList(linkIndex,hostIndex);
config.setLastFatherDoc
(config.getLinkFatherDoc(hostIndex),hostIndex);
}
else
//si aggiorna la struttura dati della sessione attuale
config.setLastFatherDoc(-1,hostIndex);
}
//se
si può forwardare la richiesta...
if
(request.getIsToForward()) {
//...si
invia la richiesta al proxy padre o al web-server
//se
non è già stato creato...
if (!isServerSocketAlive)
//...si crea il socket verso il web-server (o verso il
proxy padre)
if (config.getIsFatherProxy())
serverSocket=new Socket(config.getFatherProxyHost(),
config.getFatherProxyPort());
else {
serverName=url.getHost();
serverSocket=new Socket(serverName(request.getUrl()),
serverPort(request.getUrl()));
request.setUrl(serverUrl(request.getUrl()));
}
serverOut=serverSocket.getOutputStream();
serverDataOut=new
DataOutputStream(serverOut);
serverDataOut.writeBytes(request.toString(true));
serverDataOut.flush();
sendRestOfRequestMessage(request,clientIn,serverOut);
Una
volta arrivata la risposta, il proxy effettua un parsing dellheader, tramite
i metodi della classe HttpResponseHdr. Quindi si controlla se il file è
un HTML ed eventualmente, si effettua un parsing del corpo del messaggio,
secondo le specifiche HTML 4.0[ ], tramite i metodi della classe HtmlResponseBody,
con cui si prelevano i link presenti allinterno del documento HTML, e
si aggiorna di conseguenza la struttura dati del proxy. Inoltre si inserisce
allinterno del file HTML un applet nascosto (oggetto della classe TimeCounter)
che servirà a calcolare il tempo che lutente impiega per leggere
il documento stesso. Infine, il file richiesto può essere inviato
al browser che potrà visualizzarlo allutente. Lapplet TimeCounter
è un applet molto semplice. Alla sua attivazione inizia a contare
il tempo che scorre. Quando lutente cambia pagina, lapplet si ferma,
ma non prima di aver calcolato il tempo totale di lettura ed averlo inviato
al proxy tramite il modulo admin server.
//gestione
risposta dal web-server
serverIn=serverSocket.getInputStream();
//parsing
dell'header della risposta del server
response=new
HttpResponseHdr();
response.parse(serverIn);
if
(!isLastMessage)
isLastMessage=response.getIsLastMessage();
//se
il message body non è vuoto ed è completo...
if
((response.getStatusCode().indexOf("200")>-1)||
(response.getStatusCode().indexOf("304")>-1))
{
//...se
è la risposta ad una GET...
if
(request.getMethod().equalsIgnoreCase("GET"))
{
//se
non è codificato...
if
(!response.getIsMessageEncoded())
{
//...se è un file HTML...
if ((response.getContentType().toLowerCase().indexOf("text/html"))>-1)
{
//Si salva la vecchia lista dei link
//relativa al vecchio actualHtmlDoc
config.saveLinkList(hostIndex,docIndex);
//se non lo abbiamo già fatto...
if (!config.isParsed(hostIndex,docIndex))
{
//...Parsing del file alla ricerca dei link
// con cui si aggiorna la struttura
//dati della sessione attuale
String bodyMess=getRestOfResponseMessage(serverIn);
body.parse(bodyMess);
}
//altrimenti abbiamo già in memoria la lista
//dei link presenti nel documento
else
{
config.loadLinkList(hostIndex,docIndex);
body.setMessageBody(getRestOfResponseMessage(serverIn));
}
//inserire un applet per contare il tempo di lettura
//e per aggiornare le strutture dati della sessione attuale
int newLength=body.insertApplet(hostIndex,docIndex,
config.getLocalHost(),
config.getAppletUrl(hostIndex),
config.getAdminPort());
response.setContentLength(newLength);
htmlMonitor=true;
//...si invia al client tutto
//il messaggio ricevuto dal server
clientDataOut=new DataOutputStream(clientOut);
clientDataOut.writeBytes(response.toString(true));
//resto del messaggio (si trova nell'html body)
clientDataOut.writeBytes(body.getMessageBody());
clientDataOut.flush();
}
Se,
invece, la richiesta è per un sito Web che non deve essere monitorato,
allora il proxy non farà altro che inviare la richiesta al Web server
corrispondente. Quindi, una volta avuta la risposta, effettuerà
un parsing del suo header, sempre tramite la classe HttpResponseHdr, ed
invierà la risposta al browser che lha richiesta.
Classe Config
Infine,
descriviamo brevemente anche la classe Config, che gioca un ruolo molto
importante nella gestione dei dati che riusciamo a prelevare dallanalisi
del comportamento dellutente. In essa, infatti, sono mantenuti tutti i
dati che conseguono dallanalisi dei vari movimenti che lutente effettua
durante la navigazione. Questa classe contiene fondamentalmente due tipi
di dati (Fig. 3):
-
dati di
configurazione del proxy;
-
dati di
memorizzazione dei movimenti dellutente.
Nella
prima categoria rientrano sicuramente lindirizzo dellhost in cui gira
il proxy, la sua porta di ascolto, lindirizzo e la porta di un eventuale
ulteriore proxy a cui passare le richieste, invece di indirizzarle direttamente
al Web server, ed altri dati di questo tipo.
Alla
seconda categoria, invece, appartiene il vettore di oggetti della classe
InfoHost (Fig. 4), che rappresenta la lista di siti che devono essere
monitorati.
Ogni
oggetto InfoHost contiene una serie di informazioni associate al singolo
sito Web (host) che si deve monitorare. Tra queste informazioni, oltre
allindirizzo Internet dellhost, sono presenti i dati personali dellutente
(login e password), i valori soglia, descritti nellarticolo precedente,
entro i quali si ritiene corretto il calcolo del tempo di lettura dei file
da parte dellutente, e due liste di oggetti. La prima è una
lista di documenti (oggetti della classe InfoDoc), in cui si mantengono
tutti i file del sito che lutente ha richiesto fino a quel momento. La
seconda, invece, rappresenta la lista di link (oggetti InfoLink) che sono
presenti nellultimo file HTML aperto dallutente in quel sito. Ognuna
di queste liste viene di volta in volta aggiornata dal proxy, man mano
che esso analizza i file letti dallutente, in modo tale da avere sempre
la situazione aggiornata sui suoi movimenti, durante la navigazione allinterno
del sito.
Anche
per oggi abbiamo concluso. Se le idee non vi sono molto chiare, aspettate
fiduciosi la prossima puntata e vedrete che vi si confonderanno ancora
di più, ma alla fine sapremo come realizzare un analizzatore del
comportamento di un navigatore in Internet!
I sorgenti
Cliccando
qui
potete scaricare i sorgenti
 |
Figura
3
 |
Figura
4
|



