Introduzione
In
questo articolo vediamo come è possibile il reperimento di informazioni
tra macchine diverse tra loro sia come hardware che come sistema operativo.
Supponiamo
uno scenario in cui sono presenti PC Windows (NT,95,98), PC con installato
Linux (RedHat, Debian, ... ) , workstation Unix (Solaris,HP,Digital,
)
che devono reperire informazioni da DBMS Oracle 8 e Miscrosoft SQL
Server.
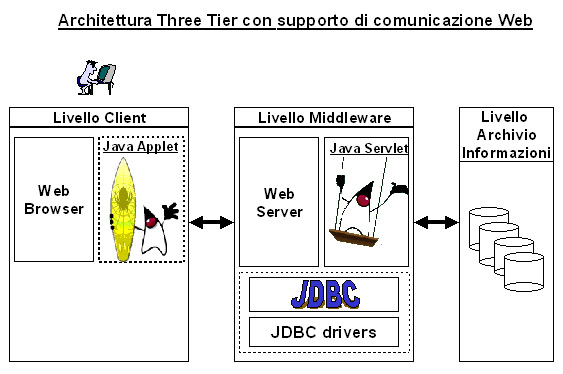
Architettura
L'architettura
di tipo Two-Tier è il modello tradizionale Client/Server, costituito
da un programma client (primo livello) che interagisce direttamente
con il livello di archivio dati (secondo livello).
Sui
client è presente sia il software (librerie e drivers) con cui accedere
al livello archivio dati, sia il software di gestione dell'interfaccia
utente.
Questo
rappresenta il maggior inconveniente dellarchitettura Two-Tier, perché
comporta di installare o scaricare via rete le librerie per accedere ai
DBMS. Inoltre in ambito Web si deve fare i conti con le limitazioni degli
Applet (vedi [1]).
Larchitettura
Three-Tier è un'evoluzione dell'architettura client / server in
quanto è contemplato un nuovo modulo intermedio (middleware) per
la gestione del trasferimento dei dati dal livello client al livello archivio
dati.
Il
modulo middleware rende indipendente il livello client dalle problematiche
di accesso al livello archivo dati.
Essendo
il livello client indipendente dal livello archivio dati, la comunicazione
fra il client e il middleware avviene tramite protocollo standard (HTTP,
RMI, Corba, socket,
)
Nell'architettura
Three-Tier vengono coinvolti tre livelli :
-
il
livello presentazione
-
il livello
intermedio (middleware)
-
il livello
archivio dati
Il
livello di presentazione rappresenta l'interfaccia utente dell'applicazione
nell'intento di acquisire dati e visualizzare i risultati.
Il
livello intermedio si occupa di inoltrare le richieste dell'utente al livello
archivio dati e di trasmettere i relativi risultati.
Il
livello archivio dati rappresenta l'insieme dei servizi offerti da applicazioni
indipendenti dal livello intermedio; nel nostro caso tale livello sarà
costituito da DBMS.
Supporto di comunicazione
Definita
l'architettura, Three-tier, bisogna decidere che supporto di comunicazione
utilizzare.
Si
puo' scegliere tra una svariata gamma di possibilità : Web, RMI,
Corba, DCOM, protocollo proprietario tramite socket, etc
Verrà
utilizzata la tecnologia Web in quanto consente laccesso al livello di
archivio dati tramite un solo strumento : il browser, cioè il programma
utilizzato per sfogliare i contenuti della rete.
In
dettaglio i vantaggi dellutilizzo del supporto di comunicazione Web sono
:
Lato
client:
-
indipendenza
dalla piattaforma del Client
-
ambiente
unico per accedere allapplicazione
-
assenza
di connessione
Lato
Server :
-
il software
dell'applicazione risiede sul Web Server
Indipendenza dalla
piattaforma
L'utilizzo
della tecnologia Web consente di risolvere molti dei problemi tipici delle
architetture client/server relativi al processo di installazione, aggiornamento
e manutenzione del software client, ed al supporto multipiattaforma. Infatti
in ambito Web non cè bisogno di affrontare lo sviluppo dei client
per diverse piattaforme, perché sarà il programma internet
browser a fornire linterfacciamento verso gli applicativi.
Questo
punto è importantissimo, perchè consente di non dover sviluppare
un software specifico per ogni tipo diverso di client.
In
questo modo lapplicazione impone al lato client il solo unico vincolo
di avere unInternet Browser, programma ormai diffusissimo su qualsiasi
macchina, sia essa un PC o una Workstation.
Ambiente
unico per accedere alle applicazioni
Come
conseguenza dellassenza di installazione di software sul client
si ha un'agevolazione dal punto di vista della facilità di apprendimento
e di utilizzo da parte degli utenti. Lambiente usato per accedere agli
applicativi è sempre lo stesso e ha sempre la medesima interfaccia,
quella del browser.
Assenza di connessione
Non
avendo il protocollo HTTP uno stato, non necessita di una connessione persistente
tra client e server e quindi si evitano i problemi tipici delle applicazioni
client-server tradizionali in cui potevano sorgere limiti sul numero degli
utenti simultanei.
Vantaggi lato
Server
Il
software dell'applicazione risiede sul Web Server
Le
operazioni di aggiornamento, manutenzione del software (applicazione, librerie,
driver) interessano esclusivamente il Web Server senza comportare modifiche
sulle postazioni client.
Il
software dell'applicazione che riguarda il lato client verrà scaricato
via rete dal Web Server al momento opportuno.
Le strutture dei
livelli
La
scelta congiunta dell'architettura Three Tier e della tecnologia Web permette
di non dovere installare nessun tipo di software sul client, nè
applicazioni d'interfaccia utente, nè librerie o driver per accedere
al livello archivio dati in quanto presenti nel livello intermedio : il
web server.
Il
supporto di comunicazione Web canonico permette di prelevare documenti
ipertestuali composti da testo ed elementi grafici in una tipica configurazione
client-server. Per attrezzarlo ad elemento di livello middleware, bisogna
sviluppare delle estensioni che permettano la gestione del livello
archivio dati.
Utilizzando
la tecnologia Web come supporto alla comunicazione dell'architetttura Three-tier,
i tre livelli risultano essere composti nel seguente modo :
-
il livello
di presentazione è formato dal programma web browser e dalle sue
estensioni, che svolgono il compito di interfaccia utente;
-
il livello
middleware è costituito dal web server e dalle sue estensioni, per
potere accedere al livello archivio dati;
-
il livello
archivio dati risulta essere composto dalle risorse contenenti le nformazioni
di specifico interesse.
Le estensioni del
browser e del web sever
Per
decidere come sviluppare i programmi di estensione del web browser e del
web server anche qui si ha l'imbarazzo della scelta :
Applet,
ActiveX, Script, CGI, ASP, Servlet ecc
Utilizzando
Applet e Servlet Java si ottiene il risultato di indipendenza dalla piattaforma
rispettivamente sia sul livello di presentazione che sul livello middleware.
Per
eseguire un codice Java, si deve utilizzare un programma per interpretare
il bytecode chiamato macchina virtuale Java (JVM - Java Virtual Machine
che provvede all'esecuzione del programma.
Un
Applet è un file bytecode, scaricato via rete dal Web server, ed
interpretato dalla JVM del browser. Tutti i browser ormai hanno incorporato
una JVM rendendo gli Applet eseguibili su qualsiasi piattaforma. Le Applet
costituiranno l'interfaccia grafica d'utente, (GUI - Graphical User Interface)
dell'applicazione traducendo le scelte grafiche dell'utente mediante bottoni,
caselle o pulsanti, in richieste HTTP verso il Web Server.
Per
quanto riguarda il livello middleware verranno utilizzate le Servlet.
Un
Java Servlet può essere pensato come un Applet lato server : esso
viene eseguito all'interno di un Web server così come un Applet
viene eseguito all'interno di un Web Browser.
La
caratteristica più importante di un servlet è che, contrariamente
ad un programma standard CGI (scritto in PERL, in C o in C++) non viene
creato un processo ogni volta che il client effettua la richiesta, ma solamente
a quella iniziale.
L'utilizzo
lato client degli Applet e lato server dei Servlet richiede la conoscenza
di una sola tecnologia : Java.
Ottenuta
l'indipendenza dalla piattaforma,è possibile ottenere l'indipendenza
dal tipo di DBMS mediante l'utilizzo di JDBC.
JDBC
è una Java API (Application Program Interface) per lesecuzione
di istruzioni SQL. Esso consiste in interfacce, scritte con il linguaggio
di programmazione Java, che consentono di sviluppare applicazioni che utilizzano
database relazionali ed a Oggetti.
Come
le API degli Applet e delle Servlet permettono lindipendenza dalla piattaforma
della macchina, quelle JDBC permettono lindipendenza dal tipo di DBMS
(Miscrosoft,Oracle,Interbase, ecc) . Il programmatore Java può utilizzare
JDBC per la scrittura delle proprie applicazioni senza preoccuparsi del
database che sta utilizzando. Questo è possibile perché le
differenze tra i vari database vengono gestite dal software del driver
specifico di quel database.
Le
servlet utilizzeranno JDBC per accedere ai DBMS del livello archivio dati.
JDBC URL e JDBC
drivers
Con
JDBC i database vengono localizzati in rete utilizzando un proprio URL.
Il
formato generico del JDBC URL è :
Jdbc:
<subProtocol > : <subname >
-
Jdbc :
indica il protocollo del JDBC URL
-
SubProtocol
: indica il meccanismo di accesso al database
-
SubName
: identifica il database a secondo del SubProtocol
Gli URL
JDBC hanno un formato differente a secondo del driver che si utilizza.
Ci
sono 4 tipi diversi di driver in Java :
-
Tipo
1 - JDBC-ODBC bridge più ODBC driver
E'
il driver che effettua un "ponte" tra le chiamate alle API JDBC Java e
le chiamate alle API ODBC scritte in linguaggio C. Tale driver sfrutta
ODBC (Open Data Base Connectivity), uno standard Microsoft consolidato
e diffuso che consente di astrarre dai protocolli specifici dei produttori
di database, fornendo un'interfaccia di programmazione comune alle applicazioni
dei client di database.
-
Tipo
2 - Native API partly Java Driver
Questo
tipo di driver converte le chiamate alle API JDBC in chiamate API client
del protocollo nativo del particolare database. Ad esempio, nel caso di
Oracle, le chiamate JDBC sono tradotte secondo il protocollo Oracle SQL
NET.
-
Tipo
3 - JDBC-Net pure Java driver
Questo
driver traduce le chiamate al JDBC in chiamate a gestori di database tramite
un protocollo di rete standard. Tali chiamate sono poi tradotte dal gestore
nel protocollo specifico del DBMS a cui ci si collega.
-
Tipo
4 - Native-protocol pure Java Driver
Questo
tipo di driver è scritto interamente in Java e usa il protocollo
di database specifico per il quale è stato progettato per comunicare.
I fornitori
di questo tipo di driver sono gli stessi del DBMS.
Vengono
riportati degli esempi di formato di JDBC URL.
-
Driver
ODBC
Nome
classe driver : sun.jdbc.odbc.JdbcOdbcDriver
Tipo
di driver : 1
Formato
JDBC-URL : jdbc:odbc:<DSN>","username","password"
Es
di utilizzo :
Class.forName(sun.jdbc.odbc.JdbcOdbcDriver);
con
= DriverManager.getConnection("jdbc:odbc:MySqlServerDb","sa","");
-
Driver
Oracle Thin
Nome
classe driver : oracle.jdbc.driver.OracleDriver
Tipo
di driver : 4
Formato
JDBC-URL : jdbc:oracle:oci8:<database>","username", "password"
Es
di utilizzo :
Class.forName(oracle.jdbc.driver.OracleDriver);
con
= DriverManager.getConnection("jdbc:oracle:oci8:<database>","scott",
"tiger");
Servlet e
JDBC
L'impiego
di Java servlet che utilizzano JDBC comporta i seguenti vantaggi :
-
indipendenza
dalla piattaforma della macchina Web server
-
indipendenza
dal tipo di database da interrogare
-
indipendenza
dalla struttura del database
Ricapitolando,
i vantaggi dell'applicazione Web Three-Tier con utilizzo di Applet, servlet
e JDBC java dal punto di vista del c lient (Browser + Applet ) sono
-
Indipendente
dalle problematiche di accesso al livello ArchivioDati
-
Ambiente
unico per accedere alle applicazioni (browser)
-
Nessuna
installazione di software sulla macchina Client
-
Nessun
problema di aggiornamento software
-
Indipendente
dalla piattaforma
-
Come unico
requisito si richiede che la postazione client abbia un Web browser
Lato Middleware
(Servlet + Jdbc ) invece i punti a favore di questo tipo di organizzazione
sono
-
Contiene
il software necessario per accedere al livello ArchivioDati
-
Contiene
il software interfaccia utente (Applet)
-
Il software
e centralizzato (manutenibile)
-
Indipendente
dalla piattaforma
-
Indipendente
dal tipo di Data Base
-
Indipendente
dalla struttura del Data Base
-
Estensione
dei dati dei DBMS a qualsiasi client browser
I requisiti
da soddisfare sono due : Web Server che supporta Java Servlets ed avere
i JDBC drivers
Queste
scelte permettono di poter estendere facilmente informazioni contenute
in DBMS eterogenei (livello archvio dati) e client eterogenei (livello
di presentazione) mediante la mediazione del Web Server (livello intermedio)
senza richiedere nessuna installazione specifica di SW sulle macchine client.
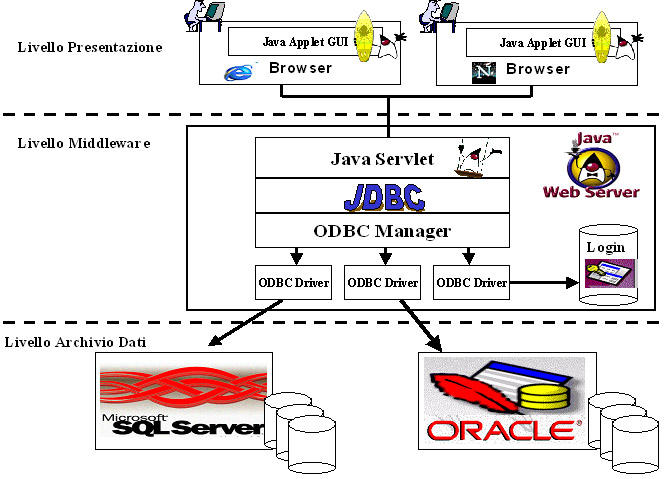
 |
Figura
1
Prodotti utilizzati
 |
Figura
2
Browser
L'applicazione
delineata fino a questo momento richiede che su ogni macchina client sia
presente un web browser come Netscape o Explorer.
Web Server
Di
Web server se ne può utilizzare uno qualsiasi purché supporti
i Java Servlet.
Il
Web server scelto nel mio caso è il Java Web Server 2.0 (JWS) prodotto
dalla SUN e scritto interamente in Java. La scelta è stata effettuata
in quanto il JWS è gratuito e supporta i Java servlet in modo nativo.
Attualmente
i Servlet sono supportati in modo nativo solo da Web server scritti in
Java, mentre gli altri Web server devono ricorrere all'utilizzo di programmi
servlet engine, ovvero motori per l'esecuzione di servlet. Tali programmi
permettono di legare la JVM al web server per l'esecuzione dei servlet.
Per
avviare il Java Web server, ovvero per mandare in esecuzione la demon task
di ascolto sulla porta TCP specificata in attesa di richieste di connessioni
da parte del client, bisogna digitare da finestra di DOS il seguente comando
: home_server/bin/httpd.
Una
volta in esecuzione, il Web Server è in ascolto sulla porta TCP
8080. Il numero della porta è configurabile. In origine tale porta
è l'8080 e permette di utilizzare il JWS anche su macchine in cui
sia già installato un servizio Web attivo sulla porta 80 (il numero
usuale della porta per un server HTTP).
Una
volta avviato, è possibile effettuare le configurazioni collegandosi
alla porta 9090 dove un'Applet permette di gestire il setup del Web Server.
Tra
queste operazioni è anche possibile installare nuovi servlet. Per
quanto riguarda l'installazione di un servlet, si seguano le istruzioni
del particolare web server utilizzato: in genere l'operazione si traduce
nel copiare i file compilati dei servlet (file di formato bytecode e di
estensione class) nella directory assegnata dal Web server.
JDBC Driver
Come
driver JDBC ho utilizzato il driver JDBC-ODBC perché consente di
utilizzare i drivers ODBC esistenti senza doversi preoccupare di dover
reperire (comprare o scaricare da Internet) driver specifici per l'accesso
a DB. Per questo motivo ODBC è l'interfaccia API più usata
per accedere a database relazionali.
Questo
driver rappresenta una garanzia di diffusione del prodotto essendo distribuito
dalla Microsoft.
I
drivers ODBC sono facili da reperire e già disponibili nei Sistemi
Operativi Microsoft, come Windows NT, che è il Sistema Operativo
su cui si è installato il JWS.
L'utilizzo
del driver JDBC-ODBC va bene nel nostro caso avendo adottato un'architettura
Three-Tier, nel caso di architetture client-server dove si acede ai DBMS
tramite Applet si raccomanda l'utilizzo dei dirver di tipo 4 (i driver
scritti interamente in Java) per mantenere l'indipendenza dalla piattaforma.
Il
servlet per accedere ad un DB tramite driver ODBC dovrà specificare:
sun.jdbc.odbc.JdbcOdbcDriver
come nome della classe driver da utilizzare, mentre jdbc:jdbcOdbc:<DSN>
come Jdbc Url del Db da interrogare; dove <DSN> è il nome della
fonte dati del driver ODBC.
Come configurare
un DSN
Apriamo
una parentesi inerente la configurazione dei DNS.
Per
utilizzare i drivers ODBC bisogna configurare l'ODBC manager che è
il modulo gestore dei drivers ODBC. I driver ODBC sono DLL che vengono
caricate dinamicamente dall'ODBC manager al momento del loro utilizzo.
L'applicazione
per utilizzare il driver ODBC deve esplicitare solamente il nome mnemonico
a lui associato tramite il DSN.
Per
definire una sorgente dati è possibile (in Windows) utilizzare l'ODBC
Administrator: un'apposita applicazione presente all'interno del pannello
di controllo di Windows. Utilizzando l'ODBC Administrator è possibile
creare delle fonti dati ODBC dette DSN (Data Source Name) con le quali
è possibile associare un nome logico al database.
Vediamo
ora come configurare tre DSN relativi a tre tipi di drivers diversi.
I
tre DSN si riferiscono ai 3 database che andremo poi a interrogare:
il
database Access 97 login.mdb che è locale al Web Server e contiene
tutte le associazioni username e password degli utenti abilitati ad accedre
al servizio
un
database Oracle 8 ed un database Miscrosoft SQL Server.
I
nomi dei DSN sono rispettivamente: login, ora8Test e ambulatorio.
Ricordo
che i nomi dei DSN sono nomi logici che possono non avere niente
a che vedere con i nomi effettivi dei database.
La
prima operazione da effettuare in ambiente Windows per configurare un DSN
è quella di selezionare l'icona ControlPanel e poi 32 ODBC (l'ODBC
Manager)
Scegliere
la cartella SystemDSN (fig.3(1)) e premere il pulsante ADD (fig.3(2)).
Viene
visualizzata la finestra dei drivers ODBC disponibili.
(fig.3(3))
Scegliere il Microsoft Access Driver (*.mdb) e premere il tasto FINISH.
Quando
compare la pagina di installazione dell'ODBC Microsoft Access, assegnare
il nome logico della fonte dei dati che nel nostro caso è login
(fig.3(4)).
Premere
il tasto SELECT (fig.3(5)) e selezionare il file mdb ((fig.3(6)) di interesse
(nel nostro caso è login.mdb).
Validare
l'operazione con il pulsante OK.
Ritornare
all'ODBC Manager e premere nuovamente ADD.
Scegliere
il driver Microsoft ODBC Driver for Oracle (fig.3(7)).
Compare
il pannello di installazione nel quale si deve inserire (fig.3(8)) :
q
nome del DSN (nel nostro caso ora8Test)
q
UserName (username / password)
q
Coonect string (il DB Alias)
Validare
l'operazione con il pulsante OK.
Ritornare
nell'ODBC Manager per configurare l'utlimo DSN e schiacciare nuovamente
ADD.
Scegliere
il driver SQL Server (fig.3(9)).
Compare
il pannello di installazione nel quale si deve inserire (fig.3(10)) :
q
nome del DSN (nel nostro caso mySqlSrv7)
q
server (nome del server)
q
indirizzo IP del server
q
Network Library (protocollo da utilizzare per la connessione)
Validare
l'operazione con il pulsante OK.
A
questo punto, nel pannello System DSN compaiono, pronte per l'utilizzo,
le tre fonti di dati create (fig.3 - punto 11).
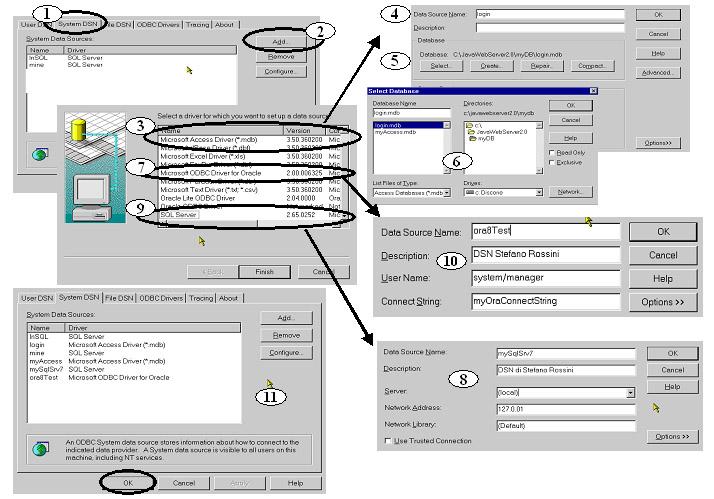 |
Figura
3
Il
nome logico (DSN) deve essere usato nel codice Java per riuscire a connettersi
a tale database.
Su
piattaforma Windows il driver JDBC-ODBC è contenuto nel file jdbcodbc.dll
che deve risiedere nella directory : java_home/bin.
DBMS
Come
DBMS verrà provato Oracle 8 e Microsoft SQL Server e Access 97.
Bibliografia
[1]
Giovanni Puliti, "Jdbc : la teoria", Giugno 1997
[2]
Giovanni Puliti, "Servlet, Jdbc e JavaServer", Giugno 1998
|



