Introduzione
Questo
modulo, come già accennato, si occupa di interfacciare il proxy,
che raccoglie i dati relativi allutente, con la banca dati in cui questi
devono essere memorizzati e dove, in generale, devono essere mantenute
le caratteristiche comportamentali dellutente.
In
particolare, il Demone è un thread creato ed avviato dal proxy
server, ed il suo scopo è quello di attivarsi ad unora precisa
della giornata per inviare i dati, accumulati fino a quel momento, alla
banche dati degli utenti di tutti i siti monitorati dal proxy. Il demone
viene attivato anche quando il proxy server viene chiuso ed è implementato
attraverso le classi DaemonThread e SaverThread.
Classe DaemonThread
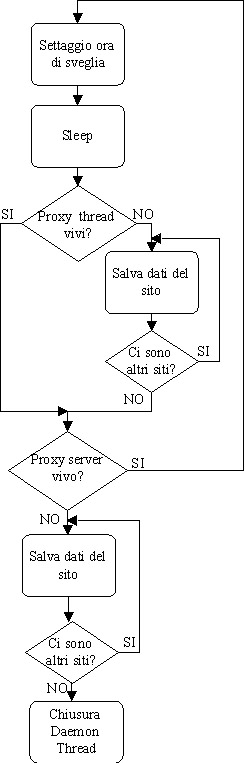
Lalgoritmo
utilizzato per implementare il DaemonThread è descritto nella fig.
1. Come si può vedere, questo thread non fa altro che settare lora
del suo risveglio e quindi addormentarsi fino a tale momento. Quando si
sveglia, se non ci sono thread del proxy che girano, cioè se non
ci sono richieste da parte del browser da gestire, per ogni sito monitorato,
avvia il thread (SaverThread) che si occupa di elaborare i dati raccolti
sui movimenti dellutente. Quindi configura nuovamente lorario di risveglio
e torna a dormire. Questo ciclo continua finché il proxy server
è vivo.
//loop
fino a che il proxy-server è attivo
while(config.getServerAlive())
{
now=new Date();
thisHour=now.getHours();
thisMin=now.getMinutes();
startTime=(((startHour*60)+startMin)*60);
if (thisHour<startHour)
{
thisTime=(((thisHour*60)+thisMin)*60);
sleepTime=(startTime-thisTime)*1000;
}
else if (thisHour>startHour)
{
thisTime=(((thisHour*60)+thisMin)*60);
sleepTime=((86400-thisTime)+startTime)*1000;
}
else
{
if (thisMin<startMin)
sleepTime=(startMin-thisMin)*60000;
else
sleepTime=0;
}
sleep(sleepTime);
//se non ci sono thread che girano
if (config.getThreads()==0)
saveData();
}//Fine loop
private
void saveData()
{
InfoHost actualHost;
int numHost=config.getNumHost();
for(int i=0; i<numHost; i++)
{
actualHost=config.getInfoHost(i);
SaverThread saverThd=new SaverThread(this,actualHost);
saverThd.start();
openThread();
}
}//fine saveData
Quando
il proxy server muore, il demone, prima di chiudersi, tramite il SaverThread,
salva unultima volta i dati raccolti sul comportamento dellutente.
Il
motivo per cui il DaemonThread decide di comunicare i dati alle banche
dati solo se non ci sono thread del proxy che girano, deriva dal fatto
che, in caso contrario, i thread del proxy che gestiscono le richieste
dellutente andrebbero a modificare gli stessi dati che il demone deve
comunicare alle banche dati. Vi sarebbe quindi un conflitto nella gestione
delle risorse (i dati stessi) da parte dei due diversi thread, ed inoltre
i dati trasmessi potrebbero risultare non corretti rispetto alle nuove
azioni che lutente sta effettuando e che il proxy sta ancora analizzando.
In questo caso è preferibile che il demone non si attivi ed aspetti
che tutti i thread del proxy si siano chiusi prima di agire.
Figura
1
Classe SaverThread
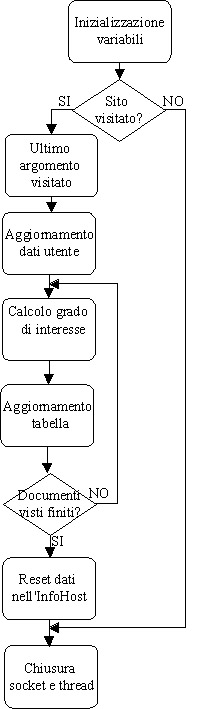
Questo
thread viene creato ed avviato dal DaemonThread ogni volta che devono essere
salvati i dati raccolti sulle azioni dellutente. Il suo comportamento
è molto semplice (si veda lalgoritmo in fig. 2): per ogni sito
da monitorare, si controlla se lutente ha fatto qualche accesso al sito
durante lultima sessione di navigazione svolta. Se ciò è
avvenuto, saranno presenti nella struttura dati del proxy (classe Config)
dei nuovi elementi da elaborare per aggiornare la banca dati degli utenti,
associata a tale sito. Il thread inizia, quindi, a comunicare con la banca
dati. Per prima cosa si determina qual è largomento associato allultimo
documento visitato dallutente. Quindi si aggiornano i dati dellutente
nel database (si aggiorna la data dellultima sessione aperta e largomento
associato a tale sessione). Quindi si considerano tutti i documenti visitati
dallutente allinterno del sito Internet e, per ognuno di essi, si calcola
il valore da dare al grado di interesse dellutente per tale documento.
Nel
calcolo di tale valore, si tiene conto di tutti i dati raccolti sullo studio
che lutente ha fatto del documento considerato. I dati a nostra disposizione
sono:
-
il tempo
totale di lettura del documento (TL);
-
il numero
di volte che il documento è stato letto (N);
-
il numero
di link presenti nel documento che sono stati seguiti dallutente (NL);
-
un fattore
di interesse, che tiene conto del fatto che un utente è tornato
sul documento dopo aver seguito uno dei suoi link (FI);
-
il tempo
massimo considerato valido per la lettura di un documento: di default tale
valore è pari ad 1 ora (TMAX);
-
il tempo
minimo valido per la lettura del documento: per default vale 20 secondi
(TMIN);
-
il numero
di volte che lutente ha letto un qualsiasi documento del sito Internet
(ND);
-
il numero
totale di link presenti nel documento (NT).
Tutti
questi dati sono mantenuti per ogni documento che lutente ha visitato
nelle classi InfoHost, InfoDoc ed InfoLink. In particolare i valori TMAX
e TMIN rispecchiano le considerazioni che erano state fatte nel primo di
questi articoli sullanalizzatore comportamentale, in cui si rifletteva
sulla possibilità che un utente aveva di distrarsi e che poteva
portare a delle valutazioni errate delleffettivo tempo di lettura di un
documento. Tramite questi valori si giunge a calcolare un valore (V) da
dare al grado di interesse dellutente per largomento legato al documento,
tramite la seguente formula empirica:
V
= (0,3*tFactor+0,4*dFactor+0,3*lFactor)*(1+FI);
dove
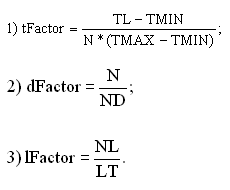
Il
primo fattore (tFactor) tiene conto del tempo impiegato dallutente per
leggere il documento; il secondo fattore (dFactor), invece, tiene conto
del numero di volte che il documento è stato letto in relazione
a tutti i documenti del sito letti dallutente; infine il terzo fattore
(lFactor) considera il numero di link presenti nel documento che lutente
ha deciso di seguire, rispetto a tutti i link contenuti nel documento stesso.
Inoltre, nel calcolo finale del valore V, si considera anche il fattore
di interesse FI che tiene conto del fatto che lutente è tornato
indietro al documento attuale dopo aver seguito uno dei suoi link. Come
già spiegato nel primo articolo, questo comportamento dellutente
può essere indice di un particolare interesse per il documento in
oggetto. Comunque, queste formule sono del tutto empiriche e quindi possono
essere soggette a modifiche che risultino utili per arrivare ad una valutazione
più accurata dellinteresse dellutente nei confronti dei concetti
espressi dai documenti del sito monitorato.
//se
l'attuale host considerato
//ha
delle modifiche da salvare
int
numDoc=actualHost.getNumDoc();
if
(numDoc>0)
{
//ND=numero di volte che l'utente ha letto un qualsiasi
// documento del sito
int ND=actualHost.countDocRead();
//inserire i dati nel DB utenti
t3toper=new ThreeTierOperator(actualHost.host,
actualHost.dbPort);
//si prende l'argomento associato all'ultimo
//documento letto dall'utente
int arg=t3toper.getArgument(actualHost.getLastDoc());
login=actualHost.getLogin();
password=actualHost.getPassword();
//aggiornamento tabella UTENTE REALE
t3toper.updateUserData(login,
password,
actualHost.getLastSession(),
arg);
//per ogni documento visitato nell'host...
for (int i=0; i<numDoc; i++)
{
actualDoc=actualHost.getDoc(i);
//...si preleva il numero di link del documento
//seguiti dall'utente
int numLink=actualDoc.getFollowedLink();
//aggiornamento valutazioni della conoscenza
//e degli interessi dell'utente
//***VALUTAZIONE DEL PUNTEGGIO***//
//se indichiamo con
//V=valore finale del punteggio
//TL=Tempo di lettura
//N=numero di volte che il documento è stato letto
//NL=numero di link del documento seguiti
//FI=fattore di interesse
//TMAX=tempo massiomo considerato per la lettura (1ora)
//TMIN=tempo minimo considerato per la lettura
//
(20 secondi)
//ND=numero di volte che l'utente ha letto un qualsiasi
// documento del sito
//LT=Numero di link totali, per ogni documento
//si ha che V=f(TL,N,NL,FI,TMAX,TMIN,ND,LT)
//V=(0.3*tFactor+0.4*dFactor+0.3*lFactor)*FI
//tFactor=(TL-TMIN)/(N*(TMAX-TMIN))
//tFactor=TL/N
//dFactor=N/ND
//lFactor=NL/LT
float tFactor=actualHost.getTimeFactor(i);
float dFactor=(float)actualDoc.numbOfTime/ND;
float lFactor=0;
int totLink=0;
if ((totLink=actualDoc.getListLength())>0)
lFactor=(float)numLink/totLink;
value=((3f/10)*tFactor+
(4f/10)*dFactor+(3f/10)*lFactor)*
(actualDoc.interestFactor+1)*100;
t3toper.updateUserInterest(login,
actualDoc.fileName,
value);
}
Figura
2
Schema Three-Tier
Per
collegarsi e scaricare i dati con la banca dati, si utilizza un insieme
di classi che realizzano uno schema di accesso al database detto three-tier[
], che, per completezza di esposizione, descriveremo brevemente, facendo
riferimento alla fig. 3.
Come
si può vedere da tale schema, le applicazioni che devono accedere
alla banca dati, girano su una macchina differente da quella su cui si
trova la banca dati stessa. Per accedere al database, quindi, si è
utilizzato un sistema three-tier, in cui lapplicazione si interfaccia
con una classe (ThreeTierOperator) che si incarica a sua volta di inviare
la richiesta al database.
Questa
classe (client) comunica, tramite un opportuno protocollo (fig. 4) su socket,
con il server del database: la classe ThreeTierServer. Questo server è
sempre in ascolto sul socket, e quando riceve una richiesta avvia un thread
che la gestisce, il ThreeTierHandler. Ad esso viene passato il socket,
su cui avviene la comunicazione tra il client e il server, e la richiesta
stessa a cui deve rispondere.
Fig.
3
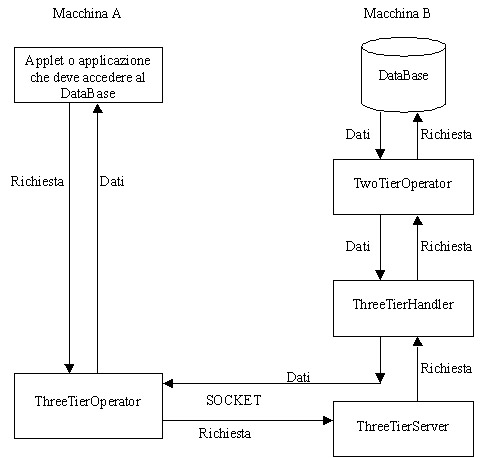
Figura
3
Le
richieste vengono inviate sul socket tramite un codice numerico, per semplificare
i messaggi che devono viaggiare su rete. Il thread decodifica il messaggio
ricevuto sul socket, ed invoca unultima oggetto, il TwoTierOperator, che
è linterfaccia del database per tutte le applicazioni locali al
database stesso, passandogli la richiesta decodificata. Il TwoTierOperator
effettua, tramite la libreria JDBC, la richiesta al database, ne ottiene
la risposta e la invia al ThreeTierHandler che, dopo averla ridotta ad
una semplice stringa di caratteri, la invia sul socket al client (ThreeTierOperator)
che la stava aspettando. Il ThreeTierOperator, infine, invierà la
risposta allapplicazione che aveva effettuato la richiesta di accesso
al database.
Come
si è visto, le classi ThreeTierOperator e TwoTierOperator, rappresentano
delle interfacce attraverso cui le applicazioni non locali o locali possono
accedere alla banca dati degli utenti. Tali interfacce mettono a disposizione
allesterno ben 6 metodi che implementano diverse istruzioni da effettuare
sulla banca dati:
-
insertNewUser:
inserisce i dati (nome, cognome, età, categoria) di un nuovo utente
che si collega per la prima volta al sito e restituisce il login che viene
associato a tale utente;
-
getUserAt:
controlla lesistenza di un record associato ad un utente, identificato
da un login e da uneventuale password;
-
getArgument:
preleva il codice associato ad un certo argomento, di cui si passa una
descrizione testuale;
-
updateUserData:
aggiorna i dati associati ad un utente, di cui si indica il login e la
password; principalmente serve per aggiornare lultima sessione aperta
dallutente e lultimo argomento da lui visitato;
-
updateUserInterest:
aggiorna i valori di interesse dellutente sullargomento visitato e sui
concetti approfonditi dallutente durante lultima sessione. Tali aggiornamenti
sono effettuati calcolando una media pesata tra i valori nuovi e quelli
già presenti nella banca dati, secondo la seguente formula empirica:
GradoInteresse=0,35*GradoInteresse+0,65*ValoreNuovo
-
updateAverageUser:
aggiorna i valori di interesse di un utente fittizio, cosiddetto medio,
che rappresenta una categoria di utenti a cui lutente attualmente considerato
appartiene; laggiornamento dei valori prevede una media pesata dei valori
di interesse dellutente considerato con quelli attuali dellutente medio
che si sta aggiornando, secondo la seguente formula empirica:
UtenteMedio=0,8*UtenteMedio+
0,2*UtenteReale
-
UpdateAllUser:
aggiorna i valori di interesse di ogni utente ed è utilizzato dal
thread DaemonDBThread. Questo demone si attiva una volta al giorno e, tramite
questo metodo, ogni valore viene diminuito per tenere conto del fatto che
con il passare del tempo linteresse di un utente verso gli argomenti trattati
nel sito diminuisce, se non viene confermato dallaccesso al sito. Ogni
valore viene quindi cambiato secondo la seguente formula:
GradoInteresse=0,9*GradoInteresse.
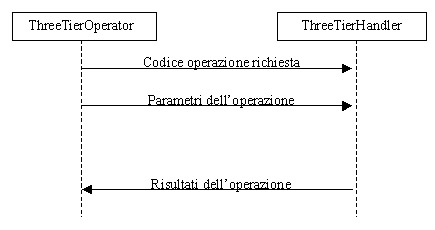
Figura
4
Con
questa breve descrizione del sistema di accesso al database, si conclude
la presentazione dellagente analizzatore di movimenti di un utente di
Internet. Sperando che largomento non vi abbia annoiato troppo, e che
magari possa essere di aiuto a qualcuno di voi, vi saluto e vi auguro buon
lavoro!
.
|



