Introduzione
Presentati
ufficialmente poco più di un anno fa da Sun, gli Enterprise Java
Beans (EJB) stanno risquotendo un successo a dir poco incredibile. Oltre
ad essere sulla bocca di tutti i vari Java-guru, o nei numerosi comunicati
stampa, è altresì vero che la maggior parte delle aziende
ha da tempo dirottato una parte congrua delle proprie energie per produrre
server per EJB, oppure tecnologia di vario tipo che si interfacci
con tali componenti.
Dovendo
fare una panoramica completa ed esaustiva sullargomento sarebbe necessario
molto più spazio di quello a disposizione, sia per la vastità
dei temi che per la complessità di certi passaggi. Cercheremo quindi
di dare una visione il più possibile esaustiva, dellargomento,
rimandando per gli approfondimenti a [1] e [2].
Come
spesso accade nel mondo Java, largomento per quanto interessate non è
in fin dei conti niente di radicalmente innovativo, basandosi su concetti
ormai ben noti, anche se la visione alla Java ne conferisce aspetti decisamente
interessanti.
Da
un punto di vista architetturale EJB non è che un altro modo di
vedere e di implementare il modello della computazione distribuita, della
quale nel corso degli anni si sono viste numerose variazioni sul tema.

Figura
1: il logo di EJB
Fra
le molte soluzioni proposte negli ultimi tempi, una delle più famose
è quella basata sugli oggetti distribuiti, i quali possono essere
eseguiti in remoto e su più macchine indipendenti fra loro.
Questo
settore però già prima degli EJB offriva importanti alternative:
da un lato infatti la Remote Method Invocation (RMI, vedi [3]) introdotta
con il JDK 1.1 permette in maniera piuttosto semplice la realizzazione
di architetture distribuite full-Java ed è di fatto la soluzione
più semplice disponibile fino alla comparsa di EJB. Parallelamente
troviamo CORBA, attualmente il più versatile, eterogeneo, potente
ma anche complesso sistema di gestione degli oggetti remoti e distribuiti
(non prenderemo in considerazione MTS di Microsoft che non può essere
preso come esempio di tecnologia distribuita, visto che limita il suo utilizzo
alla piattaforma Windows).
 Verrebbe
da chiedersi quindi a cosa possa servire un nuovo modello di oggetti distribuiti,
oppure cosa introduca di nuovo rispetto a quanto disponibile sul mercato. Verrebbe
da chiedersi quindi a cosa possa servire un nuovo modello di oggetti distribuiti,
oppure cosa introduca di nuovo rispetto a quanto disponibile sul mercato.
Ebbene
la differenze fondamentale è data dal supporto dato per la realizzazione
applicazione distribuite. RMI e CORBA infatti sono semplicemente dei motori
di oggetti distribuiti (solo Java nel primo caso, language-neutral nel
secondo), ed i cosiddetti ditribuited object services devono essere implementati
a mano o forniti per mezzo di software terze parti. Nel modello degli EJB
invece tutto quello che riguarda la gestione dei servizi è disponibile
e, cosa ancora più importante, utilizzabile in maniera del tutto
automatica e trasparente agli occhi del client.
Per
servizi si intende in genere tutte quelle funzionalità atte alla
implementazione dei seguenti aspetti:
-
Transazioni:
le transazioni sono un insieme di operazioni che devono essere svolte in
maniera atomica, oppure fallire totalmente. La modalità transazionale
è particolarmente importante nel mondo del commercio elettronico,
e nella maggior parte delle casistiche reali. I container EJB offrono un
sistema automatico per la gestione delle transazioni.
-
Security:
quando si ha a che fare con modelli distribuiti, la gestione della sicurezza
è uno degli aspetti più importanti. Nel modello EJB viene
fornito il supporto offerto dal modello della security della piattaforma
Java 2.
-
Scalabilità:
la filosofia con cui EJB è stato progettato, e soprattutto
la modalità con cui opera, permette la massima flessibilità
e scalabilità in funzione del traffico dati e del numero di clienti
(ad esempio quali, quanti e come i vari bean vengano forniti ai vari client
è un meccanismo gestito automaticamente dal server).
Da notare
che EJB si appoggia ad RMI del quale utilizza le funzionalità
e la filosofia di base per realizzare strutture distribuite, estendendone
come visto i servizi in maniera trasparente.
La
specifica di EJB definisce una architettura standard per limplementazione
della business logic in applicazioni multi-tier basate su componenti
riusabili. Tale architettura è basata essenzialmente su tre componenti:
i server, i container ed i client.
Il
server EJB ha lo scopo di incapsulare tutto quello che sta sotto
lo strato EJB (applicazioni legacy, servizi distribuiti) e di fornire ai
contenitori una serie di servizi di base per i vari componenti installati.
Il
contenitore invece è stato progettato per offrire una serie di funzionalità
legate al life-cycle dei vari componenti, la gestione delle transazioni,
e il security-management. Grazie allintercettazione delle chiamate dei
metodi effettuate dai vari clienti, il contenitore è in grado di
gestire le transazioni che si instaurano fra chiamate successive, relativamente
a contenitori differenti e server in esecuzione su macchine diverse. Lo
sviluppatore di un componente EJB può quindi concentrarsi sui dettagli
implementativi della business logic, tralasciando gli aspetti legati alla
gestione, dato che sono a carico del contenitore. Lunica cosa che deve
fare chi sviluppa un componente è implementare una serie di interfacce
standard. Il client infine rappresenta lutilizzatore finale del componente.
La visione che ha del componente è resa possibile grazie a due interfacce
(Home interface e Remote interface), la cui implementazione è effettuata
automaticamente dal container al momento del deploy del bean stesso. La
Home interface fornisce i metodi relativi alla creazione del bean, mentre
laltra implementa la business logic. Implementando queste due interfacce
ed i loro relativi metodi, il container è in grado di intercettare
le chiamate provenienti dal client, ed al contempo fornendogli una visione
semplificata del componente stesso. Il client non ha la percezione
di questa interazione da parte del container:
il vantaggio è quindi quello di offrire in modo indolore, la massima
flessibilità, scalabilità oltre ad una non indifferenze semplificazione
del lavoro da svolgere.

Tipologie di EJB
Due
sono i tipi di Enterprise Java Beans: i session beans e gli entity bean.
Il primo tipo rappresenta un collegamento con il client e soprattutto linterazione
con esso; rappresenta una estensione logica del programma client.
In
genere i bean di questo tipo implementano una sequenza di operazioni allinterno
di una transazione.
Gli
entity beans invece rappresentano dati specifici o collezioni di dati.
In genere forniscono metodi per linterazione con i dati che essi stessi
rappresentano. Questo tipo di componenti sono persistenti, dato che restano
in vita per tutto il tempo che sono memorizzati allinterno del db.
I Session Beans
Ci
sono due tipi di entity beans: stateless e stateful. Il primo tipo
non mantiene nessun tipo di informazione fra due invocazioni dei suoi metodi
da parte del client, e per ciò questo tipo di bean è in genere
utilizzato per eseguire operazioni atomiche, indipendenti dal contesto
nel quale vivono.
Sono
detti beans amorfi dato che le varie istanze dello stesso
bean sono del tutto equivalenti fra loro, e di fatti per ottimizzare le
prestazioni, alcuni server istanziano un set di bean stateless implementando
una gestione a pool.
Fra
tutti i tipi di beans, questi sono i più semplici, leggeri e facili
da utilizzare. Laltro tipo invece, i bean stateful, sono in grado di memorizzare
uno stato fra due invocazioni del client, permettendo fra le altre cose
una politica di gestione delle transazioni.
Ogni
bean di questo tipo è associato ad uno ed un solo client. Tipicamente
la gestione dello stato viene effettuata automaticamente dalla coppia
server-container, quindi riducendo drasticamente il lavoro che si deve
svolgere in fase di sviluppo sia del client che del bean stesso.
E
da notare tuttavia che i session beans non sono stati progettati per essere
persistenti, né gli stateful né gli stateless:
i dati che infatti essi memorizzano sono intesi relativamente ad una particolare
sessione o client. E per questo motivo che un session beans non può
sopravvivere a crash di sistema o semplici restart del server; infatti
il cosiddetto handle del bean, riferimento creato allinterno del container
per accedere a quel particolare bean, viene perso nel momento in cui il
client muore o la sessione finisce.
Nel
caso in cui il client necessiti di riutilizzare un bean rimosso, deve utilizzare
le informazioni in suo possesso (sul lato client) per poter ricreare il
componente sul server.
Gli Entity Beans
Si
è detto che un Entity è un bean progettato per
la rappresentazione di strutture dati nel server, strutture
dati messe a disposizione per elaborazioni particolari o per lutilizzo
da parte del client. E quindi importante, così come nel caso dei
session bean, offrire verso lesterno una interfaccia che permetta di utilizzare
tali componenti: tale interfaccia si ottiene implementando le due solite
(la Home e la Remote) più una terza, la EntityBean.
Oltre
a tutto ciò, devono essere sviluppati metodi per la ricerca del
componente da parte del client: quello più importate che deve essere
necessariamente riscritto è il findByPrimaryKey(), il quale necessita
al suo fianco della creazione di una chiave primaria (classe PrimaryKey)
per consentire lidentificazione unica e serializzabile del bean.
 Al
fine di implementare la persistenza del componente, devono essere specificate
quali variabili dovranno essere rese persistenti per mezzo di salvataggio
in un db di qualche tipo. Al
fine di implementare la persistenza del componente, devono essere specificate
quali variabili dovranno essere rese persistenti per mezzo di salvataggio
in un db di qualche tipo.
Questa
funzionalità prevede due modalità di base: la container-managed
persistence e la bean-managed persistence.
Nel
primo caso tramite meccanismi automatici del server le informazioni sono
memorizzate in una struttura dappoggio come ad esempio un RDBMS, mente
nellaltro tipo di bean tale compito è totalmente a carico dellimplementazione
del bean.
Per
creare un Entity Bean, si può operare in due modi: per mezzo
dellazione diretta del client, il quale può invocare i metodi di
creazione della Home Interface, o in alternativa effettuando una qualche
operazione che aggiunga nel database dati che rappresentino il bean.
Per
avere un riferimento di un componente già esistente invece, il client
può operare in diversi modi: ricevere il bean come parametro di
una invocazione di metodi remoti, effettuare una ricerca presso il server
per mezzo dei metodi di ricerca, ottenere dinamicamente un handle dal container
il quale provvede a fornire il bean più indicato.
Il ruolo del server
Il
server per i bean è lelemento fondamentale di tutta la piattaforma
EJB: questo componente infatti svolge buona parte del lavoro necessario
sia per rendere un componente utilizzabile dai vari client remoti, sia
per supportare i servizi più importanti (transazioni, mantenimento
dello stato, sessioni, sicurezza) associati ai vari bean.
Molti
sono i server disponibili attualmente sul mercato: dato infatti che EJB
non è un prodotto ma una specifica, i vari produttori sono liberi
di realizzare la loro implementazione compatibile con la versione 1.0 o
1.1 delle specifiche rilasciate da Sun (la 2.0 è attesa per questanno).
Da
questo punto di vista lo scenario è piuttosto articolato, e non
si ha che limbarazzo della scelta. Le persone con le quali ho avuto modo
di scambiare un po di impressioni, mi hanno confermato che non esiste
il prodotti ideale, o quello da scartare a priori (a parte certi casi
estremi), dato che la scelta dipende molto dalla situazione particolare.
Per
sapere quali siano attualmente i prodotti disponibili sul mercato rilasciati
dalle diverse case si veda il riquadro EJB Application Server.
Come
accennato poco sopra, il processo di creazione di un bean, e di deploy
nel server passa per la definizione di alcune interfacce in modo che il
server possa gestire il componente. In particolare, le interfacce da estendere
sono
-
Home interface:
basata sul pattern factory ([5] e [6]) fornisce i metodi per creare unistanza
del componente
-
Remote
interface: definisce i metodi del bean stesso
-
La bean
implementation class invece implementa linterfaccia remota, fornisce di
fatto il corpo del bean stesso e ne definisce il comportamento.
La
cosa estremamente interessante è che non è necessario fornire
limplementazione delle due prime interfacce, compito svolto automaticamente
dal server.
Per
poter completare con successo la fase di deploy del bean nel server è
necessario inoltre fornire i cosiddetti deployment descriptors, operazione
effettuabile al momento del deploy del componente utilizzando il tool fornito
dal server.
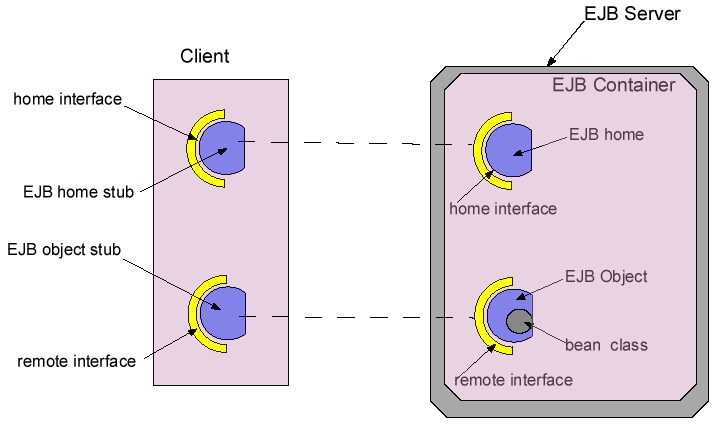
Figura
2 Modalità
di operativa degli EJB: si noti come gli oggetti remoti non sono
messi a disposizione direttamente dal server, ma il client interagisce
con questi tramite una serie di interfacce remote; il meccanismo è
molto simile a quello offerto da RMI.
Creazione di un
bean
Contrariamente
allutilizzo, il processo di creazione di un bean è piuttosto complesso
dal punto di vista teorico, anche se il codice da scrivere è di
fatto piuttosto semplice. Per brevità vedremo come realizzare un
entity bean, rimandando alla bibliografia laltro caso che prenderebbe
effettivamente troppo spazio.
Dato
che EJB è una tecnologia definita da Sun di livello Enterprise (Java
2 Enterprise Edition J2EE), per poter sviluppare un bean ed effettuare
le prime prove non è sufficiente installare il solo JDK 1.2, ma
si devono scaricare i packages opportuni (javax.ejb), e settare il
classpath in modo opportuno.
La
prima cosa da fare quindi è importare allinterno del proprio codice
i packages necessari per far funzionare il tutto
import
java.rmi.RemoteException;
import
javax.ejb.*;
Si
noti come oltre a javax.ejb, si fa riferimento anche a RMI, dato
che esso rappresenta il motore utilizzato per la gestione degli oggetti
remoti.
Si
può passare quindi a realizzare il bean: si supponga ad esempio
di voler mappare il concetto di articolo pubblicato su una delle riviste
del Gruppo Editoriale Infomedia con un bean. In tal caso sarà
necessario per prima cosa definire una interfaccia idonea, come ad esempio
public
interface Article extends EJBObject{
public
String getTitle() throws RemoteException;
public String getAuthor() throws RemoteException;
}
Poiché
tali oggetti vivono in un contesto distribuito, ogni metodo deve poter
propagare (per mezzo di throws) la RemoteException, dato che qualcosa di
non previsto può sempre accadere.
La
home interface svolge la funzione di factory e per questo mette a disposizione
i metodi per la creazione del bean
public
interface ArticleHome extends EJBHome {
public Article create() throws CreateException, RemoteException;
}
In
questo caso si è provveduto a fornire un solo metodo per la creazione
del bean, ma ne potevano essere presenti altri che ricevevano come parametri
ad esempio il titolo o altro valore.
Infine
la classe che implementa linterfaccia remota rappresenta il bean stesso
public
class ArticleBean implements SessionBean
Il
metodo per la creazione del bean di fatto istanzia la variabile relativa
al titolo dellarticolo
public void ejbCreate() {
Title = "EJB in pratica;
}
In
questo caso abbiamo una versione molto semplificata delloggetto remoto,
versione che svolge offre solo alcune funzionalità. Inoltre tale
classe espone i seguenti metodi per la manipolazione delle variabili
public String getTitle() throws EJBException{
return Title;
}
public String getAuthor() throws EJBException{
return Author;
}
Infine
da notare la presenza dei metodi
public
void ejbActivate(){}
public
void ejbPassivate(){}
public
void ejbRemove(){}
public
void setSessionContext(SessionContext context){}
che
servono per la gestione del ciclo di vita del bean : gli aspetti legati
a questo argomento sono piuttosto complessi e di fatto non basterebbe un
articolo intero per esaminarli tutti.
Diciamo
per brevità che un bean vive una sua vita che per certi versi può
essere paragonata a quella di un thread nella JVM o ad un processo in un
sistema operativo multitasking. Ad esempio per motivi di performance un
container può decidere di serializzare su file un componente non
utilizzato da un po di tempo: quando ciò accade il bean ne riceve
notifica per mezzo di una chiamata a ejbPassivate(). Allinterno
di tale metodo quindi possiamo scrivere tutte le istruzioni necessarie
per rilasciare le risorse non utilizzate come ad esempio connessioni
di rete o altro.
Quando
un bean è richiesto nuovamente, una chiamata a ejbActivate() effettuerà
le operazioni necessarie per risvegliare il bean, come ad esempio la riapertura
della connessione di rete.
Quando
infine un bean è rimosso dal container viene effettuata una chiamata
al metodo ejbRemove().
Il
metodo setSessionContext() viene in genere invocato per dare al bean la
possibilità di gestire le transazione e la security in una sessione.
Dato
che tali metodi sono chiamati in automatico in funzione del ciclo di vita
del componente, analizzando il loro significato già si può
intuire la potenza del modello EJB. Si pensi ad esempio al caso della connessione
di rete: essa verrà aperta o chiusa automaticamente in funzione
dello scheduling che il server EJB effettua sul componente.
Dopo
la parte implementativa del bean, si deve provvedere al deploy allinterno
del server: questa operazione in genere è effettuata grazie allutilizzo
dei vari tool e wizard forniti di corredo con il server utilizzato. Per
maggiori approfondimenti su tali aspetti si può ricorrere di fatto
alla documentazione del prodotto scelto.
Usare un EJB dal
client
Una
volta che il bean è pronto per essere utilizzato, il lavoro da fare
da parte del client è piuttosto semplice. Di fatto si devono
effettuare queste tre operazioni
-
utilizzare
il nome del bean per localizzare linterfaccia home
-
utilizzare
linterfaccia home per creare una istanza del bean
-
utilizzare
direttamente il bean invocandone i metodi che mette a disposizione
La
localizzazione avviene individuando da qualche parte la home interface,
compito che viene svolto per mezzo della classe java.naming.Context. Linterfaccia
remota viene localizzata per mezzo della JNDI API utilizzando il
nome ArticleJNDI utilizzato al momento del deploy del bean nel
server EJB.
Context initial = new InitialContext();
Object o = initial.lookup("ArticleJNDI");
Una
volta ottenuta linterfaccia remota si utilizza la classe PortableRemoteObject
per effettuare una conversione nel tipo voluto.
ArticleHome
home;
home=(ArticleHome)PortableRemoteObject.narrow(o,
ArticleHome.class);
Infine
per mezzo del metodo create() si crea listanza delloggetto ed utilizzarne
i metodi ad esempio per ricavarne le informazioni memorizzate.
Article
art = home.create();
System.out.println(art.getTitle());
Una volta
che il bean non serve più, è bene rimuoverlo dal container
in modo da rilasciare le risorse allocate
art.remove();
Conclusione
Dopo
questa veloce panoramica sui componenti EJB, si possono fare due osservazioni.
La
prima è come si pone EJB nei confronti delle tecnologie già
presenti sullo scenario della computazione distribuita.
Si
è detto a tal proposito che i concorrenti sono essenzialmente due,
ovvero RMI e CORBA (più MTS che però corre per una strada
tutta sua).
Il
primo di fatto rappresenta il motore che permette tutto il funzionamento
della tecnologia EJB, e quindi non si pone in concorrenza con EJB, ma semmai
in aiuto.
Si
deve dire che la scelta fra le due soluzioni (solo RMI o EJB), deve essere
fatta in funzione della tipo di applicazione che si deve realizzare. Nel
caso infatti di sistemi semplici, fortemente dipendenti dal caso particolare,
forse il semplice utilizzo di RMI può essere sufficiente; nel caso
di situazioni complesse dove è necessaria la massima flessibilità
e scalabilità (vedi e-commerce o JSP) allora la soluzione EJB è
la migliore.
CORBA
invece vede le cose da un altro aspetto: più potente e più
complesso sia di RMI che di EJB, non offre a tuttora (a meno di utilizzare
implementazioni proprietarie come VisiBroker) il supporto per i servizi
distribuiti, vero punto di forza di EJB.
CORBA
offre però prestazioni migliori (è risaputo che RMI non sia
un campione di velocità), e la possibilità di interagire
con sistemi e tecnologie differenti (vedi legacy).
La
seconda considerazione da fare è quando e dove EJB debba essere
utilizzato, e per svolgere quale tipo di compiti.
La
risposta è molto semplice: in tutti quei casi in cui si debbano
realizzare applicazioni multistrato distribuite, basate su oggetti mobili.
Al
momento il paradigma più utilizzato è quello del 3Tier, modello
che non necessariamente si deve appoggiare a modelli di oggetti distribuiti,
ma è anche vero che questultimo sta prendendo piede ad una velocità
sempre maggiore. Java da questo punto di vista è la soluzione (lunica)
in grado di fornire massima flessibilità e potenza implementativa,
ed è per questo che sta risquotendo un sempre maggiore successo
in questo settore.
Bibliografia
[1]
Enterprise Java Beans di Richard Monson Haefel, Ed. OReilly
[2]
Professional Java Server programming aa.vv. Ed Wrox
[3]
Remote Method Invocation di Giovanni Puliti, MokaByte 16 www.mokabyte.it/0298
[4]
Introduction to CORBA http://developer.java.sun.com/developer/onlineTraining/corba/magecontents.html
[5]
Design Patterns di Gamma Helm Johnson, Vlissides Ed. Addison Wesley
[6]
Il pattern factory di L. Bettini, A. Trentini - MokaByte 27 www.mokabyte.it/2099
Appendice
A: EJB Application Server e case produttrici
|
Azienda
produttrice
|
Nome
del prodotto
|
|
BEA
System
|
Bea
Web Logic Server/Enterprise
|
|
BlueStone
Software
|
Sapphire/Web
|
|
BROKAT
Infosystems
|
Brokat
Twister
|
|
Fujitsu
Software
|
Interstage
|
|
GemStone
Systems
|
GemStone/J
|
|
Haht
Software
|
HAHT
site Application Server
|
|
IBM
|
WebSphere
Application Server
Component
Broker
CICS
Transaction Server
TXSeries
|
|
Information
Builders
|
Parlay
Application Server
|
|
Inprise
|
Inprise
Application Server
|
|
Iona
Tech.
|
Orbix
Enterprise
|
|
Netscape
Comm.
|
Netscape
Application Server
|
|
Novera
Software
|
JBusiness
|
|
Object
Space
|
Voyager
|
|
Oracle
|
Oracle
Application Server
|
|
Persistence
Software
|
Power
Tier for EJB
|
|
Secant
Tech.
|
Secant
Extreme Enterprise Server
|
|
Siemens
|
Siemens
Enterprise Application Server
|
|
Silver
Stream
|
SilverStream
Application Server
|
|
Sun
Microsystems
|
NetDynamics
Application Server
|
|
Sybase
|
Sybase
Enterprise Application Server
|
|
Valto
Systems
|
Ejipt
|
|
Visient
|
Arabica
|
|



