Prima
di entrare nel merito della presentazione dei meccanismi forniti dallo
Unified Modeling Language per analizzare e documentare la proiezione software
dellÆarchitettura fisica di un sistema, si ritiene opportuno spendere qualche
parola sulla definizione di architettura di un sistema. Secondo la versione
fornita dello UML, si tratta ōdi un insieme di decisioni significative
circa lÆorganizzazione di un sistema software, la selezione di elementi
strutturali corredati dalle relative interfacce di cui il sistema è
costituito, congiuntamente ai relativi comportamenti come specificato dalle
collaborazioni tra tali elementi, la composizione tra questi elementi strutturali
e comportamentali in sottosistemi progressivamente più grandi e
lo stile architetturale che guida questa organizzazione-questi elementi
e le relative interfacce, le relative collaborazioni e le rispettive composizioni.
LÆarchitettura software non è relativa unicamente alla struttura
ed al comportamento, ma anche allÆutilizzo, funzionalità, prestazioni,
flessibilità, riutilizzo, comprensibilità, economicità
e vincoli tecnologici e bilanciamenti e interessi esteticiö.
UnÆaltra
definizione di architettura, probabilmente meno esaustiva della precedente,
ma decisamente più intuitiva è quella fornita da Buschmann
(1996), il quale afferma che ōunÆarchitettura è una descrizione
dei sottosistemi, delle componenti Sw di un sistema e delle relazioni tra
tali elementi. I sottosistemi e le componenti sono tipicamente specificati
in viste diverse che evidenziano le proprietà funzionali e non funzionali
più importanti del sistema software. LÆarchitettura Sw di un sistema
è un manufatto, risultato dellÆattività di disegno del swö.
Da
una prima analisi molto ad alto livello delle definizioni, si può
affermare che, ogni architettura è suddivisibile in due componenti:
quella logica e quella fisica. La prima, essenzialmente, si occupa degli
aspetti funzionali del sistema e pertanto è governata dai relativi
requisiti funzionali; la seconda, si occupa dei rimanenti aspetti, per
così dire, non funzionali, come affidabilità, utilizzo delle
risorse, prestazioni, deployment del sistema, e così via.
La
componente fisica di unÆarchitettura è suddivisibile in due proiezioni:
software e hardware. Alcune volte la si modella attraverso unÆunica vista
denominata Implementation view, mentre tipicamente, le due componenti sono
analizzate in due viste separate, denominate, rispettivamente, Component
e Deployment View.
Globalmente
lÆarchitettura fisica rivela la struttura hardware, specificando i diversi
nodi e come questi siano interconnessi gli uni con gli altri (physical
view); illustra la struttura e le dipendenze dei moduli di codice che implementano
i concetti definiti nel disegno del sistema, la distribuzione a tempo di
esecuzione (run-time) del software in termini di processi, programmi e
altre componenti.
Volendo
sintetizzare al massimo i concetti, si può affermare che lÆarchitettura
fisica descrive la decomposizione del software e dellÆhardware del sistema
e quindi dovrebbe fornire le risposte alle seguenti domande:
-
in
quali programmi o processi le classi e oggetti sono fisicamente allocati?
-
in quale
nodo (computer o altro dispositivo hw) i programmi ed i processi sono eseguiti?
-
quali
computer o altri dispositivi hardware sono presenti nel sistema, e come
sono connessi gli uni agli altri?
-
quali
sono le dipendenze tra le varie parti del sistema? La modifica di una sua
parte quali ripercussioni genera sulla restante parte del sistema?
Come
spesso accade, la capacità di progettare buone architetture deriva
dallÆesperienza ed in particolare dal riutilizzo e/o miglioramento di soluzioni
risultate soddisfacenti in precedenti progetti. Altre volte lÆorganizzazione
è già parzialmente stabilita dallo standard architetturale
a cui si intende far riferimento; ad esempio se si decidesse di utilizzare
il modello EJB, la struttura SW di massima risulterebbe già stabilita
dalle relative direttive, e quella dellÆhardware dipenderebbe in gran parte
(e paradossalmente) dallÆapplication server prescelto.
Altre
volte le varie aziende dispongono di una propria suite di prodotti di integrazione,
per cui lÆarchitettura consiste nellÆadattare la stessa alle problematiche
peculiari dellÆambiente del cliente (il famoso processo di customizzazione).
Pertanto,
sebbene la progettazione dellÆarchitettura fisica di un sistema dovrebbe
essere la logica conseguenza del disegno dello stesso, e quindi dei risultati
emersi nelle viste precedenti, molte volte non è così, ed
anzi si procede con una sorta di processo inverso o quantomeno Buttom upģ
DÆaltronde un imperativo del modo di pensare O.O. non è forse la
riusabilità a tutti i livelli?
Spesso,
affrontando la progettazione di un nuovo sistema, si inizia proprio con
il tracciare qualche idea di massima dellÆarchitettura fisica del sistema,
e quindi si comincia con il focalizzare lÆattenzione proprio su quella
che spesso viene vista come una delle ultime fasi del processo di progettazione
del software.
Vista
la difficoltà intrinseca del processo di modellazione di un sistema
ogni metodo volto a ridurne la complessità non può che essere
il ben venuto.
Ma
quali proprietà deve possedere unÆarchitettura per poter essere
considerata buona?
-
completezza:
corretta descrizione di tutte le parti che formano il sistema, sia dal
punto di vista funzionale, sia da quello fisico;
-
precisione:
dettagliata illustrazione grafica del sistema (mappa) che permetta agli
sviluppatori di individuare agevolmente la collocazione di ogni singola
funzionalità.
-
flessibilità:
aggiornamenti ed estensioni devono poter essere eseguiti agevolmente su
una specifica parte del sistema, senza che le restanti ne siano coinvolte
negativamente.
-
semplicità:
deve essere dotata di interfacce ben definite con ben esplicite dipendenze
tra le differenti parti, in modo tale che il disegnatore possa concentrarsi
sulle singole parti senza dover necessariamente possedere una completa
e dettagliata visione di tutte le particolarità delle restanti parti
del sistema.
-
riusabilità:
supportare il riutilizzo sia incorporando delle parti precedentemente progettate,
sia attraverso il disegno di parti sufficientemente generiche da poter
essere utilizzate in progetti futuri.
Diagrammi dei
componenti
ōIl
diagramma dei componenti descrive lÆorganizzazione e le relative interdipendenze
di un insieme di componenti; tali diagrammi indirizzano la vista statica
implementativa di un sistema.ö (UML)
Il
diagramma dei componenti, in ultima analisi, è una specializzazione
del diagramma delle classi che focalizza lÆattenzione sui componenti del
sistema.
Componenti
I
componenti software vivono nel mondo ōmaterialeö dei bit e perciò
sono importanti blocchi nella modellazione degli aspetti fisici del sistema.
Sono utilizzati per modellare gli oggetti fisici che risiedono in un nodo,
come programmi eseguibili, librerie, tabelle, files, documenti, ...
Secondo
la definizione ufficiale UML, ōun componente è un elemento fisico
rimpiazzabile di un sistema, il quale si conforma e fornisce lÆimplementazione
di un insieme di interfacceö.
DallÆanalisi
della precedente definizione emergono chiaramente tre concetti sui quali
vale la pena spendere qualche riga; in particolare un componente è:
-
un ōoggetto
fisicoö (nei limiti della fisicità concessa dal mondo virtuale!)
e non unÆastrazione o un concetto;
-
un elemento
rimpiazzabile. Ciò significa che deve poter essere sempre sostituito
da un altro che risulti conforme alla relativa interfaccia senza generare
ripercussioni negative sulla restante parte del sistema. Ciò permette
di realizzare dei sistemi assemblando componenti eseguibili, e di poter
aggiungerne nuovi o sostituirne altri senza dover necessariamente ricostruire
lÆintero sistema. Questo è reso possibile dal concetto di interfaccia;
-
è
parte di un sistema. EÆ abbastanza inconsueto che un componente venga utilizzato
per rimanere isolato, tipicamente esso collabora con altri componenti al
fine di realizzare ben precise funzionalità del sistema.
Graficamente
un componente viene rappresentato attraverso un rettangolo munito di due
linguette poste nel lato sinistro. Ogni componente deve possedere un nome
univoco che lo distingua dagli altri. Come al solito, il nome può
essere semplice oppure composto dal relativo percorso costituito dal o
dai package di appartenenza.
Tipicamente
di un componente viene fornito unicamente il nome, ma nulla vieta di aggiungervi
i famosi adornamenti, come per esempio i ōtag valueö, o compartimenti supplementari
per specificarne ulteriori dettagli.
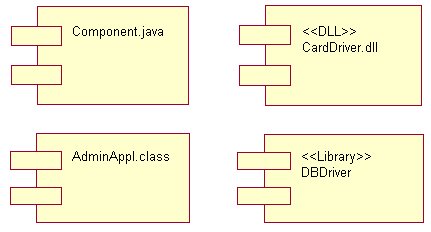
Figura
1 Esempi di componenti software.
Come
emerge dagli esempi riportati in figura 1, i componenti possono essere
di vari tipi; quelli più comuni sono:
·
programmi eseguibili;
·
librerie (statiche o dinamiche);
·
tabelle di database;
·
file sorgenti o di dati;
·
documenti.
Per
alcuni di tali stereotipi sono previste apposite icone come riportato nellÆimmagine
seguente:

Figura
2 Esempi di stereotipi di alcune
tipologie
di componenti.
Tra
il concetto di componente e quello di classe esiste una forte analogia;
in particolare, entrambi possono:
-
implementare
un insieme di interfacce;
-
partecipare
a relazioni di dipendenza, associazione e generalizzazione;
-
essere
annidati;
-
avere
delle istanze;
-
partecipare
ad interazioni.
Ciononostante,
sono altresì presenti una serie di differenze significative:
-
le classi
rappresentano delle astrazioni mentre i componenti rappresentano degli
oggetti ōfisiciö;
-
i componenti
rappresentano package fisici o componenti logici e possono essere presenti
a diversi livelli di astrazione;
-
le classi
possono avere dati e metodi, mentre i componenti possono avere unicamente
delle operazioni eseguibili solo attraverso le relative interfacce.
In
sistemi molto grandi potrebbe risultare alquanto complicato e decisamente
poco chiaro, rappresentare la Component View in termini dei singoli componenti.
Spesso si preferisce raggrupparli in package, così come avviene
per le classi, al fine di dar luogo a diagrammi più immediati e
che non richiedano un tempo eccessivo di realizzazione.
Tipologie dei
componenti
L'
UML suddivide le tipologie di componenti in tre grandi categorie, che sono:
·
spiegamento (deployment). Si tratta dei componenti necessari e sufficienti
per costituire il sistema eseguibile, come le librerie di collegamento
dinamico (DLL) e gli eseguibili. Comunque, la definizione UML di componente
è così ampia da comprendere i classici oggetti presenti in
architetture distribuite, così come pagine HTML, tabelle, file di
inizializzazione, ecc. ecc.
-
prodotto
di lavoro (work product). A questa tipologia appartengono oggetti come
i moduli di codice sorgente, che, come tali, non fanno parte direttamente
del sistema eseguibile ma che servono a generarlo.
-
esecuzione
(execution). Questi componenti sono creati come conseguenza dellÆesecuzione
del sistema.
Interfacce
UnÆinterfaccia
è una collezione di operazioni che specificano un servizio generale
fornito da una classe o da un componente. Pertanto esse esprimono il comportamento,
parziale o totale, di un elemento così come è percepito dallÆesterno.
La
stragrande maggioranza della architetture moderne (CORBA, EJB, COM+, ģ)
utilizza massicciamente il concetto di interfaccia come collante tra i
vari componenti. Chiaramente, ciò rende possibile ai server sw di
pilotare le varie ōclassi di estensioneö senza necessariamente averne conoscenza
diretta.
LÆimportanza
delle interfacce è che consentendo di stabilire a priori il comportamento
degli oggetti, rendono possibile lo sviluppo parallelo del sistema, consentono
di trattare un insieme di classi/componenti (quelle/i che la implementano)
in modo del tutto astratto, forniscono le basi per produrre protocolli
di comunicazione, rendono le varie parti del sistema indipendenti le une
dalle altre, rendendo possibile la reingegnerizzazione di determinati componenti
senza ripercussione sui restanti.
Tipicamente,
in UML, unÆinterfaccia viene rappresentata tramite un cerchio con vicino
il nome; nulla vieta però di rappresentarla come una normale classe;
anzi spesso si ricorre a tale notazione al fine di poter specificare chiaramente
le operazioni che lÆinterfaccia espone. In tal caso il collegamento tra
la classe che implementa unÆinterfaccia e lÆinterfaccia stessa avviene
per mezzo di una linea tratteggiata con un triangolo vuoto allÆestremità.
Il
componente che ne pilota un altro tramite la relativa unÆinterfaccia (detta
export interface), è associato a questÆultima per mezzo di una relazione
di dipendenza. Per il componente pilotante lÆinterfaccia è detta
ōimport interfaceö e, ovviamente, ogni componente può importare
ed esportare diverse interfacce.
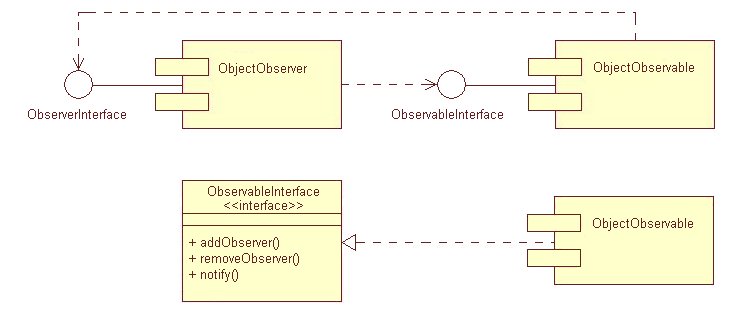
Figura
3 Esempi di componenti corredati dalle relative interfacce.
Utilizzi dei component
diagram: componenti eseguibili
Il
fine principale dei diagrammi dei componenti è sicuramente modellare
le parti fisiche che determinano lÆimplementazione del sistema. Il risultato
di tale processo risulta di fondamentale importanza per la gestione sia
della configurazione, sia del rilascio di versioni successive del sistema
o di sue parti (versioning).
Naturalmente
quando il sistema risulta composto da un solo file eseguibile, non ha molto
senso andarne a realizzare il component diagram; normalmente però,
i sistemi che si rispettino risultano costituiti da tutta una serie di
componenti: file eseguibili, librerie, tabelle, ecc. che spesso risiedono
su macchine diverse: in tali contesti la realizzazione di un diagramma
dei componenti è indispensabile.
Nei
sistemi inoltre, non è infrequente, anzi è auspicabile, che
alcuni componenti risultino condivisi da più applicazioni allocate
in diversi nodi del sistema. In questo scenario si comprende bene come
i diagrammi dei componenti siano un valido ausilio nella gestione del processo
di aggiornamento del sistema o di sue parti: la verifica dellÆimpatto sul
sistema dellÆaggiornamento di alcuni componenti è immediata.
Pertanto,
si utilizzano i diagrammi dei componenti per visualizzare, specificare,
costruire e documentare la configurazione delle versioni di eseguibili,
includendo la collocazione dei componenti che costituiscono il sistema
e le relazioni tra di essi.
Figura
4. Esempio di component diagram di un componente eseguibile.
3.2.
Codice sorgente.
Sebbene
lÆobiettivo principale dei component diagramm sia quello di modellare i
componenti eseguibili del sistema, esso risulta un valido strumento per
documentare le parti di codice sorgente utilizzate per produrre appunto
i componenti eseguibili.
I
diagrammi prodotto di tale processo risultano molti utili per visualizzare
le dipendenze a tempo di compilazione tra i file sorgenti la cui necessità
è particolarmente sentita quando non si utilizzano tools di sviluppo.
Naturalmente,
nella maggior parte dei casi, o addirittura nella quasi totalità,
si preferisce demandare la gestione delle dipendenze tra i file sorgenti
allÆambiente di sviluppo e pertanto è consigliabile, in questo contesto,
utilizzare il component diagram per visualizzare e documentare tali relazioni.
Ovviamente
quando il sistema assume dimensioni rilevanti risulta improponibile e comunque
poco utile realizzare il component diagram in termini delle singole classi,
interfacce, ecc. che costituiscono il sistema; in questi casi è
auspicabile modellare il sistema considerando come blocchi elementari opportuni
raggruppamenti degli elementi base: i package.
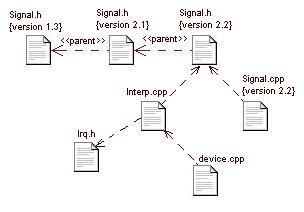
Figura
5 Esempio di diagramma dei componenti
relativo
ai file di codice sorgente
Come
si può vedere dalla precedente figura, tracciare lÆimpatto delle
modifiche di un file è unÆoperazione alquanto immediata e consiste
in una semplice ispezione visiva; per esempio lÆaggiornamento del file
header Signal.h richiederebbe la compilazione dei file Signal.cpp e Interp.cpp.
Basi di dati
Uno
schema logico di una base di dati cattura il ōvocabolarioö di un sistema
di dati persistente con semantica e relative relazioni. Dal punto di vista
fisico, questi oggetti vengono memorizzati in un database per poter essere
acceduti in seguito. I più comuni motori di gestione delle basi
di dati possono essere relazionali, ad oggetti o delle forme ibride. Quando
ci si trova nellÆultimo caso, non si ha alcun problema in quanto vi è
una corrispondenza diretta tra le classi scaturite dal processo di disegno
del sistema e la struttura del database, mentre nel caso in cui il DBMS
sia di tipo relazionale è necessario realizzare unÆinterfaccia per
il mapping dei due mondi, la cui complessità è tuttÆaltro
che trascurabile, specie in presenza di relazioni di eredità. In
tal caso si possono considerare principalmente due tecniche:
1.
raggruppare le relazioni di ereditarietà in modo tale che tutte
le classi figlie si trovino allo stesso livello. Il limite di questa tecnica
è che è necessario memorizzare diverse informazioni ridondanti
in molte istanze delle classi figlie;
2.
separare le tabelle padri da quelle figlie. Probabilmente si tratta della
soluzione più valida ma che comunque richiede di eseguire continue
interrogazioni per scorrere gli oggetti che realizzano la relazione.
Ovviamente
esistono tutta una serie di librerie commerciali che risolvono lÆintero
problema ed alcune di esse sono fornite direttamente dai produttori delle
basi di dati. Altri produttori, pur fornendo dei RDBMS, hanno provveduto
ad aggiungere dei strati superiori di ōemulazioneö che si occupano di fornire
al mondo esterno una visione O. O. delle basi di dati memorizzate.
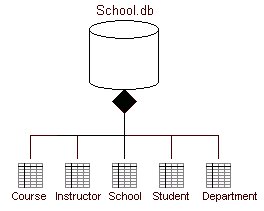
Figura
6 Tabelle della base di dati denominata school
Ovviamente
la rappresentazione in figura non è sufficiente per rappresentare
la struttura e le relazioni esistenti tra le tabelle; tale lacuna può
essere colmata aggiungendo agli stereotipi rappresentanti le tabelle le
relative colonne come se fossero comuni proprietà. Infine, alle
singole tabelle possono essere associate delle ōstore-procedureö la cui
rappresentazione può essere semplicemente ottenuta evidenziandole
come metodi.
Comunque,
al fine di eseguire lo studio del sistema nel modo più dettagliato
possibile e di fornirne una visione più chiara e semplice, è
possibile integrare il modello UML con diagrammi aggiuntivi come per esempio
entità relazioni.
Conclusioni
Il
presente articolo è stato dedicato alla illustrazione dellÆarchitetture
fisica di un sistema e dei meccanismi di modellazione messi a disposizione
dallÆUML, in particolare si è focalizzata lÆattenzione sulla relativa
proiezione sw ottenuta per mezzo della component view.
Si
è visto che sebbene lo studio dellÆarchitettura fisica del sistema
dovrebbe essere una delle ultime fasi del processo di modellazione, molto
spesso si comincia il relativo studio proprio da questa fase, tracciando
qualche ipotesi di architettura su un pezzo di carta o su una lavagna.
Altre volte, quando si ricorre a standard architetturali ben noti o quando
lÆazienda per la quale si lavora dispone già di un suo prodotto
di integrazione, lÆarchitettura fisica del sistema è, in gran parte,
stabilita a priori.
Come
per tutte le altri fasi della progettazione, anche in questa lÆesperienza
gioca un ruolo importante; infatti nellÆaffrontare la modellazione fisica
di un nuovo sistema si tenta di riciclare soluzioni dimostratesi valide
in precedenti progettazioni.
Si
è visto ancora che la component view permette di rappresentare,
attraverso gli omonimi diagrammi, la decomposizione in moduli del sistema
sw e che tali diagrammi altro non sono che una specializzazione del diagramma
delle classi la cui peculiarità è focalizzare lÆattenzione
sui componenti del sistema.
LÆutilizzo
principale che se ne fa dei diagrammi dei componenti è sicuramente
modellare le parti fisiche che determinano lÆimplementazione del sistema.
Il risultato di tale processo risulta di fondamentale importanza per la
gestione sia della configurazione, sia del rilascio di versioni successive
del sistema o di sue parti (versioning).
Attraverso
lÆispezione visiva di tali diagrammi è possibile tracciare lÆimpatto
sul sistema delle modifiche di un suo componente.
I
component diagram sono molto utili anche per visualizzare le dipendenze
tra i vari file sorgenti, le tabelle di cui è composto un database
ecc.
Per
terminare si ricordi che ogni diagramma dei componenti è una rappresentazione
grafica della vista implementativa di un sistema e non è assolutamente
necessario realizzarne uno solo per visualizzare lÆintero sistema; è
consigliabile realizzarne una serie, ognuno specializzato per un determinato
sottosistema.
Si
approfondirà il discorso nel prossimo articolo nel quale si affronterà
la proiezione Hw della Physical view.
Puntualizzazioni
e scuse
In
una serie di articoli (tra cui anche nel precedente [12]), è stato
affermato che Rational Rose non prevede i famosi Activity Diagram. Tale
affermazione è vera per le versioni di Rational Rose precedenti
alla ō2000ö. (Finalmente è chiaro il problema del millennium bug:
il suffisso 2000 da aggiungere a tutte le nuove versioni degli applicativi..
Altro che virus!).
Bisogna
tener presente che gli articoli vengono preparati con mesi di anticipo
rispetto alla relativa pubblicazione e quindi non è sempre possibile
offrire un elevatissimo grado di aggiornamento. Ciò premesso, su
segnalazione di un attento lettore, a cui vanno i personali ringraziamenti
dellÆautore, va puntualizzato che finalmente con la versione 2000 è
stata saturata tale lacuna: Rational Rose 2000 prevede la possibilità
di realizzare activity diagramģ Va comunque detto che ci sono volute ben
4 versioni per far capire tale lacuna: meglio tardi che mai.
Per
terminare, lÆautore vuole cogliere lÆoccasione per porgere le personali
scuse per non essere stato in grado, con particolare riferimento allÆultimo
periodo, di rispondere alle tante e-mail di richiesta supporto: il nuovo
lavoro e la conseguente emigrazione londinese ha generato una serie di
processi che, in ultima analisi, hanno determinato lÆutilizzo di tutti
i cicli CPU e lÆallocazione di tutte le risorseģ Un poÆ come dovrebbe avvenire
eseguendo il famoso processo ōmarriageö.
Bibliografia
[1]
The Unified Modeling Language User Guide
Grady
Booch, James Rumbaugh, Ivar Jacobson
Addison
Wesley
Questo
libro vanta il primato di essere stato scritto dai progettisti originali
del linguaggio, sebbene sia conosciuto come ōGradyÆs bookö, dal nome del
suo primo autore. La mancanza di una sua copia (magari autografata!) può
generare giudizi di scarsa professionalità per coloro che operano
nel settore della progettazione O.O... Ciò però, costituisce
una condizione necessaria, ma non sufficiente, in quanto bisogna, assolutamente,
aggiungere una copia del [3] e una del [4]. Sono soldi spesi bene! Forse,
il limite del libro, se proprio se ne vuole trovare uno, è quello
di essere poco accessibile ad un pubblico non espertissimo di progettazione
O.O. Un altro piccolo inconveniente è che, probabilmente, taluni
esempi possano sembrare di carattere accademico: poco rispondenti alle
problematiche del mondo reale.
[2]
UML Toolkit
Hans-Erik
Eriksson, Magnus Penker
Wiley
Questo
libro si fa particolarmente apprezzare per via del taglio pratico dello
stesso. Illustra in modo semplice il linguaggio, attraverso numerosi esempi,
limitando le digressioni di carattere teorico. Si suppone infatti, che
coloro che si occupano di progettazione O.O. abbiano una certa familiarità
con i relativi concetti. Chissà perché si ha la sensazione
che non sia sempre così! Naturalmente, studiare libri che illustrano
gli aspetti teorici dellÆinformatica, è sempre qualcosa più
che auspicabile. È altresì vero però, che coloro che
non hanno tempo da perdere, per la lettura di concetti arcinoti, gradiscono
arrivare rapidamente al nocciolo. Ciò spesso equivale a strappare
alle nottate lavorative ore preziose per il sonno.
[3]
The Unified Modeling Language Reference Manual
Grady
Booch, James Rumbaugh, Ivar Jacobson
Addison
Wesley
Il
commento da riportare per questo libro, noto per come ōRumbaughÆs bookö,
è sostanzialmente equivalente a quanto riportato per il primo. Esso
però offre un livello di difficoltà decisamente inferiore,
e pertanto dovrebbe essere più accessibile. Come suggerisce il nome,
si tratta di un manuale, per cui ne rispetta la tipica struttura.
[4]
Design Patterns: Elements of Reusable Object-Oriented Software
Erich
Gamma, Richard Helm, Ralph Johnson, John Vlissides, Grady Booch
Addison
Wesley.
Si
tratta di un ottimo libro che bisogna assolutamente avere se si vuole lavorare
nellÆambito della progettazione O.O. . I ōpatternö riportati, forniscono
un ottimo ausilio al processo di disegno del software. LÆutilizzo del libro
contribuisce ad aumentare la produttività, fornisce soluzioni chiare,
efficienti e molto eleganti. La fase di disegno del software, spesso, si
riduce ad individuare e personalizzare i ōpatternö che risolvono la problematica
specifica. Si è di fronte ad una nuova frontiera della progettazione
O.O.: il riutilizzo di parti del progetto. LÆunica pecca imputabile, è
che i vari diagrammi non sempre rispettano il formalismo UML.
[5]
www.omg.org
Si
tratta del sito ufficiale del Object Managment Group.
[6]
www.mokabyte.it, numero 34 (Ottobre 1999)
UML
e lo sviluppo del software.
[7]
www.mokabyte.it, numero 35 (Novembre 1999)
Use
Case: lÆanalisi dei requisiti secondo lÆU.M.L.
[8]
www.mokabyte.it, numero 36 (Dicembre 1999)
Diagrammi
delle classi e degli oggetti: proiezione statica della Design View.
[9]
www.mokabyte.it, numero 37 (Gennaio 2000)
Proiezione
statica della ōDesign Viewö parte seconda: esempi ōcelebriö di diagrammi
delle classi..
[10]
www.mokabyte.it, numero 38 (Febbraio 2000)
Proiezione
dinamica della ōDesign Viewö prima parte diagrammi di interazione.
[11]
www.mokabyte.it, numero 39 (Marzo 2000)
Proiezione
dinamica della ōDesign Viewö seconda parte: state chart diagra,.
[12]
www.mokabyte.it, numero 39 (Marzo 2000)
Proiezione
dinamica della ōDesign Viewö; terza ed ultima parte: activity diagram
|



