Introduzione
Cosè
SQLJ e da dove arriva.
SQLJ
è una collezione di specifiche definita da un consorzio di societa
leaders nel campo dei databases (per la precisione : JavaSoft, Informix,
Oracle, IBM, Cloudscape, Microsoft, Sybase, Tandem e XDB) riguardanti un
tipo accesso e interazione applicativa con i databases alternativo a JDBC.

SQLJ
si articola in tre parti.:
-
Embedded
SQL in Java (SQLJ Part0)
-
Java Stored
Procedures (SQLJ Part1)
-
Mapping
di classi Java su tipi SQL (SQLJ Part2)
Ognuna
di queste parti dello standard copre una diversa area di lavoro con i database.
La
prima parte si occupa di definire un metodo semplificato di accesso ai
database che prevede linserimento di istruzioni SQL nel sorgente Java,
la seconda specifica i meccanismi di creazione, installazione e rimozione
di Stored Procedures scritte in Java nei databases, mentre la terza infine
riguarda la possibilità di trattare le classi Java come tipi SQL.
Gli standard SQLJ
In
questa sezione diamo uno sguardo da vicino alle tre specifiche.
1.
Embedded SQL
SQLJ
Parte 0 essenzialmente un linguaggio per inserire istruzioni SQL direttamente
nel codice Java in modo del tutto simile a quanto avviene per ESQLC
(Embedded SQL C) che permette invece di inserire istruzioni SQL nel
codice C.
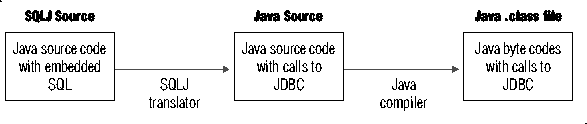
Il
metodo di lavoro con questa tecnologia è il seguente :
-
creazione
del connection context (opzionale : ne esiste uno di default)
Nota
: creare un connection context significa creare una classe ConnectionManager.class
contente il codice di connessione al database e rendere disponibile la
classe al compilatore sqlj attraverso il CLASSPATH. Ogni statement si riferirà
alla connessione definita da questo context.
-
Impostazione
del file di properties sqlj.properties: questo file permette di impostare
alcune proprietà quali lurl al db lutente con cui si vuole accedere
ecc..
-
si scrive
il programma SQLJ in un file *.sqlj diciamo Demo1.sqlj
-
si compila
il programma utilizzando il comando java ifxsqlj Demo1.sqlj
Nota
: il sorgente sqlj viene prima traslato Demo1.sqlj -> Demo1.java e poi
compilato Demo1.java -> Demo1.class; vengono anche creati files
supplementari : un file di risorse profilekeys.ser un file .class relativo
alliteratore iterator_name.class (se dichiarato nel sorgente)
e un file di risorse profilekeys.class (nel caso di Informix).
-
perché
lapplicazione sia completa occorre fare un bundle del package
del JDBC driver, che tra laltro contiene i packages sqlj.runtime.*, e
le classi generate al passo precedente .
Per
quanto riguarda invece la struttura del programma SQLJ il modulo sarà
per lo più così strutturato:
-
import
dei packages necessari allapplicazione : in particolare java.sql.* e sqlj.runtime.*
-
esecuzione
del main()
-
definizione
di un costruttore che invochi ConnectionManager.initContext() per creare
la connessione
-
dichiarazione
delliteratore del result set (se se ne fa uso)
-
esecuzione
delle queries
-
creazione
e popolamento delliteratore attraverso lesecuzione delle queries
-
manipolazione
dei risultati
-
chiusura
delliteratore (se se nè fatto uso)
Vedremo
ancora più nel dettaglio un programma sqlj più avanti nellarticolo.
2.
Java Stored Procedures
Questa
parte di SQLJ definisce i meccanismi di sviluppo e deployment di stored
procedures allinterno dei datebases relazionali.
Una
Stored Procedure è una procedura scritta in SPL (Stored Procedure
Language) solitamente scritte da DBA e/o sviluppatori per semplificare
o automatizzare le operazioni su database.
Ecco
un esempio di creazione di Stored Procedure utilizzando SPL:
-
Rimuove
la procedura SPL dal database
DROP
FUNCTION demoSPL;
-
Crea la
procedura SPL nel database
CREATE
FUNCTION demoSPL(nome VARCHAR, cognome VARCHAR) RETURNING INT;
DEFINE
cust_id INT;
SELECT
INTO cust_id FROM customers WHERE lastname = nome and firstname = cognome;
RETURN
cust_id;
END
FUNCTION;
-
Imposta
i permessi
GRANT
EXECUTE ON demoSPL TO PUBLIC;
-
Esegue
la procedura
EXECUTE
FUNCTION demoSPL;
Per utilizzare
questa procedura è sufficiente uno strumento capace di interpretare
SQL, ad esempio SQL Editor di Informix oppure Microsoft Query, ed eseguire
il codice sopra : in particolare listruzione EXECUTE FUNCTION demoSPL
eseguirà la procedura restituendo lid dellutente Diego Rossi.
La
procedura verrà compilata dallANSI SQL al linguaggio nativo SQL
del database ( anche per questo sono più efficienti) e rimarrà
dentro una tabella ( in Informix Dynamic Server se ne occupano le
tabelle sysprocs e sysbodies) fino all loro rimozione.
Osservazione
: Informix distingue tra FUNCTIONS e PROCEDURES : queste ultime non ritornano
valori.
Le
procedure SPL sono così utili per chi lavora con i databases che
si è presto provveduto ad estenderne le potenzialità, visto
che SPL di per sé è davvero poco potente a confronto di un
linguaggio compilato.
La
prima estensione è stata quella di poter scrivere tali procedure
in C. In questo caso si crea il sorgente
che
contiene la funzione o procedura, lo si compila come shared object (o come
DLL su piattaforme Windows) e infine si crea la procedura nel db con una
sintassi leggermente diversa dalla precedente.
Esempio
:
MyCProc.c
: da compilare in *.so oppure *.dll
int
myCSP(char *nome, char *cognome){
int cust_id = -1;
/* codice C */
return cust_id;
}
MyCProc.sql
-
Rimuove
la precedente versione della procedura
DROP
FUNCTION demoSPL_C;
-
Crea la
procedura nel database a partire dallo shared object precedentemente
compilato
CREATE
FUNCTION demoSPL_C(nome VARCHAR, cognome VARCHAR)
RETURNING
INT;
EXTERNAL
NAME "/home/nico/sviluppo/procedure/myprocs.so(myCSP)"
LANGUAGE
C
Con
larrivo di Java nel database è stato naturale aggiungere la possibilità
di scivere stored procedures anche con questo linguaggio : SQLJ ha standardizzato
i metodi per fare ciò.
I
passi da seguire per creare una stored procedure in Java sono i seguenti:
-
creazione
di una classe Java avente la procedura che si vuole creare come metodo
static e public
-
creazione
del JAR contente la classe appena creata e tutte quelle utilizzata dalla
procedura installazione del JAR nel database utilizzando una delle due
routines (loro stesse Java Stored Procedures) sqlj.install_jar()/sqlj.replace_jar
()
-
creazione
della procedura nel database tramite una istruzione tipo CREATE FUNCTION
o CREATE PROCEDURE
Per
deinstallare la routine Java basta seguire i due ultimi passi in modo inverso
: eseguire le istruzioni DROP FUNCTION
o DROP PROCEDURE
e rimuovere
il JAR dal database con sqlj.remove_jar().
Dopo
queste operazioni la routine Java è disponibile e utilizzabile come
una normale stored procedure scritta in SPL.
La
routine Java può ovviamente contenere al proprio interno codice
di connettività basato su JDBC o SQLJ per accedere alla base di
dati.
3.
Classi Java come tipi di dato SQL complessi
SQLJ
si chiude con la specifica riguardante la mappatura tra classi Java e dati
SQL .
Lordinario
metodo di accesso ai database, JDBC o anche SQLJ0 che comunque su di esso
si basa, prevede una mappa ben definita di corrispondenze tra i tipi
di dati SQL ANSI (es. CHAR, BLOB, INTEGER, BIT) e tipi di dati Java , e
in aggiunta ogni produttore adegua a questa mappa i propri tipi SQL non
standard (es. il tipo LVARCHAR di Informix).
Si
tratta comunque di corrispondenze tra dati primitivi : non è stato
definito per intenderci il metodo di corrispondenza tra una classe Java
(che dal punto di vista del linguaggio è un tipo di dato definito
dallutente) e la sua rappresentazione in SQL come tipo di dato SQL
complesso e viceversa.
Per
quanto riguarda gli oggetto si può al più immagazzinarlo
in una colonna come BLOB ovvero come binario puro, e recuperarlo come tale
per poi fare gli opportuni casts attraverso ad esempio ResultSet.getObject().
Per
la stessa ragione non è neppure possibile passare oggetti come parametri
di procedure.
Con
il meccanismo definito nella sezione precedente potrei definire una procedura
del tipo
int
GetCustomerID(String nomeUtente, String cognomeUtente)
per
recuperare lID di un utente nel mio db anagrafico fornendo il suo nome
e cognome alla procedura e utilizzando lSQL che segue (si presuppone di
aver eseguito tutti i passaggi preliminari):
CREATE
FUNCTION GetCustomerID(nome VARCHAR, cognome VARCHAR)
RETURNING
INT;
EXTERNAL
NAME my_jar:mokabyte.DemoSQLJ.GetCustomerID
LANGUAGE
JAVA;
Si
può notare quindi che si utilizzano tutti tipi di dati primitivi
sia per il metodo Java che per la procedura SQL.
Quello
che SQLJ Parte 2 permette è ad esempio di riscrivere la precedente
procedura in modo che essa ritorni invece dellID utente, un oggetto di
classe Customer che contenga le informazioni complete dellutente o anche
di passare alla procedura un oggetto di classe Person (diciamo una superclasse
di Customer) come metodo alternativo per passare le informazioni relative
al cliente o ancora un oggetto di tipo Address, per specificarne il recapito
e cosi via.
In
questo modo è possibile immagazzinare nelle colonne di tabelle SQL
gli oggetti Java ed estrarli in modo trasparente ; qualche esempio di istruzione
SQL che sfrutta questa possibilità vale più di ulteriori
spiegazioni:
-
creazione
del tipo addr
create
type addr
external
name 'Address' language java
(zip_attr
char(10) external name 'zip',
street_attr
varchar(50) external name 'street',
static
rec_width_attr integer external name 'recommended_width',
method
addr ( ) returns addr external name 'Address',
method
addr (s_parm varchar(50), z_parm char(10)) returns addr
external
name 'Address',
method
to_string ( ) returns varchar(255) external name toString,
method
remove_leading_blanks ( ) external name removeLeadingBlanks;
static
method contiguous (A1 addr, A2 addr) returns char(3)
external
name 'contiguous'
);
-
creazione
del tipo addr_2_line
create
type addr_2_line
under addr
external name 'Address2Line' language java
(line2_attr varchar(100) external name 'line2',
method addr_2_line ( ) returns addr_2_line external name 'Address2Line',
method addr_2_line (s_parm varchar(50), s2_parm char(100), z_parm char(10))
returns addr_2_line external name 'Address2Line',
method to_string ( ) returns varchar(255) external name 'toString',
method remove_leading_blanks ( ) external name removeLeadingBlanks;
method strip ( ) external name 'removeLeadingBlanks'
)
-
garantizia
permessi sul tipo:
grant
usage on datatype addr to public;
grant
usage on datatype addr2line to admin
-
esempio
di tabella contenente il tipo complesso
create
table emps (
name
varchar(30),
home_addr
addr, -- colonna con tipo di dato complesso addr
mailing_addr
addr_2_line); -- colonna con tipo di dato complesso addr_2_line
insert
into emps values('Bob Smith',
new
Address('432 Elm Street', '99782'),
new
Address2Line('PO Box 99', 'attn: Bob Smith', '99678'));
-
esempio
di select
select
name, home_addr>>zip, home_addr>>street, mailing_addr>>zip
from
emps where home_addr>>zip <> mailing_addr>>zip
update
emps set home_addr>>zip = '99783' where name = 'Bob Smith'
Nota:
loperatore >> permette di accedere al dato membro delloggetto : non
si può ricorrere a . essendo già riservato in SQL.
Alcuni
DBMS già dispongono di questa estensione : nel caso di Informix
la funzionalità è implementata attraverso lObject Translator
uno strumento da poco uscito dalla fase di beta, mentre ad esempio nel
db Cloudscape, distribuito con Java 2 Enterprise Edition di SUN, è
già supportata da quasi un anno.
Informix Embedded
SQL in Java
Si
è già parlato dettagliatamente di SQLJ 0 precedentemente,
pertanto in questa sezione vediamo come praticamente si muove uno sviluppatore
per creare un programma SQLJ per il database Informix.
Ecco
un esempio di programma SQLJ completo :
Perquisiti:
JDK
1.2
Informix
JDBC Driver Bundle (contiene SQLJ tools e runtime)
Informix
DBAccess (tool di amministrazione del DB)
GNU
Makefile.
sqlj.properties
: file
di properties utilizzato dal compilatore sqlj
####
Following are sample properties file entries:
####
If the sqlj.user is commented then Online semantic
###
check is not performed.
#
username
sqlj.user=informix
#
password
sqlj.password=segreto
#
classe del driver
sqlj.driver=com.informix.jdbc.IfxDriver
#
url di connessione al database
sqlj.url=jdbc:informix-sqli://localhost:1526/
demo_sqlj:informixserver=ol_demo
compile.verbose
DemoSQLJ.sqlj
: programma
SQLJ
import
java.sql.*; // JDBC 2.* o 1.*
import
sqlj.runtime.*; //SQLJ runtime classes
//
Dichiara iteratore per la scansione del result set
#sql
iterator CustRec(
int customer_num,
String fname,
String lname ,
String company ,
String address1 ,
String address2 ,
String city ,
String state ,
String zipcode ,
String phone
);
public
class DemoSQLJ
{
public static void main (String args[]) throws SQLException
{
DemoSQLJ demoSqlj = new DemoSQLJ();
try
{
demoSqlj.runDemo();
}
catch (SQLException s)
{
System.err.println( "Errore durante lesecuzione della demo: " + s );
System.err.println( "Error Code
: " +
s.getErrorCode());
System.err.println( "Error Message
: " +
s.getMessage());
}
}
// Inizializza la connessione al database attraverso Connection Manager
DemoSQLJ()
{
ConnectionManager.initContext();
}
void runDemo() throws SQLException
{
System.out.println();
System.out.println( "---== Programma demo SQLJ ==---" );
System.out.println();
// Dichiara Iterator di tipo CustRec
CustRec cust_rec;
#sql cust_rec = { SELECT * FROM customer };
int row_cnt = 0;
while ( cust_rec.next() )
{
System.out.println("===================================");
System.out.println("Numero utente :" + cust_rec.customer_num());
System.out.println("Nome :" + cust_rec.fname());
System.out.println("Cognome :" + cust_rec.lname());
System.out.println("Societa
:" + cust_rec.company());
System.out.println("Indirizzo
:" + cust_rec.address1() +"\n" +
"
" + cust_rec.address2());
System.out.println("Citta
:" + cust_rec.city());
System.out.println("Nazione
:" + cust_rec.state());
System.out.println("CAP
:" + cust_rec.zipcode());
System.out.println("Telefono
:" + cust_rec.phone());
System.out.println("===================================");
System.out.println("\n\n");
row_cnt++;
}
System.out.println("Numero di righe selezionate :" + row_cnt);
cust_rec.close() ;
System.out.println("\n\n\n\n\n");
}
}
Makefile
: makefile del progetto
PROGNAME=DemoSQLJ
%.java:%.sqlj
java
ifxsqlj props sqlj.properties $<
%:%.java
javac
$<
all
: $(PROGNAME)
jar:
jar
cvf demosqlj.jar DemoSQLJ.class Dem
clean:
rm
*.class
rm
*.java
Con
il Makefile a disposizione per creare il programma sono sufficienti i seguenti
comandi:
prompt>
make
prompt>
make jar
Abbiamo
così a disposizione un package contentente la nostra applicazione.
Per
eseguirla e verificare che tutto funzioni è sufficiente il comando:
prompt>
java DemoSQLJ
Devono
essere impostati i percorsi ai files ifxjdbc.jar, ifxsqlj.jar, ifxtools.jar
contenti rispettivamente il driver JDBC di Informix, il runtime di SQLJ
e il compilatore SQLJ perché la compilazione e il programma possano
funzionare.
Informix
Java Stored Procedures.
Anche
in questa sezione affrontiamo direttamente il problema pratico di creazione
di una routine Java nel database seguendo i passi illustrati precedentemente.
Creiamo
nel database una procedura hello che accetta come parametro un nome ,
ed es. Nico e ritorna il messaggio Ciao Nico! o Ciao a tutti! nel
caso non venga fornito un nome.
Prerequisiti:
JDK
1.2
J/Foundation
(parte di Informix Internet Foundation.2000)
Java
Virtual Processor (attivato dal DBA)
Informix
DBAccess (tool di amministrazione del DB)
GNU
Makefile.
//
Hello.java : sorgente della classe che contiene la nostra routine
public
class Hello
{
public static String hello(String nome)
{
if
(nome == null)
return Ciao a tutti!;
else
return Ciao + nome + !;
}
}
sqljdemo.sql
: script SQL che installa il JAR e crea la routine
--
install the Java UDR jar file (customize the URL for your installation)
execute
procedure install_jar(
"file:/home/informix/extend/krakatoa/examples/hello/Hello.jar",
"hello_jar",
0);
--
register the Java UDRs
create
function hello()
returns
lvarchar
external name 'hello_jar:Hello.hello()'
language java;
Makefile
: makefile del progetto
#--------------------------------------------------
#
#
Makefile
#
#
Requisiti :
#
#
GNU Make
#
SUN JDK 1.*
#
Informix DBAccess
#--------------------------------------------------
PROJNAME=Hello
SOURCES=$(wildcard
*.java)
CLASSES=$(patsubst
%.java,%.class,$(SOURCES))
JARNAME=$(PROJNAME).jar
TARGETS=${CLASSES}
${JARS}
DB=sqlj_demo
SQLSCRIPT=$(PROJNAME).sql
#
Pattern rules
#%.jar:
%.class
#
jar -cf `echo $< | sed -e "s/\.class/\.jar/"` $<
%.class:
%.java
javac
$<
all:
prog jar
prog:
$(CLASSES)
jar
: $(JAR)
jar
cvf $(JARNAME) $(CLASSES)
install:
prog jar
dbaccess
$(DB) $(SQLSCRIPT)
clean:
rm
-f *.class ${JARS}
help:
@echo
@echo
"-- Targets disponibili -- "
@echo
@echo
"jar : crea il JAR da installare nel DB"
@echo
"prog : crea i binari"
@echo
"clean : rimuove i binari"
@echo
"install : installa il JAR e crea la procedura"
@echo
"[default] : prog jar install"
@echo
Il
Makefile è fatto in modo da poterlo utilizzare in un altro progetto
semplicemente cambiando la
variabile
PROJNAME (nome del progetto).
A
questo punto è sufficiente eseguire il comando make, e se non
vi sono errori si ha nellordine compilazione,
creazione
del jar, installazione del Jar nel db e creazione della routine.
Occorre
ora semplicemente verificare che la routine sia effettivamente installata
e funzionante
utilizzando
ad esempio SQLEditor o DBAccess eseguendo la seguente istruzione:
EXECUTE
FUNCTION hello(Mario Rossi);
il
risultato sarà :
Ciao
Mario Rossi!
In conclusione
Larticolo
ha trattato piuttosto in dettaglio lo standard SQLJ per poi mostrare due
esempi di utilizzo di SQLJ con il database Informix.
Ci
si può chiedere a questo punto perché imparare SQLJ quando
esiste ed è ben collaudato JDBC ?
Il
confronto va fatto in realtà tra JDBC e SQLJ0 ovvero tra la maniera
tradizionale di accesso ai databases di Java e questa nuova possibilità
di introduzione di codice SQL embedded nel sorgente Java.
Indubbiamente
questultima tecnica ha il pregio di una maggiore semplicità, e
una certa potabilità (occorre infatti solo variare un file di proprietà
testuale per cambiare ad esempio il DB a cui il programma si connette oppure
la porta del DB Server) .
Per
contro SQLJ complica leggermente la procedura di sviluppo e appesantisce
il programma con i packages sqlj.runtime.* che con JDBC non sono ovviamente
necessari. Quindi è solo questione di preferenze personali. Il vantaggio
invece di poter scrivere potenti routine di database direttamente in Java
è subito apprezzabile, inoltre il loro meccanismo di creazione e
gestione non è affatto complicato, o comunque non più complicato
di una procedura scritta in C.
Ancora
più apprezzabile è infine SQLJ 3 che permette di immagazinare
gli oggetti Java nel database come tali e non come BLOB : questo semplifica
notevolmente la logica dei programmi oltre ad aprire grandi possibilità
per le applicazioni e i frameworks che richiedono la persistenza degli
oggetti.
|



