Introduzione
Dopo
aver parlato a lungo della teoria di EJB, passiamo questo mese ad affrontare
un esempio completo. Lo scopo di questo articolo sarà quello
di mettere in evidenza alcuni importanti aspetti nel caso in cui si voglia
realizzare una applicazione basata su EJB. Per quanto riguarda lesempio
allegato a questo articolo, pur essendo perfettamente funzionante, non
è prevista nessuna spiegazioni per linstallazione e deploy
nellapplication server, la quale fase è eseguibile in modo
pressoché automatico grazie ai potenti tool di sviluppo presenti
sul mercato.
Chi
lo desiderasse potrà approfondire tale argomento facendo riferimento
ai numerosi documenti reperibili sui siti web delle case produttrici dei
vari application server(vedi [BAS] e [BEA]).
Il caso duso
Il
caso in esame che affronteremo è quello di un carrello della spesa
virtuale che permetta lacquisto da parte di un client che si colleghi
al server remoto. Per facilitare la comprensione dei vari punti che analizzeremo,
come si è avuto modo di fare in precedenza, spesso ci rifaremo al
caso dellacquisto online tramite browser e protocollo HTTP.
Nel
caso specifico lesempio che analizzeremo è composto da quattro
bean, due session e due entity, in modo da prendere in esame tutte le possibili
casistiche. Vedremo anche alcuni semplici client in azione per evidenziare
come un bean possa essere gestito da remoto.
Il
codice delle varie classi è organizzato in modo che ogni package
contenga un caso particolare (entity CMP, entity BMP, session stateless
e session stateful), in modo da ottenere una configurazione estremamente
pulita, anche se leggermente ridondante.
Entity Bean
Lentity
bean che andiamo a realizzare, rappresentato dalla classe MokaUserBean,
ha il compito di memorizzare alcune informazioni relative allutente che
effettua le operazioni di acquisto di prodotti da remoto. In questo caso
molto semplice, le informazioni relative allutente sono rappresentate
dalle due variabili userId e userCredit. La prima memorizza un codice
univoco con cui lutente viene identificato, mentre la seconda rappresenta
il credito dellutente: al fine di semplificare al massimo eliminando parti
non significative che avrebbero complicato inutilmente il codice, si scelto
di quantificare con un portafoglio a punti il credito di ogni singolo utente,
tralasciando i dettagli relativi alla valuta utilizzata.
Tale
astrazione potrebbe essere del tutto plausibile in una community web dove
ogni singolo utente compra e vende beni utilizzando punti guadagnati tramite
la fornitura o scambio di servizi e o beni.
Nella
versione CMP, dove la persistenza di queste due variabili è attuata
in modo automatico dal container, il bean svolge solo poche operazioni,
se non si considerano quelle relative alla gestione del credito.
In
particolare il prelievo di punti (conseguente ad una operazione di prelievo)
o la memorizzazione (ricarica del punteggio) sono operazioni effettuabili
tramite i due metodi withdrawCredit() e rechargeCredit(). Ecco una possibile
implementazione
public
int withdrawCredit(int amount) throws UserAppException{
if (amount > userCredit){
throw new UserAppException("Si è tentato di addebitare una cifra
maggiore
di quella disponibile");
}
userCredit-=amount;
return userCredit;
}
public
int rechargeCredit(int amount){
userCredit+=amount;
return userCredit;
}
si
noti come in withdrawCredit(), prima di procedere al prelievo, venga
effettuato un controllo sul credito disponibile ed eventualmente sia generata
una eccezione specifica della applicazione. Dato che questi metodi rappresentano
la business logic del bean dovranno essere esposti tramite linterfaccia
remota MokaUserRemote generata automaticamente durante la creazione del
bean per mezzo di appositi wizard messi a disposizione dal tool, oppure
manualmente scrivendo le semplici righe di codice
public
interface MokaUserRemote extends EJBObject {
public void setUserCredit(int newUserCredit) throws RemoteException;
public int getUserCredit() throws RemoteException;
public void setUserId(java.lang.String newUserId) throws RemoteException;
public java.lang.String getUserId() throws RemoteException;
// business methods
public int withdrawCredit(int amount) throws UserAppException, RemoteException;
public int rechargeCredit(int amount) throws RemoteException;
}
Si
noti anche in questo caso la dichiarazione delle eccezioni generabili dai
due business methods
Gli
altri metodi della classe sono i classici accessori (get/set) per accedere
alle due variabili del bean, ed quelli relativi alla gestione del ciclo
di vita. Anche in questo caso non vi sono particolari note da evidenziare.
Metodi di ricerca
La
ricerca di un bean è una delle funzionalità più importanti
ed utilizzate durante linterazione da parte dei vari client. Le due tipologie
di ricerca abitualmente utilizzate vedono da un lato la ricerca per
chiave, e dallaltro tutti gli altri metodi che effettuano ricerche secondo
criteri particolari.
Nel
caso di un entity BMP, non deve essere scritta alcuna riga di codice per
implementare tali metodi, dato che vengono realizzati al momento del deploy,
e per questo non se ne troverà traccia allinterno del bean.
A
tal proposito può apparire piuttosto intuitivo il processo
messo in atto dal server per la generazione del corpo del metodo di ricerca
per chiave (facendo riferimento alla chiave della tabella del database
sottostante), mentre per gli altri ci si può chiedere quale
sia il processo seguito per arrivare alla definizione del metodo.
Anche
in questo caso EJB mette a disposizione una serie di strumenti molto potenti
ed efficaci: dato infatti che lo scopo principale di un CMP è astrarsi
completamente dal database sottostante si è pensato di definire
in modo astratto (es. tramite regole basate su SQL e formalizzate in un
file XML) quello che deve fare il metodo. Questa parte è fortemente
dipendente dal tool di deploy utilizzato: ad esempio in JBuilder, utilizzando
i wizard appositi si otterrà la seguente porzione di codice XML
<finder>
<method-signature>findBigCredit(int arg1)</method-signature>
<where-clause>where CreditBalance>100</where-clause>
<load-state>False</load-state>
</finder>
ad
indicare che il metodo findBigCredit() è uno dei metodi di ricerca
che dovrà restituire tutti gli elementi (bean) la cui variabile
credit sia maggiore del valore 100.
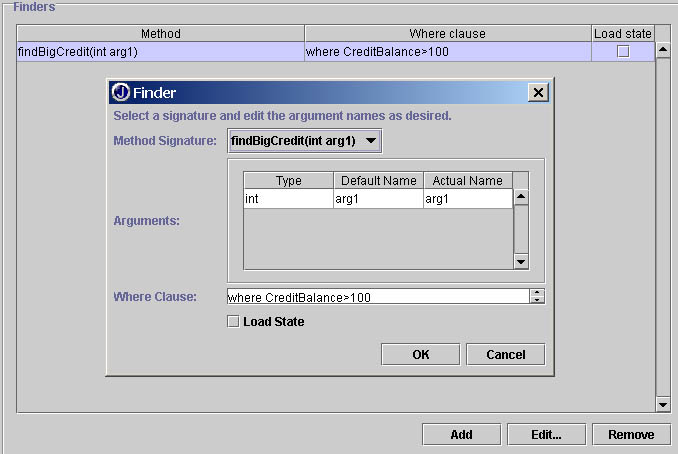
Figura
1: il wizard messo a disposizione da JBuilder 4.0 con il quale è
possibile definire le regole relative al metodo di ricerca
Equivalentemente
utilizzando WebLogic si otterrà un descriptor file che nella parte
relativa alla definizione del comportamento di tale metodo sarà
(finderDescriptors
"findBigAccounts(double creditGreaterThan)" "(> credit $creditGreaterThan)"
);
end finderDescriptors
con
una struttura in simil-XML.
E
presumibile che nelle prossime versioni tutti gli application server supportino
univocamente il formato XML per il deployment descriptor file.
Il client
Il
client, rappresentato dalla classe TestClient, effettua una serie di operazioni,
prima fra tutte il lookup delloggetto remoto ottendendo un riferimento
alla home interface MokaUserHome:
Context
ctx = new InitialContext();
Object
ref = ctx.lookup("MokaUser");
UserHome
= (MokaUserHome) PortableRemoteObject.narrow(ref, MokaUserHome.class);
Fatto
questo prova ad effettuare una ricerca nel database per verificare se esiste
un utente associato ad un determinato id.
UserRemote
= (MokaUserRemote) UserHome.findByPrimaryKey(UserId);
Tale
operazione restituisce linterfaccia remota al bean cercato, oppure null:
in tal caso si può procedere alla creazione del nuovo utente
if
(UserRemote == null) {
UserRemote = UserHome.create(UserId, initCredit);
}
Si
tralasci per il momento come creare o gestire i vari id degli utenti:
eventualmente per chi fosse curioso presso [BEA] si possono trovare alcuni
interessanti esempi su come gestire automaticamente tali valori, utilizzando
le routine che il database engine mette a disposizione.
Una
volta ottenuto il riferimento al bean, in un modo o nellaltro, si potranno
effettuare delle modifiche al credito invocando in successione i metodi
rechargeCredit() o withdrawCredit().
Nella
parte finale del client viene implementata una minimale gestione concorrente
di un bean da parte di più client. Per prima cosa si creano 10 thread,
classe ThreadClient, che agiranno sullo stesso bean
ThreadClient[]
Clients = new ThreadClient[10];
ThreadClient
TClient;
for
(int i = 0; i < Clients.length; i++) {
UserId = ""+System.currentTimeMillis(); // unique account id
Clients[i] = new ThreadClient(UserId, UserRemote, 1500);
Clients[i].start();
}
Il
metodo run della ThreadClient effettua un semplice prelievo dal credito
del bean.
public
void run() {
try
{
UserRemote.withdrawCredit(credit2Withdraw);
}
catch
(Exception e) {
}
}
come
si può notare, grazie al modello concorrente definito allinterno
della specifica EJB, non è necessario preoccuparsi dei dettagli
implementativi legati alla concorrenza o aspetti simili.
La
versione BMP del bean è relativamente simile a quella appena vista,
tranne che per due importanti differenze: la prima è nella diversa
implementazione dei metodi di persistenza, che in questo caso devono accedere
direttamente tramite JDBC ed SQL alle tabelle del database, e la seconda
è la differente organizzazione della gerarchia di classi messa in
atto.
Sul
primo punto non vi è molto da dire di più di quanto non sia
già stato fatto nelle puntate precedenti: i metodi ejbCreate(),
ejbRemove() così come quelli di ricerca, svolgono delle banali operazioni
di accesso ai dati tramite lapi JDBC. Benché il codice sia più
complesso, sicuramente chi si avvicina a EJB per la prima volta troverà
finalmente qualcosa di concreto e familiare.
Si
noti eventualmente, come accennato in precedenza, il modo in cui sono gestire
le eccezioni a seconda del tipo di errore generatosi: per tutti i problemi
a livello applicativo si genera una ApplicationException, mentre le SQLException
sono wrappate in una EJBException.
La
gerarchia delle classi invece è particolarmente interessante e mette
in evidenza alcuni aspetti di cui si è avuto modo di accennare in
precedenza senza dare particolare spiegazione del motivo.
Innanzi
tutto il bean remoto in questo caso è implementato dalle due classi
MokaUser e MokaUserBMP che estende MokaUser. La prima è di fatto
la copia esatta della versione CMP, ed è stata ripetuta solo per
fare ordine nei vari package in cui sono raggruppati i vari files.
La
MokaUserBMP invece estende la classe padre con lo scopo di ridefinire i
vari metodi ejbCreate, ejbLoad()ed ejbRemove().
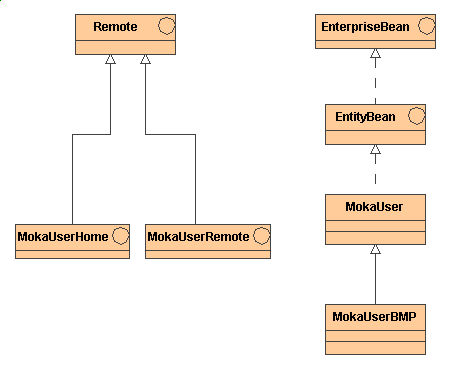
Figura
2: organizzazione delle classi per lentity bean BMP
In
questo modo con una semplice modifica al deploy descriptor ed aggiungendo
la classe figlia è possibile ridefinire il comportamento del bean
da CMP a BMP: questo piccolo trucco, che però è estremamente
importante ed utile, è reso possibile grazie ad una piccola modifica
introdotta con la specifica 1.1. Infatti adesso il metodo create restituisce
sempre una istanza della home interface, indipendentemente dal fatto che
si tratti di un CMP o di un BMP. Nel primo caso il valore ritornato sarà
ignorato del tutto, mentre nel secondo verrà utilizzato dal codice
successivo alla invocazione.
Dato
che in Java non è possibile loverload dei metodi con differenti
valori di ritorno, la scelta fatta dai progettisti di EJB permette di realizzare
strutture pulite con il minimo del lavoro.
Si
noti come questa particolare struttura è messa in atto automaticamente
da JBuilder utilizzando il wizard apposito per la generazione del
codice per lentity CMP.
Session Bean
Proseguendo
nella analisi dellesempio ipotizzato passiamo adesso a prendere in esame
il session bean. Come ho avuto modo di sottolineare più volte,
la definizione che secondo me rende meglio lidea circa lo scopo e la funzione
di questo genere di componenti è quella che li descrive come oggetti
lato server contenenti la business logic del client.
Quindi
visto che un session è logica di esecuzione, vediamo di capire come
e cosa ciò significhi in pratica.
Riprendendo
in esame lesempio del client che effettua degli acquisti da remoto, acquisti
poi addebitati sul conto di un particolare utente, e mantenendo il parallelo
con il caso del carrello della spesa web, in questo caso il
session bean implementerà quelle funzionalità di gestione
del carrello della spesa, quindi con aggiunta e rimozione di prodotti.
Per
fare questo linterfaccia pubblica del bean offrirà i metodi addItem()
e removeItem() utilizzabili dal client per laggiunta e la rimozione di
prodotti dal carrello.
Per
rendere lo scenario più plausibile e veritiero si immagini che ogni
qualvolta il client aggiunga un elemento al carrello della spesa virtuale,
oltre ad effettuare la memorizzazione, instauri tramite il metodo
getPrice() una connessione verso un non meglio specificato service remoto
per ottenere il prezzo delloggetto in funzione del cliente che ne effettua
lacquisto (ipotizzando un politica di prezzi variabili). Il metodo getPrice()non
è implementato e la sua presenza è giustificata solo per
rendere più realistico lo scenario.
Il
bean quindi in questo caso svolgerà due funzioni importanti: da
un lato fornire il servizio di calcolo del prezzo per ogni oggetto aggiunto
al carrello, e dallaltro memorizzare lo stato dei prodotti presenti nel
carrello. Ovviamente questa seconda funzionalità verrà messa
a disposizione solo nel caso della versione stateful, mentre nellaltro
caso dovrà essere il client che dovrà tenerne traccia. Per
questo motivo i metodi addItem() e removeItem() restituiscono il prezzo
delloggetto aggiunto al carrello, in modo che il client possa ricavare
il prezzo delloggetto.
Questo
scenario è stato scelto perché evidenzia in modo molto netto
ed immediato la differenza fra i due tipi di session bean, dal punto di
vista applicativo. Anche in questo caso infatti, così come avviene
per i sistemi di commercio elettronico via web, è il client che
deve tener traccia della sua identità e della persistenza dello
stato (ad esempio tramite cookie, o sessioni divario tipo), il client deve
memorizzare il cambiamento della configurazione dopo aver effettuato una
invocazione di metodi remoti sul server.
Nel
caso del bean stateful il container si preoccuperà di mantenere
la persistenza delle variabili pubbliche
public
java.util.Hashtable itemsBasket;
public
String clientId;
private
int amount;
Limplementazione
dei metodi per la gestione dei prodotti nel carrello potrebbe essere per
il primo
public
Integer addItem(String productCode){
Integer
price = getPrice(productCode, clientId);
itemsBasket.put(productCode,
price);
amount+=price.intValue();
return
price;
}
mentre
removeItem()
potrebbe essere
public
Integer removeItem(String productCode){
Integer price=(Integer)itemsBasket.get(productCode);
itemsBasket.remove(productCode);
amount-=price.intValue();
return price;
}
Questi
due metodo agiscono sulle variabili appena viste, modificandone il contenuto
al fine di rendere consistente il contenuto del carrello virtuale. Tale
mantenimento viene effettuato in automatico semplicemente per il fatto
che sono variabili pubbliche.
Il
client quindi dopo aver ricavato il riferimento allinterfaccia remoto
nel modo consueto
Context
ctx = new InitialContext();
Object
ref = ctx.lookup("StatefulShopper");
statefulShopperHome
= (StatefulShopperHome) PortableRemoteObject.narrow(ref, StatefulShopperHome.class);
StatefulShopperRemote
Shopper=statefulShopperHome.create("ClientXYZ");
Potrà
procedere a modificare il contenuto del carrello tramite i due metodi
appena visti
Shopper.addItem("prod_121");
Shopper.addItem("prod_123");
Shopper.addItem("prod_124");
Shopper.addItem("prod_125");
Shopper.removeItem("prod_121");
Ed
eventualmente stampare il conto totale da pagare
System.out.println("Il
prezzo complessivo da pagare: "+Shopper.getAmount());
ricavando
tale valore con il metodo getAmount().
Nella
versione stateless le variabili itemsBasket, clientId ed amount perderanno
il loro stato fra due invocazioni successive, e per questo il client ne
deve tenere traccia, ad esempio nel seguente modo
Amount+=Shopper.addItem("prod_121","ClientXYZ");
Amount+=Shopper.addItem("prod_123","ClientXYZ");
Amount+=Shopper.addItem("prod_124","ClientXYZ");
Amount+=Shopper.addItem("prod_125","ClientXYZ");
Amount-=Shopper.removeItem("prod_121");
Stampando
il conto totale accedendo direttamente alla variabile client-side di cui
si è tenuto traccia
System.out.println("Il
prezzo complessivo da pagare: "+Amount);
Riconsiderando
lesempio appena visto può apparire più chiaro quando sia
indicato utilizzare un bean stateless piuttosto che uno stateful: questultimo,
consentendo di gestire il cosiddetto converstaional state, può
risultare particolarmente indicato in quei casi in cui le successive invocazioni
del client devono essere fatte in funzione di quanto avvenuto in precedenza
(si immagini una serie di operazioni di acquisto/vendita in cui si debba
agire in base al conto totale totalizzato ad ogni istante). Quindi lesempio
appena visto troverebbe piena giustificazione in un stateful.
Se
invece lo scopo fosse stato esclusivamente quello di mettere a disposizione
una serie di metodi di servizio come il getPrice() direttamente a disposizione
del client, allora uno stateless bean sarebbe stato sicuramente più
adatto.
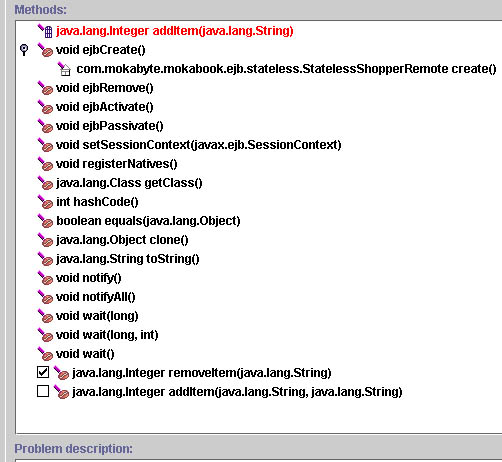
Figura
3: solo i metodi che devono essere invocati dal client sono
esposti
pubblicamente nella interfaccia remota del bean
Conclusione
Dopo
le varie puntate teoriche, il lettore finalmente avrà modo di sperimentare
direttamente sul campo lutilizzo di un sistema EJB.
Sulla
base dellesempio appena visto si tengano presenti due cose: la prima è
che sicuramente si tratta di un esempio molto semplice, il cui scopo è
non tanto quello di mostrare le potenzialità nei minimi dettagli
della piattaforma EJB, ma piuttosto di comprenderne la filosofia con un
esempio completo. Ad esempio quanto detto nel caso del sub-classing del
bean BMP e della firma del metodo ejbCreate(), dovrebbe far comprendere
come lo scenario sia in realtà molto complesso e che il pregio di
EJB, una volta giunto alla maturità, è proprio quello di
essere predisposto per levoluzione futura.
Laltra
osservazione di cui tener conto è che lo sforzo principale di Sun
sia stato rivolto a definire una specifica piuttosto che una API o un prodotto
fine a se stesso: questo fatto però pur essendo il principale punto
di forza di EJB ne rappresenta anche la maggiore limitazione per tutti
coloro che si avvicinano a tale tecnologia per la prima volta. Le molte
cose da sapere infatti non si limitano solo alle specifiche, ma anche ed
in forma piuttosto importante alle modalità di deploy negli application
server e quindi nel comportamento di tali prodotti.
E
per questo motivo quindi che ci siamo mantenuti fino a questo punto ad
un livello piuttosto teorico ed astratto, demandando la parte pratica a
quanto riportato nei vari tutorial dei prodotti commerciali.
Bibliografia
[BAS]:
paper per il deploy ed installazione su JB e BAS
[BEA]:
http://www.weblogic.com/docs/resources.html
Allegati
Gli
esempi descritti in questo articolo possono essere scaricati cliccando
qui
|



