Senza
entrare nel merito della architettura di unapplicazione web e della sua
organizzazione su più livelli - presentation layer, business layer,
data layer - la cui suddivisione logica e fisica porta ad applicazioni
di tipo single-tiered o multi-tiered -, possiamo, in maniera molto povera
dal punto di vista dei contenuti ma ottima per presentare un esempio, immaginare
che una applicazione web sia costituita, ai suoi minimi termini, da uninterfaccia
grafica verso lutente (che viene eseguita in un browser), e da un server
con le sue estensioni, su cui gira almeno una servlet. Tra questi due elementi
cè il protocollo HTTP, lo standard attraverso cui browser e web
server possono comunicare:
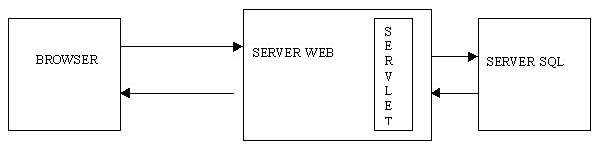
Figura
1. Architettura di unapplicazione web a due livelli
Questo
tipo di architettura permette di gestire agevolmente un sito che consente
allutente di ottenere pagine che non siano generate staticamente dal server
web, ma costruite dinamicamente dalla servlet.
Tuttavia,
se la quantità di pagine e di informazioni da gestire è consistente,
affidare tutto il carico di lavoro ad una sola servlet è:
-
Complicato
dal punto di vista dellarchitettura;
-
Estremamente
soggetto ad errori, data la complessità del flusso;
-
Esteticamente
poco elegante;
-
In alcune
circostanze assolutamente impraticabile.
Supponiamo
di dover realizzare un sito per la vendita di CD on-line. Potremmo distinguere
due macro-funzionalità:
-
Visualizzazione
del catalogo;
-
Inserimento
degli ordini da parte dellutente.
In
virtù di questa suddivisione molto spartana, potremmo desiderare
di avere due servlet che si occupino della gestione rispettivamente delluna
e dellaltra funzione. Inoltre, potremmo volere una terza servlet il cui
compito sia di accettare tutte le richieste del browser e di smistarle
alla servlet competente; questo semplifica il lavoro a noi stessi e allo
sviluppatore che scriverà i template HTML.
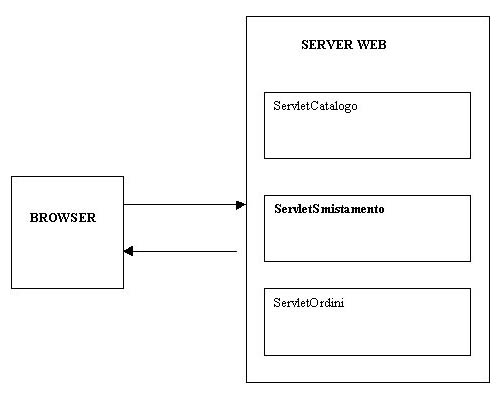
Figura
2. Il server è composto da tre risorse distinte
Ovviamente,
questo tipo di prospettazione non si propone di illustrare come si può
strutturare lapplicazione, ma è funzionale allo svolgimento dellesempio.
Quando
lutente richiede al browser di visualizzare una pagina, ServletSmistamento
reindirizza la richiesta verso, supponiamo, ServletCatalogo. Per fare questo
ci sono tre sistemi, di cui due sono in realtà una diversa formalizzazione
dello stesso concetto.
Il
protocollo HTTP mette a disposizione un header (REDIRECT), che, inviato
dal web server al browser, comunica a questultimo dove andare a cercare
la risorsa che si aspetta di ottenere.
Gli
header sono stringhe che vengono trasmesse dal browser al server web e
viceversa prima e dopo la spedizione di un file. Non sono il contenuto
della pagina, ma rivelano informazioni SUL contenuto della pagina (META-informazioni):
in pratica gli header sono la formalizzazione dello standard HTTP. Il browser
spedisce gli header al web server per comunicare informazioni sul tipo
di connessione usata, sui linguaggi preferiti o accettati, sui tipi MIME
contenuti nella pagina, e
altre informazioni del tipo definito dallutente,
tramite i cookies, che sono in realtà pezzetti di header che viaggiano
dal server web al browser e viceversa. Chiunque abbia sviluppato servlet
si è prima o dopo trovato a scrivere o a leggere listruzione response.setContentType(text/html).
Lheader content-type dice al browser cosa deve aspettarsi in ingresso.
Se non viene impostato, il browser non sa come interpretare il flusso di
input ricevuto(Netscape visualizza una pagina bianca, anche se riceve tutta
la stringa HTML, mentre Explorer 5 e succ. è comunque in grado di
riconoscere il tipo MIME dal contenuto della stringa). Ma, sebbene sia
lunico che uno sviluppatore di servlet è obbligato a definire manualmente,
content-type non è lunico header che si può inviare al browser
tramite codice.
Header HTTP redirect
Lheader
REDIRECT (status code 301 e 302) nasce, quindi, per dire al browser che
la risorsa che cerca si trova nella nuova locazione, che viene specificata
nel campo LOCATION.
Supponiamo
che lutente chieda di vedere il catalogo dei CD disponibili: attiverà
un link ad una URL simile a questa:
http://localhost:8080/CD/servlet/ServletSmistamento?
operazione=catalogo&genere=classica&naz_autore=D
nel
doGet (o nel doPost, ma supponiamo per comodità che sia una chiamata
GET) di ServletSmistamento troviamo:
public
void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException{
// non ho bisogno di un oggetto PrintWriter
// o ServletOutputStream, perchè questa servlet non risponde
//direttamente al browser
//imposto content-type della risposta
response.setContentType(text/html);
String url = ;
//controllo i parametri nella Query String
if(request.getParameter(operazione).equals(catalogo)){
// passo alla nuova servlet tutta la Query String,
// anche se potrei usare il metodo
// parseQueryString() per eliminare il parametro operazione.
// Comunque questo non provoca problemi
// NOTARE CHE LA URL E ASSOLUTA
url = http://localhost:8080/CD/servlet/ServletCatalogo?+
request.getQueryString();
//Imposto il campo Location
response.setHeader(Location, url);
//imposto lo status: 302 corrisponde a
// MOVED_ TEMPORARILY (con 301,
// MOVED_PERMANENTLY, la prossima volta che il browser
// dovrà chiamare quella stessa
// locazione, la cercherà nella nuova URI
response.setStatus(302);
//tutto il codice che segue verrà comunque eseguito
}
else if(request.getParameter(operazione).equals(ordine)){
url = http://localhost:8080/CD/servlet/ServletOrdini?+
request.getQueryString();
response.setHeader(Location, url);
response.setStatus(302);
}
}
Appena
comincia lesecuzione di doGet() la servlet si chiede a quale delle due
servlet deve rimbalzare la rchiesta del browser. In realtà bisognerebbe
prevedere anche del codice che restituisca una pagina di errore se loperazione
di redirect non dovesse andare a buon fine. Inoltre, si potrebbe pensare
di inserire in ServletSmistamento le operazioni di inizializzazione di
pool di oggetti (ad esempio, connessioni, che potrebbe essere argomento
di futuri articoli) che poi saranno usati anche dalle altre due servlet...
insomma il codice dovrebbe essere molto più complesso, ma ora concentriamoci
su quello che succede:
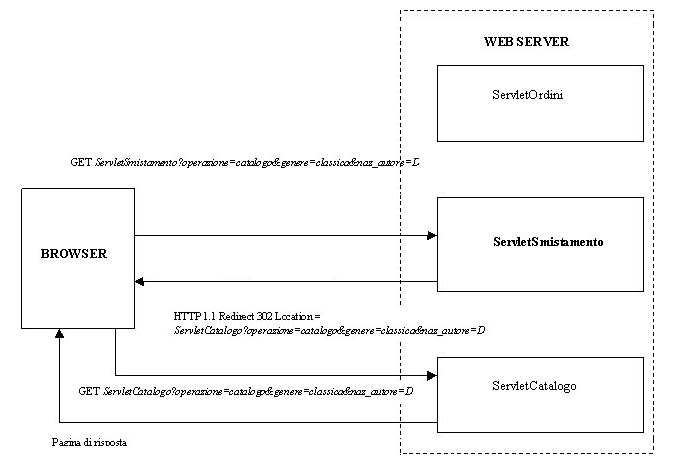
Figura
3. Architettura delloperazione di Redirect Browser - Server1 -Browser
- altro Server2
HttpServletResponse.sendRedirect()
Lo
sviluppatore di servlet Java ha a disposizione delle API che forniscono
un sistema più elegante per fare la stessa cosa.
Linterfaccia
HttpServletResponse() descrive il metodo sendRedirect(String url). Questo
metodo, quando viene invocato, invia al browser un header di redirect temporaneo
(status code 302). Il codice precedente diventa:
public
void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException{
//imposto content-type della risposta
response.setContentType(text/html);
String url = ;
if(request.getParameter(operazione).equals(catalogo)){
//NOTARE CHE LA URL E ASSOLUTA
url = http://localhost:8080/CD/servlet/ServletCatalogo?+
request.getQueryString();
//chiamo sendRedirect passandogli la nuova URI,
// con la Query String
response.sendRedirect(url);
}
else if(request.getParameter(operazione).equals(ordine)){
url = http://localhost:8080/CD/servlet/ServletOrdini?+
request.getQueryString();
response.sendRedirect(url);
}
}
Nonostante
il codice sia leggermente cambiato, la figura 3 è ancora valida
per descrivere quello che avviene.
Tramite
sendRedirect() la servlet invia al browser un header redirect, valorizzando
il campo Location con la URI passata al metodo come parametro.
Fin
qui sembra essere tutto semplice, ma, quando si parla di web, le sorprese
sono sempre in agguato, e di solito sono sorprese dispendiose in termini
di tempo. Quando si usa sendRedirect(), si affida ad unaltra risorsa il
compito di rispondere al browser. Per cui è indispensabile NON aprire
stream di output, ne prima, ne dopo linvocazione di sendRedirect(), poiché
il browser potrebbe trovarsi a ricevere una risposta sporca e quindi
visualizzare una pagina dal contenuto assolutamente insensato ed incongruente
con ciò che lutente si aspetta di vedere.
public
void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException{
//istanzio loutput stream per la risposta
PrintWriter out = response.getWriter();
//imposto content-type della risposta
response.setContentType(text/html);
String url = ;
//controllo i parametri nella Query String
if(request.getParameter(operazione).equals(catalogo)){
url = http://localhost:8080/CD/servlet/ServletCatalogo?+
request.getQueryString();
response.setContentType(text/html);
// chiamo sendRedirect passandogli la nuova URI,
// con la Query String
response.sendRedirect(url);
}
else if(request.getParameter(operazione).equals(ordine)){
url = http://localhost:8080/CD/servlet/ServletOrdini+
request.getQueryString();
response.sendRedirect(url);
}
//spedisco una pagina al client
out.print(<html> <title>Questa Pagina ");
out.println(è potenzialmente dannosa!</title>);
out.print(<body><H2>Probabilmente non vedrai questa");
out.println( scritta\n);
out.print(anzi potresti vedere una pagina molto ");
out.println(strana</H></body></html>);
out.close();
}
nelle
linee di codice precedente viene compiuta unoperazione potenzialmente
dannosa. Dopo la chiamata a sendRedirect, lesecuzione del codice continua,
ma sendRedirect ha già detto al browser di richiedere al server
unaltra pagina. In effetti, è molto probabile che lesecuzione
delle ultime righe di codice possa e debba considerarsi alternativa alla
chiamata a sendRedirect().
public
void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException{
//predispongo loutput stream per la risposta
PrintWriter out = null;
String url = ;
if(request.getParameter(operazione).equals(catalogo)){
url = http://localhost:8080/CD/servlet/ServletCatalogo?+
request.getQueryString();
response.setContentType(text/html);
// chiamo sendRedirect passandogli la nuova URI,
// con la Query String
response.sendRedirect(url);
}
else if(request.getParameter(operazione).equals(ordine)){
String url;
url=http://localhost:8080/CD/servlet/ServletOrdini?+
request.getQueryString();
response.sendRedirect(url);
}
else{
// istanzio loggetto Writer
out = response.getWriter();
// spedisco una pagina al client
out.print(<html> <title>Questa Pagina è potenzialmente");
out.println(dannosa!</title>);
out.print(<body><H2>Probabilmente non vedrai ");
out.println(questa scritta\n);
out.print(anzi potresti vedere una pagina molto");
out.println(strana</H></body></html>);
out.close();
}
}
In
questo esempio, o viene chiamato sendRedirect() oppure viene aperto loutput
stream per la risposta al browser... questo è il modo corretto di
operare con sendRedirect(). Per dirla in termini molto tecnici, è
bene essere sicuri che linvocazione di sendRedirect() sia in un ramo di
else rispetto allapertura e alluso di un output stream (questo vale anche
per System.out.println(pippo)).
RequestDispatcher
Ai
più avvezzi con il mondo della programmazione, anche non in ambito
web, non sarà sfuggita la complessità e lo spreco di risorse
insito in questo modo di lavorare:
-
Il browser
chiede una pagina
-
La servlet
interpreta la richiesta e decide dove reindirizzarla
-
La servlet
dice al browser dove può trovare la risorsa che ha chiesto
-
Il browser
invia unaltra richiesta alla nuova URI
-
La seconda
servlet finalmente risponde
Il punto
1) mi sembra inevitabile, e anche il punto 2) sembra avere una sua ragion
dessere. Ma il punto 3), e di conseguenza il 4), potrebbero essere ottimizzati.
Perché
mai la servlet non potrebbe chiamare direttamente unaltra risorsa passandogli
la querystring ottenuta dal browser? Il nostro paradigma diventerebbe:
-
Il browser
chiede una pagina
-
La servlet
interpreta la richiesta e decide dove reindirizzarla
-
La servlet
invoca unaltra servlet e le affida il compito di rispondere al browser
-
La seconda
servlet elabora la richiesta e risponde
Non solo
si è eliminato un passaggio, ma il punto 3, che nella precedente
ipotesi era dispendioso (soprattutto con connessioni non di tipo keep-alive)
si è notevolmente alleggerito. Questo nellassunto che tutte le
risorse si trovino sullo stesso server e non su due macchine distanti tra
di loro, nel qual caso la prima soluzione no ha alternative ( a meno che
non si parli di RMI e CORBA naturalmente).
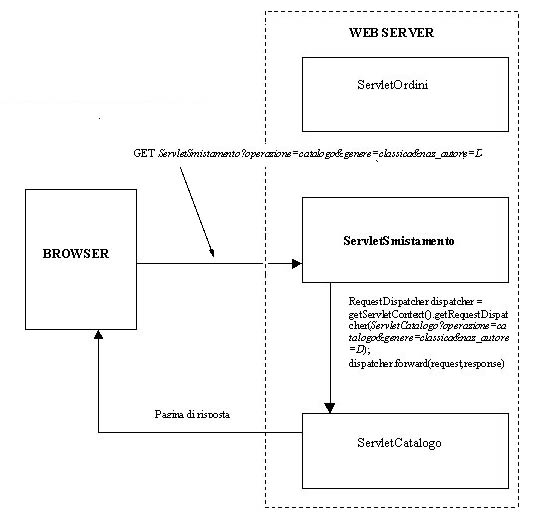
Figura
4. operazione di forwarding: la servlet inoltra
direttamente
la richiesta ad unaltra servlet
Fortunatamente,
le API servlet mettono a disposizione un oggetto molto utile per gestire
questo tipo di operazione: linterfaccia RequestDispatcher.
Unistanza
di RequestDispatcher può essere ottenuta con il metodo getRequestDispatcher(String
url) di ServletContext:
RequestDispatcher
dispatcher = getServletContext().getRequestDispatcher(url);
questa
interfaccia ha due metodi: forward() e include().
Linterfaccia
RequestDispatcher agisce come un wrapper, un contenitore che impacchetta
la richiesta del browser e le informazioni per rispondere, e le consegna
ad unaltra risorsa (che non deve essere necessariamente una servlet, ma
può essere anche una JSP, una CGI, una pagina HTML
).
Metodo;
forward(HttpServletRequest request, HttpServletResponse response)
Il
metodo forward() è molto diverso da sendRedirect(): il browser non
entra più nella catena della comunicazione tra due risorse sul server,
ma soprattutto è sensibilmente diverso il modo in cui il codice
deve essere concepito. Con forward() si affida ad unaltra risorsa del
server la responsabilità di rispondere al browser.
public
void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException{
//istanzio loutput stream per la risposta
PrintWriter out = response.getWriter();
//imposto content-type della risposta
response.setContentType(text/html);
String url = ;
//controllo i parametri nella Query String
if(request.getParameter(operazione).equals(catalogo)){
//NOTARE CHE LA URL E RELATIVA
url=/servlet/ServletCatalogo?+request.getQueryString();
// Ora spedisco una pagina al client come avevo
// fatto nellesempio precedente
out.println(<html> );
out.print(<title>Questa Pagina è sicuramente ");
out.println(inutile</title>);
out.print(<body><H2>Sicuramente non vedrai questa ");
out.println(scritta</H>);
out.print(Perché il mio buffer di output verrà ");
out.println(cancellato!);
out.println(</body>);
out.println(</html>);
// ottengo loggetto RequestDispatcher
RequestDispatcher dispatcher;
dispatcher = getServletContext().getRequestDispatcher(url);
// chiamo forward passandogli loggetto request
// e loggetto response
dispatcher.forward(request, response);
}
else if(request.getParameter(operazione).equals(ordine)){
url = /servlet/ServletOrdini?+request.getQueryString();
RequestDispatcher dispatcher;
dispatcher = getServletContext().getRequestDispatcher(url);
dispatcher.forward(request, response);
//Provo ancora una volta a spedire una pagina al client
out.println(<html> );
out.println(<title>Anche questa Pagina è inutile</title>);
out.print(<body><H2>Sicuramente non vedrai questa ");
out.println(scritta</H2>);
out.print(Perché non posso scrivere sul buffer ");
out.println(di output!);
out.println(</body>);
out.println(</html>);
out.close();
}
}
Ricorderete
che abbiamo sconsigliato la scrittura di codice simile a questo quando
si usa di sendRedirect().
Qui,
invece, tutto loutput che si trova prima della chiamata di forward() e
tutto quello che sta dopo,semplicemente non viene visualizzato, anzi neanche
spedito: qualsiasi stream apriamo non raggiungerà mai la sua destinazione.
Quando
viene invocato forward(), ci si aspetta che ci sia unaltra servlet (o
qualsiasi altro oggetto) che invii una risposta alla richiesta che il browser
aveva originariamente fatto alla prima servlet. La spiegazione di questo
ci porta a parlare brevemente del concetto di buffered response,
e di come questo meccanismo viene usato dalle servlet. La risposta ad un
client da parte di una servlet è SEMPRE bufferizzata, a meno che
noi non indichiamo esplicitamente il contrario. Non possiamo andare a fondo
allargomento (che spero di affrontare in una successiva serie di articoli,
perché ha molto a che fare col discorso di miglioramento delle performance
dellapplicazione), ma, brevemente, questo avviene per ottimizzare le prestazioni.
Ogni
volta che viene aperto uno stream in uscita o in entrata si fa una chiamata
al sistema (si esce quindi dallambito della macchina virtuale Java).
Ogni chiamata di sistema è un collo di bottiglia, che rallenta
le prestazioni di unapplicazione. Per questo motivo si tenta di ridurre
le chiamate di sistema utilizzando un buffer in cui parcheggiare i dati
da scrivere, per poi scriverli quando il buffer è pieno.
Ci
sono vari esempi di questo modo di operare, e il funzionamento delle servlet
è uno di questi (un altro potrebbe essere Oracle Server, che prima
di scrivere le modifiche DML su datafile, le appoggia in unapposita area
di memoria che si chiama Data Base Buffer Cache; quando questa si riempie,
viene invocato un processo che si chiama DBWR- DB WRiter- che riversa la
DBBC su datafile e in maniera speculare aggiorna i segmenti di rollback).
In generale, possiamo dire che tutto ciò che prevede il passaggio
di dati verso unarea di memoria persistente(Hard Disk) o verso unuscita
di sistema (socket) passa prima per un buffer. Quindi, più capiente
è il buffer, meno chiamate di sistema vengono effettuate. Dallaltro
lato, tuttavia, questo si paga in termini di memoria, perché un
buffer è di fatto unarea di memoria RAM. Bisogna quindi vedere
quanta memoria si è disposti a sacrificare in cambio di un dato
incremento delle prestazioni, e questa è materia ormai annosa e
sempre attualissima: il cosiddetto trade-off tra uso della memoria e incremento
delle prestazioni. E un argomento, questo, che meriterebbe veramente uno
spazio tutto suo per essere affrontato...
Per
tornare a noi, quando viene invocato forward(), il buffer viene ripulito
e la servlet perde la capacità di scrivere ancora su di esso: tale
responsabilità è ora della servlet oggetto di forward().
Ciò
significa che la servlet che invoca forward() rinuncia di fatto alla facoltà
di utilizzare il buffer.
Quindi,il
buffer può essere riempito solo dalla servlet che è stata
invocata dalloggetto RequestDispatcher. Per la stessa ragione, una chiamata
a forward dopo che il buffer è già stato ripulito (chiamando
response.flushBuffer() oppure out.close()), provoca una eccezione di tipo
IllegalStateException. Le API servlet 2.2 sono un grande passo in avanti
rispetto alle precedenti versioni, poiché forniscono un controllo
diretto sulle caratteristiche e dimensioni del buffer.
NOTA:
per quanto riguarda Java Server Pages, esiste un campo di JSPWriter, NO_BUFFER,
che serve ad escludere esplicitamente luso di un buffer nella gestione
delle risposte al browser; la modalità NO_BUFFER per il JSPWriter
devessere impostata allatto dellistanza di PageContext (oggetto dal
quale si ottiene JSPWriter con il metodo getOut()): largomento buffer
(di tipo int) di getPageContext() può essere impostato come JSPWriter.NO_BUFFER.
Inoltre, lattributo buffer della direttiva page può essere
usato per indicare se loggetto response della pagina dovrà o meno
fare uso del buffer (che ha una dimensione di default di 8k). Lattributo
autoFlush, invece, serve a stabilire se il buffer debba o meno essere
ripulito automaticamente, oppure debba essere sollevata una eccezione allatto
del suo riempimento, con conseguente gestione manuale dello svuotamento.
In questo caso, response.flushBuffer() diventa forse il metodo più
importante che dovete prendere in considerazione. Ma, a meno che non abbiate
particolari esigenze, vi conviene non toccare questi attributi...
Una
chiamata a forward() dopo che la risposta è stata committata,
cioè dopo una chiamata a response.flushBuffer() o ad out.close(),
provoca una eccezione IllegalState. Provate queste righe:
public
void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException{
//istanzio loutput stream per la risposta
PrintWriter out = response.getWriter();
//imposto content-type della risposta
response.setContentType(text/html);
String url = ;
// Ora spedisco una pagina al client come avevo
// fatto nellesempio precedente
out.print(<html> <title>Questa Pagina è
out.println(sicuramente inutile</title>);
out.print(<body><H2>Sicuramente non vedrai questa");
out.println(scritta</H></body></html>);
out.flushBuffer();
// questa chiamata provocherà uneccezione di tipo
// IllegalStateException: catturiamola
RequestDispatcher dispatcher;
try{
dispatcher=getServletContext().getRequestDispatcher(url);
dispatcher.forward(request, response);
}
catch(IllegalStateException ise){
// lunica cosa che vedrò sarà la stack
// trace delleccezione
ise.printStackTrace(out);
}
}
NOTA:
sempre nellambito delle risposte bufferizzate, quando chiamate il metodo
flushBuffer() tutto ciò che si trova nel buffer che non è
stato ancora inviato al browser viene scritto immediatamente.
Metodo:
include(HttpServletRequest req, HttpServletResponse res)
Laltro
metodo di RequestDispatcher è include(). Permette a una servlet
di includere loutput di unaltra risorsa nella risposta al client. Questa
risorsa, ancora una volta, può essere anche una jsp, una CGI, una
pagina HTML. Ovviamente, è possibile chiamare include() anche dopo
aver invocato flushBuffer(), perchè nel caso di include il buffer
rimane, per così dire, nella disponibilità della risorsa
chiamante e anche di quella chiamata. il metodo include() è molto
meno pericoloso di forward() per quanto riguarda la possibilità
di generare eccezioni.
Si
pensi al caso di un sito in cui cè, ad esempio, una testata presente
in ogni pagina: sarà compito di una sola servlet generarla, e a
noi sarà sufficiente includere questa servlet in tutte le altre
che generano le varie pagine:
Ipotizziamo
di avere questo doGet() in una servlet che chiameremo ServletTestata:
public
void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
PrintWriter
out = response.getWriter();
response.setContentType("text/html");
out.println("<H2>
QUESTA E LA TESTATA DEL MIO SITO </H2>");
}
In
unaltra sevlet, che chiameremo ServletPagina, vogliamo includere loutput
di ServletCatalogo:
public
void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException{
PrintWriter out = response.getWriter();
response.setContentType("text/html");
out.println("<html>");
out.println("<body>");
String url = "";
url = "/servlet/ServletTestata"
RequestDispatcher dispatcher;
dispatcher = getServletContext().getRequestDispatcher(url);
if(dispatcher != null){
// QUI VIENE INCLUSOLOUTPUT DI ServletTestata
dispatcher.include(request,response);
}
out.println("<H2> questo è il corpo della pagina</H2>");
out.println("Se volessi, potrei includere anche altri file!");
out.println("</body>");
out.println("</html>");
//
out.close();
}
Conclusioni
Per
concludere, direi che dovremmo concentrarci sulle differenze tecniche e
di uso tra sendRedirect() e di oggetti RequestDispatcher. Facciamo un piccolo
riassunto.
Per
prima cosa, usate forward() e include() se le risorse che volete far comunicare
girano sullo stesso server, mentre se sono su macchine remote è
necessario usare sendRedirect(). Quando usate il metodo sendRedirect(),
abbiate cura di passargli delle URL assolute, mentre loggetto RequestDispatcher
si dovrebbe creare con una URL relativa: disattenzioni su questi semplici
accorgimenti provocano fastidiosi errori.
Inoltre,
non bisogna mai chiamare forward() o include() dopo che la risposta sia
già stata committata (chiedo scusa per lorribile termine). Nel
caso non si sia sicuri di questo, si può (si deve) usare un controllo
tipo:
if(!response.isCommitted()){
dispatcher.forward(request,responde);
}
Infine,
non pensiate che tutto si esaurisca con i metodi che abbiamo descritto:
sono stati volutamente tralasciati RMI e CORBA, che tuttavia vanno molto
al di là dellambito delle servlet, così come dello scopo
di questo articolo.
Bibliografia
M.
Wutka, Using Java Server Pages and Servlets, QUE. James Goodwill, Java
Server Pages, Guida di Riferimento, Apogeo.
Allegati
Gli
esempi descritti in questo articolo sono scaricabili cliccando qui
|


