Dopo
gli articoli dei mesi scorsi si dovrebbe essere in possesso adesso delle
conoscenze di base della tecnologia EJB, anche se ad ora però ne
è stato volutamente lasciato in sospeso uno degli aspetti più
importanti di EJB, ovvero quello relativo alla gestione delle transazioni.
Per
la stessa natura degli EJB è piuttosto evidente che laccesso concorrente
da parte di più client sullo stesso set di bean comporta prima o
poi un accesso concorrente ai dati memorizzati nel database, rendendo necessario
un qualche sistema di controllo dei dati.
Visto
che la filosofia di base di EJB è quella di semplificare il lavoro
dello sviluppatore di bean, anche in questo caso il lavoro sporco verrà
effettuato dal container, consentendo una volta di più di lasciare
il programmatore a concentrarsi solo sulla logica business del componente.
Vediamo
quindi quali sono i passi necessari per fornire il cosiddetto supporto
transazionale ai componenti EJB.
Introduzione alle
transazioni: il modello ACID
Lobiettivo
primario di un sistema transazionale è garantire che laccesso concorrente
ai dati non porti a situazioni incoerenti sui dati stessi o sui risultati
di tali operazioni. Per ottenere questo risultato in genere si fa riferimento
al cosiddetto modello ACID, ovvero una transazione deve essere atomica
(Atomic), consistente (Consistent), isolata (Isolated), e duratura (Durable).
Atomic
indica che tutte le operazioni che costituiscono la transazione devono
essere eseguite senza interruzioni; se per un qualche motivo una qualsiasi
delle operazioni dovesse fallire, allora il motore transazionale dovrà
ristabilire la situazione originaria prima che la prima operazione della
transazione sia stata eseguita. Nel caso di transazioni sui database, questo
significa che ai dati dovranno essere rassegnati i valori iniziali precedenti
allinizio della transazione.
Se
invece al contrario tutte le operazioni sono state eseguite con successo,
allora le modifiche sui dati nel database potranno essere effettuate realmente.
La
Consistenza
dei dati è invece un obiettivo che si ottiene grazie al lavoro congiunto
del sistema transazionale e dello sviluppatore: nel primo caso si ottiene
questo sia grazie allutilizzo di atomicità ed isolamento
sia tramite i controlli sulle relazioni fra le tabelle del database inseriti
nel database engine; lo sviluppatore invece dovrà progettare
le varie operazioni di business logic in modo da garantire la consistenza
ovvero lintegrità referenziale, correttezza delle chiavi primarie,
e così via.
LIsolamento
garantisce che la transazione verrà eseguita dallinizio alla fine
senza linterferenza di elementi esterni o di altri soggetti.
La
Durabilità
infine deve garantire che le modifiche temporanee ai dati debbano essere
effettuate in modo persistente in modo da evitare che un eventuale crash
del sistema possa portare alla perdita di tutte le operazioni intermedie.
Lo Scope transazionale
Il
concetto di scope transazionale è di fondamentale importanza nel
mondo EJB, ed indica linsieme di quei bean che prendono parte ad una determinata
transazione. Il termine scope viene utilizzato proprio per dar risalto
al concetto di spazio di esecuzione: infatti ogni volta che un bean facente
parte di un determinato scope invoca i metodi di un altro o ne ricava un
qualche riferimento causa linclusione di questultimo nello stesso
scope a cui appartiene lui stesso.
In
tal modo quando il primo bean transazionale prende vita, lo scope verrà
propagato a macchia dolio a tutti i bean interessati dalla esecuzione.
Anche
se può essere piuttosto semplice seguire la propagazione dello scope
monitorando il thread di esecuzione di un bean, in realtà,
come si avrà modo di vedere più in dettaglio in seguito,
la propagazione dello scope si interseca con la politica definita in fase
di deploy per ogni singolo bean, dando così vita ad uno scenario
piuttosto complesso.
La
gestione della transazionalità di un bean e quindi la modalità
con cui esso potrà prendere parte ad un determinato scope (sia attivamente
che perché invocato da altri bean) può essere gestita in
modo automatico dal container in base ai valore dei vari parametri transazionali,
oppure manualmente nel caso in cui si faccia esplicitamente uso di un sistema
sottostante come Java Transction Api (JTA). Normalmente, a meno di particolari
esigenze, non è necessario gestire direttamente le transazioni,
ma ci si affida al container di EJB: la capacità di poter specificare
come i vari componenti possono prendere parte alle varie transazioni in
atto è una delle caratteristiche più importanti del modello
EJB, fin dalla specifica 1.0.

Tabella
1: gli attributi transazionali in EJB 1.0 ed 1.1
Nel
caso in cui ci si voglia affidare al motore transazionali fornito dal container
EJB, si può facilmente definire il comportamento di un determinato
bean facendo uso degli attributi transazionali elencati nella tabella 1.
Il
valore di tali attributi è cambiato dalla versione 1.0 alla 1.1:
se prima infatti si faceva riferimento a costanti contenute nella classe
ControlDescriptor, nella 1.1 si è passati a più comode stringhe
di testo, scelta sicuramente che permette di utilizzare file XML per la
configurazione manuale del bean.
Tramite
gli attributi riportati nella tabella 1 è possibile definire il
comportamento sia per tutto il bean che per ogni singolo metodo, cosa questultima
che sebbene sia più complessa ed a rischio di errori, offre
sicuramente maggior controllo e potenza.
In
EJB 1.0 per poter impostare uno dei possibili valori transazionali è
necessario scrivere del codice Java apposito seguendo la stessa tecnica
vista in precedenza: ad esempio per prima cosa è necessario definire
un ControlDescriptor impostando opportunamente lattributo transazionale
ControlDescriptor
cd= new ControlDescriptor();
cd.setMethod(null);
cd.setTransactionAttribute(ControlDescriptor.
TX_ NOT_SUPPORTED);
ControlDescriptor
[]cds= {cd};
SessionDes.setControlDescriptors(cds);
dove
SessionDes è un SessionDescriptor del bean, da utilizzarsi come
si è visto in precedenza. In questo caso con cd.setMethod(null)
si imposta lattributo transazionale per tutto il bean (valore null), mentre
se si fosse desiderato impostare tale valore solo per un metodo si sarebbe
dovuto tramite la reflection, individuare il metodo esatto e passarlo come
parametro. Ad esempio
Class
[]parameters= new Class[0];
Method
method=MyBean.class.getDeclaredMethod(getName,parameters);
cd.setMethod(method);
e poi
procedere come in precedenza.
In
EJB 1.1 invece le cose sono sicuramente più semplici, infatti tramite
un file XML è possibile ottenere lo stesso risultato. Ad esempio,
riconsiderando lesempio visto in precedenza, tramite il seguente codice
XML
<container-transaction>
<method>
<ejb-name>BMPMokaUser</ejb-name>
<method-name>*</method-name>
</method>
<trans-attribute>Required</trans-attribute>
</container-transaction>
definiamo
che tutti i metodi del bean BMPMokaUser avranno lattributo Required.
Significato dei
valori transazionali
Si
vedranno adesso i vari valori transazionali utilizzando per semplicità
il loro nome in italiano, intendendo sia le costanti di EJB 1.0 che le
stringhe di testo della versione 1.1.
NOTA
volte si usa dire che una determinata transazione client è
sospesa, ad indicare che la transazione del client non è propagata
al metodo del bean invocato, e la transazione è temporaneamente
sospesa fino a che il metodo invocato non termina. Si ricordi che come
detto altrove per client si intende una applicazione stand alone o anche
semplicemente un altro bean.
Not
Supported
Invocando
allinterno di una transazione un metodo di un bean settato con questo
valore, si otterrà una interruzione della transazione; lo
scope della transazione non verrà propagato al bean o ad altri da
lui invocati. Appena il metodo invocato termina, la transazione riprenderà
la sua esecuzione.
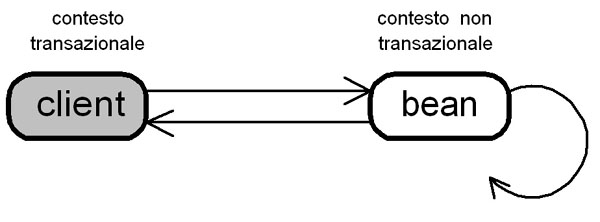
Figura
1: il funzionamento dellattributo transazionale not supported. In
questo caso
lo
scope della transazione non verrà propagato al bean o ad altri da
lui invocati
Supports
Nel
caso in cui il metodo di un bean sia impostato a questo valore, allora
la sua invocazione da parte di un client facente parte già
di un determinato scope, provocherà la propagazione dello scope
al metodo. Ovviamente non è necessario che il metodo sia necessariamente
invocato allinterno di uno scope, per cui potranno invocarlo anche client
non facenti parte di nessuna transazione.
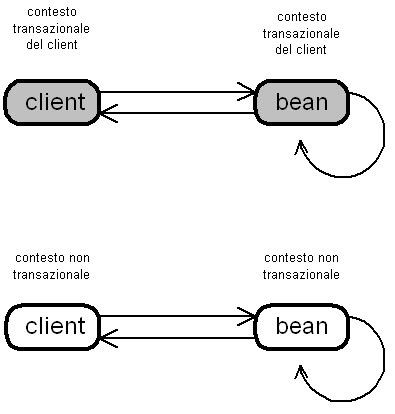
Figura
2 Confgurazione Supports: in questo caso il bean
è
in grado di entrare nello scope transazionale del client, anche
se
può essere invocato al di fuori di uno scope.
Required
In
questo caso si ha la necessità della presenza di uno scope
per linvocazione del metodo. Nel caso in cui il client sia parte di una
transazione, allora lo scope verrà propagato, altrimenti uno nuovo
verrà creato appositamente per il metodo del bean (scope che verrà
terminato al termine del metodo).
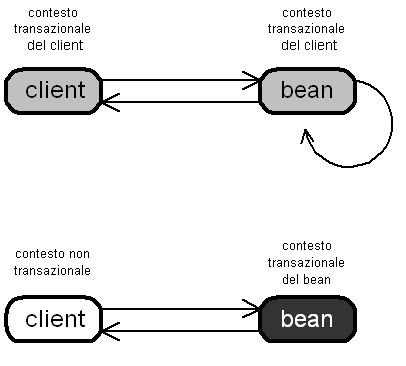
Figura
3 Confgurazione Required: un bean di questo tipo deve
essere
eseguito obbligatoriamente allinterno di uno scope: se il client
opera
in uno scope, il bean entrerà a far parte di quello del client oppure
altrimenti
un nuovo scope verrà creato appositamente per il bean
Requires
New
In
questo caso il bean invocato da vita necessariamente ad una nuova transazione,
indipendentemente dal fatto che il client faccia parte o meno di
una transazione. Nel caso in cui il client sia parte di una transazione,
questultima verrà interrotta fino al completamento della transazione
del bean invocato. Il nuovo scope creato per il bean verrà propagato
esclusivamente a tutti i bean invocati dal bean di partenza.
Quando
il bean invocato terminerà la sua esecuzione, il controllo ritornerà
alla client che riprenderà la sua transazione.
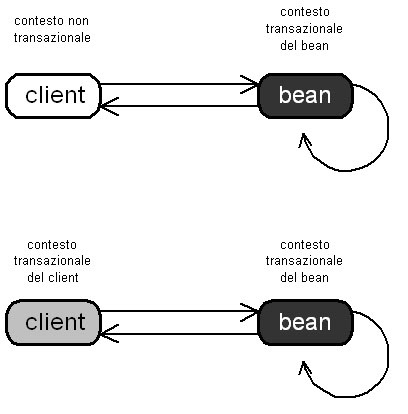
Figura
4 Confgurazione Requires New: in questa configurazione
il
bean creerà sempre un suo nuovo scope
Mandatory
Questo
valore serve per specificare che il bean deve sempre essere parte di una
transazione; nel caso in cui il client invocante non appartenga a nessuno
scope transazionale, il metodo del bean genererà una eccezione TransactionRequiredException.
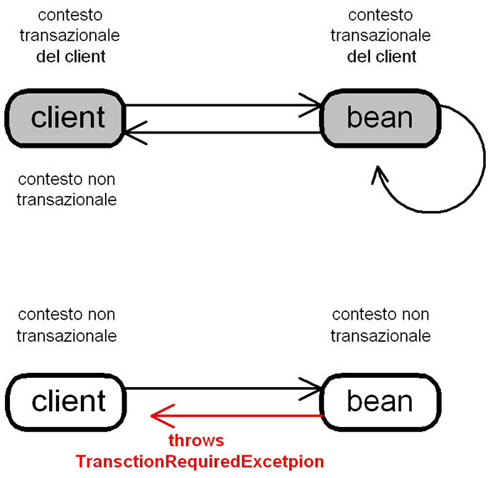
Figura
5 Confgurazione Mandatory: è una situazione simile alla
required,
anche
se in questo caso la mancanza di uno scope preesistente nel client
provoca
la generazione di una eccezione da parte del bean, e non la
creazione
di uno scope apposito
Never
(solo in EJB 1.1)
In
questo caso il client invocante non può appartenere a nessun scope
transazionale, altrimenti il bean invocato genererà una RemoteException.
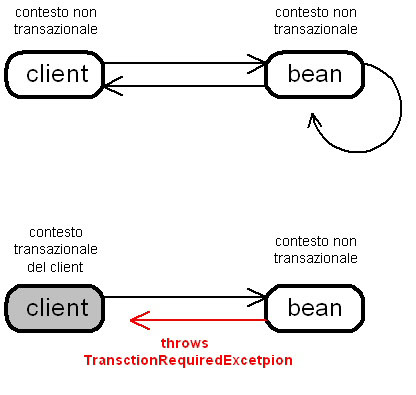
Figura
6 Confgurazione Never:lesatto contrario del caso precedente.
In
questo caso il bean non può assolutamente appartenere ad uno
scope,
pena la generazione di una eccezione.
Bean
Managed (solo in EJB 1.0)
In
questo caso, possibile solo con la specifica 1.0, si indica che nessun
supporto per la transazione deve essere specificato, dato che la gestione
verrà effettuata manualmente (tramite ad esempio JTS) allinterno
dei metodi del bean.
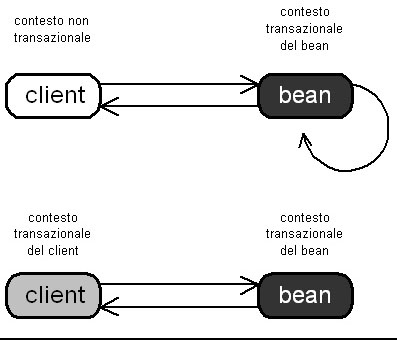
Figura
7 Confgurazione Bean Managed: il bean opererà sempre
in
un suo scope personale, gestito direttamente dal bean tramite
un
transaction engine come JTS.
I vari
attributi possono essere impostati in modo autonomo sui vari metodi del
bean, ad eccezione di questultimo caso, dove limpostazione a bean managed
per anche uno solo dei metodi obbliga necessariamente a fornire il
supporto manuale per tutti i metodi del bean.
Approfondimenti
sul database e integrità dei dati
Il
concetto forse più importante e più critico di un sistema
transazionale concorrente è quello relativo allisolamento
(lettera I del modello ACID), dato nasconde alcune importanti insidie.
Il
livello di isolamento di una transazione in genere è valutabile
in funzione della qualità con cui riesce a risolvere i seguenti
problemi:
-
Dirty
reads: si immagini il caso in cui due transazioni una in lettura ed una
in scrittura, debbano accedere ai medesimi dati. In questa situazione si
possono avere incoerenze dei dati, nel caso in cui la transazione in lettura
accedesse ai dati appena modificati da quella in scrittura, quando questultima
dovesse per un motivo qualsiasi effettuare un rollback riponendo i dati
nella configurazione originaria.
-
Repeteable
reads: questa condizione garantisce limmutabilità dei dati al succedersi
di differenti letture allinterno della stessa transazione. In genere questa
condizione è garantita o tramite un lock sui dati, oppure tramite
lutilizzo di copie dei dati in memoria su cui effettuare le modifiche.
In genere la prima soluzione è più sicura, anche se impatta
pesantemente sulle prestazioni. La seconda invece può complicare
molto la situazione, a causa delle difficoltà derivanti dalla necessità
di sincronizzare i dati copia con quelli originali. Una lettura non
ripetibile si ha quando una transazione dopo una prima lettura, vedrà
alla seguente le modifiche effettuate dalle altre transazioni.
-
Phantom
reads: letture di questo tipo possono verificarsi quando nuovi dati aggiunti
al database sono visibili anche allinterno di transazioni iniziate
prima dellaggiunta dei dati al database, transazioni che quindi si ritrovano
nuovi dati la cui presenza è apparentemente immotivata.
Ecco
alcune soluzioni comunemente utilizzate per prevenire i problemi di cui
sopra:
-
Read locks:
questo blocco impedisce ad altre transazioni di modificare i dati quando
una determinata transazione effettua una lettura dei dati. Questo previene
linsorgere di letture non ripetibili, dato che le altre transazioni possono
leggere i dati ma non modificarli o aggiungerne di nuovi. Se il lock venga
effettuato su un record, su tutta la tabella oppure su tutto database
dipende dalla implementazioni particolare del database.
-
Write
locks: in questo caso, utilizzato in operazioni di aggiormanto, le altre
transazioni sono impedite di effettuare modifiche ai dati; rappresenta
un livello di sicurezza ulteriore, anche se non impedisce linsorgere di
letture sporche dei dati (dirty reads) da parte di altre transazioni ed
anche di quella in corso.
-
Exclusive
locks: questo è il blocco più restrittivo ed impedisce ad
altre transazioni di effettuare letture o scritture sui dati bloccati:
le dirty e phantom reads quindi non possono verificarsi.
Alcuni
sistemi offrono un meccanismo alternativo ai lock, detto comunemente snapshot
di dati: in questo caso sono create delle vere e proprie istantanee dei
dati effettuate al momento dellinizio della transazione, istantanee che
permettono di lavorare in lettura e scrittura su una copia dei dati. Se
questo elimina del tutto il problema dellaccesso concorrente, introduce
problemi non banali relativamente alla sincronizzazione dei dati reali
con le varie snapshot.
Livelli di isolamento
delle transazioni
Per
qualificare la bontà di un sistema transazionale in genere si fa
riferimento ai cosiddetti livelli di isolamento.
Read
Uncommitted: una transazione può leggere tutti i dati uncommitted
(ovvero quelli ancora non resi persistenti) di altre transazioni
in atto. Corrisponde al livello di garanzia più basso dato che può
dar vita a dirty e phantom reads, cosi come possono verificarsi letture
non ripetibili.
Read
Committed: una transazione non può leggere i dati temporanei
(not committed) di altre transazioni in atto. Sono impedite le dirty reads,
ma possono verficarsi le letture fantasma e le non ripetibili. I metodi
di un bean con questo livello di isolamento non possono leggere dati affetti
da una transazione.
Repeteable
reads: una transazione non può modificare i dati letti da unaltra
transazione. Sono impedite le dirty reads e le letture fantasma ma
possono verficarsi le letture non ripetibili.
Serializable:
corrisponde al livello massimo di sicurezza, dato che una determinate transazione
ha lesclusivo diritto di accesso in lettura e scrittura sui dati.
Si ha la garanzia contro le le dirty reads, le letture fantasma e le non
ripetibili.
Questi
attributi sono gli stessi definiti come costanti in JDBC allinterno della
classe java.sql.Connection.
Gestione del livello
di isolamento in EJB
A
parte il caso della gestione diretta allinterno del bean delle transazioni,
la specifica 1.1 non prevede un sistema per limpostazione tramite attributi
del livello di isolamento come invece accadeva per la 1.0. In questo
caso lisolamento può essere scelto fra quattro livelli ed assegnato
ai vari metodi grazie come al solito ad un oggetto ControlDescriptor. Ecco
ad esempio una breve porzione di codice che mostra questa semplice operazione
ControlDescriptor
cd = new ControlDescriptor();
cd.setIsolationLevel(ControlDescriptor.TRANSACTION_SERIALIZABLE);
cd.setMethod(null);
ControlDescriptor
[]cds = {cd};
SessionDes.setControlDescriptors(cds);
In
questo caso si è scelto il livello TRANSACTION_SERIALIZABLE, mentre
nella tabella 2 sono riportati tutti i valori disponibili
Livello
di isolamento Costanti di ControloDescriptor
Read
committed TRANSACTION_READ_COMMITTED
Read
Uncommitted TRANSACTION_READ_UNCOMMITTED
Repeatable
reads TRANSACTION_REPEATABLE_READ
Serializable
TRANSACTION_SERIALIZABLE
In
EJB 1.0 è possibile impostare livelli di isolamento differenti per
ogni metodo, anche se poi in fase di runtime è necessario che allinterno
della medesima transazione siano invocati metodi con lo stesso livello
di isolamento.
Scelta del livello
di isolamento: il giusto compromesso
Visti
i molti problemi legati alla gestione concorrente dei dati, si potrebbe
pensare che la soluzione migliore possa essere ladozione sempre e comunque
di un livello di isolamento molto alto, al fine di assicurare in ogni istante
la correttezza dei dati e delle operazioni svolte su di essi.
Come
si è avuto modo già di accennare in precedenza questa non
sempre è la soluzione migliore, visto che è vera la regola
empirica che vede inversamente proporzionali il livello di isolamento e
le performance complessive del sistema.
Infatti,
oltre ad un maggiore numero di operazioni di controllo da effettuare, laccesso
esclusivo in lettura, scrittura o entrambi trasforma lo scenario da concorrente
a sequenziale.
Purtroppo
non esistono regole precise per poter scegliere in modo preciso e
semplice quale sia la soluzione migliore da adottare in ogni circostanza
e spesso ci si deve basare sullesperienza valutando in base al contesto
in cui si sta operando.
Ad
esempio se si è in presenza di un bean che potenzialmente
possa essere acceduto da molti client contemporaneamente (è il caso
di bean che rappresentano una entità centrale, come la banca nellesempio
delle transazioni monetarie visto in precedenza), allora non sarà
molto saggio utilizzare un livello alto di isolamento, dato che questo
metterà in coda tutte le chiamate di tutti i client.
E
altresì vero che, proprio per lelevato numero di client che accederanno
al bean comune, si dovrà fornire un livello di sicurezza molto alto,
dato che un piccolo errore si potrebbe ripercuotere su un numero elevato
di applicazioni client.
La
soluzione migliore potrebbe essere quella di separare i vari contesti e
di applicare differenti livelli di isolamento per i vari metodi. Ad esempio
tutti i metodi che dovranno essere invocati spesso per ottenere informazioni
dal bean, ovvero metodi che corrispondono ad operazioni di lettura, potranno
essere impostati con un livello molto basso di isolamento (sia perché
non si rende necessario altrimenti sia per favorire le prestazioni) come
ad esempio Read Uncommitted. I metodi del tipo setXXX potrebbero essere
invocati molto di rado (è probabile che la banca non cambierà
mai il suo nome), e quindi in questo caso deve essere fornito il
livello massimo di isolamento (in questo caso le prestazioni non sono un
problema dato lo scarso uso dei metodi, mentre la correttezza deve essere
massima).
Ovviamente
in tutti i casi intermedi è necessario pensare se sia il caso di
introdurre qualche funzionalità di business logic ad hoc per sopperire
ad un livello di sicurezza minore.
Conclusione
Abbiamo
affrontato con questo articolo il tema conclusivo relativamente alla piattaforma
EJB. Il prossimo mese concluderemo affrontando il caso della gestione manuale
delle transazioni.
Come
si è potuto vedere gli argomenti sono piuttosto delicati e generici.
Solo con luso e lesperienza se ne potranno comprendere a fondo i diversi
aspetti. Una volta di più, grazie alla trattazione delle transazioni,
si è potuto vedere come il modello EJB sia potente ci risparmi allo
sviluppatore di EJB maggior parte del lavoro sporco, demandandolo al container.
Parallelamente si evince in modo piuttosto lampante come sia importante
la fase di analisi a priori e ladozione di appropriate tecniche di design.
|



