Architettura
e semantica dello UML
Prima
di entrare nel dettaglio dellanalisi delle modifiche proposte con la versione
1.4 dello UML ritenute più interessanti, si ritiene opportuno illustrare
brevemente la definizione formale dello UML. La relativa padronanza è
utile per la comprensione degli argomenti riportati di seguito.
La
semantica del linguaggio è fornita per mezzo di una architettura
a strati (esattamente quattro, procedendo per livelli di astrazione crescente:
oggetti utente, modello, metamodello, e meta-metamodello come descritto
nel capitolo precedente) organizzata in packages, ognuno dei quali è
composto da:
-
Sintassi
astratta. Questa viene descritta per mezzo dello UML stesso, o meglio attraverso
i diagrammi delle classi. In altre parole si utilizza uno dei formalismi
appartenenti allo UML (i diagrammi delle classi appunto) per descrivere
il linguaggio stesso: listanza che definisce la classe! (Ciò rievoca
memorie risalenti al linguaggio C, ed in particolare al fatto che i compilatori
del linguaggio siano realizzati per mezzo del linguaggio stesso). Si tratta
di una soluzione molto raffinata ed elegante, che però può
originare qualche problema ad un pubblico con non molta esperienza inerente
al formalismo. In particolare i class diagram sono utilizzati per mostrare
il metamodello dello UML, i relativi concetti, le relazioni, e così
via;
-
Regole
ben formate (well-formedness rules). Si tratta delle regole e i vincoli
atti a definire modelli validi (riducono il contenuto semantico presente
nel modello). Sono espresse sia in linguaggio naturale (English of course)
sia in modo più formale per mezzo dellOCL (Object Constraint Language).
-
Semantica.
La semantica dellutilizzo del modello è espressa attraverso il
linguaggio naturale.
Lorganizzazione
in package del metamodello UML è riportata nella figura seguente:
Sebbene
i diversi package abbiano subito diverse modifiche interne (in alcuni casi
anche sostanziali) la struttura generale è rimasta la stessa.
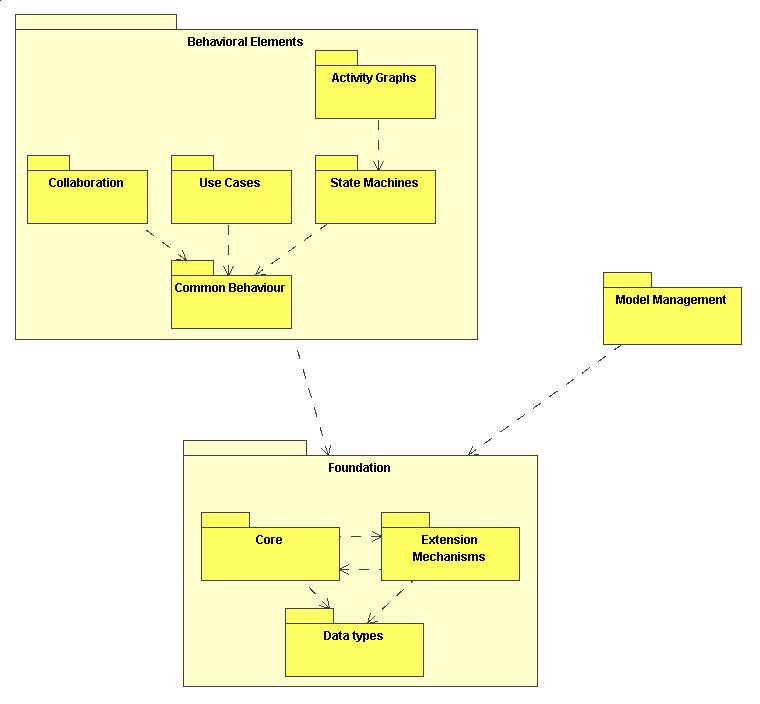
Figura
1. Organizzazione generale in package del metamodello UML
(clicca
per ingrandire)
Le
linee tratteggiate rappresentano istanze della relazione di dipendenza.
Molto semplicemente, indicano che un aggiornamento apportato ad un oggetto
indipendente (quello a cui punta la freccia) implica la revisione e verosimilmente
una modifica delloggetto dipendente.
I lettori
più attenti potrebbero interrogarsi sullassenza, nella diagramma
di figura 1, di riferimenti al formalismo dei diagrammi delle classi. In
effetti, si tratta di uno dei diagrammi di maggiore interesse dello UML.
La risposta è semplice. Poiché i class diagram sono utilizzati
per definire la sintassi astratta del metamodello, la relativa conoscenza
è un prerequisito. Una constatazione interessante è che nella
sezione inerente la guida alla notazione dello UML (istanza del metamodello)
i diagrammi delle classi vengono illustrati in dettaglio.
Larchitettura
presentata in figura 1 è esclusivamente logica, quindi non implementativa
o tantomeno fisica.
Manufatto (Artifact)
Uno
degli aggiornamenti più evidenti introdotti con la versione 1.4
dello UML è lelemento Artifcat (manufatto). Analizzando il package
Core, con particolare riferimento alla metaclasse Classifier(*) (classificatore),
è possibile constatare diversi elementi interessanti, ed in particolare
la nuova specializzazione denominata Artifact.
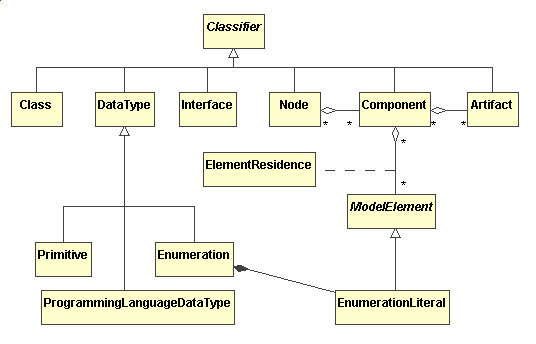
Figura
2. Package Core. Porzione del diagramma relativo allelemento Classifier
Si
ricordi che gli elementi dei modelli UML definiti dallutente sono istanze
di concetti definiti al livello di metamodello. Per esempio una particolare
classe (Ordine, LineaOrdine, Prodotto, Cliente, ecc.) è unistanza
del concetto classe definito nello UML (metaclasse Class). (In caso di
perplessità si consideri la figura 3 dellarticolo del mese precedente)
Si
noti che nel diagramma di figura volutamente non sono state dettagliate
ulteriori specializzazioni, al fine di non complicare ulteriormente le
cose.
NOTA:
Brevemente, il Classificatore e un elemento base dello UML atto a descrivere
caratteristiche comportamentali e strutturali di molti altri derivati,
quali per esempio: classe, interfaccia, use case, componente, nodo, ecc.
Esso
dichiara un elenco preciso di proprietà come Attributi, Metodi
e Operazioni ed è associato ad altri elementi per mezzo di specifiche
associazioni. Per esempio eredita dal NameSpace e GeneralizableElement.
La prima eredità gli permette di incorporare altri Classificatori
identificati per mezzo di un identificatore univoco. Essere un elemento
generalizzabile invece, consente, agli elementi sue istanze, di poter essere
associati tra loro per mezzo della relazione di generalizzazione (una classe
B eredita da una A).
Non
tutti gli elementi derivati dal Classificatore ne conservano intereamente
le caratteristiche, la relativa limitazione semantica è ottenuta
per mezzo di vincoli semantici, tipicamente definiti attraverso lOCL.
Per esempio uninterfaccia essendo un particolare Classificatore dovrebbe,
teoricamente, essere in grado di disporre sia di operazioni, sia attributi.
Ciò invece è vietato da un apposito vincolo che sancisce
che uninterfaccia può contenere unicamente operazioni.
Un
manufatto rappresenta una specifica porzione fisica di informazioni utilizzata
o prodotta dal processo di sviluppo del software. Alcuni esempi sono costituiti
dai modelli stessi (use case, class diagram, ecc.), file sorgenti, script,
file eseguibili ecc. Pertanto il relativo significato è molto simile
a quello cui, intuitivamente, si è portati a pensare.
Dallanalisi
del diagramma di figura 2 è possibile evidenziare che un manufatto
è una specializzazione di un Classifier eventualmente aggregato
ad uno o più componenti (Components).
Poiché
gli Artifact sono particolari Classificatori, ne seguono molte interessanti
proprietà. Per esempio il poter disporre di attributi e operazioni.
Questultimo periodo, verosimilmente potrebbe creare qualche perplessità
Che
senso potrebbe avere assegnare ad un manufatto attributi ed operazioni!?
Si
consideri un modello di casi duso, per esempio quello a livello di business.
Ebbene potrebbe risultare utile disporre di attributi quali il nome, la
descrizione, eventuale modificabilità dello stesso e così
via. Sul fronte delle operazioni potrebbe aver senso indicare quelle di
checkIn, checkOut, ecc.
Poiché
il Classificatore eredita anche da NameSpace, ne segue che un Artifact
può essere costituito (o se si preferisce può incorporare),
praticamente, tutti gli elementi dello UML.
Programming
Language Data Type (tipo di dato del linguaggio di programmazione).
Proseguendo
nellesame del package core con particolare riferimento gli elementi che
estendono il Classificatore (figura 2), è possibile scorgere un
altro figlio novello, (o meglio nipote in quanto specializzazione dellelemento
DataType) il
ProgrammingLanguageDataType
Si
tratta di tipi di dato definiti in conformità a specifici linguaggi
di programmazione, utilizzandone i relativi costrutti. In taluni casi potrebbe
risultare utile disporre di tipi di dato specifici, sebbene la maggior
parte di essi dovrebbero poter essere rappresentati direttamente utilizzando
altri Classificatori dello UML.
Questo
elemento - completamente in linea con la filosofia dello UML - appartiene
alla categoria di quelli che permettono di contenere la complessità
del linguaggio renderlo al tempo stesso flessibile. Da un lato esistono
i tipi di dato generali dello UML (DataType) indipendenti dai linguaggi
di programmazione, dallaltro sono presenti una serie di strumenti che
permettono di definire tipi di dato specifici dei linguaggi di programmazione.
Chiaramente
la peculiare specificità di un tipo di dato ne limita la portabilità.
I
tipi di dati specifici dei linguaggi di programmazione sono rappresentati
dal nome del linguaggio e da una stringa che li caratterizza, la cui interpretazione
è demandata al linguaggio di appartenenza.
Diagrammi dei
Componenti
Unarea
in cui, secondo diversi tecnici, lo UML risulta sensibilmente carente è
quella dei componenti. Già con la versione 1.4 dello UML diverso
lavoro è stato realizzato, ma verosimilmente, è necessario
proseguire nel lavoro di studio di soluzioni atte a facilitare lo studio,
rappresentazione, documentazione, ecc. di sistemi component-based.
Il
risultato che molti tecnici si aspettano è assistere (magari con
la versione 2) alla transizione dello UML da linguaggio di modellazione
object oriented a linguaggio di modellazione component-based.
Nella
figura seguente è riportato un esempio di componet diagram.
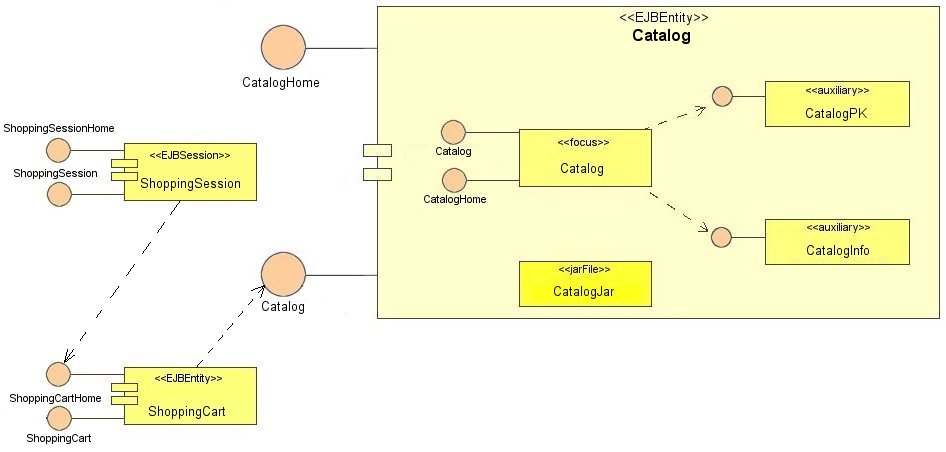
Figura
3 Esempio di diagramma dei componenti (clicca per ingrandire)
Brevemente,
il diagramma mostra tre componenti: ShoppingSession, ShoppingCart e Catalog.
Verosimilmente, compito del primo componente è fornire una serie
di servizi quali per esempio linserimento di specifici articoli nel carrello
della spesa.
Dallanalisi
della figura è possbile evidenziare una serie di elementi introdotti
con la nuova versione, particolarmente utili per la progettazione e descrizione
della struttura di sistemi component-based.
In
particolare gli stereotipi (in questo contesto si tratta di classi con
particolare significato semantico) «focus» e «auxiliary»
(da utilizzarsi in coppia come i carabinieri) permettono di distinguere
classi core (fondamentali o centrali per il flusso di controllo) da altre
di secondaria importanza (sempre dal punto di vista logico).
Nel
diagramma di figura, viene conferito particolare risalto alla struttura
del componente Catalog, costituito dalle classi CatalogInfo, CatalogPK
(dove PK vuole essere lacronimo di Primary Key, Chiave Primaria).
Come
si può notare gli stereotipi «focus» e «auxiliary»
risultano particolarmente utili per cominciare a progettare e descrivere
componenti già nelle fasi di analisi e disegno attraverso i diagrammi
delle classi.
Infine
lo stereotipo «jarFile» permette di distinguere componenti
eseguibili (EJB entity bean, EJB session bean, COM object) da gli manufatti
che li implementano (Jar file, DLLs ).
Visibilità
Sul
fronte della visibilità è stata aggiunta (meglio tardi che
mai) quella a livello di package.
La
definizione formale della visibilità degli elementi dello UML è
definita per mezzo dellelemento VisibilityKind (tipo di visibilità).
Si tratta di un enumeration appartenente al package dei tipi di dato (Data
Type).
Al
fine di garantire ad un elemento del linguaggio (attributo, metodo, ecc.)
la possibilità di dichiarare la propria visibiltà, è
necessario che il relativo concetto al livello di metamodello preveda un
apposito attributo (denominato con grande sforzo di fantasia visibility)
di tipo Visibilitykind.
Per
esempio la metaclasse astratta Feature (che prevede come specializzazioni
indirette elementi come Attributo, Operazione e Metodo) appartenente al
package Core, al fine di assicurare alle propre subclassi la possibilità
di dichiarare la relativa visibilità, possiede proprio lattributo
visibility: Visibilitykind.
I
valori previsti da Visibilitykind sono: public (+), protected (#), private
(-) e package (~).
Per
quanto concerne i primi tre cè poco da dire, mentre lultimo sancisce
che gli elementi con visibilità package siano fruibili (nei modi
previsti dalla loro entità: attributi, metodi, operazioni, associazioni,
ecc.) da tutti gli elementi appartenenti allo stesso package o in un qualsiasi
altro ad esso annidato a qualsiasi livello di profondità.
TagDefinition
I
tagged value sono un esempio di meccanismi di estensione previsti dallo
UML. In particolare permettono di estendere le proprietà degli elementi
aggiungendo informazioni supplementari.
Molto
semplicemente, si tratta di elementi costituiti dalla coppia (nome, valore).
Linterpretazione
della semantica dei valori etichettati esula (volutamente) dagli obiettivi
dello UML. Si tratta di convenzioni interamente demandate al tool e/o dellutente.
Non a caso vengono definiti meta attributi virtuali.
Per
esempio un tool di disegno potrebbe utilizzare opportuni tag value per
definire in quale linguaggio effettuare la generazione del codice.
Un
esempio di tagged value potrebbe essere costituito dalla coppia: (persistence,
booleano) da associare alle classi. In particolare un valore etichettato
{persistence=true} (da notare che in casi di valore booleano true è
sufficiente specificare unicamente letichetta {persistence }) sancirebbe
che le istanze della classe debbano essere memorizzate persistentemente
dal sistema.
Un
altro esempio di utilizzo di tagged value connesso a quello precedente,
potrebbe essere relativo alla possibilità di specificare il nome
della tabella in cui memorizzare le istanze di una classe persistente,
in questo caso si avrebbe: {persistence=Ordini}
Con
la versione 1.4 dello UML i tagged value diventano tipizzati, il che equivale
a dire che vengono vincolati i valori che possono assumere le relative
istanze come mostrato nel caso dello stereotipo Persistent. Sempre nella
versione 1.4 è presente una nuova metaclasse nel package Extension
Mechanisms del metamodello dello UML denominata tagDefinition. Questa specifica
linsieme di tagged value che possono essere associati ad un elemento.
Si tratta di un espediente tecnico atto ad invogliare i progettisti ad
associare insiemi di valori etichettati ad opportuni stereotipi. In altre
parole, qualora sia necessario definire dei tagged value dovrebbe essere
obbligatorio definire anche un opportuno strereotipo che li raggruppi.
Il congiuntivo è dovuto al fatto che, per questioni di compatibilità
con le versioni precedenti dello UML, è ancora possibile definire
tagged value non associati ad alcun stereotipo.
Profili
Un
altro esempio di meccanismo di estensione previsto dallo UML è costituito
dai profili che con la versione 1.4 sono entrati a far parte integrante
del linguaggio. In particolare ne sono stati formalizzati due: il profilo
per il software development processes (processi di sviluppo del software)
e quello per il business modeling (modellazione dellarea business) i cui
dettagli verranno illustrati nellarticolo del prossimo mese.
In
particolare un profilo è uno stereotipo di un package contenente
un insieme di elementi del modello opportunamente adattati ad uno specifico
dominio o scopo.
Quindi
a partire dal nucleo base, utilizzando opportunamente i meccanismi di estensione
dello UML è possibile definire tutta una serie di plug-in contenenti
elementi aggiuntivi (ottenuti specializzando opportunamente quelli basi)
utili per scopi ben definiti. Per esempio dovendo realizzare sistemi sfruttanti
architetture ricorrenti quali per esempio EJB, CORBA, +COM, è decisamente
utile disporre di relative librerie di elementi definiti ad hoc per tali
architetture. Ciò offre tutta una serie di vantaggi come: la possibilità
di disporre (senza ulteriori necessità di investigazione) di elementi
predefiniti e ben collaudati, plug-in standard e quindi comprensibili a
tutti i tecnici a conoscenza dello UML, ecc.
Conclusioni
Scopo
del presente articolo è stato quello di illustrare gli aggiornamenti
ritenuti più significativi tra quelli proposti con la versione 1.4
dello UML. In particolare si è colta loccasione sia per illustrare
rapidissimamente larchitettura del linguaggio sia, ogni qual volta si
è presentata lopportunità, per presentare specifici elementi
appartenenti al metamodello dello UML.
Tra
gli aggiornamenti proposti, vi è lelemento Artifcat, specializzazione
dellelemento base Classifier. Esso rappresenta una specifica porzione
fisica di informazioni utilizzata o prodotta dal processo di sviluppo del
software. Alcuni esempi sono costituiti dai modelli stessi (use case, class
diagram, ecc.), file sorgenti, script, file eseguibili ecc.
Un
altro elemento introdotto con la versione 1.4 è il ProgrammingLanguageDataType.
Si
tratta di tipi di dato definiti in conformità a specifici linguaggi
di programmazione, utilizzandone i relativi costrutti.
Unarea
in cui lo UML non sembrerebbe ancora brillare particolarmente è
quella relativa ai sistemi component-based. Ciò è del tutto
giustificato considerando che verosimilmente la tecnologia stessa si trova
allinizio della relativa curva di apprendimento. Il dato confortante è
che tale lacuna è ben nota alla nuova Revision Task Force e, dalle
varie dichiarazioni di intenti, emerge una chiara volontà affrontare
e risolvere i problemi legati allutilizzo dello UML nellarea di sistemi
basati sui componenti.
Con
la versione 1.4 sono stati comunque introdotti due stereotipi particolarmente
utili: «focus» e «auxiliary». Essi permettono di
distinguere classi core (fondamentali o centrali per il flusso di controllo)
da altre di secondaria importanza (sempre dal punto di vista logico).
Inoltre
lo stereotipo «jarFile» permette di distinguere componenti
eseguibili (EJB entity bean, EJB session bean, COM object) da gli manufatti
che li implementano (Jar file, DLLs ).
Altri
aggiornamenti degni di nota sono lintroduzione della visibilità
al livello di package e lelemento Tagdefinition che consente di raggruppare
insiemi di tagged value da utilizzarsi per definire nuovi stereotipi.
Infine
sono stati presentati brevissimamente i profili che, con la versione 1.4,
entrano a far parte integrante del linguaggio. In particolare sono stati
standardizzati quello relativo al software development processes (processi
di sviluppo del software) e quello per il business modeling (modellazione
dellarea business), i cui dettagli verranno presentati nellarticolo del
prossimo numero.
Come
si buon ben vedere lo UML è una tecnologia molto viva continuamente
in evoluzione al fine di far fronte ai sempre nuovi stimoli provenienti
dal mondo della pratica. Lobiettivo che molti i tecnici si attendono è
quello di vederlo evolvere da linguaggio di modellazione object oriented
a linguaggio di modellazione component based.
Luca
Vetti Tagliati è uno studioso e appassionato del linguaggio
UML. Ha scritto diversi articoli pubblicati sulla rivista virtuale www.Mokabyte.it.
Attualmente sta terminando di redigere il libro UML dalla teoria alla
pratica presto disponibile sempre nel sito di Mokabyte.
Negli
ultimi anni ha applicato la progettazione/programmazione component based
in settori che variano dal mondo delle smart cards (www.datacard.com) a
quello del trading bancario (www.hsbc.com). Lavora come consulente presso
la banca londinese HSBC con funzioni di technical architect e team leader.
È membro del gruppo di processing engineering (a cui partecipano
personaggi del calibro di Frank Armour coautore del libro Advanced Use
Case Modeling e John Daniles coautore del libro UML components). Si
tratta di un gruppo ristretto di dieci tecnici istituito per stabilire
ed attuare, una versione del RUP da utilizzarsi come standard interno della
banca da applicarsi nello sviluppo di sistemi software.
E
rintracciabile, presso lindirizzo lvetti@mokabyte.it. |



