Obiettivi
UDDI
(Universal Description. Discovery and Integration) è uniniziativa
nata per creare un registro mondiale di società e servizi. Per servizi
non si intendono solo Web Services (quindi SOAP e WSDL) ma anche attività
diverse quali il Web design, il trasporto o lo sviluppo di software su
commessa. Il raggio di azione di UDDI è quindi molto ampio e quindi
non rivolto solo ai Web Services.
UDDI
è gestito dal consorzio UDDI (http://www.uddi.org) che annovera
tra i suoi membri, tra laltro, IBM, Microsoft, Ariba ed anche SUN Microsystems
(che però sponsorizza anche laltro gruppo di lavoro con obiettivi
simili, lebXML). Lo scopo di questo consorzio di aziende è quello
di sviluppare un framework aperto ed indipendente dalla piattaforma per
descrivere servizi, individuare società e integrare servizi di business
utilizzando Internet. La tecnologia UDDI è quindi proprietaria
di questo consorzio, ed anche se si basa su tecnologie aperte definite
dal W3C (come XML, HTTP e DNS), è una tecnologia attualmente non
propriamente aperta.
UDDI
si posiziona dunque in un contesto meno tecnico ma più orientato
alle problematiche commerciali delle società, anche se fornisce
gli strumenti per catalogare servizi basati su SOAP e WSDL. Lo stack tecnologico
diviene dunque quello presente in fiigura 1.
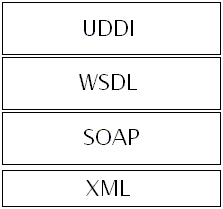
Figura
1 Stack di tecnologie dei Web Services
Lobiettivo
finale di UDDI è quello di integrare le competenze delle varie società
di diversi settori e centralizzando queste informazioni in un registro
condiviso tra più partner accessibile dal Web.
Il
funzionamento di UDDI si può riassumere in cinque passaggi:
-
Le società
di software, le organizzazioni per gli standard ed i programmatori popolano
il registro con le descrizioni dei differenti tipi di servizi (in questo
caso Web Services);
-
Le società
che erogano servizi popolano il registro con le descrizioni dei servizi
che propongono, facendo riferimento ai tipi di servizio precedentemente
catalogati;
-
Il registry
assegna un indicativo univoco per ogni tipo di servizio e per ogni società
registrata;
-
I motori
di ricerca, le applicazioni e simili interrogano il registro per scoprire
i servizi delle società erogatrici;
-
Le società
fruitrici utilizzano queste informazioni per facilitare lintegrazione
tra tutte le società tramite il Web.
Questo
processo è riassunto in figura 2.
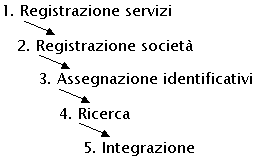
Figura
2 - Funzionamento UDDI
Un
esempio di funzionamento di UDDI può essere il seguente:
-
La società
Harbour Metals crea un sito online con un fornitore di applicazioni locale;
-
Il fornitore
registra la Harbour Metals presso il registro UDDI;
-
I motori
di ricerca interrogano il registro, salvano le informazioni e si collegano
ai servizi di Harbour;
-
I clienti
finali oppure altre società ottengono le informazioni dai motori
di ricerca ed entrano in affari con la Harbour Metals.
In questo
modo anche società piccole di importanza locale hanno modo di farsi
conoscere su tutto il pianeta.
Implementazione
I
tre elementi principali del framework UDDI si possono riassumere nei seguenti
punti:
-
descrizione.
La descrizione non si riferisce semplicemente alla definizione del servizio
web, che ben può essere implementata da un documento WSDL, ma piuttosto
a descrizione legate alle società erogatrici di Web Services, alla
categorizzazione del servizio (in modo simile alle categorie di Yahoo!,
ad esempio) ed alle informazioni tecniche del servizio. Queste ultime contengono
informazioni di semantica e non di sintassi, come nel caso dei WSDL;
-
individuazione.
Il framework di UDDI supporta la pubblicazione, lindividuazione ed il
collegamento a servizi web. Queste caratteristiche sono implementate tramite
un registry UDDI (vedi sotto) e possiamo immaginarli come i registry di
RMI evoluti, anche se ricordano più i registry Jini. Lindividuazione
avviene a design-time;
-
integrazione.
Lintegrazione dei servizi web allinterno delle proprie applicazioni avviene
tramite lutilizzo di tModels. Questi sono metadati che definiscono la
semantica dei servizi (parte della descrizione vista sopra) ottenuti con
i servizi di identificazione.
Le informazioni
fornite dai servizi UDDI possono essere catalogate in tre gruppi, che riflettono
lorganizzazione vista sopra e con una nomenclatura che ricorda le più
concrete e consolidate rubriche telefoniche, come le pagine gialle (anche
se con un approccio allamericana).
UDDI
definisce:
-
Pagine
bianche. Contiene le informazioni relative al nome, indirizzo, numero telefonico
ed altre informazioni sui contatti di una determinata azienda erogatrice
di servizi Web. Queste informazioni vengono pubblicate sul registro tramite
loggetto businessEntity che conterrà anche le informazioni a proposito
dei servizi;
-
Pagine
gialle. Descrive la categorizzazione delle società e dei servizi
e permette di individuare un particolare servizio Web per la successiva
invocazione. Linformazione è contenuta in un oggetto businessService.
-
Pagine
verdi. Riporta informazioni tecniche a proposito dei Web Services forniti
da una particolare società. Consente lintegrazione con i servizi
esterni ed avviene tramite tModels e bindingTemplate. Alcune informazioni
fornite sono gli URL, le informazioni sui nomi e gli argomenti dei metodi
ed altre informazioni tecniche.
Registry UDDI
I
registry UDDI sono il cuore della tecnologia UDDI limplementazione reale
delle API definite dal consorzio. Se siete familiari con la tecnologia
CORBA, una parte di UDDI quella relativa alle yellow pages precisamente
ricorda da vicino i servizi Trader CORBA. Il servizio Trader è
una sorta di repository di tipi di servizio e consente, tramite la funzione
di Register di pubblicare un servizio, e tramite quella di Lookup la sua
ricerca.
Alcuni
dei concetti di UDDI non sono quindi nuovi, ma rielaborazioni del passato
(vedi CORBA e Jini), ricucinati in salsa Internet.
Larchitettura
di UDDI ha un approccio distribuito, in modo simile ai DNS di Internet,
in questo modo ogni nodo è sempre aggiornato, ogni giorno, con tutte
le informazioni del registro. Ad oggi nodi UDDI sono implementati da IBM,
Ariba, Microsoft ed UDDI.org.
Le
motivazioni che hanno portato alla creazione di un registro distribuito
non sono solo tecniche (il risultato è una ampia disponibilità
dellinfrastruttura), ma sono anche orientate a rafforzare la compatibilità
tra i diversi produttori dimostrando un certo grado di apertura lun con
laltro e per evitare di legare UDDI alla tecnologia specifica di un singolo
produttore.
È
chiaro come le informazioni relative alle società ed ai servizi
siano dati preziosi (un po come i dati personali che raccolgono i vari
siti web che erogano servizi) e prima o poi dovrà essere chiarito
chi gestirà questo vasto patrimonio informativo.
Su
Internet sono disponibili alcune implementazioni dei registry UDDI, in
particolare segnaliamo:
-
jUDDI
www.juddi.org; Una implementazione open source che però attualmente
è ancora in versione pre-alpha;
-
IBM UDDI4J
- http://oss.software.ibm.com/developerworks/opensource/uddi4j/. Una implementazione
Java di UDDI da parte di IBM, rilasciata come codice open source.
-
IBM Web
Services Toolkit (vedi [7]); oltre a contenere un registro UDDI descritto
sopra (UDDI4J), fornisce anche una implementazione di SOAP e WSDL più
altre particolarità, tra cui un plug-in per browser per abilitarli
alla navigazione del registro UDDI (una funzionalità simile verrà
integrata da Microsoft in una prossima versione di Internet Explorer);
Tramite
il toolkit IBM è possibile implementare un proprio registro UDDI,
privato, per sperimentare la tecnologia senza dover accedere a registri
esterni. Questo è importante soprattutto in fase di test [9], ma
anche per implementare Internal Enterprise Application Integration UDDI,
cioè registri interni allazienda che consentono di coordinare i
servizi erogati dai singoli dipartimenti per tutta la società. In
alternativa, è possibile utilizzare i registry di test disponibili
su http://www-3.ibm.com/services/uddi/.
API
Le
API di UDDI sono un po particolari. Non sono classiche API Java che possiamo
consultare con un browser nel classico formato Javadoc, sono piuttosto
delle strutture XML che definiscono richieste e risposte per ciascuna funzione.
La particolarità è che il dialogo è inserito allinterno
di messaggi SOAP 1.1 che sono sempre di tipo sincrono (viene inviata una
risposta per ogni richiesta).
Le
due API principali riguardano linterrogazione e la pubblicazione.
Linterrogazione
(inquiry) fornisce due tipi di chiamate:
-
per una
visione più ampia del registro, basata su più possibilità
di ricerca, si utilizzano le chiamate del tipo find_xx;
-
per una
chiamata più diretta, quando sia noto il contesto, si utilizzano
le chiamate get_xx.
Le API
per la pubblicazione consistono invece in:
-
quattro
chiamate del tipo save_xx;
-
quattro
chiamate del tipo delete_xx;
ciascuna
chiamata opera sulle quattro entità presenti nel modello informativo
di UDDI (Fig.2) businessEntity, businessService, bindingTemplate, tModel.
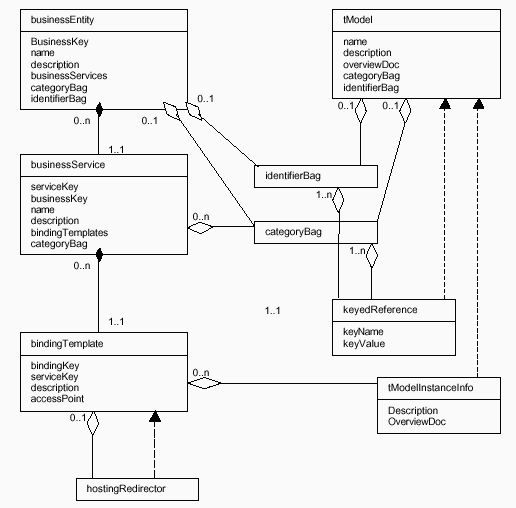
Figura
3 Modello informativo di UDDI
Linvocazione
avviene tramite le informazioni contenute nelloggetto bindingTemplate.
Conclusioni
La
cosa positiva di UDDI è che funziona ed è attualmente in
linea. Microsoft ed IBM forniscono online la possibilità di registrarsi
e di cercare servizi presso il registry, e basta provare per verificare
come (almeno la release 1.0) UDDI sia già in funzione.
Nonostante
ciò, prima di vedere una vasta diffusione di UDDI potrebbe passare
ancora qualche tempo. Per prima cosa, questo è uno standard proprietario,
creato si da un vasto consorzio di aziende, ma non ratificato da un organismo
indipendente, come ad esempio il W3C che proprio in questi tempi sta affrontando
il problema degli standard per i Web Services con il su gruppo di lavoro
XML Protocol. Anche se gli obiettivi che si propone di raggiungere UDDI
non sono attualmente negli obiettivi del gruppo di lavoro del W3C, pressioni
da parte di diverse società (quali IBM) potrebbero far estendere
il contesto del progetto in modo da includere UDDI. Questo sarebbe un forte
riconoscimento ed una spinta notevole alladozione della tecnologia, anche
se un organismo indipendente come il W3C non si esimerà di certo
dal prendere in considerazione tecnologie concorrenti (come ad esempio
ebXML) e produrre uno standard che prenda il meglio dai due mondi. Tra
laltro è previsto, proprio dal consorzio UDDI, il rilascio del
controllo della tecnologia ad un organismo indipendente dopo la versione
3.0 delle specifiche.
In
secondo luogo alcuni aspetti (come per il fatto che il collegamento ad
un servizio deve essere eseguito in fase di progettazione e non può
avvenire in fase di runtime) rendono la tecnologia forse un po limitata
e dunque poco appetibile ad una immediata adozione che potrà essere
rimandata ad una delle prossime release.
Riferimenti
[1]
Andrea Giovannini - SOAP e Java Integrazione di applicazioni con Java e
il nuovo protocollo SOAP - http://www.mokabyte.it/2001/01/soap.htm
[2]
Specifiche WSDL - http:/www.w3c.org/TR/wsdl
[3]
Massimiliano Bigatti Web services: SOAP e d'intorni - http://www.mokabyte.it/2001/05/webservices.htm
[4]
Massimiliano Bigatti Web services II parte: capire i WSDL - http://www.mokabyte.it/2001/06/webservices.htm
[5]
UDDI.org www.uddi.org
[6]
XML.com A Web Services primer http://www.xml.com/lpt/a/2001/04/04/webservices/index.html
[7]
IBM alphaWorks http://www.alphaworks.ibm.com
[8]
IBM UDDI - http://www-3.ibm.com/services/uddi/index.html
[9]
The role of private UDDI nodes in Web services, Part 1: Six species
of UDDI
IBM
developerWorks - http://www-106.ibm.com/developerworks/webservices/library/ws-rpu1.html?dwzone=webservices
[10]
UDDI Overview Presentation - http://www.uddi.org/pubs/UDDI_Overview_Presentation.ppt
|



