|
Introduzione
Nel corso dei precedenti articoli si é visto
come realizzare una applicazione ad interfaccia web
tramite il cosiddetto pattern MVC, separando i contesti
di presentation e di business logic. In particolare
si é cercato di porre particolare attenzione
alle potenzialità di questo modello volendo mettere
in luce come sia relativamente semplice scalare la complessità
della applicazione ad esempio sostituendo la logica
di esecuzione da dei semplici java beans ad uno strato
EJB.
Per poter considerare definitiva l'architettura vista
fin'ora manca un componente piuttosto fondamentale,
ovvero un qualche sistema per la gestione dei messaggi
di errore.
Scopo di questo articolo è quello di effettuare
prima una panoramica veloce e sintetica alla API log4j
presentandone funzionamento e filosofia di base, e successivamente
di elencare le principali problematiche circa la gestione
delle eccezioni in una applicazione distribuita basata
su EJB.
La gestione delle eccezioni in Java
Java mette a disposizione del programmatore una tecnica
molto potente per la gestione delle nomalie (eccezioni)
tramite i costrutti throw e try-catch. Spesso al programmatore
neofita viene detto di evitare il più possibile
di inserire blocchi try catch all'interno dei metodi
pubblici di una classe, ma piuttosto di reinnoltrare
le eccezioni fuori dal metodo. In questo modo non si
nasconde il problema all'interno di un metodo di una
classe X ma si comunica al livello delle classi client
il problema.
Ad esempio se un metodo readObject(), della classe PersistenceManager
di cui si parlerà più avanti, è
invocato da molte parti all'interno di una applicazione,
allora il metodo
public
Object readObject(){
try {
FileInputStream
fis;
fis
= new FileInputStream(Filename);
ObjectInputStream
ois = new ObjectInputStream(fis);
return
= ois.readObject();
}
catch
(IOException ioe) {
//
salva un log dell'eccezione su file
...
}
}
è preferibile scriverlo nel seguente modo
public
Object readObject() IOException{
FileInputStream
fis;
fis
= new FileInputStream(Filename);
ObjectInputStream
ois = new ObjectInputStream(fis);
return
= ois.readObject();
}
Questa
convenzione non sempre è indicata, specialmente
nel caso in cui vi sia uno strato EJB: una alternativa
valida infatti prevede di intrappolare le eccezioni
all'interno di un metodo tramite una try-catch, effettuarne
il log al suo interno e successivamente rilanciare l'eccezione
per poter comunicare all'esterno tale situazione (le
eccezioni in Java da questo punto di vista sono un ottimo
sistema di messaggistica). Utilizzando questa tecnica,
detta exception wrapping, se il metodo di prima fosse
un metodo remoto di un session bean potrebbe diventare
public
Object readObject(){
try
{
FileInputStream
fis;
fis
= new FileInputStream(this.dataFilename);
ObjectInputStream
ois = new ObjectInputStream(fis);
return
= ois.readObject();
}
catch
(FileNotFoundException fnfe) {
throw
new EJBException(fnfe);
}
In questo caso l'eccezione è stata incapsulata
in una EJBException che essendo una eccezione remota
potrà essere inoltrata senza problemi al client
invocante il metodo del bean.
Con il procedere nello studio il buon programmatore
Java scoprirà inoltre che scegliere se effettuare
un log oppure rilanciare l'eccezione o infine eseguire
entrambe le operazioni è un dilemma di non facile
soluzione. Spesso la soluzione dipende molto dal contesto
e dal tipo di applicazione. Per poter affrontare il
problema con la massima chiarezza, occorre analizzare
la questione analizzando un aspetto per volta: per prima
cosa vediamo di capire come gestire in modo adeguato
il log dei messaggi, ovvero come salvare da qualche
parte una descrizione il più esplicativa possibile
della eccezione.
La API log4j
Il semplice log dei messaggi su file o su console, ha
lo svantaggio di essere troppo rigido rispetto alle
normali esigenze di una applicazione reale e difatti
molto spesso ci si appoggia a framework esterni che
offrono funzionalità avanzate piuttosto potenti.
Sebbene nella nuova versione del J2SE 1.4 sono state
introdotte alcune classi per gestire queste funzionalità,
attualmente il tool più utilizzato è log4j
del gruppo Apache [log4j] ed è per questo motivo
che anche qui verrà utilizzato come sistema di
riferimento.
In ogni sistema di log l'elemento principale, elemento
su cui si basa tutto il framework, é il logger,
ovvero l'oggetto che invia i messaggi verso un determinata
destinazione. Per rendere il sistema più flessibile
in log4j, i logger sono affiancati da altri due oggetti:
gli appender ed i layout.
Un layout, come il nome lascia intuire, permette di
customizzare l'output prodotto dal logger, mentre un
appender rappresenta la destinazione verso la quale
i messaggi sono inviati (file, console, JMS, Syslog
demon in Unix o NT Eventi Logger). Questa organizzazione
consente in fase di stesura del codice, di limitare
l'attenzione all'inserimento nei punti "caldi"
del programma i logger, mentre l'associazione logger/appender/layout
viene di solito effettuata tramite file .properties.
I loggers e gerarchie di loggers
Un logger e' uno strumento che permette di inviare messaggi
verso una determinata destinazione. Istanza della classe
Logger (che dalla versione 1.2 della API sostituisce
la Category) sono strutturati gerarchicamente in modo
analogo ai package in Java dai quali prendono spunto
per la organizzazione dei nomi. Ad esempio un logger
di nome com.mokabyte sará il padre di com.mokabyte.mylogger,
e antenato di com.mokabyte.mylogger.speciallogger.
L'organizzazione gerarchica dei logger é molto
importate dato che è alla base di tutto il framework
permettendone flessibilità e maneggevolezza.
Al vertice della gerarchia dei logger si trova il RootLooger
che ha la caratteristica di esistere sempre e non può
essere ricavato per nome ma tramite il metodo statico
Logger.getRootLogger();
Ogni
altro logger invece deve essere ricavato tramite il
nome assegnatogli per mezzo del metodo di factory
Logger.getLogger(String
name);
Il
fatto di passare un nome di un logger al metodo, implicitamente
crea un logger con quel nome. Si tratta di un pattern
factory che restituisce un logger già pronto
all'uso senza doverne invocare il costruttore. Leggendo
nella documentazione si scopre inoltre che internamente
questo factory utilizza un singleton, per cui se in
vari punti della applicazione si invoca lo stesso logger
(stesso nome) si otterrà sempre la stessa istanza
di logger.
Quindi se si scrive
Logger
LogA = Logger.getLogger("pippo");
Logger LogB = Logger.getLogger("pippo");
allora
le due variabili LogA e LogB punteranno alla stessa
istanza di logger. Questa caratteristica è molto
comoda in quanto permette di poter ricavare in ogni
punto della applicazione un logger semplicemente utilizzandone
il nome e senza dover ogni volta passare da un punto
ad un altro tutti i parametri di inizializzazione.
Il fatto che ci sia un singleton da qualche parte ha
anche un altro importante riflesso: l'inizializzazione
tramite la lettura dei parametri di configurazione può
essere fatta una sola volta per tutta l'applicazione;
normalmente questo deve essere fatto all'interno della
classe principale (per una applicazione stand alone)
o del costruttore del bean principale (per una web application).
Di
seguito é riportata la definizione completa della
classe Logger
package
org.apache.log4j;
public class Logger {
// metodi di creazione e factory
public static Logger getRootLogger();
public static Logger getLogger(String name);
// metodi di stampa:
public void debug(Object message);
public void info(Object message);
public void warn(Object message);
public void error(Object message);
public void fatal(Object message);
// generico metodo di stampa
public void log(Level l, Object message);
}
L'invocazione
di uno dei metodi di stampa da luogo a quella che in
gergo si dice una request. Si possono quindi avere 5
livelli di request che corrispondono anche ai livelli
che si possono assegnare ad un determinato Logger. Dal
più basso al più alto questi livelli sono
DEBUG,
INFO, WARN, ERROR e FATAL
Quindi
scrivendo
Logger.info("ecco
un messaggio di avvertimento");
si
genera un request INFO, ovvero si invia il messaggio
contenuto tra virgolette verso gli appender registrati
come ascoltatori di questo logger.
Ad ogni logger viene assegnato un livello di importanza
e l'intersezione fra livello del logger con quello della
request da luogo al comportamento del logger stesso:
una request risulta essere attiva (ovvero alla sua invocazione
il messaggio viene effettivamente inviato) se il livello
della request é maggiore o uguale al livello
assegnato al logger. Quindi la request appena vista
verrà eseguita solo se il logger ha livello DEBUG
o INFO.
Anche se non si possono avere le stesse prestazione
del C++ che utilizza il meccanismo di preprocessamento
del codice (che però richiede la ricompilazione),
la documentazione ufficiale di log4j specifica che una
request disattivata non impatta sulle performance della
applicazione complessiva: il messaggio non solo non
verrà inviato, ma in base ad una efficiente ottimizzazione
del codice il metodo non verrà nemmeno eseguito.
Durante la fase di sviluppo e quindi di test della applicazione
si potrebbe cospargere il codice di tante debug request
per verificarne il funzionamento; tali request potranno
essere disabilitate in fase di test o produzione, quando
gli errori più grossolani si presume siano stati
individuati ed eliminati.
Da notare che l'organizzazione gerarchica dei logger
consente fra le altre cose di impostare i livelli dei
vari logger in modo gerarchico. Ad esempio se un logger
non ha nessun livello impostato, allora erediterà
tale informazione dal primo logger genitore per il quale
sia impostato un livello. Se nessun logger ha un livello
impostato, allora la gerarchia risale fino al rootLogger
il quale ha sempre un valore impostato, tipicamente
il valore di INFO.
Questa semplice regola viene sfruttata al meglio se
anche i nomi assegnati ai logger ricalcano la struttura
gerarchica delle classi e dei package coinvolti.
Ad esempio se nella classe MyClass si potrebbe scrivere
package
com.mokabyte.log4j;
public
class MyClass {
Logger
logger = Logger.getLogger(MyClass.getClass.getName());
…
}
ed
in questo caso il logger qui definito ad uso interno
avrà lo stesso nome della classe, ovvero com.mokabyte.log4j.MyClass.
In
modo molto semplice la struttura della applicazione
o della libreria da quindi luogo ad una struttura di
logger isomorfa.
La
scelta del quante, di che tipo e dove inserire le varie
request nel codice, é probabilmente una delle
cose più difficili da stabilire. Si tratta come
sempre di seguire il buon senso, di avvalersi dell'esperienza
e di trovare il giusto compromesso.
I layout
Sui layout non vi molto da dire, dato che il loro funzionamento
è piuttosto intuitivo. Di fatto si tratta di
oggetti che servono per definire la formattazione e
la forma del messaggio. Dato che nella maggior parte
dei casi una request è costituita da messaggio
testuale, un laout è generalmente una stringa
utilizzata da un parser per formattare il messaggio
finale; il tutto in modo simile a quanto accade nella
funzione printf del linguaggio C. Nel caso in cui si
utilizzino appender differenti da quello testuale (JMS,
o Syslog di Unix) ci sono delle piccole differenze di
cui tener conto e per le quali si rimanda alla documentazione
per maggiori approfondimenti.
Gli appenders
La relazione che lega un logger con un appender ricalca
il cosiddetto pattern sorgente ascoltatore. Ogni request
eseguita su un particolare logger, verrà inviata
a tutti gli appender che si sono registrati presso quel
logger.
Il framework mette a disposizione alcuni appender predefiniti
come la console, il file di testo, code di messaggi
JMS, oppure demoni Syslog di Unix così come il
logger di eventi di NT.
Eventualmente è possibile definire un proprio
appender, ad esempio reindirizzando i messaggi o verso
un database (vedi [jdbcapp] per un appender JDBC), o
come email verso un determinato indirizzo di posta elettronica.
Anche per gli appender l'organizzazione gerarchica dei
logger è utile: infatti un messaggio prodotto
da una determinata request verrà propagato, oltre
all'appender registrato su quel determinato logger,
anche verso tutti gli appender registrati sui logger
più in alto nella gerarchia. Questo comportamento,
detto appender additivity, può essere evitato
settando a false l'additivity flag. Anche in questo
caso in [manual] si possono trovare tutti gli approfondimenti
sia sul ruolo degli appender che sulle regole di additività.
La configurazione
Questa è probabilmente la parte più importante
di tutta la gestione del sistema log4j: questa procedura
vuol dire essenzialmente definire per ogni logger il
suo livello e oltre agli appender e layout ad esso associati.
La configurazione può essere fatta all'interno
del codice o tramite file di configurazione (nel formato
.properties). Per ovvi motivi è da preferirsi
la seconda soluzione che è anche quella che si
analizzerà in questa sede.
Di seguito è riportato un breve esempio di file
di configurazione tramite il quale si cercherà
di dare un'idea della struttura e della sintassi che
tale file deve avere. Ovviamente non si ha la pretesa
di analizzare ogni singolo caso ed elemento possibile,
ma di dare un'idea di massima su come utilizzare tale
file per i casi più frequenti.
Esso è organizzato in sezioni, a seconda della
parte che si vuole configurare. Per prima cosa si può
impostare il valore di soglia (livello di log) per tutta
l'applicazione tramite la riga
log4j.threshold=[level]
dove
al solito i valori di level al solito possono essere
OFF,
FATAL, ERROR, WARN, INFO, DEBUG, ALL.
Successivamente si passa a configurare uno o più
appender: la sintassi da seguire è la seguente
log4j.appender.MyAppender=fully.qualified.name.of.appender.class
che
specifica il nome della classe per un appender di nome
MyAppender: il nome dell'appender può contenere
punti separatori.
Successivamente si possono passare alcuni parametri
di configurazione per l'appender.
log4j.appender.appenderName.option1=value1
...
log4j.appender.appenderName.optionN=valueN
Nell'esempio
che si vedrà in seguito si definisce il seguente
appender
log4j.appender.MyConsole=org.apache.log4j.ConsoleAppender
che
definisce un appender di nome MyConsole rediretto sulla
console (classe ConsoleAppender ) dove verranno stampati
tutti i messaggi.
Il formato dell'output potrà essere gestito in
vari modi: in questo caso si sceglie di utilizzare un
pattern layout manager
log4j.appender.MyConsole.layout=org.apache.log4j.PatternLayout
specificandone
il formato tramite
log4j.appender.MyConsole.layout.ConversionPattern=%-4r
%-5p [%t] %37c %3x - %m%n
Se
si desiderasse configurare un appender su file, si potrebbe
utilizzare il seguente codice per il quale si è
preso spunto direttamente dalla documentazione ufficiale
#
definisce un appender di nome FA
# FA è RollingFileAppender con dimensione massima
del file di 10 MB
# Utilizza come layout il TTCCLayout, con le date in
formato ISO8061
log4j.appender.FA=org.apache.log4j.RollingFileAppender
log4j.appender.FA.MaxFileSize=10MB
log4j.appender.FA.MaxBackupIndex=1
log4j.appender.FA.layout=org.apache.log4j.TTCCLayout
log4j.appender.FA.layout.ContextPrinting=enabled
log4j.appender.FA.layout.DateFormat=ISO8601
A
questo punto si può procedere nella definizione
delle proprietà di configurazione dei logger,
sia specificando il comportamento del logger root, sia
specificando uno per uno ogni logger definito all'interno
della applicazione. Nel primo caso si potrebbe scrivere
ad esempio
log4j.rootLogger=[level],
appenderName, appenderName, ...
anche
in questo caso level può assumere uno dei valori
OFF,
FATAL, ERROR, WARN, INFO, DEBUG, ALL,
mentre i vari appenderName sono i nomi degli appender
da utilizzare.
Questa soluzione evita di dover configurare ogni singolo
logger della applicazione (che di fatto essendo figli
di root ne ereditano le caratteristiche), anche se non
è molto flessibile. Il programmatore dovrà
scegliere il giusto compromesso fra semplicità
e potenza.
Infine se si volesse configurare ogni singolo logger
si dovrà per ognuno inserire una riga simile
a quella vista per il rootLogger: ad esempio
log4j.logger.com.mokabyte.log4j.util.io.PersistenceManager=DEBUG,
MyConsole
log4j.logger.com.mokabyte.log4j.User=ERROR, MyConsole
log4j.logger.com.mokabyte.log4j.GuestUser=ERROR, MyConsole
log4j.logger.com.mokabyte.log4j.PowerUser=ERROR, MyConsole
log4j.logger.com.mokabyte.log4j.UserManager=ERROR, MyConsole
In questo caso, pur essendo l'applicazione molto semplice,
si è costretti a dover specificare molte informazioni;
se ci si dimentica di definire il comportamento di un
logger verrà generata un errore bloccante.
Per chi fosse interessato ad una completa analisi dei
parametri di configurazione si consiglia di leggere
la pagina di commento inserita direttamente nel JavaDoc
del log4j [log4jconf].
Coloro che invece preferissero una procedura più
veloce e semplice, si tenga conto che si può
procedere alla inizializzazione utilizzando la classe
BasicConfigurator che utilizza le impostazione di default
proprie del framework e che non sono modificabili.
Infine chi fosse interessato ad utilizzare il formato
XML configurazione, sappia che esiste un apposito configuratore
(DOMConfigurator) particolarmente utile all'interno
del codice di pagine JSP tramite apposita tag library
fornita di corredo (anche se ogni programmatore MVC-entusiast
non dovrebbe avere questo genere di necessità).
Un esempio
L'esempio che si andrà a vedere è molto
semplice e non comprende componenti J2EE, proprio per
cercare di dare un'idea il più chiara possibile
sul funzionamento di log4j indipendentemente dall'ambito
di utilizzo.
In questo caso la classe UserManager in modo molto semplice
e rudimentale gestisce alcuni semplici profili utente
(classe User) utilizzando i metodi della PersistenceManager
per memorizzare su file le informazioni di tre utenti.
Al fine di verificare il comportamento di log4j in presenza
di classi organizzate in modo gerarchico, la classe
User è stata derivata in due sottoclassi: la
classe PowerUser e GuestUser. La prima rappresenta un
ipotetico utente con la facoltà di poter eseguire
un maggior numero di operazioni: legge e scrive il suo
profilo su file ed inoltre lo può anche cancellare;
La GuestUser invece rappresenta un ospite al quale sono
assegnate potenzialità ridotte come ad esempio
leggere il suo profilo ma non salvarlo; in questo caso
l'invocazione al metodo saveData() genera una eccezione
che verrà controllata da log4j.
Di seguito sono riportate le varie classi dell'esempio,
con accanto il loro ruolo all'interno della politica
di gestione delle eccezioni in log4j.
La classe PersistenceManager svolge il compito di rudimentale
gestore della persistenza di oggetti: al suo interno
i metodi loadData() e saveData() sono monitorati tramite
una serie piuttosto fitta di request di tipo debug.
Invece sono state inserite solo due info request, all'inizio
ed alla fine sono inserite due request di tipo info,
ad alcune error nelle clausole catch.
Il motivo di questa scelta è da ricercarsi nel
fatto che all'interno di una catch cadranno tutti gli
errori non trovati durante il debug, mentre in fase
di sviluppo può accadere di voler controllare
ogni singolo step del programma (quindi è per
questo che sono state inserite molte debug request).
Ecco il codice completo del metodo readObject()
public
Object readObject()
throws
FileNotFoundException,
IOException,
ClassNotFoundException{
logger.info("Entering the method readObject");
Object ret = null;
try {
logger.debug("opening the
file "+dataFilename);
FileInputStream fis = new FileInputStream(this.dataFilename);
logger.debug(dataFilename +"
opened");
ObjectInputStream ois = new
ObjectInputStream(fis);
logger.debug("reading Object");
ret = ois.readObject();
logger.debug("done "+ret);
}
catch (FileNotFoundException fnfe) {
logger.error("FileNotFoundException
in the method readBytes()\n"+fnfe+"\n"+this.toString());
throw fnfe;
}
catch (IOException ioe) {
logger.debug("IOException
in the method readBytes()\n"+ioe+"\n"+this.toString());
throw ioe;
}
catch (ClassNotFoundException cnfe) {
logger.debug("ClassNotFoundException
in the method readBytes()\n"+cnfe+"\n"+this.toString());
throw cnfe;
}
logger.info("Exiting method readObject");
return ret;
}
Il
metodo writeObject() è analogo.
Ecco di seguito il metodo saveData() della classe PowerUser
//
un PowerUser non può salvare i suoi dati
public void saveData() throws Exception {
logger.error("The
operation saveData is not allowed
if
you are a \'Guest\'");
throw
new Exception("The operation saveData is not
allowed
if you are a \'Guest\'");
}
Il
fatto di poter disporre di una gerarchia di classi e
quindi di logger permette di sperimentare direttamente
il funzionamento di log4j: ad esempio se non si volesse
specificare le impostazioni di ogni logger, potrebbe
essere sufficiente definire il comportamento di quello
di User. Analogamente si potrebbe verificare il comportamento
della applicazione commentando le impostazioni dei logger
e commentando quella del RootLogger.
A
questo punto si dovrebbe avere piuttosto chiaro quale
sia il funzionamento e la filosofia di log4j (ed analogamente
di ogni altro sistema di log).
Appare evidente come non esista una regola unica per
la generazione di codice di log all'interno di una applicazione:
alcune regole empiriche possono essere in ogni caso
molto utili. Ad esempio un messaggio di tipo INFO dovrebbe
essere inserito all'inizio ed alla fine di ogni metodo.
Le request di tipo DEBUG invece dovrebbero essere inserite
in tutti i punti delicati per poter risalire in ogni
momento all'esatto flusso delle operazioni. Le ERROR
dovrebbero essere inserite nelle catch del programma
nei punti di gravità non massima, dove invece
si potranno inserire le FATAL. Un WARN infine dovrebbe
essere segnalato per tutte quelle situazioni non gravi
ma tali da suscitare l'attenzione del programmatore
per un probabile problema che si verifichi in seguito.
La gestione delle eccezioni in una applicazione reale
Se si esclude la fase di debug e di test del codice,
situazioni in cui ogni programmatore dovrebbe essere
in grado di cavarsela egregiamente, il test finale e
lo scenario di produzione sono sicuramente i momenti
dove l'insorgere di un problema deve essere assolutamente
segnalato. In questo senso un log è legato al
verificarsi di una eccezione e perciò in questa
ultima parte dell'articolo si concentrerà l'attenzione
su questo aspetto.
La gestione delle eccezioni in una applicazione complessa
è un aspetto piuttosto delicato e molto importante.
La presenza di uno strato EJB di fatto complica non
poco le cose, dato che si introduce il concetto di codice
distribuito e molto spesso di separazione dei contesti
di esecuzione (le virtual machine dove gira l'EJB container
può essere differente da quella del resto della
applicazione).
Per prima cosa è forse utile fare una prima suddivisione
macroscopica delle tipologie di eccezioni:
JVM
exception: questo è probabilmente il
caso peggiore che si possa verificare. Quando si verifica
una eccezione di questo tipo non è possibile
fare niente per intervenire ed il programma si bloccherà
irrimediabilmente. Per fortuna con il migliorare del
codice interno delle JVM questi problemi accadono abbastanza
raramente.
Application
exception: si tratta di eccezioni custom generate
dalla applicazione o da una libreria utilizzata. Genericamente
denotano una qualche condizione negata o una anomalia
di funzionamento. In questo caso il metodo chiamante
può gestire il problema in modo opportuno ed
indolore per l'utente finale.
System
exception: nella maggior parte dei casi si tratta
di eccezioni derivate dalla RuntimeException ed indicano
spesso un bug nel codice. Esempi molto frequenti possono
essere la NullPointerException o la ArrayOutOfBoundException.
Si tratta in ogni caso di eccezioni unchecked per le
quali non è necessario il controllo forzato ovvero
il codice che può generare una unchecked non
necessariamente deve essere incluso in una try-catch.
A volte possono verificarsi anche delle system exception
di tipo checked (il cui controllo è obbligatorio),
come ad esempio nel caso in cui si sbagli un nome JNDI
di un oggetto remoto. In questo caso una regola empirica
dice che eccezioni checked per le quali non sia possibile
trovare nessun rimedio (ad esempio se il nome del database
è errato, non si potrà proseguire in nessun
modo), dovranno essere catturate in una catch e rilanciate
come eccezioni unchecked. Si ricordi infatti una eccezione
unchecked non deve essere dichiarata nella firma del
metodo: questa regola essendo soluzione di situazioni
del tutto impreviste, consente di scrivere codice in
modo più libero e non troppo macchinoso.
La
gestione delle eccezioni in una applicazione EJB
In una applicazione EJB ogni invocazione di metodo è
filtrata dal container che quindi riesce anche ad intercettare
ogni eccezione. La specifica EJB cataloga formalmente
le eccezioni in due principali categorie:
Application
exception: eccezioni di questo tipo sono quelle
definite nella firma di un metodo remoto (oltre alla
RemoteException). In questo caso normalmente il client
invocante può effettuare un workaround o invocare
direttamente un altro metodo. La regola dice che non
si possono considerare application exception quelle
di tipo unchecked, dato che questo porterebbe a situazioni
ingestibili: ad esempio se non è noto quali eccezioni
genera un metodo, è impossibile al client gestire
tutte le possibili alternative.
Eventi di questo tipo non obbligano il container ad
una rollback sulla transazione in atto e le eccezioni
sono rilanciate al client così come sono senza
nessuna operazione di rewrapping.
System
exception: in questo caso possono essere eccezioni
sia checked che unchecked. Nel secondo caso il container
effettua una rollback ed incapsula l'eccezione in una
RemoteException dopo aver effettuato tutte le operazioni
di pulizia e ripristino del caso.
Per le checked exception il container non effettua nessuna
operazione di pulizia, per cui è compito del
programmatore di incapsulare le eccezioni in una unchecked,
tipicamente una EJBException o una sua sottoclasse.
Dato che questa è a sua volta una eccezione unchecked
(quindi non deve essere dichiarata nella firma del metodo),
il container procede ad effettuarne il wrapping all'interno
di una RemoteException. Notare che in EJB 1.0 tutte
le eccezioni checked devono essere rilanciate come RemoteException,
mentre in EJB 1.1 nessun metodo può lanciare
eccezioni di questo tipo.
In un caso o nell'altro il client riceverà quindi
sempre eccezioni di tipo RemoteException o di una sua
sottoclasse.
Tutte le eccezioni system sono obbligatoriamente loggate
dall'application server, ma dato che il formato può
variare da prodotto a prodotto, è sempre bene
utilizzare un proprio sistema di log.
Alcune tecniche e strategie per la gestione delle eccezioni
in EJB
Dopo aver parlato di tipologie di eccezioni in EJB,
sorge spontaneo chiedersi dove debbano essere effettuati
i log, ovvero in quali clausole catch della applicazione
EJB.
Si può subito dare una risposta molto sintetica
a questa domanda: se l'applicazione EJB è stata
ben progettata, allora il client finale non dovrebbe
mai accedere agli entity, ma sempre a dei session. Per
questo motivo tutte le eccezioni in un entity dovrebbero
essere rilanciate come EJBException mentre in un session
si dovrebbe anche effettuarne il log.
Come è stato più volte detto nel corso
di questa serie, non è buona cosa che l'applicazione
client acceda ad un entity; questo è vero anche
considerando il caso dei log. Se l'entity fosse invocato
direttamente dal client si sarebbe costretti ad effettuare
direttamente il log al suo interno; lo stesso entity
però potrebbe essere invocato da un altro session
ed in tal caso si avrebbe una duplicazione dei messaggi,
con indubbia confusione finale.
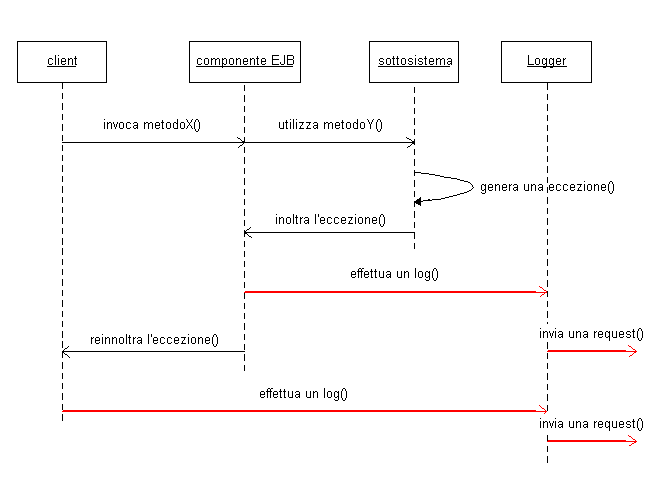
Figura
1 - la gestione dei messaggi di log e delle eccezioni
deve tenere conto della architettura della applicazione.
Si può pensare da un lato di gestire tutte le
eccezioni localmente al luogo di generazione, oppure
di propagare il tutto sempre verso lo strato client.
In figura è mostrato il caso in cui una applicazione
con client stand alone è strato server di EJB.
Per voler mantenere separati i contesti si preferisce
in ogni caso effettuare il log delle eccezioni, anche
se questo può portare ad una duplicazione dei
messaggi
Infine
la decisione se propagare una eccezione fino allo strato
client oppure fermarsi a un determinato livello dipende
molto dal tipo di applicazione che si sta realizzando.
Se il client è una applicazione web basata sul
pattern Command (ovvero in una situazione in cui gli
oggetti remoti invocati sono sempre li stessi, switchando
command con un parametro di invocazione) allora probabilmente
la cosa migliore è fermare il log e le eccezioni
a livello di business logic EJB. Se invece si opera
in un MVC classico, è preferibile propagare le
eccezioni al livello web dove verranno intercettate
e dove quindi si procederà ad effettuare il log.
Quando non si ha ancora troppo le idee chiare su quale
sia la struttura ed il design finale della applicazione,
oppure quando la business logic debba essere invocata
da differenti tipologie di client (come nel caso in
esame in questa serie di articoli) è forse preferibile
effettuare un log a livello EJB e comunque re-inoltrare
le eccezioni sullo strato web dove verrà eventualmente
creato un altro log.
Alcuni autori dicono però che una system exception
spesso è causata da una situazione non chiara,
non identificabile, per cui è bene effettuarne
sempre il log. Per le application exception invece essendo
state create direttamente dal programmatore, è
più semplice ricavare il contesto che le ha generate:
una MyPersonalFIleIsMissingException non dovrebbe lasciare
dubbi circa cosa sia realmente successo. In questi casi
il semplice rilancio della eccezione dovrebbe essere
sufficiente.
Una tecnica proposta in [ejbexc] per limitare il proliferare
di log in una applicazione mista (un qualche tipo di
client più uno strato EJB), si basa sul concetto
di re-inoltrare sempre le eccezioni quando esse si verificano,
ma di effettuare il log delle stesse solo se questo
non è già stato effettuato prima.
A tale scopo viene proposta una rivisitazione della
classe EJBException nel sequente modo:
public
class LoggableEJBException extends EJBException {
protected boolean isLogged;
protected String uniqueID;
public LoggableEJBException(Exception exc)
{
super(exc);
isLogged = false;
uniqueID = ExceptionIDGenerator.getExceptionID();
}
...
}
il
campo isLogged verrà impostato a true quando
in un punto qualsiasi, oltre a rilanciare l'eccezione
si procederà al log della stessa. Ad esempio
se in un determinato metodo si avesse
...
try {
...
}
catch(LoggableException le){
if (!le.isLogged){
logger.error("EJBException
……");
le.isLogged=true;
}
throw e;
}
dovesse
invocare altri metodi passibili di generare una eccezione
Conclusione
Quello qui proposto è solo una minima parte di
quello che dovrebbe essere detto a tal proposito. Nell'ambito
di un tutorial dedicato alla programmazione J2EE non
poteva mancare una sezione dedicata a questi aspetti.
Ovviamente per motivi di spazio non è possibile
indugiare oltre: anche se in alcuni passaggi il lettore
più esperto troverà superficiali alcune
trattazioni, è bene tenere presente che in un
modo o nell'altro è bene non tralasciare di soffermarsi
sulla definizione ed implementazione di una saggia politica
di gestione delle eccezioni.
La parte dedicata al canale web e la sua integrazione
con EJB è praticamente conclusa. Il prossimo
mese inizieremo a parlare di integrazione di moduli
sul lato server, argomento che sarà poi da preludio
per iniziare a parlare degli altri canali: le applicazioni
stand alone e la piattaforma embedded.
Bibliografia
[log4j] - Home page del progetto log4j, http://jakarta.apache.org/log4j
[log4jdocs] - Documentazione ufficiale di log4j
http://jakarta.apache.org/log4j/docs/documentation.html
[jdbcapp] - JDBCAppender, http://support.klopotek.de/log4j/jdbc/default.htm
[vconfig] - configLog4j un ambiente visuale per la configurazione
di log4j http://www.japhy.de/configLog4j/
[log4jconf] - Configurazione di log4j tramite file di
proprietà http://jakarta.apache.org/log4j/docs/api/org/apache/log4j/PropertyConfigurator.html
[ejbexc] - Best Practice in EJB exception handling -
di Srikanth Shenoy,
http://www-106.ibm.com/developerworks/library/j-ejbexcept.html
Risorse
Scarica qui i
sorgenti presentati nell'articolo
|


