|
Introduzione
Inizia questo mese una serie di articoli dedicati a
JNDI, l'API di Java per i servizi di Naming e Directory:
citata soprattutto nell'ambito di Java 2 Enterprise
Edition, dove gioca un ruolo fondamentale per la gestione
di risorse e degli EJB, spesso viene ridotta alla citazione
delle due operazioni più ricorrenti, bind() e
lookup(). In realtà JNDI è molto di più
dato che rappresenta lo strumento per poter poter accedere
in modo uniforme e standard a i principali sistemi di
naming e directory attualmente a disposizione.
JNDI è una API utilizzata moltissimo nell'ambito
J2EE, anche se in modo silente: tutte le volte che in
RMI, in CORBA o in EJB per esempio si effettua una ricerca
di un oggetto remoto, in realtà si utilizzano
i servizi di base di JNDI. Affrontare nel dettaglio
questa API è quindi molto importante non solo
per realizzare applicazioni che si interfaccino con
sistemi di naming e directory distribuiti, ma anche
per comprendere a pieno cosa significhi effettuare un
lookup di un oggetto remoto (in RMI) o ricavare la home
interface di un enterprise bean (in EJB).
JNDI
offre lo stesso livello di astrazione nei confronti
dei sistemi di naming che JDBC ha verso i database relazionali.
Per questo motivo per poter comprendere a pieno la potenza
di questa API, è utile se non indispensabile
affrontare i concetti di naming e directory services,
effettuando al contempo una ampia introduzione a LDAP.
Servizi di naming
Un sistema di naming fornisce il supporto per la gestione
di un set di dati associati ad un determinato nome,
ma non permette di cercare o manipolare oggetti direttamente
agendo sui nomi associati. Ogni set di dati deve avere
almeno un nome univoco con il quale può essere
identificato ad esempio tramite una operazione di bind
o di lookup (più avanti si affronteranno meglio
tali concetti).
I servizi di naming sono un pilastro fondamentale di
internet, e sono utilizzati ogni giorno da milioni di
utenti: si pensi ad esempio che ogni volta che ci si
collega al sito MokaByte, tramite l'indirizzo del dominio
www.mokabyte.it in realtà si è connessi
con il server il cui indirizzo numerico è 212.177.120.162,
decisamente più difficile da ricordare. Il computer
su cui gira il browser ha effettuato, in modo del tutto
trasparente, un'interrogazione su uno dei servizi fondamentali
di Internet, il DNS: Domain Naming Service. La domanda
era "a quale indirizzo è associato il nome
www.mokabyte.it?" ed un server predisposto ha fornito
la risposta.
Oltre
che a rendere la vita più facile per evitare
di memorizzare numeri, un servizio di naming porta anche
ad una maggior facilità di configurazione di
un sistema, permettendo un maggiore disaccoppiamento
tra fornitore e fruitore di servizio. Infatti non solo
non è necessario sapere che l'indirizzo IP di
MokaByte è per l'appunto 212.177.120.162, ma
nemmeno essere informati delle operazioni amministrative
del service provider di MokaByte, che dall'oggi al domani
potrebbe decidere di spostare il suo sito su un indirizzo
diverso, per esempio 12.184.31.32. Sarà sufficiente
che il database DNS tenga conto della modifica e tutti
i lettori di MokaByte potranno continuare a leggere
tranquillamente la loro rivista preferita.
Un
altro esempio di naming service è quello fornito
dal filesystem del sistema operativo: per esempio il
nome C:\temp\file.txt (mnemonico e facile da ricordare)
è associato ad un ben preciso numero di settore
fisico sull'hard disk dove sono memorizzati i dati.
Il sistema operativo è libero di riorganizzare
il modo in cui memorizza i dati (per esempio una deframmentazione
potrebbe spostare i dati su altre aree del disco), ma
il nome c:\temp\file.txt permetterà comunque
di accedere ai dati senza tenere conto di questi dettagli.
Ogni
servizio di naming viene identificato tramite un determinato
contesto o context; così il root context è
il nome base di una entry, sotto la quale tutte le altre
directory sono memorizzate. Ad esempio in un filesystem
rappresenta la directory radice (/ in Unix o C:\ in
Windows).
Un sottocontesto invece è il nome che rappresenta
un set di dati appeso gerarchicamente al contesto principale.
Possono esserci più sottocontesti attaccati al
contesto principale, in modo da organizzare meglio i
vari name space e conferire al sistema complessivo una
maggiore pulizia e flessibilità.
Servizi di Directory
Un servizio di directory permette di associare alcune
informazioni o metadati, ad un oggetto identificato
dal suo nome univoco: è quindi possibile trovare
un determinato elemento tramite tali informazioni senza
conoscerne il suo nome. In genere un sistema di directory
contiene anche un servizio di naming, ma non è
detto il viceversa.
Un directory è un particolare tipo di database
in grado di organizzare i propri dati in modo gerarchico:
fra i più noti si possono sicuramente ricordare
LDAP, NIS/NIS+ (Network Information Service di Sun),
NDS (Novell Directory Service di Novell), Windows NT
Domains, ADS (Active Directory Service).
Con il crescere delle reti informatiche e delle infrastrutture
distribuite, è cosa piuttosto frequente che questi
sistemi differenti coesistano nello stesso sistema;
nasce per questo l'esigenza di accedere con un unico
strumento a tali sistemi.
Il protocollo LDAP rappresenta probabilmente il meccanismo
migliore per permettere tale unificazione; JNDI è
la API Java che permette di parlare LDAP, e per questo
è consuetudine considerare queste due tecnologie
strettamente dipendenti, anche se JNDI consente il collegamento
con altri sistemi di directory e naming.
LDAP
Il Lightweight Directory Access Protocol (LDAP) è
stato sviluppato nei primi anni '90 come standard per
la gestione di Directory Services. Tale protocollo non
definisce come i dati debbano essere memorizzati sul
server, o nel sistema di directory, ma solamente come
il client debba accedervi. LDAP fornisce essenzialmente
tre tipologie di servizi: Access Control, White Pages
Services, Distribuited Computing Directory.
LDAP
Access
Si basa essenzialmente su due tipi di servizi, l'autenticazione
e l'autorizzazione. L'autenticazione determina l'identità
di chi sta utilizzando o desidera utilizzare un determinato
software. Anche se non si può essere completamente
certi dell'identità di un determinato soggetto,
si possono utilizzare differenti meccanismi che permettono
a vari livelli di ottenere tale informazione. Si passa
dalla semplice autenticazione tramite userid e password,
trasmesse in chiaro o crittate, fino all'utilizzo di
certificati digitali di autenticazione. LDAP fornisce,
come si potrà vedere più avanti con degli
esempi completi, tre livelli di autenticazione: semplice
(uid e passwd), certificati digitali (SSL) e tramite
il protocollo Simple Authentication and Security Layer
(SASL) che rappresenta un misto dei due sistemi precedenti.
Il perché sia necessario utilizzare tali sistemi,
e come essi funzionino, è un argomento che esula
dagli scopi di questo articolo anche se dovrebbero in
parte essere concetti noti alla maggior parte dei lettori.
Una volta determinata l'identità di un utente,
l'autorizzazione definisce quali operazioni siano permesse
all'utente e quali risorse esso può accedere.
Si può utilizzare LDAP per definire complesse
policies di sicurezza.
LDAP White Pages Services
Questo servizio permette di ricercare persone in un
determinato archivio sulla base di precise caratteristiche
o attributi, proprio come si può fare ad esempio
consultando l'elenco del telefono. Il nome infatti deriva
proprio dalle white pages statunitensi, che rappresentano
il corrispettivo del nostro elenco del telefono. In
genere questo tipo di servizio è reso di pubblico
dominio, senza nessuna restrizione di accesso, da tutti
i principali sistemi di archivio di schede personali.
Java in genere partecipa in questo scenario come gateway
fra un sistema di anagrafica LDAP ed una applicazione
Java vera e propria.
LDAP Distribuited Computing Directory
La programmazione distribuita è sicuramente uno
dei settori dell'informatica in più ampia e rapida
espansione. RMI, CORBA, EJB sono solo alcuni esempi
in cui Java è direttamente parte in causa.
In tali scenari l problema principale è determinare
dove si trovi un determinato pezzo di codice e come
fare per poterlo ricavare. LDAP da questo punto di vista
offre un importante strato di separazione fra una classe
ed il suo nome logico e quindi fra il codice remoto
e chi lo deve utilizzare. Chiunque abbia realizzato
una qualsiasi applicazione RMI o CORBA comprenderà
perfettamente cosa significhi tutto ciò e quali
siano gli aspetti legati a tali concetti.
In genere tramite LDAP è possibile non solo memorizzare
pezzi di codice in modo strutturato in un sistema di
directory, ma anche aggiungere alcune informazioni descrittive
relative al codice memorizzato, dando luogo a notevoli
possibilità aggiuntive.
I
dati in LDAP
In LDAP i dati sono organizzati in modo gerarchico secondo
uno schema ad albero, detto Directory Information Tree
(DIT), in cui ogni foglia viene detta entry. La prima
entry è la root entry. Ogni entry è univocamente
identificata da un Distinguished Name (DN), più
una serie di coppie attributo/valore.
Il DN, che rappresenta l'equivalente della chiave primaria
in un database relazionale, indica anche la posizione
della entry all'interno dell'albero DIT, come ad esempio
il path completo di un file ne identifica la posizione
all'interno del file system.
Un esempio di DN potrebbe essere
uid=giovanni.puliti,
ou=writers, o=mokabyte.it
la
parte più a sinistra rappresenta il Relative
Distinguished Name (RDN), ed in questo caso è
data dalla coppia uid=giovanni.puliti
Gli attributi LDAP in genere utilizzano valori mnemonici
per i vari nomi; ad esempio alcuni tipici attribuiti
potrebbero essere
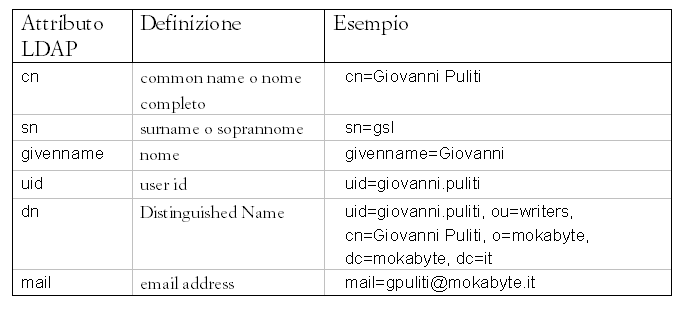
Tabella
1 - alcuni esempi di attributi LDAP
Ogni
attributo può avere uno o più valori ed
più in generale seguire determinate regole come
definito nel cosiddetto schema. Lo schema definisce
l'objectclasses e gli attributi in un DT LDAP. Ad esempio
un utente può avere uno o più indirizzi
di posta elettronica.
L'attributo objectclass che equivale alla tabella di
un database relazionale, specifica quali sono gli attributi
di una entry, suddividendoli in obbligatori (required)
ed opzionali (allowed).
In seguito si ritornerà questo punto, analizzando
l'objectclass inetOrgPerson, uno degli oggetti più
utilizzati in tutti i sistemi LDAP, potrebbe essere
definito nel seguente modo
(
2.16.840.1.113730.3.2.2
NAME 'inetOrgPerson'
SUP organizationalPerson
STRUCTURAL
MAY (
audio $ businessCategory $ carLicense $ departmentNumber
$
displayName $ employeeNumber $ employeeType $ givenName
$
homePhone $ homePostalAddress $ initials $ jpegPhoto
$
labeledURI $ mail $ manager $ mobile $ o $ pager $
photo $ roomNumber $ secretary $ uid $ userCertificate
$
x500uniqueIdentifier $ preferredLanguage $
userSMIMECertificate $ userPKCS12
)
)
Si
noti la prima stringa che rappresenta l'Object Identifier
o OID, che identifica l'oggetto in modo analogo a come
in Java il serialization UID identifica una classe serializzabile.
Il SUP invece identifica il padre di tale oggetto, dato
che l'organizzazione gerarchica di LDAP permette di
dar vita a gerarchie di oggetti un po' come avviene
nel modello OO.
In questo caso il processo di generalizzazione-specificazione
(legame padre-figlio) permette di aggiungere-rimuovere
proprietà e non comportamenti (metodi).
Successivamente sono riportati gli attributi obbligatori
(campo MUST) e quelli opzionali (MAY).
Il carattere di separazione $ è stato scelto
per tradizione, in onore alla convenzione adottata dal
protocollo X.500, che quando fu definito, si basava
hardware particolare non in grado di stampare il carattere
$, che quindi pur rappresentando il separatore non veniva
rappresentato.
Una entry può essere rappresentata anche tramite
il formato di interscambio LDIF (LDAP Data Interchange
Format), che di fatto è il modo comune con il
quale una entry può essere rappresentata in modo
leggibile all'occhio umano.
version:
1
dn: cn=Barbara Jensen,ou=Product Development,dc=siroe,dc=com
objectClass: top
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Barbara Jensen
cn: Babs Jensen
displayName: Babs Jensen
sn: Jensen
givenName: Barbara
initials: BJJ
title: manager, product development
uid: bjensen
mail: bjensen@siroe.com
telephoneNumber: +1 408 555 1862
facsimileTelephoneNumber: +1 408 555 1992
mobile: +1 408 555 1941
roomNumber: 0209
carLicense: 6ABC246
o: Siroe
ou: Product Development
departmentNumber: 2604
employeeNumber: 42
employeeType: full time
preferredLanguage: fr, en-gb;q=0.8, en;q=0.7
labeledURI: http://www.siroe.com/users/bjensen My Home
Page
Dato che lo scopo di questo articolo non è una
trattazione approfondita di LDAP, concludiamo qui questa
introduzione a tale protocollo. Per chi fosse interessato
a maggiori approfondimenti, si rimanda alla lettura
della molta bibliografia presente sull'argomento, fra
cui [LDAP].
JNDI
Sebbene LDAP stia crescendo in popolarità e diffusione,
esso è ancora molto lontano da essere il protocollo
universale per tutti i sistemi di naming e directory.
Tecnologie come
NDS e NIS sono forse più diffusi nel mondo dei
server, mentre CORBA, basato su un sistema di naming
proprio, era fino a qualche tempo fa la tecnologia più
diffusa per la realizzazione di applicazioni distribuite
language e platform indipendent; EJB di recente sta
velocemente diffondendosi come la tecnologia di riferimento
in questo genere di architetture.
Per questo JNDI sta diventando sempre più una
delle colonne portanti di J2EE ed in particolare di
EJB, dove è importantissimo poter disporre di
un sistema di localizzazione di oggetti remoti.
Come rappresentato dalla figura 1, si può pensare
di utilizzare JNDI per collegarsi non solo ad un server
LDAP, ma indifferentemente ad un directory service NDS
o NIS. In questo modo JNDI fornisce una interfaccia
comune verso i diversi sistemi sottostanti, e si può
passare molto facilmente da un sistema all'altro semplicemente
cambiando driver Purtroppo, differentemente da JDBC,
lo strato driver non espone una interfaccia uniforme
e completamente standard per cui non sempre è
possibile per l'applicazione client astrarsi dai dettagli
implementativi e tecnologici sottostanti.
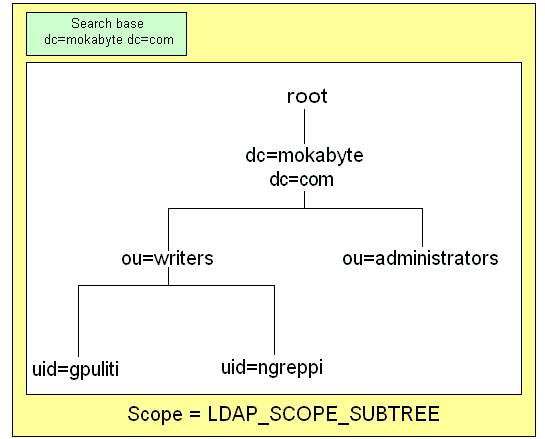
Figura 1 - JNDI può essere utilizzato
per interfacciarsi con sistemi di naming/directory differenti,
fornendo in questo modo una piattaforma unica
Il JNDI Service Provider (JNDI Driver)
Un service provider è un driver che permette
di comunicare con un directory service in modo analogo
a come un driver JDBC consente la comunicazione con
un database relazionale. Come si avrà modo di
vedere negli esempi, un driver deve implementare l'interfaccia
Context o più spesso la DirContext che la estende
direttamente per accedere ai sistemi di directory.
Il driver però non è in grado di astrarre
completamente il sistema sottostante, ma è necessita
di alcuni parametri operativi legati al sistema sottostante:
ad esempio JNDI non dispone ancora di un linguaggio
di interrogazione come invece JDBC che dispone di SQL.
In tal senso il gruppo di sviluppo di XML sta pensando
di dar vita a quello che dovrebbe prendere il nome di
DSML (Directory Service Markup Language); il lavoro
da fare è ancora molto (il primo maggio 2002
la specifica DSML ver. 2 è stata approvata come
OASIS Specification), e non da tutti ritenuto così
importante: si ritiene infatti che gli sforzi maggiori
dovrebbero volti ad ampliare il supporto per LDAP dei
vari sistemi di directory.
Per migliorare l'integrazione di sistemi differenti,
JNDI supporta il concetto di federazione in modo che
un service provider possa passare una determinata richiesta
ad un altro nel caso in cui questa non possa essere
soddisfatta dal primo. In questo caso questo meccanismo
è molto simile a quello supportato da JDBC in
cui per una connessione al database viene utilizzato
il primo driver in grado di comprendere la stringa di
connessione.
Il package JNDI viene fornito di default con alcuni
service provider per connettersi ai principali sistemi
di directory attualmente disponibili: LDAP, NIS, COS
(CORBA Object Service), RMI Regostry, File System. Altri
provider possono essere utilizzati in alternativa o
in aggiunta a quelli di base: ad esempio Novell fornisce
un service provider per il collegamento con NDS, mentre
IBM e Netscape hanno prodotto alcuni provider alternativi
per la connessione con LDAP.
Per chi fosse interessato a sviluppare un proprio service
provider può fare riferimento il tutorial JNDI
di Sun (vedi [tutorial]), oppure studiare l'implementazione
di Netscape reperibile come progetto open source presso
il sito di Mozzilla.org (vedi [mozilla])
Lavorare
con JNDI
Le operazioni concesse in JNDI sono essenzialmente le
seguenti
- Connessione ad un server LDAP
- Autenticazione sul server (LDAP bind)
- Operazioni sui dati: ricerca, aggiunta modifica e
rimozione di una entry
- Disconnessione dal server LDAP
Si vedranno adesso tali operazioni una dopo l'altra
Connessione
ed autenticazione
La prima cosa da fare per poter manipolare le informazioni
contenute in un archivio LDAP è connettersi con
il sistema. Per effettuare tale operazione è
necessario ricavare un oggetto che implementa l'interfaccia
DirContext. Nella maggior parte dei casi questo può
essere fatto tramite l'oggetto InitialDirContext fornendo
al costruttore i parametri necessari tramite una hastable.
A livello minimale tali parametri comprendono il nome
della classe da utilizzare come inizializzatore di contesto,
e l'url del server. Ad esempio si potrebbe scrivere
Hashtable
env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,
"com.sun.jndi.ldap.LdapCtxFactory");
env.put(Context.PROVIDER_URL, "ldap://localhost:389");
Context ctx = new InitialContext(env);
per
la connessione verso un server LDAP in esecuzione sul
server locale.
Il paramentro Context.INITIAL_CONTEXT_FACTORY è
molto importante dato che specifica il tipo di directory
service verso il quale si desidera collegarsi. Ad esempio
se si volesse utilizzare il file system, si potrebbe
scrivere
Hashtable
env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, "com.sun.jndi.fscontext.RefFSContextFactory");
Context ctx = new InitialContext(env);
Utilizzando
un questo caso il factory fornito da Sun per la connessione
con il directory service filesystem. Da notare che spesso
tali parametri possono essere scritti in un file jndi.properties
memorizzato nel classpath della applicazione: tale file
verrà caricato automaticamente e passato come
oggetto Properties al costruttore InitialContext. Normalmente
questa operazione viene effettuata nelle applicazioni
client di EJB, fornendo in questo caso i parametri del
server e del context Factory. Ecco di seguito alcuni
casi per la connessione ai più famosi EJB container
disponibili sul mercato:
#
Weblogic Server
INITIAL_CONTEXT_FACTORY=weblogic.jndi.WLInitialContextFactory
PROVIDER_URL=t3://localhost:7001
#
Borland Enterprise Server
INITIAL_CONTEXT_FACTORY=com.inprise.j2ee.jndi.CtxFactory
PROVIDER_URL=iiop:///
#
JBoss
INITIAL_CONTEXT_FACTORY=org.jnp.interfaces.NamingContextFactory
PROVIDER_URL=jnp://localhost:1099
#
IBM WebSphere
INITIAL_CONTEXT_FACTORY=
com.ibm.websphere.naming.WsnInitialContextFactory
PROVIDER_URL=iiop://localhost:900
In
questo caso JNDI viene utilizzato per connettersi con
un repositori di oggetti remoti, non tanto per accedere
alle informazioni di un DIT, ma piuttosto per poter
ricavare gli stub remoti. C desiderasse approfondire
l'utilizzo di JNDI per questo genere di operazioni,
si rimanda alla specifica di EJB.
Anche se d'ora in poi si focalizzerà l'attenzione
su JNDI e LDAP si tenga presente che specificando la
classe definita dal parametro INITIAL_CONTEXT_FACTORY
è possibile cambiare completamente il tipo di
service directory utilizzato. Questo è una operazione
molto più potente di quella permessa in JDBC
al momento di specificare il driver: tanto per avere
un'idea è come se si decidesse di cambiare non
solo database (server) ma passare indifferentemente
da un database relazionale ad uno ad oggetti o ad uno
di tipo flat file (esempio File .csv).
Al momento della connessione verso il server viene effettuata
anche l'autenticazione del client. Questa operazione
è detta binding e non deve essere confusa con
l'operazione di bind di oggetti con nomi logici come
avviene abitualmente con i registry di oggetti.
Nel caso in cui non sia fornita nessuna credenziale,
l'utente viene connesso con il profilo anonimo, con
un ridotto set di operazioni permesse: ad esempio spesso
viene fornito il solo accesso in lettura verso anagrafiche
di utenti. Tutte le operazioni, comprese anche quelle
a livello base di lettura, sono definite tramite una
ACL definita nel server LDAP.
Ad ogni entry può essere associata una o più
ACL in modo da realizzare differenti viste sui dati
memorizzati nel DIT. I tre livelli di autenticazione
forniti dallo standard LDAP (simple, SSL, SASL), possono
essere specificati al momento della connessione utilizzando
i relativi parametri al costruttore del contesto. In
particolare
- Context.SECURITY_AUTHENTICATION
("java.naming.security.authentication").
Specifica il mccanismo di autenticazione da utilizzare.
Per il service provider LDAP di Sun, può essere
uno dei seguanti valori: none, simple, sasl_mech,
dove sasl_mech è una lista separata da spazi
di nomi basati sul meccanismo SASL.
- Context.SECURITY_PRINCIPAL
("java.naming.security.principal").
Specifica il nome dell'utente o programma client che
effettua l'autenticazione. Questo valore dipende dal
valore precedente.
- Context.SECURITY_CREDENTIALS
("java.naming.security.credentials").
Specifica le credenziali di autenticazione. A seconda
del tipo di autenticazione, si può inserire
la password o un certificato digitale.
Ecco
alcuni esempi di autenticazione
Autenticazione
Anonima
Hashtable
env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,
"com.sun.jndi.ldap.LdapCtxFactory");
env.put(Context.PROVIDER_URL, "ldap://localhost:389/o=JNDITutorial");
//
Usa la anonymous authentication
env.put(Context.SECURITY_AUTHENTICATION, "none");
//
Crea l' initial context
DirContext ctx = new InitialDirContext(env);
//
... fai qualcosa con ctx
Autenticazione
Simple
// Set up the environment for creating the initial context
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,
"com.sun.jndi.ldap.LdapCtxFactory");
env.put(Context.PROVIDER_URL, "ldap://localhost:389/o=JNDITutorial");
//
Autentica come utente Giovanni Puliti e password pippo
env.put(Context.SECURITY_AUTHENTICATION, "simple");
env.put(Context.SECURITY_PRINCIPAL,
"cn=Giovanni
Puliti, ou=writers,
o=mokabyte");
env.put(Context.SECURITY_CREDENTIALS, "pippo");
//
Crea l'initial context
DirContext ctx = new InitialDirContext(env);
//
...fa qualcosa con ctx
E'
possibile eventualmente eseguire una seconda bind dopo
la prima, con un differente livello di autenticazione
utilizzando i metodi Context.addToEnvironment() e Context.removeFromEnvironment().
Le operazioni successive lavoreranno con le nuove credenziali
fornite.
env.put(Context.SECURITY_AUTHENTICATION,
"simple");
env.put(Context.SECURITY_PRINCIPAL, "cn=Giovanni
Puliti,
ou=writers,
o=mokabyte");
env.put(Context.SECURITY_CREDENTIALS, "pippo");
//
Crea l'initial context
DirContext ctx = new InitialDirContext(env);
//
... fa qualcosa con ctx
//
Cambia l'autenticazione usando il profilo anonimo
ctx.addToEnvironment(Context.SECURITY_AUTHENTICATION,
"none");
//
... fa qualcosa con ctx
In
caso autenticazione fallita si riceve un errore del
tipo
javax.naming.AuthenticationException:
[LDAP: Invalid Credentials]
at java.lang.Throwable.<init>(Compiled Code)
at java.lang.Exception.<init>(Compiled Code)
Se
invece si specifica un tipo di autenticazione non supportata
verrà generata una eccezzione del tipo AuthenticationNotSupportedException;
ad esempio il pezzo di codice seguente
env.put(Context.SECURITY_AUTHENTICATION,
"myauthentication");
env.put(Context.SECURITY_PRINCIPAL, "cn=Giovanni
Puliti, ou=writers,
o=mokabyte");
env.put(Context.SECURITY_CREDENTIALS, "pippo");
produce
il seguente output:
javax.naming.AuthenticationNotSupportedException:
Unsupported value for java.naming.security.authentication
property.
at java.lang.Throwable.<init>(Compiled Code)
at java.lang.Exception.<init>(Compiled Code)
at javax.naming.NamingException.<init>(Compiled
Code)
...
Autenticazione
SASL e SSL
Per quanto riguarda i procedimenti di autenticazione
tramite SASL e SSL una esauriente e comprensiva analisi
di tali meccanismi richiederebbe molto più spazio
di quello qui a disposizione e per certi versi esula
dagli scopi di questo articolo, per cui si rimanda al
tutorial sun su JNDI [tutorial], o alla documentazione
relativa alla JAAS API.
Leggere le proprietà di una entry
Una primo approccio relativamente alla lettura di informazioni
in un DIT può essere fatto tramite il metodo
DirContext.getAttributes() che permette di leggere gli
attributi di un oggetto nel directory. Il metodo riceve
il nome dell'oggetto del quale si vogliono leggere gli
attributi, ad esempio per l'oggetto "cn=Giovanni
Puliti, ou=writers", si potrebbe scrivere
Attributes
answer = ctx.getAttributes("cn=Giovanni Puliti,
ou=writers ");
A
questo punto si può ricavare il contenuto della
risposta come di seguito
for
(NamingEnumeration ae = answer.getAll(); ae.hasMore();)
{
Attribute attr = (Attribute)ae.next();
System.out.println("Stampa dei
valori attributo con id: "
+
attr.getID());
// Stampa il valore di ogni attributo
for (NamingEnumeration e = attr.getAll();
e.hasMore();
System.out.println("-
valore: " + e.next()));
}
Ricerca di una entry
Dato che l'utilizzo più frequente di LDAP è
per memorizzare informazioni, prima o poi si rende necessario
eseguire una ricerca.
Si può cercare una entry sulla base del DN, o
in base ad ogni tipo di attributo. Le ricerche si effettuano
utilizzando una connessione, un punto base da cui iniziare
a cercare, definendo la profondità cui effettuare
le ricerche ricorsive nel DIT (scope search) ed dei
filtri che specificano il criterio di ricerca in modo
analogo ai filtri SQL (clausola WHERE).
In genere ogni ricerca si basa sulla comparazione di
un attributo con un determinato valore: un filtro può
essere booleano o di tipo più sofisticato come
il "sounds like" di iPlanet.

Tabella 2 - alcuni esempi di ricerche e filtri
da utilizzare
Il
punto di partenza per la ricerca e la ricorsività
nel DIT possono essere specificate tramite appositi
attributi: ad esempio se nel DIT rappresentante lo staff
di MokaByte si volesse cercare tutti le entry corrispondenti
a tutti i componenti dello staff si potrebbe specificare
come punto di partenza la radice del DIT stesso,
dc=mokabyte,
dc=it
oppure
se si volesse restringere la ricerca ai soli autori
ed articolisti si potrebbe specificare
ou=writers,
dc=mokabyte , dc=it
In
LDAP invece lo scope di una ricerca indica se tale ricerca
deve essere effettuata in modo ricorsivo e la profondità
di tale ricorsione. Lo scope può essere specificato
tramite i tre seguenti attributi
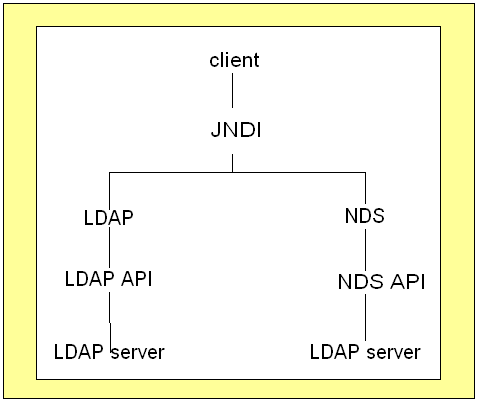
Figura
2- alcuni esempi di ricerca in base a punto di partenza
e scope.
In JNDI una ricerca su un DIT LDAP può essere
fatta tramite il metodo DirContext.search().
//
Specifica gli attributi da confrontare
// Cerca gli oggetti con l'attributo "sn"
= "gsl"
// e l'attributo "mail" con un valore qualsiasi
Attributes
matchAttrs = new BasicAttributes(true);
matchAttrs.put(new BasicAttribute("sn", "gsl"));
matchAttrs.put(new BasicAttribute("mail"));
//
Search for objects that have those matching attributes
NamingEnumeration answer = ctx.search("ou=writers",
matchAttrs);
L'esempio
precedente restituisce tutti gli attributi associati
alle entries che soddisfano la ricerca. Si può
eventualmente selezionare quali attributi debbano essere
restituiti come risultato della ricerca passando al
metodo search() un array di attributi.
//
Specifica quali attributi debbano essere restituiti
String[] attrIDs = {"sn", "telephonenumber",
"mail"};
//
Esegue la ricerca
NamingEnumeration answer = ctx.search("ou=People",
matchAttrs, attrIDs);
Per
affinare una ricerca in alternativa all'uso degli attributi,
si può utilizzare un filtro, ovvero una espressione
logica di confronto. Ad esempio per cercare tutte le
entries con un determinato indirizzo di posta elettronica
si potrebbe utilizzare la seguente espressione:
(&(ou=writers)(mail=*))
Il
codice seguente crea un filto ed un default search controls,
SearchControls e li usa per la ricerca
//
Crea i default search controls
SearchControls ctls = new SearchControls();
//
Specifica il filtro di ricerca
String filter = "(&(ou=writers)(mail=*))";
//
Cerca utilizzando il filtro
NamingEnumeration answer = ctx.search("o=mokabyte",
filter, ctls);
La
sintassi e il significato delle espressioni logiche
utilizzabili dovrebbe essere piuttosto intuitiva. Nella
tabella 3 è riportata una breve spiegazione.
Per una completa descrizione si faccia riferimento alla
RFC 2254.
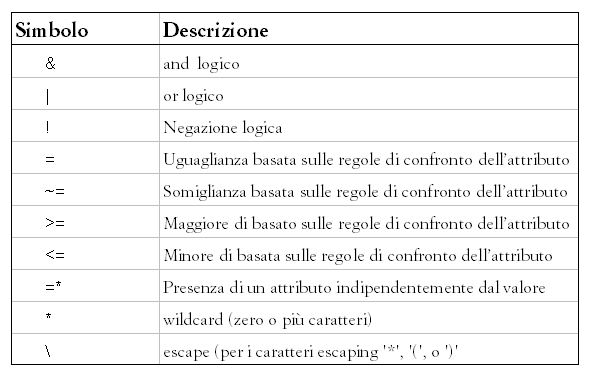
Tabella
3 - Simboli logici per le comparazioni nelle ricerche
Lo
scope di una ricerca indica la profondità con
cui una ricerca deve essere effettuata ricorsivamente
nell'albero del DIT. In LDAP si possono avere i valori
riportati nella tabella 4

Tabella
4 - Attributi dello scope di una ricerca
Ecco
un esempio di utilizzo degli attributi di scope nelle
ricerche:
String[]
attrIDs = {"sn", "telephonenumber",
"mail"};
SearchControls ctls = new SearchControls();
ctls.setReturningAttributes(attrIDs);
ctls.setSearchScope(SearchControls.SUBTREE_SCOPE);
// Specifica il filtro di ricerca
// cerca gli oggetti che hanno attributo "sn"
== "gsl"
// ed un valore qualsiasi in "mail"
String filter = "(&(sn=gsl)(mail=*))";
NamingEnumeration answer = ctx.search("",
filter, ctls);
Una
ricerca può essere limitata nel numero massimo
di elementi ritornati, o nel tempo massimo di esecuzione.
Nel primo caso si può utilizzare il metodo SearchControls.setCountLimit(),
come ad esempio
SearchControls
ctls = new SearchControls();
ctls.setCountLimit(1);
Se
il programma cerca di ottenere più risultati
del numero massimo specificato, verrà generata
una SizeLimitExceededException. Il limite temporale
invece può essere specificato tramite il metodo
SearchControls.setTimeLimit(); anche in questo al superamento
del limite caso verrà generata una eccezione
TimeLimitExceededException.
SearchControls
ctls = new SearchControls();
ctls.setTimeLimit(1000);
Impostare
il limite temporale a zero equivale a non imporre nessuna
restrizione.
Modificare
gli attributi di una entry
L'interfaccia DirContext offre alcuni metodi per la
modifica degli attributi e dei loro valori. Un modo
per effettuare tali modifiche è fornire una lista
di ModificationItem che rappresentano le costanti indicanti
il tipo di modifica che si desidera fare. I valori consentiti
sono i seguenti:
ADD_ATTRIBUTE
REPLACE_ATTRIBUTE
REMOVE_ATTRIBUTE
Il
cui significato dovrebbe essere piuttosto intuitivo.
Le modifiche sono ovviamente applicate nell'ordine in
cui compaiono nella lista e sono eseguite tutte oppure
nessuna.
Il seguente codice di esempio esegue una serie di modifiche
su una entry: per prima cosa modifica l'indirizzo di
posta elettronica (attributo mail), aggiunge un nuovo
numero di telefono (attributo telephonenumber) e rimuove
l'attributo codfiscale.
//
Specifica le modifiche da effettuare
ModificationItem[] mods = new ModificationItem[3];
//
Modifica l'attributo "mail" con un nuovo valore
mods[0] = new ModificationItem(DirContext.REPLACE_ATTRIBUTE,
new BasicAttribute("mail", "gpuliti@mokabyte.it"));
//
aggiunge un valore addizionale all'attributo "telephonenumber"
mods[1] = new ModificationItem(DirContext.ADD_ATTRIBUTE,
new BasicAttribute("telephonenumber", "123456789"));
//
rimuove the "codfiscale" attribute
mods[2] = new ModificationItem(DirContext.REMOVE_ATTRIBUTE,
new BasicAttribute("codfiscale"));
Non
sempre è possibile inserire valori multipli per
ogni attributo. Ad esempio in Windows Active Directory:
l'attributo telephonenumber deve essere di tipo single-value,
contrariamente a quanto specificato in RFC 2256. Per
utilizzare questo esempio con Active Directory, si dovrà
quindi rimpiazzare DirContext.ADD_ATTRIBUTE to DirContext.REPLACE_ATTRIBUTE
per il telephonenumber.
Dopo
aver creato la lista delle modifiche le si potranno
eseguire tramite
ctx.modifyAttributes(name,
mods);
Conclusione
Come si è potuto vedere JNDI offre un potente
sistema di gestione di archivi gerarchici permettendo
tutte le operazioni che similmente sono eseguibili in
un archivio gerarchico. In realtà JNDI e LDAP
permettono di fare molto di più, consentendo
di memorizzare e gestire oggetti Java e non solo in
modo remoto. Questa forse è la particolarità
più importante ed utile di questa API, tanto
da renderla una delle colonne portanti di J2EE e di
EJB in particolare. Il mese prossimo vedremo questi
aspetti.
Bibliografia
[RFC2798] "Definition of the inetOrgPerson LDAP
Object Class" http://www.faqs.org/rfcs/rfc2798.html
[tutorial] - JNDI Sun Tutorial -
[mozila] - Netscape's LDAP service provider - www.mozilla.org/dirctory
Risorse
Scarica
qui l'archivio con i sorgenti
presentati nell'articolo
|


