|
Introduzione
Quelli
appena visti questi sono soltanto alcuni dei commenti
sui Java Data Object, da parte degli esperti del settore.
Ma come stanno realmente le cose ? E' possibile avere
qualche elemento in più che ci aiuti a formulare
un giudizio corretto sui JDO?
In quest'articolo discuteremo questa nuova tecnologia,
come è stata pensata, cosa promette, i suoi punti
di forza e di debolezza, il supporto dato dai venditori.
In seguito, nei prossimi articoli, approfondiremo l'argomento,
occupandoci di integrazione JDO-J2EE, con il confronto
tra le strategie più utilizzate per la persistenza
dei business object (Entity Bean, JDO, SLQ e pattern
DAO) e con l'aiuto di esempi che presentino situazioni
"reali", come capita di affrontare nel lavoro
quotidiano.
Che ne dite? Se il programma vi piace, possiamo iniziare
……
I
Java Data Object
Una
delle critiche portate dai detrattori dei JDO è
il troppo tempo trascorso dalla loro introduzione, datata
Giugno 1999, alla nascita della prima versione delle
specifiche, arrivata solamente a Marzo di quest'anno.
Questa critica passa in secondo piano non appena pensiamo
all'ambizioso ed importante obiettivo dei JDO: essere
per i prodotti di persistenza quello che la J2EE è
per gli application server, un indiscusso standard comune.
JDO infatti si propone come uno standard per la persistenza
di oggetti java, utilizzabile su tutti gli ambienti
java (da J2ME a J2EE), accettato dai produttori di un'area
che tradizionalmente è molto restia ad uniformarsi
ad uno standard comune, capace di gestire trasparentemente
diverse fonti dati (DBMS,ODBMS, ecc.ecc).
Anche se destinate a crescere, già oggi le implementazioni
disponibili sono abbastanza numerose (vedi tabella1
e 2), pur senza il supporto ufficiale dei produttori
leader del settore e con poche implementazioni open-source
complete.
Le posizioni dei produttori più noti, sono diverse,
ed in generale non molto benevole, e vanno da un parziale
supporto (Oracle-Toplink e Exolab-Castor), ad una feroce
critica (Thought-Cocobase).
Sul loro supporto futuro immagino che molto dipenda
dal successo a breve dei JDO, perché sulle critiche
iniziali alla nascita di uno standard comune, da parte
di chi fino a ieri controllava un mondo proprietario,
immagino abbiate già lo vostra idea a riguardo.

Tabella 1 - Implementazioni JDO commerciali

Tabella 2 - Implementazioni JDO Open Source
Confronto con gli Entity Bean
Fin
dalla loro introduzione i JDO sono stati accompagnati
dall'idea di essere una tecnologia sostitutiva degli
entity bean, nonostante Sun abbia sempre negato questa
eventualità.
Vediamo ora le caratteristiche di entrambe le tecnologie
per capire se, ed in quali condizioni, risultino essere
sostitutive o complementari.
Gli
entity fanno parte delle specifiche J2EE e nascono come
dei componenti distribuiti che possono sfruttare tutta
una serie di servizi garantiti loro da un container
EJB, quali persistenza, sicurezza, transazionalità
e gestione del ciclo di vita delle istanze (object pooling).
Sono stati pensati per la modellazione delle entità,
i cosiddetti business object, anche se risentono da
subito di alcuni problemi (quasi tutti legati al concetto
di persistenza), affrontati e parzialmente risolti con
le specifiche 2.0, che potremmo riassumere con:
-
Obbligatorietà dell'accesso utilizzando un'interfaccia
remota.
- Persistenza
poco efficiente, difficilmente ottimizzabile per i
container, con poche funzionalità.
- Mapping
macchinoso, per le troppe informazioni presenti nei
deployment descriptor.
- Mancanza
di trasparenza dello strato di persistenza.Uso limitato
agli EJB contatiner.
I
JDO invece non fanno parte della J2EE ma sono integrabili
con essa, e rispetto agli entity bean, si occupano soltanto
del concetto di persistenza, senza considerare altre
problematiche, come ad esempio transazioni distribuite,
accessi remoti, meccanismi di sicurezza.
I JDO cercano una gestione della persistenza migliore
e diversa rispetto agli entity CMP, ed infatti rispondono,
da subito, a molti dei problemi degli entity:
-
Oggetti locali.
- Persistenza
performante e ricca di funzionalità.
- Sviluppo
semplificato, contenuto informativo dei descrittori
di persistenza (chiamati metadati) ridotto.
- Trasparenza
assoluta dello strato di persistenza.
- Possibilità
di utilizzo con tutte le piattaforme JAVA, dalla semplice
JVM ai container J2EE (le specifiche parlano di ambienti
managed e non).
Quanto
è ampia allora la sovrapposizione delle due tecnologie?
Sicuramente nel campo della persistenza è totale,
per quel che riguarda gli altri servizi dipende dalla
nostra architettura. Dobbiamo infatti ricordare che,
se escludiamo la persistenza, anche i session bean forniscono
gli stessi servizi ulteriori, e che quindi le due tecnologie
possono diventare complementari o sostitutive a seconda
delle nostre scelte architetturali.
Facciamo un paio di esempi per questi due scenari.
Se la nostra architettura utilizza il pattern session
facade, per l'accesso delle entità da parte del
web-tier (o del-client tier), siamo nelle migliori condizioni
per la sostituzione degli entity con i JDO.
Se invece vogliamo esporre direttamente le entità
(gli esempi sono solo ipotesi!) e controllare le autorizzazioni
sulle chiamate di ciascun metodo esposto, in questo
caso possiamo pensare ad un entity bean che utilizzi
la persistenza dei JDO.
Difficile
confermare, come alle volte si legge, che le implementazioni
JDO siano per natura più performanti dei motori
di persistenza CMP degli Entity. La diversità
delle due specifiche nella sezione SPI, cioè
nei cosiddetti contratti che i produttori devono soddisfare
nella realizzazione di una implementazione, è
certo una base di partenza su cui i produttori possono
costruire, ma da qui a dire che le implementazioni JDO
siano sicuramente più performanti………
Quando
si parla di trasparenza dello strato di persistenza
dei JDO, l'obiettivo è quello di permettere al
programmatore di concentrarsi sulla logica di business,
senza dover manualmente aggiungere nessuna istruzione
di persistenza nelle classi che modellano i business
object.
Questo codice può essere aggiunto alla classe
con differenti modalità, che troviamo nelle specifiche
e che possiamo riassumere con: prima della compilazione,
dopo la compilazione, direttamente nel codice (in questo
caso senza la trasparenza cercata!!!).
Finora tutti i produttori utilizzano la seconda soluzione,
con un tool chiamato enhancer, che modifica (anzi, sostituisce)
la classe originaria con una capace di persistere.
L'enhancer, ed il codice aggiunto alla classe sono diversi
per ciascuna implementazione, ma tutti compatibili,
dato che un requisito fissato dalle specifiche è
la compatibilità binaria tra le classi "enhanced"
dalle diverse implementazioni JDO.
Non sono moltissime le differenze su quest'argomento
tra gli entity CMP e i JDO: in entrambi i casi non è
il programmatore applicativo che si occupa di scrivere
il codice di persistenza, per gli entity di solito lo
aggiunge il container a tempo di deploy, per i jdo le
specifiche propongono un enhancer. L'unica è
forse che gli entity CMP obbligano sempre il programmatore
ad implementare anche un'interfaccia (chiamata EntityBean),
che però nella modalità CMP ha spesso
metodi vuoti o istruzioni di debugging.
Assieme
alla fase di enhancing praticamente tutti i produttori
affiancano un tool per generare la struttura della base
dati su cui far persistere gli oggetti, un file con
istruzioni SLQ-DDL specifico per il database da utilizzare.
Ma se la base dati, come spesso capita sui progetti,
esiste già ? Le specifiche non affrontano l'argomento,
lasciando ai venditori dei tag proprietari per descrivere
il mapping E-R.
Ecco spiegato perché nei tutorial su JDO si preferisce
ricostruire o modificare la base dati ad ogni modifica
delle classi, invece di utilizzarne una già definita.
E' quindi realistico che, in questa situazione, i metadati
aumentino di complessità, a causa di estensioni
non standard, in parte tradendo la promessa di poche
informazioni nei metadati.
Magari in futuro torneremo sull'argomento, ma, come
si dice in questi casi, difficile avere "la botte
piena e la moglie ubriaca.."
Prima di vedere un esempio in figura 1 c'e' uno schema
delle operazioni che seguiremo nel processo di sviluppo:
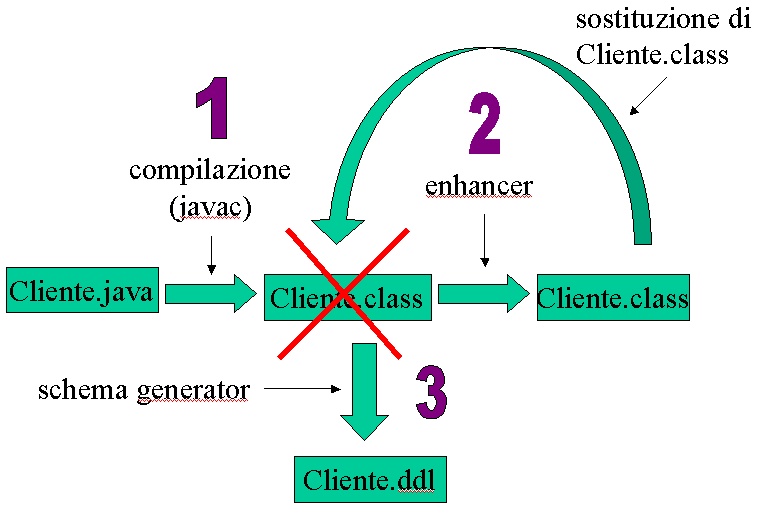
Figura 1
(clicca per ingrandire)
Un
primo esempio
Prendiamo
una normale classe java e cerchiamo di farla persistere.
Cliente ha tre semplici attributi: nome, cognome, data
di nascita.

Figura 2
Prepariamo il file dei metadati che indichi all'enhancer
le classi persistenti.
Ecco Cliente.jdo
<?xml
version="1.0" encoding="UTF-8" ?>
<!DOCTYPE jdo SYSTEM " jdo.dtd">
<jdo>
<package name="it.fpavo.ordini.business.model">
<class name="Cliente" />
</package>
</jdo>
Notate
che non abbiamo specificato field e colonne. Ci siamo
messi nella situazione in cui è l'oggetto java
che controlla la base dati, e non viceversa.
Compiliamo
ora Cliente.java, eseguiamo l'enhancer con Cliente.jdo
e Cliente.class, ed otteniamo il nuovo Client.class
Non abbiamo ancora la base dati e quindi eseguiamo il
tool per generarla (nella implementazione JDO che uso,
è chiamato Schema Generator).
Eccone il contenuto (per HSQLDB):
CREATE
TABLE ifobm_Cliente (
LIDOID BIGINT NOT NULL ,
nome VARCHAR(255) NULL ,
cognome VARCHAR(255) NULL ,
dataNascita DATETIME NULL )
CREATE
UNIQUE INDEX ifobm_Cliente_LIDOID ON ifobm_Cliente (
LIDOID )
CREATE
TABLE LIDOIDTABLE (
LIDOID BIGINT NOT NULL ,
LIDOTYPE VARCHAR(255) NOT NULL )
CREATE
UNIQUE INDEX index_LIDOID ON LIDOIDTABLE ( LIDOID )
CREATE INDEX index_LIDOTYPE ON LIDOIDTABLE ( LIDOTYPE
)
CREATE TABLE LIDOIDMAX ( LIDOLAST BIGINT NOT NULL )
INSERT INTO LIDOIDMAX VALUES( 0 )
Per
ora vogliamo provare il nostro esempio in un ambiente
non managed, e quindi scriviamo una classe TestCliente
che si occupi di inserire un Cliente e di visualizzare
tutti i Clienti del sistema.
Ecco
il codice significativo di TestCliente.java:
//import
necessari
import ordini.business.model.Cliente;
import java.util.Date;
import javax.jdo.PersistenceManagerFactory;
import javax.jdo.PersistenceManager;
import javax.jdo.Transaction;
import javax.jdo.Extent;
import javax.jdo.JDOHelper;
import java.util.Properties;
Properties prop;
// creazione di un nuovo cliente
Cliente cliente = new Cliente("federico","pavo",new
Date());
// l'oggetto prop contiene alcune informazioni obbligatorie
// per poter agganciare la PersistenceManagerFactory
// e di solito riflette il contenuto di un file esterno
PersistenceManagerFactory pmf = JDOHelper.getPersistenceManagerFactory(prop);
PersistenceManager pm = pmf.getPersistenceManager();
Transaction t = pm.currentTransaction();
// dopo aver ottenuto un PersistenceManager ed una Transaction
// possiamo iniziare
t.begin();
pm.makePersistent(cliente);
t.commit();
// il cliente è diventato persistente
// visualizziamo ora i clienti del sistema
t.begin();
Extent clienti = pm.getExtent(Cliente.class, false);
System.out.println("--------------------------------");
System.out.println("Lista clienti: ");
System.out.println("--------------------------------");
Iterator i = clienti.iterator();
while (i.hasNext()) {
System.out.println(i.next());
}
System.out.println("--------------------------------");
System.out.println("Terminata");
System.out.println("--------------------------------");
// rilascio delle risorse
clienti.close(i);
t.commit();
pm.close();
A
questo punto desidero aggiungere solo un paio di precisazioni
ai commenti che trovate nel codice dell'esempio.
L'oggetto più importante è sicuramente
il PersistenceManager, che si occupa di salvare e successivamente
ricercare gli oggetti Cliente, rispettivamente con i
metodi makePersistence() e getExtent(). Gli altri oggetti
coinvolti, PersistenceManagerFactory e Transaction,
sono, se vogliamo di contorno, ed infatti in un ambiente
managed saranno gestiti diversamente, con JNDI e JTA.
L'ambiente che ho utilizzato per i test è composto
da ant, hsqsldb, lido di Libelis, j2sdk1.4.
Non è complesso installare e provare il tutto,
anche se ci sono alcuni dettagli che possono farvi perdere
molto tempo, come ad esempio la necessaria presenza
di alcuni file di configurazione e delle licenze nel
classpath, eccezioni dell'enhancer con descrizione vuota,
i class file non correttamente cancellati.
Per evitare questi problemi e per tanti altri motivi,
nel prossimo articolo presenterò un ambiente
che automatizzerà l'installazione e l'esecuzione
dei test, e comunque, prima di allora, sono raggiungibile
per e-mail.
Conclusioni
Penso
sia difficile e complesso per tutti pronosticare il
futuro di una tecnologia, per via dei tanti fattori
che ne concorrono a determinare il successo o la prematura
scomparsa.
Il nostro approccio con i JDO è stato quello
di discuterla e, nei prossimi articoli, cercare di applicarla
alla piattaforma J2EE in un'architettura simile a quelle
dei progetti più evoluti e moderni.
Ma forse c'e' già un valido motivo per cui i
JDO saranno la tecnologia del futuro……
Roger Sessions, CEO di ObjectWatch, società di
consulenza su .NET e J2EE, il 4 Agosto 1999 su COM+
ed EJB affermava "COM+ is mature. …EJB is
immature and unproven technology"
Lunga vita a JDO, quindi…….
Bibliografia
[1] La home dei JDO - http://java.sun.com/products/jdo/
[2] Il JSR12 dei JDO - http://jcp.org/en/jsr/detail?id=012
[3] Uno dei siti di riferimento - http://www.jdocentral.com
Risorse
Scarica qui i sorgenti presentati
nell'articolo
Federico Pavoncelli si
occupa di architetture software in ambito JAVA, come
consulente e docente per le più importanti società
di software. Può essere contattato all'indirizzo
e-mail fpavoncelli@mokabyte.it
|

