Introduzione:
l’evoluzione
di CMP
Come ormai dovrebbe essere noto la specifica EJB prevede
due tipi di Entity Beans, i BMP ed i CMP. I primi prevedono
un meccanismo di gestione della persistenza a totale
carico del programmatore, il quale deve preoccuparsi
di implementare quei metodi relativi alla gestione del
ciclo di vita del bean: tali metodi verranno invocati
dal container a sua discrezione quando esso ritenga necessario
eseguire un qualche sincronizzazione dello stato del
bean con i dati contenuti nel database sottostante (o
in qualche altro sistema di memorizzazione legacy). In
un BMP il programmatore si deve preoccupare di implementare
cosa debba essere effettuare per gestire lo stato del
bean, mentre l’application server gestisce il quando
ed il come.
Il meccanismo
adottato per i CMP è filosoficamente
differente, dato che in questo caso il container non
solo gestisce il ciclo di vita ma provvede anche a
fornire il codice Java necessario per scrivere e leggere
i dati.
In questo caso tramite un preciso contratto con il
container (volto a definire l’interfaccia del
bean) e l’ausilio di maggiori informazioni inserite
nel file XML di deploy.
Il modello di persistenza di EJB 1.1
Una delle maggiori limitazioni del modello di persistenza
della specifica 1.1 era data dalla impossibilità di
gestire in modo potente e flessibile la persistenza
di entity beans legati da legami relazionali fra
loro.
Riconsiderando per un momento il caso della Community
di MokaByte, più volte presa ad esempio per
gli articoli pubblicati su EJB, si potrebbe pensare
di creare un entity User, rappresentante un utente
iscritto alla comunità virtuale, ed un altro
di nome UserProfile, contenente tutte le informazioni
relative all’utente, come indirizzo abitativo,
dati di fatturazione (nel caso in cui l’utente
voglia procedere all’acquisto di un libro).
In questo caso per ogni User potranno esservi uno o
più UserProfile, dando vita ad una tipica relazione
1-a-n; prendendo spunto dalla terminologia dei database
relazionali, il bean UserProfile viene detto dependent
object. Il legame fra i due oggetti viene realizzato
tramite uno o più campi presenti in uno o in
entrambi gli oggetti del tipo dell’oggetto puntato;
quindi in User vi sarà un campo di tipo UserProfile,
mentre non è detto il viceversa se il legame
non è bidirezionale. La direzione del legame
dipende in genere dalle funzioni che si devono instaurare
fra i due oggetti, tipicamente funzioni di ricerca.
Ad esempio potrebbe essere utile ricavare da un determinato
utente tutti i suoi profili, mentre non è detto
che sia interessante o necessario dover fare il viceversa.
L’argomento è sicuramente molto vasto
e strettamente legato alla teoria dei database relazionali:
una sua completa trattazione esula dagli scopi di questo
articolo, per cui daremo per scontato che il lettore
abbia sufficiente familiarità con tali aspetti.
In EJB 1.1
mentre i campi del bean Entity possono essere facilmente
resi persistenti grazie all’utilizzo
di opportuni campi di una tabella (in genere una tabella
per entity), gli oggetti dipendenti vengono salvati
tramite serializzazione in campi opportuni, ad esempio
di tipo blob.
Questo meccanismo soffre della limitazione di dovere
utilizzare necessariamente oggetti serializzabili,
ed introduce una pesante restrizione sulla possibilità di
interagire con gli oggetti dipendenti. Infatti da un
punto di vista del database tali dati sono semplicemente
array di byte memorizzati in un campo blob (in modo
simile a quanto viene fatto ad esempio con una immagine
o un file mp3) e non è possibile effettuare
nessuna operazione diretta su di loro. Essi non esistono
come entità a se stanti, ma solo come dati fantasma.
Se da un certo punto di vista è corretto imporre
l’esistenza di un CustomerProfile alla presenza
in memoria di un entity User, potrebbe essere utile
per una altra applicazione o per un altro entity, poter
accedere a tali dati senza dover per forza creare un
User che li rappresenti.
Il problema viene reso ancora più fastidioso
in presenza di complesse strutture dati in cui le relazioni
fra oggetti siano più complesse e con cardinalità e
direzionalità tali da non rendere così immediata
la definizione dell’oggetto principale e dei
suoi dipendenti.
La
persistenza per CMP in EJB 2.0: l’Abstract
Persistence Schema
La prima grossa novità introdotta nella versione
2.0 della specifica è la presenza di un nuovo
componente all’interno del container, il persistence
manager, il quale si occupa di gestire tutte le fasi
di sincronizzazione degli entity, lasciando il container
libero di occuparsi di tutto il resto (sicurezza, pooling,
transazioni,…).
Dato che questo oggetto è in un qualche modo
esterno dal nucleo centrale del container, è reso
più semplice per i costruttori di application
server effettuare operazioni di sostituzione o integrazione
di prodotti terze parti (come ad esempio CocoBase o
quello fornito da Pramati).
Da un punto di vista della programmazione la nuova
gestione prevede l’introduzione del cosiddetto
Abstract Persistence Schema, che fondamentalmente serve
per realizzare un contratto ben preciso fra il bean
ed il persistence manager volto a migliorare la possibilità di
personalizzare il comportamento del CMP. Adesso è infatti
possibile realizzare relazioni più complesse
e gestire in modo più semplice e portabile le
varie relazioni fra bean.
Il nuovo contratto bean-persistence manager è realizzato
in pratica da un nuovo set di tag XML contenuti all’interno
del deployment descriptor e da una serie di convenzioni
nella stesura del codice Java. Un CMP in EJB 2.0 è rappresentato
da una classe astratta i cui campi di persistenza e
di relazione sono definiti solo dai metodi accessori
e mutatori, i quali devono poi avere corrispondenza
nella definizione nel file di deploy.
La sottoclasse concreta viene generata al momento del
deploy dal persistence manager, che si preoccupa anche
di creare i relativi dependings objects. In questa
fase vengono generati anche le implementazioni dei
metodi di accesso ai campi degli entity
NOTA:
spesso
i metodi mutatori sono utilizzati per effettuare
un qualche tipo di controllo sintattico sui valori
inseriti nel bean, così come gli accessori
permettono la conversione di valori in lettura. In
questo caso, dato che l’implementazione dei
vari setXXX()/getXXX() è lasciata al container,
non è possibile intervenire in alcun modo
ne sulla scrittura che sulla lettura. In [ejbdesgin]
viene proposta una soluzione a questo problema tramite
un noto pattern: in pratica si tratta di creare una
interfaccia aggiuntiva al bean e di accedere ai campi
di persistenza non tramite metodi setXXX()/getXXX()
sui quali non è possibile intervenire, ma
piuttosto tramite appositi setXXXField()/getXXXField()
i quali potranno effettuare tutte le operazioni necessarie
sui valori in entrata/uscita e poi invocare i metodi
accessori o mutatori.
Così come per i campi di persistenza, l’APS
impone che anche i campi di relazione siano acceduti
tramite metodi get/set i cui parametri di input e di
output devono fedelmente ricalcare il tipo di realazione.
Per una relazione semplice (uno-a-xxx) dovrà essere
utilizzato un oggetto del tipo del dipendente, mentre
per relazioni molteplici (molti-a-xxx) si dovranno
utilizzare collezioni come l’oggetto Collection
o List.
Per ogni tag XML <ejb-relation> vi è una
coppia di metodi set/get. La specifica impone che tutti
gli entity che partecipano alla stessa relazione debbano
essere definiti all’interno del medesimo deployment
descriptor.
Un aspetto che non appare immediatamente evidente è il
ruolo del client nei confronti dei vari dependent objects.
Per prima cosa un entity non dovrebbe contenere mai
della business logic ma solo e sempre dati di vario
tipo in modo da mappare in logica OO il dominio dei
dati. Quindi un client dovrebbe sempre interagire con
session beans (meglio se la parte server è quindi
organizzata secondo un qualche pattern raggruppativo
come il Session Façade o il Business Delegate).
Oltre a questo la stessa struttura APS ha come scopo
quello di gestire ed ordinare una serie di relazioni
di vario tipo esistenti fra oggetti del dominio dei
dati. In APS è quindi ancora più forte
la predominanza dei dati sulla business logic e quindi
a maggior ragione un client non dovrebbe accedere ai
dependent obejects.
In analogia con quanto avviene con il mondo dei database
relazionali, la rimozione di un entity partecipante
ad una relazione con altri come elemento centrale,
provoca la rimozione anche dei dependent objects. Anche
per questo, per non alterare l’integrità delle
relazioni, il client non dovrebbe accedere agli oggetti
dipendenti.
Infine, a conferma o come ultima conseguenza delle
indicazioni di cui sopra, la specifica impone che i
campi di relazione debbano sempre reference delle interfacce
locali degli oggetti dipendenti. Questo elimina ogni
dubbio, trattandosi di reference locali, non possono
essere passati ai client remoti.
Infine da tenere presente che per mantenere la retro-compatibilità,
gli application server EJB 2.0 dovranno continuare
a fornire il supporto con il modello dei CMP 1.1, anche
se i due modelli sono incompatibili fra loro. Il programmatore
potrà quindi scegliere quale soluzione adottare
ma non potrà utilizzare entrambi i modelli contemporaneamente
all’interno della stessa applicazione.
Un esempio
Di seguito sono riportati alcuni pezzi di codice
XML e Java relativi alla relazione uno-a-molti
che si forma
fra un CommunityUser della comunità virtuale
di MokaByte ed i sui n profili di cliente del negozio
ondine: in questo caso i vari acquisti potrebbero essere
inviati, spediti o fatturati a soggetti differenti,
ma facenti capo allo stesso utente registrato; non è detto
che la situazione sia reale o calzante perfettamente
ad uno scenario reale, ma è sufficientemente
plausibile per poter analizzare un po’ di
codice.
Ovviamente per brevità non tutto il codice XML
e Java è qui riportato, ma soltanto i passaggi
più interessanti.
La struttura delle classi che si viene a formare è riportata
nel diagramma della figura 1 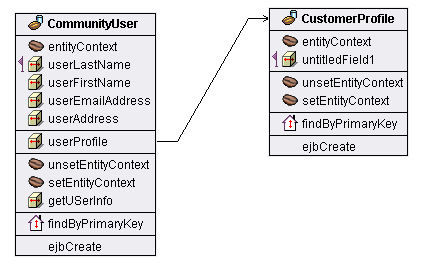
Figura
1 – diagramma di classi rappresentante
il legame di relazione
fra i due entity bean
Di seguito è riportato
il codice XML del deployment descriptor: si noti
che per motivi di spazio nella
fase di impaginazione i nomi completi delle classi
sono stati ridotti dai loro originali che contengono
anche i nomi dei packages com.mokabyte.mokabook.ejb.CustomerProfileHome
<
?xml version="1.0" encoding="UTF-8"?>
<
!DOCTYPE ejb-jar PUBLIC "-//Sun Microsystems,
Inc.//DTD Enterprise JavaBeans 2.0//EN"
"
http://java.sun.com/dtd/ejb-jar_2_0.dtd">
<ejb-jar>
<enterprise-beans>
<entity>
<display-name>CommunityUser</display-name>
<ejb-name>CommunityUser</ejb-name>
<local-home> CommunityUserLocalHome</local-home>
<local>CommunityUserLocal</local>
<ejb-class>CommunityUserBean</ejb-class>
<persistence-type>Container</persistence-type>
<prim-key-class>java.lang.String</prim-key-class>
<reentrant>False</reentrant>
<cmp-version>2.x</cmp-version>
<abstract-schema-name>CommunityUser</abstract-schema-name>
<cmp-field>
<field-name>userId</field-name>
</cmp-field>
<primkey-field>userId</primkey-field>
</entity>
Qui finisce
la definizione del primo entity beans: si noti la
presenza del tag <cmp-version> che
indica la versione del CMP 2.0.
Il secondo bean, il CustomerProfile, è definito
dal seguente codice XML
<entity>
<display-name>CustomerProfile</display-name>
<ejb-name>CustomerProfile</ejb-name>
<local-home>CustomerProfileHome</local-home>
<local>CustomerProfile</local>
<ejb-class>CustomerProfileBean</ejb-class>
<persistence-type>Container</persistence-type>
<prim-key-class>java.lang.String</prim-key-class>
<reentrant>False</reentrant>
<cmp-version>2.x</cmp-version>
<abstract-schema-name>CustomerProfile</abstract-schema-name>
<cmp-field>
<field-name>customerId</field-name>
</cmp-field>
<primkey-field>customerId</primkey-field>
</entity>
</enterprise-beans>
a questo punto si trovano le sezioni relative alla
definizione delle relazioni fra i due beans.
Il tag che definisce questa parte è <relationships>,
che contiene almeno una coppia di sezioni <ejb-relation>.
<relationships>
<ejb-relation>
<ejb-relation-name>communityUser-customerProfile</ejb-relation-name>
<ejb-relationship-role>
<description>communityUser</description>
<ejb-relationship-role-name>
CommunityUserRelationshipRole
</ejb-relationship-role-name>
<multiplicity>One</multiplicity>
<relationship-role-source>
<description>communityUser</description>
<ejb-name>CommunityUser</ejb-name>
</relationship-role-source>
<cmr-field>
<description>customerProfile</description>
<cmr-field-name>customerProfile</cmr-field-name>
<cmr-field-type>java.util.Collection</cmr-field-type>
</cmr-field>
</ejb-relationship-role>
Questa prima
parte definisce le caratteristiche della relazione
da parte dell’oggetto CommunityUser.
La relazione è identificata da un nome (tag <ejb-relation-name>),
e da una serie di caratteristiche dell’oggetto
vi partecipa, specificato dal tag <ejb-relationship-role>:
in questo caso devono essere specificate la molteplicità (tag <multiplicity>),
l’oggetto che rappresenta il ruolo (tag <relationship-role-source>)
ed il campo utilizzato per realizzare la relazione
(tag <cmr-field>).
La definizione del secondo entity bean che partecipa
alla relazione è molto simile (cambia solamente
la molteplicità)
<ejb-relationship-role>
<description>customerProfile</description>
<ejb-relationship-role-name>
CustomerProfileRelationshipRole
</ejb-relationship-role-name>
<multiplicity>Many</multiplicity>
<relationship-role-source>
<description>customerProfile</description>
<ejb-name>CustomerProfile</ejb-name>
</relationship-role-source>
</ejb-relationship-role>
</ejb-relation>
</relationships>
Il file
XML a questo punto prosegue con la parte dedicata
alla definizione della transazionalità dei vari
metodi. Tralasceremo questa parte dato che non è molto
interessanti ai fini della trattazione su CMP.
Il codice
Java presente nelle classi astratte che permette
il mantenimento della relazione è dato
dai seguenti metodi in CommunityUser
public abstract void setCustomerProfile(java.util.Collection
customerProfile);
public abstract java.util.Collection getCustomerProfile();
e, poiché la relazione è bidirezionale,
dai corrispondenti in CustomerProfile
public abstract void setCustomerId(java.lang.String
customerId);
public abstract java.lang.String getCustomerId();
In accordo con quanto accennato in precedenza, si
noti che, essendo il tipo di legame di tipo uno-a-molti,
i metodi accessori di CommunityUser utilizzano come
parametro un oggetto di tipo Collection.
EJB Query Language: EJBQL
Gli entity di tipo CMP hanno l’importante caratteristica
di poter astrarre completamente il processo di sincronizzazione
dei dati con il sistema sottostante, grazie ad una
raffinata tecnica di definizione del mapping object
relational. La specifica 2.0 introduce un altro potente
strumento che in tal senso permette di rendere ancor
più standard il meccanismo di definizione del
comportamento di un CMP.
Come noto infatti già da tempo era disponibile
un sistema, basato su file di script, atto a definire
in modo astratto, il comportamento dei metodi relativi
al ciclo di vita. Ad esempio tramite sintassi di vario
tipo, era possibile definire il comportamento dei vari
metodi di ricerca all’interno del database relazionale
o a oggetti.
La grossa limitazione era che tali script, pur ispirandosi
in qualche modo all’SQL, erano nella maggior
parte dei casi basati su una grammatica proprietaria,
limitando fortemente la portabilità della applicazione
finita. Partendo dal file .jar contenente entity CMP
non si poteva farne il deploy in modo indolore senza
prima ricontrollare che il container fosse in grado
di comprendere senza problemi il linguaggio SQL-like.
Sun per questo motivo ha definito da specifica un linguaggio
simil SQL, detto EJB-QL: esso definisce come il persistence
manager debba implementare i metodi di ricerca definiti
nella interfaccia home del bean.
Basato su SQL-92 esso può essere compilato automaticamente
rendendo il deploy del bean e della applicazione complessiva
molto più portabile.
I vari statements EJBQL sono definiti nel deployment
descriptor del bean, tramite una ben precisa sintassi
XML.
Riconsiderando l’entity CommunityUser di cui
sopra, potrebbero essere definiti i seguenti metodi
di ricerca nella home interface:
public CommunityRemote findByPrimaryKey(String uid)
throws RemoteException, CreateException;
public CommunityRemote findByEMail(String uid) throws
RemoteException, CreateException;
public CommunityRemote findByPassword(String uid) throws
RemoteException, CreateException;
In questo
caso la ricerca chiave primaria corrisponde a ricercare
un utente in base al suo id, ricerca necessaria
per implementare il meccanismo di login utente, unitamente
alla ricerca per password; la ricerca per email invece
si rende necessaria per implementare il meccanismo
di password recovery (invio di uid e passw nella casella
di posta dell’utente che li abbia dimenticati).
Dato che la chiave primaria è un dato ben specificato
al momento della creazione del bean, non è necessario
insegnare al container come realizzare tale ricerca:
si tratta di una banale select sulla tabella relativa
al bean con filtro sulla chiave della tabella.
Le altre ricerche invece non sono invece determinabili
in modo automatico, per cui si deve procedere alla
definizione del codice EJBQL necessario. Ad esempio
la ricerca per email potrebbe essere definita tramite
qualcosa del tipo
FROM user WHERE user.password=?1
In questo
caso la clausola Select non è necessaria,
dato che la ricerca verrà effettuata sulla tabella
indicata restituendo sempre il tipo corretto (l’interfaccia
remota del bean) o per ricerche multiple una Collection
contenente i reference remoti corrispondenti alla ricerca.
Utilizzando il tool EJB di sviluppo preferito si potrà inserire
il codice di query che verrà inserito nel file
di deploy nella forma
<query>
<query-method>
<method-name>findByPassword</method-name>
<method-params>
<method-param>java.lang.String</method-param>
</method-params>
</query-method>
<ejb-ql>FROM user where user.password=?1</ejb-ql>
< /query>
Conclusione
Senza scendere nei dettagli della programmazione CMP,
abbiamo visto in modo piuttosto completo i nuovi strumenti
messi a disposizione della specifica 2.0 di EJB per
la gestione dei componenti CMP.
Anche se da più parti questo tipo di entity
(e gli entity in generale) sono considerati molto potenti
ma altrettanto pericolosi per i loro effetti dannosi
sulle performance e sull’occupazione di memoria,
le nuove specifiche consentono di migliorare notevolmente
l’astrazione del processo di definizione e quindi
consentono una migliore portabilità delle applicazioni
al variare dell’application server ma anche del
database sottostante.
Per coloro che non hanno nelle performance il loro
principale obiettivo, si tratta sicuramente di una
interessantissima nuova funzionalità.
Bibliografia
[CMP2.0] – “EJB 2.0 – il CMP 2.0
e l’Abstract Persistent Model” di Giovanni
Puliti, MokaByte 70, gennaio 2003, www.mokabyte.it/2003/01
[ejbspec] – “EJB 2.0 specification”,
java.sun.com/products/ejb/
[ejb] – “Enterprise Java Beans, sviluppare
componenti Enterprise Java”, di R. Monson-Hefel,
Edizioni Hops-O’Reilly.
[ejbdesgin] – “EJB Design Pattern” di
Floy Marinescu, ed. Wiley |


