|
Introduzione
L'idea di "saturare" una macchina con più
di un'istanza dello stesso server software, anzichè
duplicare l'hardware e far girare ogni istanza su una
macchina dedicata, potrà a qualcuno sembrare
strana; tuttavia, esistono delle ragioni ben fondate
per le quali spesso si adotta questa tecnica.
Come
già accennato in precedenza, uno scopo può
essere quello di massimizzare l'utilizzo dell'hardware
a disposizione. L'hardware costa, specialmente i sistemi
server hardware, e talvolta non si hanno le risorse
economiche per affrontare l'acquisto di un nuovo elaboratore.
Il discorso è ancora più azzeccato se
si considera che ormai molti software si pagano in base
al numero di CPU, per cui mantenere basso il numero
delle stesse (pur aumentando le istanze in esecuzione
parallela) può essere conveniente. Inoltre, oramai
le CPU hanno raggiunto potenze di calcolo assolutamente
impressionanti, spesso sovradimensionate, e sono benissimo
in grado di servire più istanze contemporanee
allo stesso tempo.
Sempre
rimanendo nel discorso CPU, usufruire di istanze multiple
consente di sfruttare al meglio anche gli elaboratori
multiprocessore, magari dedicando una CPU ad ogni istanza.
Infine,
non dimentichiamo le situazioni tipiche che devono affrontare
i fornitori di servizi di Hosting e Server Condivisi
(o Virtuali); per costoro, un rapporto 1:1 tra clienti
e macchine dedicate è assolutamente impraticabile.
JBoss
clustering
JBoss è un application server che supporta il
clustering a partire dalla versione 3.0. Per supporto
al clustering si intende il fatto che le varie istanze
in esecuzione (che siano su macchine diverse o sulla
stessa macchina) sono in grado di colloquiare "dietro
le quinte" della nostra applicazione enterprise
per scambiarsi informazioni riguardanti lo stato della
stessa. Ciò è necessario, poiché
per l'utente il cluster è visto nel suo complesso
come un unico elaboratore servente, e quindi eventuali
modifiche allo stato dell'applicazione che avvengono
in un istanza devono essere trasmesse (o condivise)
su tutti i nodi del cluster. Un esempio può essere
lo stato dei Session Bean Stateful, degli Entity Bean,
delle cache.
Tutto questo lavoro, deve essere gestito dal motore
di clustering dell'application server in coppia ad un
dispositivo di bilanciamento del carico e risultare
trasparente ai programmatori.
Le
versioni 2.4.x di JBoss, purtroppo, non supportano il
clustering nel senso appena descritto; è possibile
tuttavia sfruttare almeno il meccanismo delle istanze
multiple, che ovviamente non saranno sincronizzate.
Setup
di istanze multiple in JBoss 2.4.x
Per
eseguire più istanze di JBoss 2.4.x nella stessa
macchina, è sufficiente garantire che non ci
siano istanze che condividano le stesse porte TCP. JBoss
utilizza infatti diverse porte per consentire l'accesso
a servizi quali ad esempio il naming (JNDI, porta 1099),
o la console JMX (8082). Ogni porta deve risultare ad
uso esclusivo di una sola istanza. Pertanto, la strategia
adottata in questo esempio sarà quella di individuare
tutte le porte utilizzate e garantire l'univocità
per ogni istanza.
E'
necessario inoltre anche un settaggio diverso per il
database Hypersonic che JBoss utilizza internamente
per salvare il suo stato e le informazioni del motore
di persistenza degli oggetti CMP JAWS; in caso contrario,
le istanze condividono il database, dando luogo a probabili
e sgradite interferenze. Nel caso, è possibile
anche sostituire il database Hypersonic con un altro
database di nostra scelta.
La
cartella di installazione di JBoss sarà di seguito
riferita col nome JBOSS_HOME.
In questo esempio, saranno create due istanze di JBoss,
denominate "default" e "clone".
Tutti i problemi strettamente applicativi (es: duplicazione
di pool di connessioni, risorse) non sono oggetto del
presente documento, anche se è doveroso segnalare
che devono essere assolutamente presi in considerazione.
Procedura
Creare
una cartella clone dentro JBOSS_HOME\conf e copiarci
dentro tutto il contenuto della cartella JBOSS_HOME\conf\default.
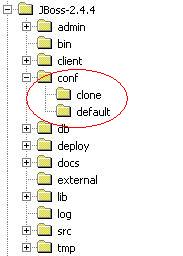
Figura 1 - Configurazione delle cartelle
In
questo modo la configurazione del clone è identica
a quella dell'istanza di default.
Vediamo
ora dove e come modificare le porte TCP utilizzate.
Nell'esempio, aggiungiamo la costante 10000 ad ogni
numero di porta utilizzato dall'istanza clone.
Aprire
il file JBOSS_HOME\conf\clone\jboss.jcml con un editor
di testo:
· Nella sezione Classloading, modificare la porta
8083 del servizio WebServer in 18083.
· Nella sezione JNDI, modificare la porta 1099
del servizio Naming in 11099.
· Nella sezione JDBC, modificare la porta 1476
del servizio Hypersonic in 11476.
· Sempre nella stessa sezione, modificare anche
la riga
<attribute
name="URL">jdbc:hsqldb:hsql://localhost:1476</attribute>
in
<attribute
name="URL">jdbc:hsqldb:hsql://localhost:11476</attribute>
·
Nella sezione JMX Adaptors, modificare la porta 8082
del servizio html in 11802.
Veniamo
ora ai settaggi relativi agli EJB.
Aprire il file JBOSS_HOME\conf\clone\standardjboss.xml
con un editor di testo:
· Cambiare ogni occorrenza dell'elemento
...
<container-invoker-conf>
<RMIObjectPort>4444</RMIObjectPort>
...
in
...
<container-invoker-conf>
<RMIObjectPort>14444</RMIObjectPort>
...
Quest'ultima
modifica è da effettuarsi anche in tutti i deployment
descriptor proprietari di JBoss (jboss.xml) contenuti
nei JAR delle applicazioni, nel caso siano stati effettuati
dei settaggi a grana fine per qualche EJB.
Esecuzione
delle istanze
Le istanze vanno eseguite separatamente, utilizzando
il comando run (run.bat in Windows e run.sh in Linux)
contenuto nella cartella JBOSS_HOME\bin.
Il nome dell'istanza va specificato come parametro al
momento del lancio. Ad esempio:
$:>
run clone
oppure,
per l'istanza di default
$:>
run
Sì
può verificare l'istanza in esecuzione controllando
semplicemente l'output di JBoss, come in figura:
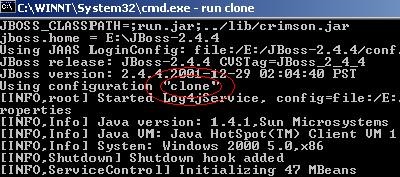
Figura 2 - Startup dell'istanza clone
Utilizzo
delle istanze
Una volta che le istanze sono in esecuzione, possono
essere liberamente utilizzate dai client nei modi consueti.
Si deve solamente aver cura di riferirsi ad ogni istanza
attraverso le porte corrette. Ad esempio, consideriamo
il lookup a degli EJB. Per l'istanza di default avremo:
java.util.Properties
defaultEnv= new java.util.Properties();
defaultEnv.put("java.naming.factory.initial",
"org.jnp.interfaces.NamingContextFactory");
//Per
l'istanza di default, JNDI è sulla porta 1099
defaultEnv.put("java.naming.provider.url",
"jnp://localhost:1099");
defaultEnv.put("java.naming.factory.url.pkgs",
"org.jboss.naming:org.jnp.interfaces");
Context
defaultCtx = new InitialContext(defaultEnv);
Object pippoRef = ctx.lookup("ejb/PippoBean");
Mentre
per l'istanza clone:
java.util.Properties
cloneEnv= new java.util.Properties();
cloneEnv.put("java.naming.factory.initial",
"org.jnp.interfaces.NamingContextFactory");
//Per
l'istanza clone, JNDI è sulla porta 11099
cloneEnv.put("java.naming.provider.url",
"jnp://localhost:11099");
cloneEnv.put("java.naming.factory.url.pkgs",
"org.jboss.naming:org.jnp.interfaces");
Context
cloneCtx = new InitialContext(cloneEnv);
Object plutoRef = ctx.lookup("ejb/PlutoBean");
Varianti
La procedura sopradescritta consente di eseguire più
istanze mantenendo unica la cartella d'installazione
e di deploy. Questo implica che all'interno di ogni
istanza saranno in esecuzione le stesse applicazioni
delle altre istanze (ovviamente in JVM separate).
Ciò costituisce una limitazione nel caso in cui
si voglia destinare un'istanza all'applicazione X e
un'altra all'applicazione Y. Per differenziare le applicazioni
a seconda dell'istanza, si propongono due varianti:
Variante
1: Installazione multipla
La soluzione più banale è quella di duplicare
le installazioni di JBoss. Ferma restando la stessa
macchina fisica, si avranno dunque più cartelle
d'installazione. Rimane obbligatoria, comunque, la procedura
di cambiamento di numerazione delle porte TCP, anche
se non è più necessario duplicare la cartella
JBOSS_HOME\conf\default, poiché ogni installazione
avrà la sua.
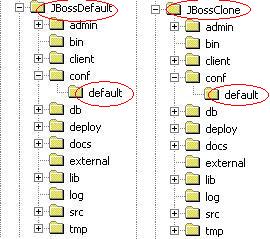
Figura 3 - Installazione duplicata
Variante
2: Separazione delle cartelle di deploy
E' possibile specificare nel file JBOSS_HOME\conf\nomeistanza\jboss.jcml
il percorso della cartella di deploy, nella sezione
Auto deployment:
…
<attribute name="URLs">../deploy,../deploy/lib</attribute>
…
In
questo modo, ogni istanza può puntare ad una
propria cartella di deploy, come visibile in figura:
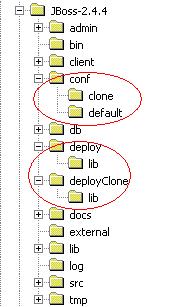
Figura 4 - Separazione delle cartelle di Deploy>>
Conclusioni
Eseguire più istanze di JBoss sulla stessa macchina
comporta senz'altro il vantaggio di non duplicare le
installazioni su macchine diverse, realizzando comunque
un qualcosa che assume sempre più le sembianze
di un cluster (con tutti i distinguo del caso) e massimizzando
l'utilizzo delle risorse a disposizione. Come già
citato, questa tecnica risolve alcuni problemi presentando
costi veramente bassi.
Tuttavia, può comportare anche vari svantaggi;
dato che ogni istanza è eseguita su una JVM separata,
necessita di una quota di RAM e CPU indipendentemente
dalle altre. Abusando di tali risorse in maniera indiscriminata,
un sistema potrebbe divenire presto inutilizzabile.
Pur non essendo recentissima, l'architettura 2.4.x di
JBoss si conferma un prodotto assolutamente valido,
in grado di fornire un utilissimo supporto in fase di
sviluppo e, perchè no, anche in fase di produzione
se i requisiti lo consentono. La completa configurabilità,
modularità e l'essere open source colloca ormai
JBoss a livello degli application server commerciali.
Bibliografia
[1] JBoss Group, LLC - "JBoss 2.4.x documentation",
http://jboss.sourceforge.net/doc-24/, 2003
[2] Bill Burke - "Clustering with JBoss/Jetty",
http://www.onjava.com/pub/a/onjava/2001/09/18/jboss.html
, 2001
[3] Renè Muller - "Hands-on Guide to JBoss",
University of Applied Sciences Northwestern Switzerland,
2002
Fabrizio
Gianneschi, si occupa di tecnologia Java, J2EE e
metodologia XP presso Atlantis S.p.A - La Città
dell'Innovazione (CA). Svolge attività di formazione,
progetto e sviluppo di applicazioni web, content management,
e-business e progetti di Ricerca relativi alla Pubblica
Amministrazione. Nel (poco) tempo libero coordina le
attività del Java User Group Sardegna. È
laureato in Ingegneria Informatica presso il Politecnico
di Torino ed è in possesso delle certificazioni
SUN Certified Programmer for Java 2 e SUN Certified
Web Component Developer for J2EE.
|

