|
Il
contributo di Exolab è quindi importante, ma
si ha la sensazione che sia meno riconosciuto tra gli
sviluppatori, rispetto ad altri progetti che hanno successo
maggiore, come Jakarta e JBoss. Tra le altre cose, Castor
JDO (è questo il nome completo del framework
che verrà descritto più avanti) è
stato oggetto di qualche critica da parte della comunità
degli sviluppatori, in un breve pezzo pubblicato su
O'Reilly Net [1]. Quanto affermato è sicuramente
vero, e la critica è che il nome JDO può
trarre in inganno il potenziale utente, in quanto è
il nome della tecnologia di SUN (Java Data Object) che
affronta la stessa problematica dei framework di persistenza:
la memorizzazione ed il recupero trasparente dello stato
degli oggetti, senza la necessità di codice invasivo.
Il fatto è che Castor utilizza API proprie e
non compatibili con JDO di SUN: Castor JDO è
dunque diverso da Sun JDO.
Castor
Mokatrack
In realtà Castor è molto di più
di un framework di persistenza, perchè supporta
anche una infrastruttura di binding con XML: consente
infatti di memorizzare lo stato di un oggetto come documento
XML e viceversa. Ricorda qualche cosa? E' la tecnologia
JAXB di SUN, che ha scopi similari.
Il vantaggio però, è che è possibile
centralizzare le informazioni di mappatura (mapping)
delle classi Java a flussi XML ed a tabelle di database
in un unico descrittore, semplificando il lavoro nel
caso siano necessarie entrambe le funzionalità.
Inoltre Castor DAX offre una mappatura tra classi Java
e registri LDAP.
Nel nostro caso ci limiteremo ad affrontare la persistenza
su database, modificando il banale progetto Mokatrack
in modo da utilizzare Castor per la persistenza; il
modello di dominio, per chi non lo ricordasse nei particolari,
è rappresentato in figura 1. Come si noterà,
le modifiche non saranno eccessive, perchè questo
framework, come Hibernate [2] si basa fortemente sulla
persistenza, evitando il più possibile di essere
invasivo nel codice, anche se per accedere a qualche
funzionalità avanzata, è necessario implementare
interfacce proprietarie.
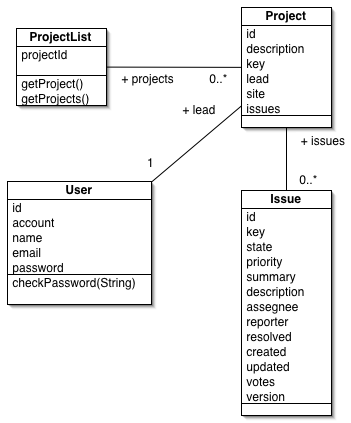
Figura 1 - Dominio di Mokatrack
Dove
tutto inizia
Come Hibernate, Castor supporta una serie di database
diversi, ognuno con il proprio dialetto specifico; i
database supportati da Castor 1.0 sono riassunti in
tabella 1.
Tabella
1 - Database supportati
| Codice |
Tipo |
| db2 |
DB/2 |
| generic
Generic |
JDBC
support |
| hsql
|
Hypersonic
SQL |
| informix
|
Informix |
| instantdb
|
InstantDB |
| interbase
|
Interbase |
| mysql
|
MySQL |
| oracle |
Oracle
7 - Oracle 9i |
| postgresql
|
PostgreSQL
7.1 |
| sapdb
|
SAP
DB |
| sql-server
|
Microsoft
SQL Server |
| sybase
|
Sybase
11 |
L'indicazione
del dialetto da utilizzare viene inserita all'interno
di un file XML di configurazione, il cui nome dovrà
essere indicato nel codice (in Castor tutta la configurazione
è in XML, contrariamente ad Hibernate dove queste
informazioni sono contenute in un file .properties).
Quello qui utilizzato è il seguente:
<!DOCTYPE
databases PUBLIC "-//EXOLAB/Castor JDO Configuration
DTD Version 1.0//EN"
"http://castor.exolab.org/jdo-conf.dtd">
<database
name="mokatrack" engine="mysql"
>
<driver url="jdbc:mysql://localhost/mokatrack"
class-name="org.gjt.mm.mysql.Driver">
<param name="user" value="root"
/>
<param name="password" value="mysql"
/>
</driver>
<mapping
href="mokatrack/mapping.xml" />
</database>
L'attributo
name dell'elemento database indica il nome del database
da referenziare nel codice, mente l'elemento engine
specifica il tipo di database; l'elemento driver specifica
il driver da utilizzare; in questo caso il db utilizzato
è MySQL, dunque la struttura dell'elemento driver
assume questa specifica forma. Altri database potrebbero
richiedere altri parametri di configurazione. L'elemento
mapping specifica un link al file di mappatura delle
singole classi; visto che nel nostro caso siamo all'interno
della Web Application mokatrack, il link include il
percorso "mokatrack/".
Nel file mapping.xml vengono definite le classi mappate
(in database.xml si possono volendo includere più
file, suddividendo quindi il contenuto di mapping.xml
in archivi diversi). La classe User è cos"
configurata:
<class
name="com.mokabyte.tracking.model.User" identity="id">
<description>Definizione utente</description>
<map-to table="users" />
<field name="id" type="long">
<sql name="id" type="integer"
/>
</field>
<field name="account" type="string">
<sql name="account" type="char"
/>
</field>
<field name="password" type="string">
<sql name="password" type="char"
/>
</field>
<field name="name" type="string">
<sql name="name" type="char"
/>
</field>
<field name="email" type="string">
<sql name="email" type="char"
/>
</field>
</class>
L'elemento
class contiene due attributi: name identifica il nome
completo della classe in oggetto, mentre identity indica
quale campo implementa la chiave primaria della tabella.
Oltre ad una descrizione opzionale, contenuta nell'elemento
description, è necessario indicare la tabella
associata a questo oggetto, attraverso l'elemento map-to
(in questo caso è users). Si noti che viene riutilizzato
lo schema introdotto in [2], e che questo non viene
minimamente variato; uno dei vantaggi dei framework
di persistenza come Hibernate, Castor od altri è
proprio quello di potersi adattare senza necessità
di modifica a modelli di dominio e schemi di database
già esistenti.
Conclude la mappatura della classe l'insieme di elementi
field, che specificano nome e tipo dell'attributo della
classe; Castor supporta due tipologie di attributi:
quelli pubblici e quelli acceduti tramite i getter/setter.
In generale nella OOP è sconsigliata la realizzazione
di modelli che utilizzino attributi pubblici, ma se
si vuole perseguire comunque questa strada, è
possibile farlo, impostando l'attributo directed a true.
Relazioni
tra tabelle
Per configurare una relazione di tipo 1:N oppure N:1
(di lookup) è sufficiente fare uso degli elementi
field e sql in modo differente, eventualmente specificando
attributi aggiuntivi. Si consideri la configurazione
della classe Project, che ha un campo di lookup sulla
tabella utenti (Team Leader) ed una serie di Issue (relazione
1:N). Le configurazione della classe e dei suoi campi
standard è:
<class
name="com.mokabyte.tracking.model.Project"
identity="id">
<description>Definizione progetto</description>
<map-to table="projects" />
<field name="id" type="long">
<sql name="id" type="integer"
/>
</field>
<field name="key" type="string">
<sql name="ukey" type="char"
/>
</field>
<field name="description" type="string">
<sql name="description" type="char"
/>
</field>
<field name="site" type="string">
<sql name="site" type="char"
/>
</field>
La
prima relazione (sugli User) viene configurata specificando
nell'attributo type il nome della classe da utilizzare:
<field
name="lead" type="com.mokabyte.tracking.model.User">
<sql name="id_lead" />
</field>
Nell'elemento
sql viene specificata la colonna della tabella projects
che contiene la chiave univoca della tabella users.
Per creare una relazione 1:N, invece, è necessario
specificare qualche informazione in più. Per
prima cosa è sempre indispensabile indicare il
tipo della classe nell'attributo type, e poi è
necessario specificare la tipologia di associazione
(array, vector, hashtable, collection, set e map) nell'attributo
collection:
<field
name="issues" type="com.mokabyte.tracking.model.Issue"
required="true" collection="collection">
<sql many-key="id_project" many-table="issues"
/>
</field>
</class>
Nell'elemento
sql è poi necessario specificare, non più
il name del campo che contiene la relazione, ma i due
attributi many-key e many-table. Il primo indica la
colonna nella tabella di destinazione che contiene la
chiave primaria dell'entità che si sta configurando
(in questo caso Project). In many-table viene indicata
la tabella che contiene i record figli.
Pariteticamente, nell'entità Issue, è
necessario configurare opportunamente le relazioni al
contrario, in modo da completare l'impostazione delle
relazioni. Ad esempio, la colonna id_project nella tabella
issues viene correttamente indicata come di tipo Project:
da un oggetto Issue si può infatti ottenere il
progetto conoscendo il valore della sua chiave univoca,
memorizzata appunto in id_project:
<class
name="com.mokabyte.tracking.model.Issue" identity="id">
<description>Definizione segnalazione</description>
<map-to table="issues" />
<field name="id" type="long">
<sql name="id" type="integer"
/>
</field>
<field name="project" type="com.mokabyte.tracking.model.Project">
<sql name="id_project" />
</field>
Anche
i campi assegnee e reporter vengono correttamente indicati
come di tipo User:
<field
name="assegnee" type="com.mokabyte.tracking.model.User">
<sql name="assegnee" />
</field>
<field name="reporter" type="com.mokabyte.tracking.model.User">
<sql name="reporter" />
</field>
Accesso
dalla persistenza
Le API di Castor sono molto differenti rispetto a quelle
di Hibernate, anche se il meccasimo di funzionamento
è molto simile. La caratteristica particolare
di Castor è quella di fornire solo una classe
concreta da cui inizia tutto: JDO. Le rimanenti entità
documentate nel Javadoc del framework non sono altro
che interfacce: Exolab nasconde la reale implementazione
di Castor all'interno di implementazioni di queste.
La classe JDO è dunque il punto di inizio di
ogni interazione con la persistenza di Castor; dalla
classe ProjectList, opportunamente revisitata per utilizzare
Castor, ecco il metodo createSession(), che ritorna
in realtà un oggetto Database, che consente,
in modo transazionale, l'accesso agli oggetti persistenti.
Le operazioni principali che si dovranno fare per ottenere
una connessione sono:
l'instanziazione di JDO;
l'impostazione del nome di database (in precedenza l'abbiamo
inserito nel file database.xml);
l'impostazione del file di configurazione (essendo mokatrack
una web application, nel codice è stato specificato
semplicemente l'URL a cui viene esposto il file database.xml);
il class loader da utilizzare.
private
Database createSession()
throws DatabaseNotFoundException, PersistenceException
{
if(
jdo == null ) {
jdo
= new JDO();
jdo.setDatabaseName("mokatrack");
jdo.setConfiguration("http://127.0.0.1:8080/mokatrack/database.xml");
jdo.setClassLoader(
getClass().getClassLoader() );
}
Database
database = jdo.getDatabase();
return
database;
}
A
questo punto è possibile ottenere l'elenco dei
progetti, utilizzando una query OQL (Object Query Language),
un linguaggio di query simile ad SQL ma legato agli
oggetti e simile a HQL (Hibernate Query Language). Nella
versione corrente di Castor l'implementazione non è
completa, ma è sempre possibile impostare alcune
query di base (non sono implementate ad esempio le query
annidate). In particolare, l'elenco dei progetti è
ottenibile con la query SELECT p FROM Project p:
public
List getProjects() throws PersistenceException {
List
result;
OQLQuery
query;
Database
db = createSession();
db.begin();
query
= db.getOQLQuery("SELECT p FROM com.mokabyte.tracking.model.Project
p");
QueryResults
results = query.execute();
result
= new ArrayList( results.size() );
while(
results.hasMore() ) {
result.add(
results.next() );
}
db.commit();
db.close();
return
result;
}
si
noti la presenza dei delimitatori begin() ed commit(),
oltre a close(). Castor è fortemente transazionale,
e richiede che tutte le operazioni vengano correttamente
delimitate. All'interno di una applicazione J2EE, infatti,
è possibile utilizzare una transazione JTA di
tipo UserTransaction.
Il risultato della query non è una collezione
o array di oggetti del tipo richiesto, ma è memorizzata
sottoforma di QueryResult, che ha una interfaccia del
tipo Iterator. Da questa è possibile estrarre
i singoli oggetti ritornati, questa volta del tipo corretto,
e ritornarli all'interno, ad esempio di una lista. In
questo modo possiamo riutilizzare la pagina JSP di presentazione
realizzata in [2].
CRUD
In merito alle operazioni di Create/Read/Update/Delete,
come Hibernate, per caricare un singolo oggetto è
possibile utilizzare il metodo load() presente nell'interfaccia
Database:
public
Project getProject( String projectId )
throws NumberFormatException,PersistenceException {
Database
db = createSession();
db.begin();
Project
result = (Project)
db.load(
Project.class, new Long( projectId ) );
db.commit();
db.close();
return
result;
}
Le
altre funzionalità di supporto sono:
create(). Memorizza un nuovo oggetto nella base dati;
remove(). Rimuove un oggetto esistente dalla base dati;
update(). Aggiorna un oggetto esistente, ottenuto da
una altra transazione.
Ad
esempio, la creazione di un nuovo oggetto è implementata
in questo estratto della classe IssueAdder, utilizzata
per creare una nuova segnalazione:
public
void setAdd( String projectId ) throws PersistenceException
{
Database db = createSession();
db.begin();
User
currentUser = (User)db.load( User.class, new Long( 1
) );
ProjectList
list = new ProjectList();
Project
currentProject = list.getProject( projectId );
Issue
issue = new Issue(
currentProject,
currentUser, summary, description, priority
);
db.create(
issue );
db.commit();
db.close();
}
Conclusioni
Castor è un interessante framework di persistenza,
con un esteso supporto anche ad XML ed LDAP e dotato
di integrazione con i contesti transazionali, le cui
funzionalità qui sono state solo accennate negli
elementi principali.
Bibliografia
e Riferimenti
[1] Autore -"Castor JDO: Simply False Advertising",
O'Reilly Net, dicembre 2003
[2] Bigatti - "Motori di persistenza in Java1:
Hibernate", Mokabyte, marzo 2004
[exolab]
http://www.exolab.org/
[castor] http://www.castor.org/
Scarica
l'archivio con gli esempi
|


