|
Continuous
Integration
La
Continuous Integration (CI) è una pratica che pone
l'accento sul fatto di avere un processo di build e di test
completamente automatico che permetta ad un team di modificare,
compilare e testare un progetto più volte al giorno.
I
principali elementi costitutivi di un processo automatico
di build e di test sono i seguenti:
- il
codice sorgente e' conservato in un singolo posto (Repository),
da dove chiunque possa ottenerne la copia corrente (o una
precedente)
- il
processo di build deve essere automatizzato in modo che
chiunque possa usare un singolo comando per ottenere un
sistema funzionante a partire dal sorgente
- il
processo di testing deve essere automatizzato in modo che
sia possibile eseguire un test o una test suite sul sistema
in qualsiasi momento con un singolo comando
Il
principale beneficio della Continuous Integration è
che facilita lo sviluppo incrementale del software agevolando
le operazioni d'integrazione tra i moduli software che man
mano concorrono a costituire il prodotto finale.
Se
in un sistema il test viene effettuato di rado su moduli software
di una certa dimensione, l'attività d'integrazione
risulta essere onerosa in termini di tempo e difficile da
un punto di vista tecnico dato che i bachi risultano difficili
da trovare perché hanno origine dall'interazione tra
più moduli. Inoltre lo sforzo di integrazione e' tanto
maggiore tanto più tempo passa tra le diverse sessioni
di integrazione.
Con un processo di Continuous Integration la maggior parte
di questi bachi si manifesta il giorno stesso in cui si integrano
i moduli interessati riducendo i problemi (e i tempi!) di
integrazione.
Questo facilita la ricerca del baco (principalmente sul nuovo
codice integrato) e, nel caso non si riesca a trovarlo nei
tempi desiderati, è possibile evitare temporaneamente
di mettere in produzione le modifiche che lo hanno introdotto.
Grazie alla Continuous Integration l'attività di "bug
finding" risulta essere più circoscritta dovendo
essere attuata solo sui moduli recentemente introdotti.
La
Continuous Integration aumenta quindi la produttività
e diminuisce il tempo speso nell' "inferno dell'integrazione"
[MFCI].
La
chiave di una CI e' l'automatizzazione
La maggior parte dell'integrazione va svolta in maniera automatica:
ottenere i sorgenti, compilare, eseguire i test. Alla fine
del processo si deve ottenere un'indicazione precisa sull'esito:
OK o FAIL. Nel secondo caso e' sufficiente ottenere la precedente
configurazione per avere una versione funzionante e indagare
sul modulo software opportuno.
Il concetto di fondo è di fatto molto semplice: ogni
sviluppatore deve poter collegare una macchina alla rete e
con un singolo comando ottenere l'ultima versione di tutti
i sorgenti da un sistema di controllo delle revisioni, ogni
file viene compilato, vengono generati i vari jar (EAR, WAR,
JAR, RAR,…) , vengono eseguiti i test e, se tutto avviene
con successo e senza intervento umano, allora il "build"
si può dire completo.
Dal procedimento si nota come è importante avere un
sistema di versionamento del codice e di come sia importante
utilizzarlo bene.
Prima di iniziare a lavorare ad un nuovo compito e' necessario
allinearsi con il repository, altrimenti si rischia di lavorare
su codice non aggiornato.
Una "regola for dummies" è quello di riallineare
i sorgenti dal sistema di versionamento ogni mattina. Per
poter eseguire il commit non e' cosi' importante se si ha
finito tutto, ma piuttosto che il codice compili e che abbia
passato i test necessari.
Uno script di build deve poter permettere la scelta del target
e rendere quindi possibile l'esecuzione di un build totale
(es: l'EAR dell'applicazione) o anche di un build specifico
di un certo target (es: la costruzione del solo WAR, o del
solo EJB JAR).
Come parte del processo di build e' possibile definire un
insieme di test definiti come "Build Verification Tests".
Tutti questi test devono poter essere eseguiti con successo
per considerare il build terminato correttamente.
La CI permette quindi di avere una procedura centralizzata,
automatizzata e disponibile a tutti.
Questo permette, con un semplice click, di ottenere un sistema
completo invocando una procedura che compia la sequenza dello
scaricamento dal Repository dei sorgenti, la compilazione,
il deploy su un ambiente di riferimento il lancio dei test
automatici e la pubblicazione dei relativi risultati.
Grazie a questo procedimento ogni operazione di build è
replicabile in modo sistematico e deterministico. Infatti
si è in grado di sapere con certezza quale set di sorgenti
ha generato un particolare build (ad esempio, si può
adottare la prassi di apporre un Tag al Repository del progetto
a seguito di una compilazione successful); inoltre, si eliminano
i problemi di errate configurazioni degli ambienti locali
che generano disuniformità fra gli esiti di compilazioni
e test negli ambienti degli sviluppatori e quelli negli ambienti
definiti.
Quante volte vi sarà capitato, dopo aver riscontrato
dei problemi sugli ambienti 'ufficiali', di sentire la frase:
'Ma sulla mia macchina funziona perfettamente". Di solito
queste situazioni si concludono scoprendo che sulla macchina
in questione era presente una modifica mai rilasciata, o un
file di configurazione impostato in maniera diversa da quanto
contenuto nel repository.
La disciplina di CI prevede di schedulare i build ad intervalli
temporali ben definiti integrando sempre lo stato dell'arte
dei vari moduli.
In
definitiva la pratica di CI di fatto si fonda su quattro pilastri:
- un
sistema di Version Control
- l'automazione
del processo di compilazione/deploy
- l'esecuzione
sistematica di test di unità e di non regressione
- un
processo di scheduling dei vari task
Passiamo
quindi a descrivere brevemente ognuno di questi elementi.
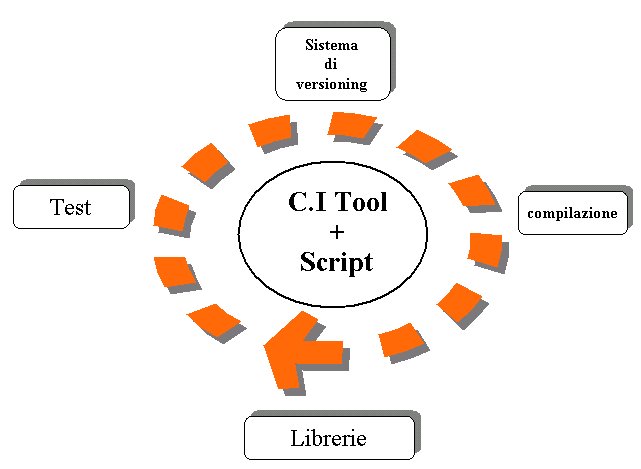
Figura 1: Continuous Integration
Il
sistema di versionamento
Il
controllo di versione permette di gestire e storicizzare in
modo centralizzato, attraverso un Repository comune, la storia
di tutte le versioni dei file necessari per generare un'applicazione
software.
I vantaggi che ne derivano sono enormi e praticamente non
esistono progetti software "nel mondo reale" che
possano prescindere dall'esistenza di un qualche meccanismo
di controllo del versionamento.
Le operazioni tipiche che permette un sistema di versionamento
sono:
checkin: consiste nell'aggiornare la versione di un file contenuta
nel repository, adeguandola alla versione presente nell'ambiente
di lavoro di uno sviluppatore (workspace)
checkout: è l'operazione inversa, con la quale la versione
conservata nel repository viene ricopiata nell'ambiente di
lavoro di uno sviluppatore.
Add/remove: ovviamente è possibile aggiungere / togliere
dei file dal sistema di versionamento. Per quanto riguarda
in particolare la rimozione, è possibile sia effettuare
la rimozione definitiva dal repository, con cui vengono perse
tutte le versioni del file in questione, sia effettuare una
semplice delete, che ha l'effetto di eliminare tale file soltanto
da un certo istante temporale in avanti, ma esplorando le
situazioni precedenti si può sempre ricostruire una
versione del sistema in cui il file era ancora presente.
Tag/freeze: questa è l'operazione con cui l'intero
set di file sorgenti del progetto viene congelato. Il risultato
che si ottiene è la cosiddetta "baseline".
Ciascun file infatti ha una sua storia indipendente ed il
suo "version number" viene incrementato ad ogni
checkin. La baseline è una fotografia che indica quale
versione di ciascun file fa parte di un certo rilascio.
Branch/merge: spesso è necessario poter lavorare in
contemporanea su due differenti versioni di uno stesso sistema:
il caso tipico è rappresentato da una versione per
il sistema in manutenzione ed una versione che invece contiene
le evoluzioni del sistema. Questa operazione di biforcazione
viene realizzata appunto con il comando di merge, che viene
a creare ciò che nel mondo Open Source è noto
come un 'fork' ossia una biforcazione nella storia di un sistema
software. Il comando di merge realizza l'operazione duale,
ossia compie la riconciliazione delle modifiche compite su
un ramo della biforcazione in modo da reinnestarle nel ramo
principale. Questo può servire ad esempio per riportare
dei bug fix eseguiti nella versione in manutenzione in modo
che siano presenti anche nella fase evolutiva del progetto;
o viceversa, per riportare delle evoluzioni particolarmente
utili che sono realizzate nella versione evolutiva (che magari
ha una data di rilascio ancora lontana) in una versione di
manutenzione che può essere rilasciata agli utilizzatori
in tempi più brevi (chi segue lo sviluppo di Linux
ha certamente familiarità con questo fenomeno di 'backporting').
A
seconda del sistema di versionamento utilizzato, l'operazione
di checkout può anche effettuare un lock sul file in
questione in modo tale che finché non ne viene effettuato
il corrispondente checkin, sia impedito un secondo checkout
da parte di un altro sviluppatore, allo scopo di prevenire
modifiche concorrenti allo stesso file (strategia utilizzata
ad esempio dal prodotto Microsfot Visual Source Safe).
Se
invece non viene invece fatto il lock del file piu' persone
possono lavorare sullo stesso file contemporaneamente effettuando
un merge del file a "check-in time". Questa strategia
è ottimistica perché presuppone che le situazioni
di conflitto siano poco probabili (strategia utilizzata ad
esempio dal prodotto Open Source CVS).
Gli script
Gli
script sono file testuali che includono una sequenza di comandi
che permettono di eseguire uno o piu' operazioni.
Uno script di build deve poter costruire una specifica versione
completa del progetto.
Lo scipt di build oltre al build totale deve permettere anche
un build parziale di specifiche parti del sistema (target).
Aspetto delicato dei file di script è sicuramente la
corretta gestione delle dipendenze tra i vari target che danno
luogo alla costruzione dell'intero sistema software.
Esempi di questo tipo di tool sono il Make, ANT (vedere [ANT]),
Maven.
I
test
L'ultima
parte del processo di build e' caratterizzata da un insieme
di test definiti come Build Verification Tests che devono
poter essere eseguiti con successo per considerare il build
terminato correttamente.
Dal
momento che i test aiutano ad identificare gli errori, se
si testa il frequentemente e a piccoli step incrementali,
si permette alla test suite (test unitari e funzionali), che
viene eseguita con il build, di mettere in luce gli errori
e di circoscrivere le porzioni di software su cui effettuare
il debug.
Esistono
diversi framework di test nati per semplificare la scrittura
dei test e organizzarli in suite.
Grazie a tali prodotti lo sviluppatore può concentrarsi
sulla sola scrittura dei test ed ottenere un risultati facilmente
interpretabili (non solo dallo sviluppatore del test).
Esempio
di framework di test la famiglia di prodotti xUnit. Questo
framework open source è disponibile per Java sotto
il nome di Junit (vedere [JUNIT]).
Il
tool di continuous Integration
Esistono
diversi tool di CI (es: CruiseControl, Anthill, Gump,…)
il cui scopo è l'automazione delle tre procedure descritte
mediante un meccanismo di schedulazione programmata delle
compilazioni (eseguite sempre partendo dai sorgenti nel repository)
a cui fa seguito la esecuzione degli unit test e la pubblicazione
dei risultati in un posto accessibile a tutti, in modo che
si possa immediatamente verificare che non vi siano stati
errori di compilazione e che i test abbiano dato esito positivo.
Una volta quindi versionati i sorgenti, preparati gli script
per il download/compilazione e deploy del software e per lanciare
il test, è possibile schedulare la loro esecuzione
al fine di ottenere un processo completo di CI.
Conclusioni
In
questo articolo si è parlato della pratica di CI che
pone l'importanza di avere un processo di build e di test
completamente automatico che permetta ad un team di modificare,
compilare e testare un progetto più volte al giorno.
Nel
prossimo articolo verrà presentato un esempio pratico
di Continuous Integration.
Si utilizzerà un'applicazione J2EE minimale (la MokaDemo)
come "pilota" del processo di CI.
Verrà utilizzato JBoss come Application server, CVS
come sistema di version control, ANT per gli script e Junit
come framework di test. Il motore per la CI sarà Anthill.
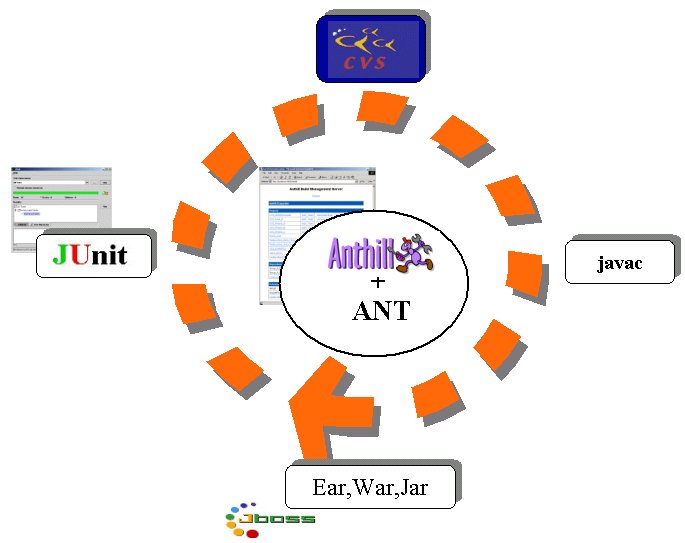
Figura 2 - Esempio di Continuous Integration
Bibliografia
[MOKA_PSS_TDD]
S.Rossini: Pratiche di sviluppo del software (I): Test Driven
Development-Mokabyte 86 Giugno 2004
[MOKAMET_1] S. Rossini: Processi e metodologie di sviluppo(I)-Mokabyte
83 Marzo 2004
[MOKAMET_1] S. Rossini: Processi e metodologie di sviluppo(II)-Mokabyte
85 Maggio 2004
[MFCI]Continuous Integration: Martin Fowler
httpp://martinfowler.com/articles/continuousIntegration.html
[CVS] https://www.cvshome.org/
[ANT] http://ant.apache.org/index.html
[ANTHILL] http://www.urbancode.com/projects/anthill/default.jsp
[JUNIT] http://www.junit.org/index.htm
[TWCC] http://cruisecontrol.sourceforge.net
|

