|
Introduzione
Parte con questo articolo una nuova serie dedicata alla presentazione
di un progetto software che stiamo preparando in redazione
e che mese dopo mese presentermo ai lettori man mano che questo
prenderà vita.
L'idea è quella non tanto di presentare un prodotto
o una tecnologia dall'alto della nostra esperienza, ma di
raccontare cosa stiamo facendo, riportando le idee ed i pensieri
che stanno uscendo dalle nostre teste.
Per una volta ci prenderemo il lusso di raccontare gli sbagli
che faremo e di seguire le nostre intuizioni senza il dovere
a tutti i costi rispettare un rigore formale stretto nella
presentazione degli argomenti.
Questo non significa che con questa premessa avremo la giustificazione
a scrivere e descrivere idee strampalate senza il supporto
di nessuna giustificazione pratica o tecnica.
Quello che vorremmo fare è presentare a tutti una idea
e mostrare come abbiamo pensato di implementarla senza nascondere
difficoltà, insuccessi o idee del tutto infruttuose.
Speriamo che questo dia maggior interesse al nostro lavoro
ed attiri l'attenzione del lettore.
Una volta ho detto ai miei collaboratori che il tutto dovrebbe
avere il taglio di una specie di romanzo giallo-polizesco.
Insieme al lettore seguiremo il nostro ispettore alla ricerca
dell'assassino: il non nascondere insuccessi o passi falsi,
renderà ancora più appassionante arrivare fino
in fondo a questo racconto. Almeno questo è quello
che speriamo.
Il progetto ha iniziato i primi passi grazie anche al valido
supporto di Massimiliano Bigatti e Massimiliano Dessì
(in ordine strettamente alfabetico) che sono stati validi
ed indispensabili suggeritori in questa prima fase di brain
storming.
Il
forum
Brevemente ricordo a tutti che mese dopo mese pubblicheremo
sul magazine i risultati del nostro lavoro, ma che giorno
dopo giorno potete seguirne le evoluzioni sul forum di MokaByte
dove è stato attivato un thread di discussione apposito.
Invito tutti i lettori a dare il loro contributo o scrivendo
direttamente a me o agli altri autori, oppure a postare messaggi
sul forum.
MokaByte
CMS
Il progetto in questione è rivolto alla realizzazione
di un Content Management System (CMS) per la produzione dei
contenuti editoriali del sito MokaByte.it.
Il sistema dovrebbe permettere alla redazione di inserire
contenuti, agli articolisti di proporre i loro articoli, ma
anche di organizzare il sito nella sua struttura e nella organizzazione
delle rubriche.
Al momento infatti MokaByte è messa in linea mese dopo
mese con un sistema speudo-automatico, che per quanto sia
ancora in grado di soddisfare le esigenze della redazione,
inizia a mostrare alcune limitazioni, specie per la parte
di produzione editoriale su formati alternativi (primo fra
tutti PDF).
Nel corso degli anni abbiamo introdotto una serie di script
più o meno automatici per la realizzazione delle pagine
finali, per cui di fatto ormai non si impagina quasi più
direttamente gli articoli. Quello usato attualmente è
comunque da considerarsi pur sempre di un sistema manuale.
I motivi per cui si è continuato con questa strada
sono molteplici: da un lato visto che le pagine cambiano di
rado (il magazine una volta al mese) si è sempre ritenuto
che non valesse la pena di mettere in piedi un sistema per
fare poco lavoro in automatico una volta al mese.
Ma la ragione più importante è la manutenibilità.
Il sistema attuale prevede la centralità dei contenuti:
tutto l'impaginato (file HTML, immagini, allegati, template,
etc..) risiede su file system in un'unica gerarchia di directory
e la cosa per quanto possa apparire rudimentale ha un grosso
vantaggio: la gestione è semplicissima.
Per fare il backup basta copiare una directory radice su un
altro dispositivo (CDROM, HD secondario, raid, nastro…).
Per aggiornare i server è sufficiente copiare dei file
con un semplice FTP.
Con un semplice comando ("mv" di unix) si può
in un attimo spostare la directory www di Apache e ad esempio
metterla sotto un altro punto o su un server differente.
Il sistema manuale è quindi molto semplice, ma appunto
è manuale e per ogni modifica si deve prendere l'HTML
e modificarlo.
Funzionalità
richieste al sistema
Il sistema che si va qui a presentare dovrebbe essere composto
da alcuni moduli e funzionalità ognuna rivolta ad uno
specifico compito.
Sintetizzando le parti che dovranno essere realizzate il sistema
dovrà svolgere le seguenti funzionalità:
- Inserimento
testi: l'inserimento dei brani verrà realizzato
tramite browser utilizzando una web application baricentrata
su una applet che svolgerà la funzione di word processor.
La web application di contorno, consentirà di inserire
tutti gli attributi dell'articolo (titolo, sottotitolo,
autore etcc.) che sotto forma di testo verranno salvati
nel database; il corpo dell'articolo invece verrà
trasformato dalla applet in XML e spedito al database.
- Amministrazione
struttura sito: questa parte dovrebbe servire per organizzare
i vari contenuti, spostare sezioni, gestire i permessi di
accesso e quant'altro sia necessario al-la customizzazione
del portale nel suo complesso.
- Portale:
questa parte si concentrerà sulla organizzazione
e composizione della prima pagina del sito e di poche altre
che sono state pensate con la logica del portale.
- Pubblicazione
testi: questa parte differisce dalla precedente che
è esclusivamente focalizzata alla gestione della
struttura modulare della prima pagina del sito. In questo
caso invece una web application, prelevando i contenuti
testuali da un database, permetterà la visualizzazione
dei singoli articoli, testi, brani di vario tipo. Questo
aspetto è al momento l'unico definito e viene analizzato
più avanti in questo articolo.
Inserimento
dei testi
Per testo si intende un brano organizzato secondo una struttura
editoriale ben precisa e composto da alcuni elementi fra i
quali i più importanti sono: corpo del testo, titolo,
sottotitolo, autore, titoli paragrafo, immagini e didascalia
immagini, note, codice Java, codice XML, codice HTML ed altri
elementi di minore importanza.
Dato che i brani sono pubblicati in HTML verranno anche inseriti
nell'articolo alcuni pezzi non visibili (come i tag per facilitare
il compito ai motori di ricerca o per l'inserimento di banner
o altro ancora).
Non è detto che tutti i componenti appena descritti
possono essere presenti nella pagina, a seconda che il testo
di cui si sta parlando si riferisca ad un articolo del magazine,
ad un testo di presentazione, ad una news, o a qualsiasi altro
tipo di pagina HTML pubblicata.
Ad esempio in una pagina di presentazione del servizio di
consulenze (uno dei canali del sito ) non è presente
il blocco relativo all'autore, mentre è presente un
blocchetto sulla sinistra con i menu per la navigazione fra
le pagine del canale (blocchetto che invece non è presente
negli articoli pubblicati mese dopo mese).
La modalità con cui queste parti verranno inserite
nel db e pubblicate poi su web è un aspetto molto importante
e verrà discusso più avanti.
Amministrazione
La parte di CMS deve avere una console di amministrazione
potente e flessibile che permetta di:
- Aggiungere
un articolo ad una gerarchia o sotto un canale già
esistente: esempio sotto il canale "consulenze"
si deve poter inserire un articolo utilizzando il template
definito per quel canale.
- Modificare
la gerarchia: ad esempio nasce una nuova colonna da attaccare
sotto la home page del portale: si deve poter definre URL,
template di canale etc...
- Agganciare-sganciare
dalla home page un canale.
- Definire
operazioni per determinati ruoli
Pubblicare
i testi: la produzione dei contenuti dinamici
Come si è avuto modo di accennare brevemente in precedenza
i contenuti del sito sono stati catalogati durante questa
fase di analisi in due tipologie principali.
- Portale
Qui si possono trovare la home page del sito ed altre sezioni
che analogamente alla home hanno una struttura composta
da contenuti modulari normalmente ricavati da altri contesti.
Ad esempio nella home troviamo la "civetta" con
i contenuti del numero in corso, alcuni link a rubriche
più o meno statiche, una finestra sul negozio online
(dove sono presentate le offerte del mese) ed altre parti.
Il tutto è assemblato in maniera più o meno
modulare.
- Testi
di canale
Sono l'altro tipo di contenuti che si trovano in MokaByte.
Si tratta di pagine semplici come gli articoli del magazine,
oppure pagine di rubriche o colonne particolari.
Nel
primo caso la creazione delle pagine del portale fa uso di
componenti-testo che sono assemblati in vario modo. Tali componenti
sono in un modo o nell'altro derivanti da contenuti appartenenti
alla seconda categoria, i testi di canale. Questi ultimi verranno
composti e visualizzati secondo precise norme editoriali tramite
l'utilizzo di una web application che diventa il baricentro
di tutta l'architettura.
L'implementazione di questa parte può essere realizzata
in maniera relativamente semplice dal punto di vista tecnologico:
si potranno seguire diverse soluzioni a seconda di come debba
essere composto l'HTML di ogni singola pagina, in funzione
di cosa sia stato salvato nel database e su come questi contenuti
siano poi trasformati in HTML (ma anche in PDF o altro formato
editoriale).
Tutte le soluzioni individuate non hanno evidenziato problematiche
non risolvibili ma hanno sottolineato la diversità
dell'approccio finale ottenibile a seconda della soluzione
adottata.
Anche la parte di inserimento di contenuti di fatto dovrà
semplicemente adattarsi a quanto scelto in questa parte.
Per questo motivo per questa parte è di fondamentale
importanza scegliere la strada giusta in modo da ottenere
il massimo di flessibilità leggerezza e manutenibilità.
Di seguito è presentata la soluzione adottata per la
parte di pubblicazione dei testi di canale.
Pubblicazione
dei testi di canale
Le pagine che compongono i vari canali del sito (sia il magazine
mensile che le varie colonne) sono in genere composte da una
serie di parti di cui il testo dell'articolo è quella
centrale. Intorno troviamo altre componenti come la sezione
dedicata al titolo dell'articolo, l'autore, alcuni link relativi
alle altre pagine della rubrica in cui l'articolo viene pubblicato
(menu di canale), così come sezioni dedicate alla visualizzazione
di link verso l'esterno, link tematici (come ad esempio "cerca
tutti gli articoli inerenti al presente articolo"), banner
tematici, link per l'acquisto di libri e così via.
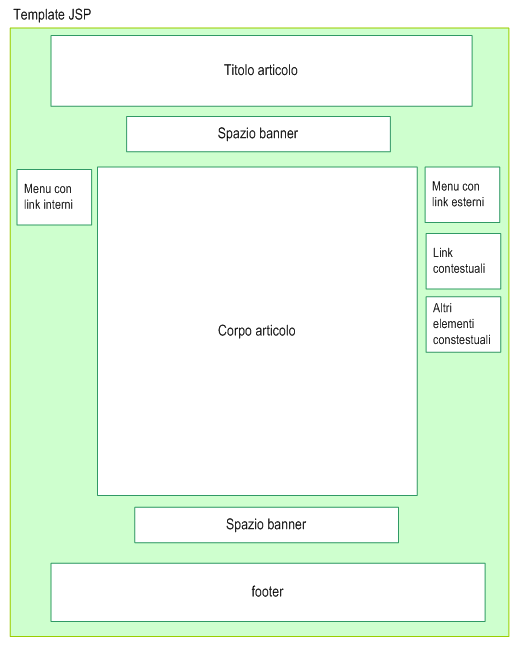
Figura 1 - Una pagina del portale in genere è composta
da
numerose sezioni più o meno dinamiche
In
base alle scelte fatte, dal punto di vista della applicazione
che stiamo progettando, esiste una differenza sostanziale
fra il corpo dell'articolo ed i blocchi che lo circondano
così come sono nettamente differenti le modalità
che portano alla loro creazione.
Il corpo dell'articolo in genere segue una struttura visivamente
piuttosto semplice ma complessa da un punto di vista editoriale
e quindi la produzione dell'HTML non è del tutto banale.
Un articolo è composto in genere da un corpo del testo,
i titoli dei paragrafi, le immagini con relative didascalie,
le liste puntate, le tabelle, il codice Java, XML o altro
ancora.
Tutti questi elementi devono essere visualizzati in modo semplice
e chiaro in modo da risultare di facile comprensione e fruizione.
In MokaByte da sempre si è scelto di usare una veste
grafica il più possibile gradevole ma al tempo stesso
estremamente semplice.
Per arrivare a questo risultato finale le opzioni e le strade
da seguire possono essere molteplici. Dopo molto disquisire
si è giunti ad una soluzione che, almeno nelle intenzioni,
è stata formulata avendo in testa i seguenti obiettivi.
- Performance:
il sistema per visualizzare una pagina all'utente non deve
avere presta-zioni inferiori a quello attualmente in uso
(HTML statico servito dal server HTTP). Il tempo per generare
l'THML finale può essere molto, ma non deve impattare
sul tempo di presentazione all'utente (ovvero l'HTML lo
si genera prima che l'utente richieda di visualizzare una
pagina).
- Scalabilità:
il sistema deve scalare le prestazioni in funzione del numero
di accessi e di utenti alle pagine del portale.
- Cache:
in un qualche modo il sistema, sebbene basato su pagine
dinamiche deve offrire sistemi di cache sia a livello di
produzione dell'HTML da XML che di creazione delle pagine
dinamiche (per questo secondo aspetto ci si affiderà
probabilmente ad un motore di cache esterno come JCS [JCS])
.
La parte di codice HTML relativo al corpo dell'articolo verrà
creato partendo da XML ed effettuando una trasformazione basata
presumibilmente su XSL.
La trasformazione da XML ad HTML è molto costosa in
termini di tempo per cui essa deve avvenire solo quando strettamente
necessario: se si immagina che il sistema editoriale inseri-sce
i contenuti in XML direttamente nel database, una volta prodotto
l'HTML relativo tra-mite un template XSL, si memorizzerà
nel database anche l'HTML prodotto attivando un sistema di
cache interno molto efficace.
Solo nel caso in cui l'articolo venga modificato (quindi cambia
l'XML dell'articolo) si potrà procedere nuovamente
alla generazione dell'HTML.
Il database, di cui ancora non si è ancora parlato
dettagliatamente, conterrà una tabella AR-TICLE all'interno
della quale saranno inseriti tutti i pezzi dell'articolo.
La struttura di tale tabella potrebbe essere qualcosa del
tipo:
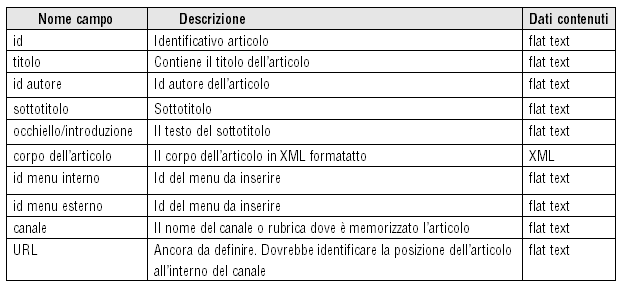
Tabella 1 - ipotesi della struttura della tabella ARTICLE
dove verranno salvati gli articoli nel database
Dato
che per il momento si è deciso che tutte le risorse
statiche (immagini, zip con i sorgenti etc..) relative ad
un determinato articolo saranno anch'esse memorizzate nel
database sotto forma di array di bytes salvati in campi BLOB
(vedi oltre), a questa tabella probabilmente sarà associate
la tabella contenente tutte le risorse:

Tabella 2 - le risorse statiche verranno salvate sotto
forma di array di bytes in
un campo BLOB di una tabella apposita
Tutte
le informazioni contenute nelle due tabelle potranno essere
utilizzate per comporre la pagina secondo lo schema presentato
in figura 2.
In particolare alcune parti verranno lette ed utilizzate da
appositi custom tag JSP per la composizione grafica (ad esempio
i blocchetti dei menu oppure i banner) mentre altre sezioni
verranno realizzate tramite la lettura dei dati dal database.
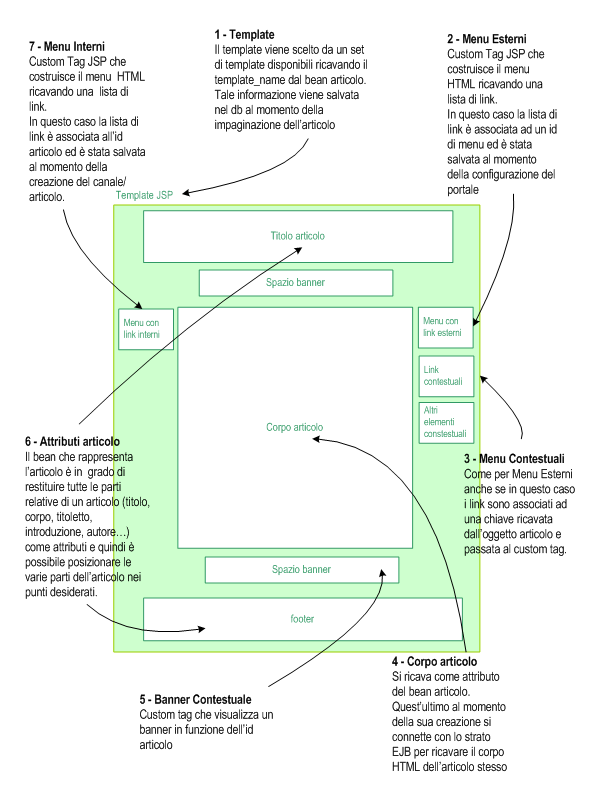
Figura 2 - le varie parti che compongono l'articolo sono
sostituite prelevando i
contenuti direttamente dal database
Alcune
sezioni sono lette dal database ed inserite senza che sia
necessario eseguire alcuna operazione di trasformazione ma
semplicemente sostituendo il testo nel template (Es. il titolo
dell'articolo).
Altre richiedono invece l'uso di alcuni custom tag per la
composizione, come ad esempio i menu con i link interni o
esterni.
Dovrebbe apparire piuttosto intuitivo che sebbene per la parte
di composizione dell'articolo o del titolo sia sufficiente
prendere del testo da un campo del database, per i menu la
composizione deve avvenire in modo dinamico in funzione della
pagina in cui il menu appare, della rubrica e di altre informazioni.

Figura 3: il menu sulla sinistra per la navigazione
del canale MBTSS
(collaborazione editoriale MokaByte-TheServerSide) riporta
una breve lista di link interni al canale
Ad
esempio in una sezione denominata rubricaXYX tutte le pagine
potrebbero essere composte con un blocchetto di link in alto
a sinistra: tale blocchetto è definito ed associato
per tale sezione, per cui dovrebbe poter essere sufficiente
(ed anzi necessario) definire il menu in maniera slegata dalle
singole pagine.
Se questo è un vantaggio da un punto di vista applicativo
(la composizione della pagine può essere eseguita prendendo
il testo dell'articolo ed attaccandoci "pezzi" a
seconda della sezione di appartenenza dell'articolo), tale
scelta diventa obbligatoria in fase di utilizzo da par-te
della redazione che inserisce i contenuti: il redattore/articolista
non è interessato a come la struttura del canale sia
organizzata, ma deve limitarsi ad inserire i testi di ogni
singola pagina.
Chi ha deciso di creare la rubrica (l'amministratore del sito)
è colui in grado di deciderne la struttura e quindi
di definire le varie voci del menu.
Tutto
questo discorso forse un po' lungo e dispersivo ci è
servito per dire che i menu (ma il discorso vale per ogni
altro componente modulare della pagina) devono essere definiti
in modo staccato dal codice XML della pagina, anche se legati
alla pagina tramite l'id della stessa.
Per risolvere la questione si è ipotizzato di inserire
nel database una tabella MENU che potrebbe contenere ad esempio
le seguenti informazioni

Tabella 3 - Per la composizione dei menu si devono
salvare le informazioni nel database relative ad ogni blocco
A
questo punto si immagini di dover comporre le pagine relative
al canale identificato dall'id "rubricaXYX": in
questo caso il sistema effettuerà una ricerca nella
tabella MENU per ricavare tutte le righe in cui sia valida
la seguente condizione
ID_MENU
="rubricaXYX"
ottenendo
tutte le voci di menu che compongono il menu del canale "rubricaXYX".
Tramite
un qualche custom tag JSP tale elenco dovrebbe essere trasformato
in qualcosa del tipo:
<table
border=0>
<tr>
<td>
<a href= " index.htm
" >home</a>
</td>
</tr>
<tr>
<td>
<a href= " informazioni.htm
" >info</a>
</td>
</tr>
<tr>
<td>
<a href= "aiuto.htm"
>help</a>
</td>
</tr>
<tr>
<td>
<a href= "logout.htm"
>esci</a>
</td>
</tr>
</table>
Altri
elementi più semplici come il titolo dell'articolo,
il nome dell'articolista verranno prele-vati come semplice
testo dalla tabella ARTICLE e come testo verranno inseriti
nella pagina. Il corpo dell'articolo, presente nella tabella
come HTML verrà prelevato dalla tabella ed in-serito
come se fosse del flat-text nel template.
Il
problema delle risorse esterne
La soluzione appena descritta non risolve un aspetto importante:
se si riconsidera il funzionamento si tratta in definitiva
di una pagina JSP che popola il suo contenuto testuale prelevando
stringhe di testo da un database.
Ma spesso un articolo non è solo testo, essendo composto
da immagini e dovendo anche offrire la possibilità
di scaricare dei file (ad esempio gli allegati in formato
.zip).
Dopo molto discutere ci siamo convinti che la soluzione migliore
fosse quella di mettere, durante l'inserimento dati, anche
le immagini e gli allegati in campi BLOB del database e di
effettuarne l'estrazione in fase di pubblicazione.
Durante
la pubblicazione su web di un articolo si compiono quindi
due operazioni: i testi sono trasformati da XML in HTML e
le immagini sono estratte dai campi binari e salvate su file
system sotto il controllo del server HTTP.
Per questo all'interno di una pagina, se i testi sono composti
nella JSP con tag particolari, le risorse statiche devono
puntare ad URL assoluti che a loro volta sono serviti da un
server HTTP.
Questa strada, benché è quella intrapresa dalla
maggior parte dei sistemi di CMS, è stata a lungo osteggiata
(principalmente dal sottoscritto, me ne assumo la responsabilità)
per un semplice motivo: non centralizza le risorse e non permette
di avere tutti i pezzi del sito in un unico punto. Una parte
dei contenuti sta come testo XML o HTML nel database, ed una
parte sul file system.
Questo complica la procedura di backup, così come la
migrazione o la semplice amministrazione del sito.
La naturale e personale avversità per questo genere
di problemi è stata superata con una assunzione ben
precisa: il database contiene tutto (testo in XML ed immagini/allegati
in bina-rio). Il database è il punto di partenza ed
il baricentro di tutto il sito.
Se si deve spostare, migrare, fare backup di qualcosa, lo
si fa sul database e poi si procede nuovamente alla pubblicazione.
Evoluzione
di una idea
Chi avesse voglia e pazienza di seguire i messaggi pubblicati
sul forum di MokaByte relativamente a MokaCMS si accorgerà
come in prima battuta le soluzioni proposte non rispecchiano
esattamente quello che alla fine è stato scelto.
Una soluzione presa in esame proponeva di mettere tutti contenuti
nel database (magari in XML) e di creare dinamicamente tutta
la pagina HTML dell'articolo tramite una trasformazione XSLT.
Dato che passare da XML a HTML con XSLT è cmq un processo
costoso e pesante, l'idea era quella di cachare pesantemente
tutti i contenuti magari salvandoli su file system o nel database.
Questa soluzione per quanto poi alla fine non molto distante
da quella scelta, prevedeva in prima analisi di comporre tutta
la pagina con la trasformazione XSLT, sia del corpo dell'articolo
che delle sezioni di contorno, tramite dei template di trasformazione.
La cosa si è rivelata quasi subito troppo macchinosa
e poco flessibile per quanto riguarda la scelta e la composizione
dei vari moduli (per generare ad esempio i menu era necessario
creare sistemi di template e strutture dati troppo macchinosi).
L'ipotesi alternativa è stata quella di tenere i contenuti
nel database in qualche formato standard aperto (XML da questo
punto di vista era una buona soluzione ma non vincolante)
e di comporre la pagina finale con una JSP e l'uso di custom
tag che mappassero i vari pezzi di pagina (un custom tag per
il titolo, uno per l'articolista ed uno per il corpo dell'articolo).
Questa idea, che alla fine è stata ripresa in parte
dalla proposta finale, non prende in esame come il corpo dell'articolo
dovrebbe essere composto. Di fatto una trasformazione verso
HTML anche in questo caso sarebbe necessaria.
Infine
l'ultima soluzione proposta presa in esame era quella che
è stata denominata "stampa HTML": in questo
caso i contenuti memorizzati nel database (XML per i testi,
binari per gli allegati) sono prelevati in toto, le pagine
HTML create (composte con una qualche tecnica figlia delle
due soluzioni precedentemente proposte) e salvate su file
system come file .html insieme a tutte le risorse statiche
(immagini, allegati .zip e così via).
I
vari file sarebbero poi stati serviti dal server HTTP come
normali file HTML impaginati a mano.
Il
vantaggio principale di questo sistema è che produce
contenuti statici (da un sottosistema dinamico) che sono poi
molto semplici da gestire e più veloci da servire al
client
Nonostante
fossi personalmente propenso ad adottare una qualche variante
di questo metodo, subito ci siamo accorti quanto questa strategia
fosse non attuabile a
causa della eccessiva macchinosità del processo: era
necessario un sistema dinamico per generare contenuti dinamici
(quindi simile a quanto proposto nei casi precedenti) e successivamente,
tramite un sistema detto "pompaHTML", leggere i
contenuti dinamici prodotti e salvarli su file in forma statica.
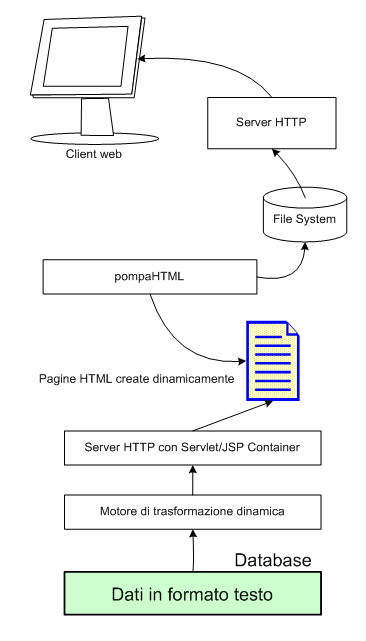
Figura 4: il sistema pompaHTML prevede di leggere file
dinamici per poi salvarli come file statici
Proprio
per i motivi legati alle prestazioni, sistemi di questo genere
qualche tempo fa erano utilizzati per la produzione di pagine
HTML di grossi portali di quotidiani nazionali: era stato
scelto perché le tecnologie alternative non erano ancora
sufficientemente potenti e complete e perché si pensava
che servire una pagina statica da un server HTTP offrisse
tali e tanti vantaggi in termini di prestazioni che si era
disposti a lavorare un po' di più con un sistema un
po' più complesso.
Ad oggi altri meccanismi di cache e di generazione intelligente
dei contenuti hanno soppiantato questa scelta. Anche per questo
motivo in MokaByte non adotteremo questa soluzione, visto
che l'iniziativa dovrebbe essere fagocitata dall'incubatore
MokaLab, luogo dove presentiamo e testiano nuove tecnologie
per i lettori.
Lo
strato di persistenza, mapping e cache
Dato che lo strato web tramite una web application si preoccupa
di visualizzare contenuti in funzione di un ID di pagina,
si rende necessario uno strato di mapping che metta in comunicazione
lo strato web con quello di persistenza. Tale strato dovrebbe
anche implementare una logica di trasformazione in automatico
da XML ad HTML in maniera intelligente (ovvero effettuare
la trasformazione solo se i dati XML sono cambiati).
Il sistema di mapping inoltre dovrebbe anche realizzare una
cache magari tramite pool di og-getti, visto che i dati sono
in numero limitato (gli articoli/pagine attualmente nel nostro
database sono circa 700), sono dati a sola lettura oppure
cambiano di rado.
Alla richiesta dell'HTML di una pagina web, il sistema deve
prima verificare se i dati in XML siano cambiati ed in caso
negativo prelevare dal campo HTML il codice della pagina da
inviare allo strato web. Se l'XML invece è cambiato
si dovrà prima procedere alla trasformazione, al successivo
salvataggio del nuovo HTML prodotto nel campo della tabella,
e solo a questo punti restituire il nuovo codice HTML.
Date
tutte queste considerazioni, questo scenario sembra un caso
tipico in cui gli EJB entity beans possano essere utilizzati
con successo. Il framework di mapping in questo caso sarà
CMP 2.0.
In particolare il meccanismo di verifica del cambiamento del
codice XML può essere facilmente attuato in un entity
implementando un pattern che si chiama "Read For Update",
e di cui parleremo quando si analizzerà questa parte.
Nella
figura 5 è riportato lo schema che mostra come dovrebbe
essere implementato il flusso delle operazioni.
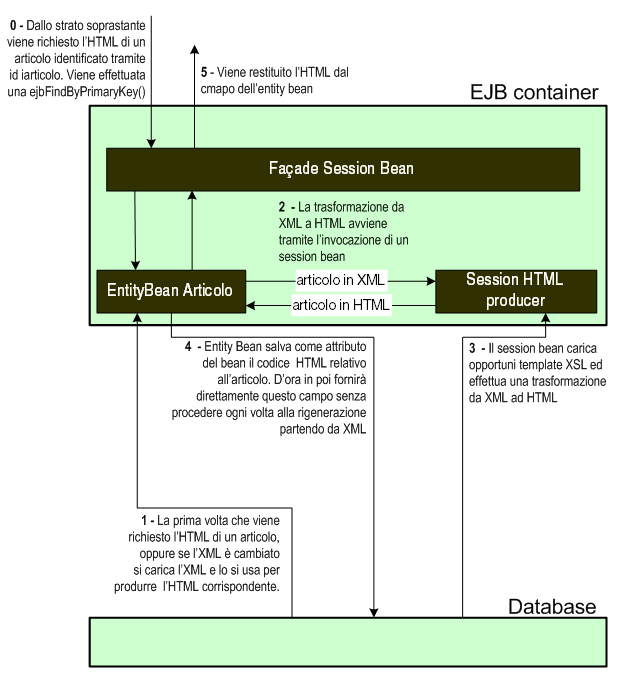
Figura 5: utilizzando uno strato EJB si potrà facilmente
implemen-tare il mapping verso il database
relazionale e realizzare un utilissimo sistema di caching
grazie ai pool di oggetti gestiti nel
loro ciclo di vita dal container
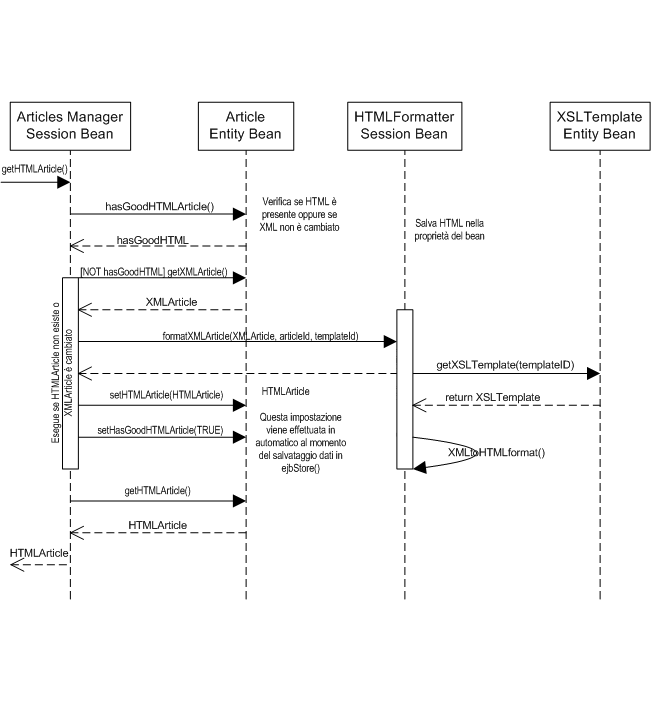
Figura
6: diagramma (pseudo) UML che mostra la sequenza delle
operazione per passare da XML ad HTML
e come questo venga restituito allo strato web dal session
bean di facciata
La scelta di EJB in un progetto enterprise è al solito
una decisione non semplice e spesso all'interno del gruppo
di lavoro ci sono idee contrastanti sulla reale necessità
di introdurre questa tecnologia.
EJB ed in particolare gli entity beans introducono un elevato
livello di pesantezza e complessità che spesso non
sono giustificati dal tipo di progetto che si deve realizzare.
In questo caso le funzionalità tipiche di object pooling
del container EJB unitamente al sistema di cache che la specifica
mette in atto, paiono essere due aspetti a favore della tecnolo-gia
enterprise Java Beans.
Conclusione
Questo mese abbiamo dato una prima descrizione del progetto
e di quella che dovrebbe essere la strada da seguire per la
sua realizzazione. Come accennato nella introduzione all'articolo,
siamo qui per raccontarvi una storia di un progetto di sviluppo
e della sua evoluzione. Il progetto nasce e si evolve mentre
scriviamo questi articoli e mentre postiamo i mes-saggi sul
forum, per cui non si stupisca troppo il lettore se di tanto
in tanto saranno intraprese soluzioni alternative apparentemente
in contraddizione con quanto detto in precedenza.
Bibliografia
e riferimenti
Fra le risorse da segnalare si menziona in modo particolare
il forum di discussione su questo progetto.
[MF] - Topic su MokaCMS sul Forum MokaByte
http://www2.mokabyte.it/forum/forum.jsp?forum=19
[JCS]
Java Caching System - http://jakarta.apache.org/turbine/jcs/
Biografia
dell'autore
Giovanni
Puliti è uno dei fondatori di MokaByte ed attualmente
passa la maggior parte del suo tempo nel coordinamento della
redazione del magazine. Esperto conoscitore della tecnologie
J2EE è anche dotato di una buona dose di umorismo.
Come
ogni anno dopo le vacanze si ritrova con qualche tonnellata
di nuove foto da cui dover sceglierne una nuova da allegare
agli articoli per il sito. In realtà essendo appassionato
di fotografia, di materiale da cui scegliere ne avrebbe a
disposizione ogni mese, ma ormai è tradizione cambiare
foto in settembre, mese che per molti aspetti è anche
l'inizio di un nuovo anno lavorativo, di buoni propositi e
di tante energie.
Per quest'anno la foto scelta da mettere nella title bar è
una foto scattata al Passo della Raticosa durante un raduno
motociclistico.
Immaginiamo
che i lettori siano a questo punto terribilmente incuriositi
dalle proposte degli anni precedenti e che in molti non trovando
tutte le foto della serie, non riusciranno a prendere sonno
senza prima aver scoperto tutte le immagini. Per questo motivo
abbiamo pensato di fare cosa utile, nel pubblicare tutte le
foto della serie, accompagnate da un breve riferimento storico....
la versione del JDK allora disponibile.
|
|
JDK
versione 0.9alfa
All'epoca delle prime pagine HTML.
Nuvole
rosse sullo sfondo, una zolla con del muschio in testa.
|
| |
 |
JDK
1.0.4
Qualche pagina HTML dopo.
Cappello
quadrato in testa.
|
|
|
|

|
JDK
1.1
Subito dopo aver discusso la tesi.
Felice.
|
|
|
JDK
1.3
In
un momento di disconnessione neurale...
Le
pilloline rosse erano finite.
L'autore ci tiene a ricordare che in quella occasione
non ha fatto male a nessuno.
|
|
|
|
JDK
1.4
L'autore ripreso mentre naviga nei mari della Corsica,
con lo sguardo rivolto verso l'infinito.
|
 |
JDK
1.5
Ormai preda di un irrefrenabile istinto autolesionista,
tenta di imitare l'eroe di un film americano.
I
bambini ridevano e sparavano con pistole ad acqua.
|
|
Il
lettore più attento potrà notare che insieme
ai capelli, con gli anni, se ne sia andata la tipica spensieratezza
della gioventù, sostituita da una forma di psicosi
non ancora del tutto diagnosticata.
L'autore adesso alterna momenti di estrema lucidità
in cui è riconosciuto un valido esperto della piattaforma
J2EE, a fasi in cui la follia pervade le sue connessioni sinaptiche.
E'
durante questi momenti di impredicibile schizzofrenia che
pare abbia avuto le intuizioni migliori e progettato i software
più innovativi.
|




