|
Introduzione
Il clustering di applicazioni enterprise è un argomento
molto vasto che richiede di affrontare numerosi aspetti non
tutti strettamente legati alla programmazione di un application
server o di una applicazione EJB.
In questa serie di articoli si parlerà di clustering
di applicazioni EJB e J2EE in genere concentrando l'analisi
all'utilizzo dell'application server open source più
utilizzato in questo momento, ovvero JBoss AS.
Si affronteranno alcuni argomenti generici relativi al clustering,
si vedrà cosa sia necessario fare per mettere in piedi
una batteria di application server e quali siano le tecniche
da adottare nella progettazione di applicazioni EJB (ma anche
web) in ottica cluster.
Clustering spesso viene identificato con alta affidabilità
e viene a volte confuso con la possibilità di avere
un sistema capace di non discontinuare il servizio.
Una architettura cluster può essere intesa sia da un
punto di vista hardware (clonazione di host identici, hard
disk replicati, cluster di partizioni di dati, alimentatori
ridondanti e scambiabili a caldo), sia dal punto di vista
applicativo: in questo caso ci occuperemo di affrontare tutti
gli aspetti programmazione e di setup e configurazione applicativa,
tralasciando gli aspetti sistemistica.
Cluster di applicazioni enterprise sarà finalizzato
alla realizzazione di un sistema in cui i componenti J2EE
(servlet, web application, EJB) possano essere deployati su
un insieme di macchine in modo del tutto trasparente, senza
che il client (un browser come client della parte web o una
applicazione qualsiasi come client di una applicazione EJB)
sappia e si possa rendere conto di cosa succede la dietro.
Concetti
generali e definizioni
Anche se esistono diverse definizioni e trattazioni che affrontano
l'argomento da diversi punti di vista, si può sinteticamente
dire che una architettura cluster è una struttura composta
da tanti nodi connessi fra loro in vario modo, in modo da
dar vita ad una unica entità con risorse ridondanti
e replicate. Un nodo è spesso assimilabile ad un application
server.
Prima di procedere alla progettazione ed installazione di
una struttura cluster, conviene capire quale sia lo scopo
di un sistema di questo genere e quali problemi effettivamente
permette di risolvere.
In tal senso si può dire che una architettura cluster
deve avere tre caratteristiche: alta disponibilità
e continuità (High Availability), resistenza agli incidenti
(Fault Tolerance) e parallelamente capacità di rimediare
agli incidenti (Fail Over), capacità di mantenere un
livello costante nella fornitura di un servizio tramite un
dipartimento del carico (Load Balancing).
High
Availability
Per alta disponibilità si intende la capacità
del sistema di offrire disponibilità del servizio con
una percentuale molto alta tendente il più possibile
al 100%. Data la complessità dei sistemi ed l'alto
numero di fattori che influiscono sulla disponibilità
del sistema, è impensabile porsi come obiettivo l'infallibilità
del sistema. In uno scenario realistico si cerca sempre di
ridurre al minimo il periodo di inattività complessiva.
Alta affidabilità o meglio alta disponibilità
significa proprio questo, minimizzare i tempi di inattività
del sistema.
Il
concetto di minimo è ovviamente funzione di quale sia
il dominio lavorativo del sistema.
Facendo un rapido calcolo sulle ore annuali (8760) si può
calcolare la percentuale di inattività massima che
si vuole sopportare e di conseguenza il livello di HA che
si deve ricercare.
Ad esempio
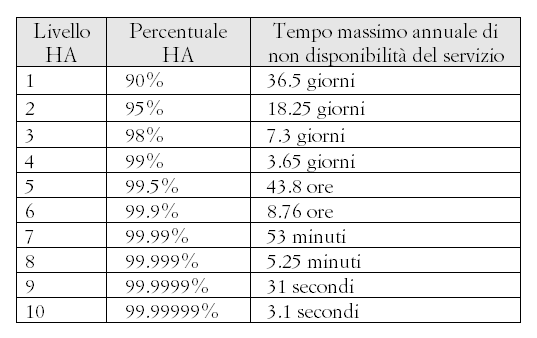
Tabella
1 - percentuali di HA e disponibilità del sevizio
Probabilmente
il livello HA5 è più che sufficiente per garantire
le normali attività di un comune sito web di divulgazione
scientifica come MokaByte (tenendo conto anche del tempo di
aggiornamento dei sistemi che può avvenire la notte
o nel fine settimana).
In un sistema home banking o di ecommerce con un elevato traffico
transazionale è plausibile porsi come obiettivo minimo
il livello HA7 o ancor più il livello HA8.
(Chi ha lavorato nel settore bancario sa che spesso determinati
servizi sono definiti non sospendibili, ed a volte questo
obiettivo viene raggiunto per servizi semplici. Altre volte
il livello di HA viene ufficialmente dichiarato solo per scopi
commerciali o di marketing ed è ben difficile poterlo
misurare)
Infine il sistema di navigazione interstellare della Astronave
USS Enterprise, è stato progettato per supportare il
livello 15 e forse anche qualcosa di più, ma si tratta
di un parametro non ancora implementabile su server terrestri.
Per quanto concerne i server klingon non ci sono al momento
dati attendibili, ma pare che il sistema di oscuramento delle
loro navi richieda un livello estremamente alto di affidabilità.
Detto
questo per poter garantire la massima efficienza è
sempre bene cercare di capire quale sia il limite accettabile
per la propria organizzazione e capire quali siano i costi
necessari per poter raggiungere tale obbiettivo. Ad esempio
passare da HA8 ad HA10 comporta uno sforzo altissimo (maggiore
di quanto necessario nel passaggio HA7 ad HA8) che spesso
non è giustificabile e probabilmente non possibile.
In questo articolo e nei successivi si analizzeranno le tecniche
di base per la realizzazione di un sistema ad alta disponibilità:
il livello di HA che si potrà raggiungere dipenderà
poi dalla ridondanza e dalle dimensioni del cluster che si
procederà ad installare.
Fault
Tolerance (FT) e Fail Over (FO)
La tolleranza degli incidenti implica la HA, ma mentre disponibilità
non dice niente sulla validità dei dati, la Fault Tolerance
dice che se successivamente ad un blocca di sistema, i dati
devono essere corretti e coerenti in tutti i punti della rete
del cluster installato.
In alcuni casi HA è sufficiente (ad esempio in un directory
service contenente dati statici o più comunemente un
sito web in cui le pagine siano tutte statiche), mentre nella
maggior parte dei casi il continuo cambiamento dei dati e
la dinamicità delle informazioni richiede anche la
FT. Le tecniche di Fail Over sono quelle che in modo più
o meno automatico permettono di continuare ad erogare il servizio
anche se uno o più nodi del cluster sono bloccati.
Load
Balancing (LB)
Questo aspetto è concentrato esclusivamente sull'ottenimento
di prestazioni migliori distribuendo il carico di lavoro su
più nodi del cluster. Non si fa nessuna ipotesi su
HA o FT che devono comunque essere garantite in altro modo.
Molte volte la architettura del sistema porta alla progettazione
di una architettura balanced solo per alcune parti. Si prenda
ad esempio il caso di un sito dinamico con contenuti memorizzati
in un database. Supponendo che lo strato di persistenza non
rappresenti un collo di bottiglia, si può pensare di
bilanciare il servizio di creazione e fornitura delle pagine
HTML spostando su più server la produzione dei contenuti
e la elaborazione delle richieste dei clienti.
Dato che il database invece rappresenta nella maggior parte
dei casi un punto molto delicato della architettura, è
opportuno dedicare tempo e risorse per la implementazione
di HA, FT, LB anche per il database server.
In uno dei prossimi articoli verrà mostrato come realizzare
un sistema di memorizzazione dati affidabile e ridondante.
Introduzione
al clustering JBoss
Si può ora passare ad analizzare come definire e come
funziona un cluster basato sull'application server JBoss.
Una applicazione J2EE che debba implementare una configurazione
clusterizzata deve fornire tutta una serie di funzionalità
più o meno avanzate volte al conseguimento delle seguenti
operazioni:
Auto
Discovery e configurazione dinamica automatica: si devono
poter aggiungere o togliere nodi (application server) al sistema
e questi devono potersi scoprire in modo automatico senza
nessuna particolare configurazione specifica
Disponibilità
di FT e LB per i seguenti servizi/componenti: JNDI, RMI,
entity beans, stateless session beans, stateful session beans
con replica delle sessioni
Replica
delle sessioni HTTP: una sessione HTTP deve poter essere
migrata da un application server ad un altro. Le sessioni
devono essere memorizzare in un qualche repository
Dinamic
discovery di risorse JNDI: la procedura di inizializzazione
del contesto deve avvenire in modo automatico da parte del
client che non deve dover conoscere la geometria di configurazione
del cluster. Questo implica che la registrazione dei nomi
JNDI deve avvenire in modo distribuito, ovvero deve essere
presente un albero JNDI unificato che copra tutto il cluster.
In terminologia cluster si deve avere un cosiddetto cluster
wide replicated JNDI tree.
Hot
deploy: deve essere possibile in ogni momento poter effettuare
il deploy su uno o su tutti i nodi del cluster di un componente
o di un servizio.
JBoss offre tutte queste caratteristiche ed essendo al momento
il prodotto open source più utilizzato per la parte
J2EE, rappresenta certamente un ottimo strumento per poter
sperimentare soluzioni ridondanti e sicure.
JBoss
Clustering: partizioni e nodi
Secondo la terminologia utilizzata in JBoss un nodo è
un application server, e per dar vita ad un cluster composto
da più nodi, si dovranno raccogliere insieme più
application server in quello che si definisce una partizione.
Un nodo può appartenere a più partizioni ed
una partizione ovviamente può essere composta da più
nodi. Infine all'interno della stessa architettura di rete
possono esservi più partizioni. Ogni partizione è
individuata da un nome: il nome di default è DefaultPartition
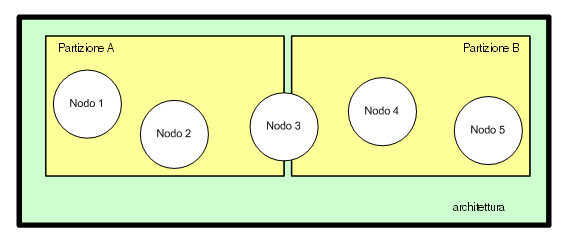
Figura1
- Nodi e partizioni: più nodi costituiscono una partizione
ma uno stesso nodo
può appartenere a partizioni differenti
Partendo
da una configurazione in cui una partizione sia composta da
un singolo nodo (soluzione non particolarmente interessante
ai fini di garantire FT, LB e HA) è importante notare
come sia possibile in ogni momento aggiungere nuovi nodi.
JBoss utilizza il JavaGroups framework2 (vedi [JGROUPS2])
per l'implementazione della comunicazione fra nodi, ma come
per ogni altro componente dell'application server, esso può
essere sostituito con un altro sistema se lo si ritenesse
necessario. JBoss offre anche la possibilità di organizzare
le partizioni in sottopartizioni per migliorare la scalabilità
e la flessibilità del sistema. Non affronteremo questo
argomento rimandando alla documentazione ufficiale ([JBCLUSTER]).
Smart
proxies
Un tipico scenario cluster è genericamente composto
da n client (con n potenzialmente molto grande) ed m server
(con m in genere limitato ad un numero piuttosto basso).
Si immagini il caso in cui uno degli n client desideri entrare
in comunicazione con un session bean stateful deployato in
uno degli m server.
In questo caso il problema più comune che può
verificarsi è dato dalla indisponibilità del
server o del servizio di lookup JNDI: data la equivalenza
(di servizio e di stato) fra tutti i nodi del cluster (e quindi
fra tutti i session bean), il client potrà utilizzare
un altro.
All'interno dello strato client si potrebbe pensare di implementare
una qualche logica di controllo che consenta di poter passare
da un server m non più disponibile ad un p sul quale
è in funzione lo stesso session stateful.
Questo modo di operare, per quanto sia una delle soluzioni
possibili va contro la cosiddetta location transparency del
servizio EJB: infatti non dovrebbe essere compito del client
preoccuparsi dello stato di funzionamento del server ed anzi
il passaggio dal server m non più disponibile al server
p di sostegno, dovrebbe avvenire in modo trasparente ed automatico.
Secondariamente il client per poter passare da m a p dovrebbe
avere la lista dei server disponibili ed anche questo non
è accettabile, dato che la configurazione cluster potrebbe
in ogni momento cambiare con l'aggiunta di nuovi nodi o la
rimozione di altri non più funzionanti.
Il meccanismo di FT deve essere quindi trasparante (Trasparent
FT o TFT).
La location transparency agli occhi del client viene in genere
risolta introducendo un punto centrale che funzioni come dispatcher
di tutte le richieste dei vari client verso i server.
Il dispatcher sa quali sono i servizi messi a disposizione
dai vari server ed è in grado di tenere sotto controllo
lo stato di salute di ogni server certificando al contempo
i servizi offerti da ogni nodo.
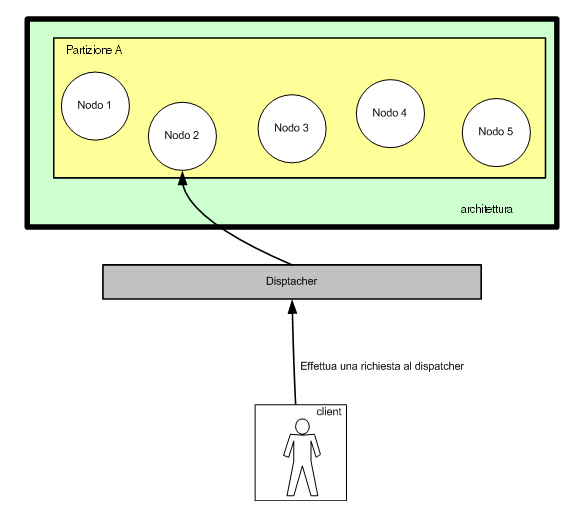
Figura 2- Utilizzando un dispatcher centralizzato si
risolve il problema della location
transparency e si possono utilizzare più server senza
che il client ne abbia percezione
Il
dispatcher quindi centralizza le chiamate dei vari client
e per certi versi può essere considerato il rappresentante
di una partizione di nodi: quando un client effettua una chiamata
(lookup e/o invocazione) di un componente remoto lo fa sul
dispatcher che poi provvederà ad inoltrare tale richiesta
al nodo più indicato (si veda oltre per capire meglio
cosa si intenda per nodo più indicato).
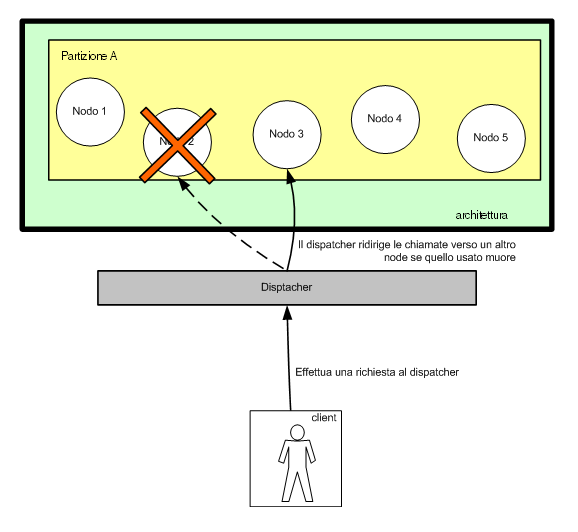
Figura 3- Il dispatcher permette di passare da un server
ad un altro senza
che
il client ne sia informato
Se nodo cade, il dispatcher provvede ad inoltrare le richieste
ad un altro nodo. Il client non sa niente circa la presenza
di un cluster, di una o più partizioni, degli m nodi.
Ma cosa accade se dovesse andare in blocco il dispatcher stesso?
Si otterebbe un blocco totale del cluster, essendo a quel
punto i singoli nodi non più raggiungibili.
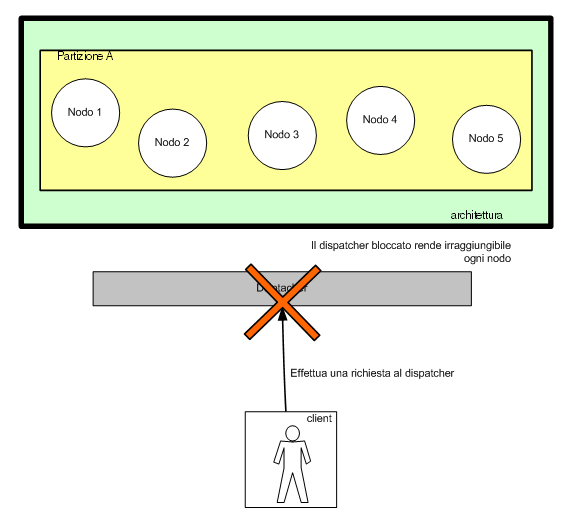
Figura 4- Il blocco del dispatcher rende il sistema irraggiungibile
Per
risolvere questo problema in JBoss si sfruttano alcune interessanti
caratteristiche che RMI offre rispetto ad altri protocolli
di comunicazione.
Il tutto si basa sul meccanismo base di RMI, ovvero nella
diversificazione di oggetti remoti in stub e skeleton.
Quando un client invia al server una richiesta di uno stub
di un oggetto remoto, il server può procedere ad inviare
una forma serializzata dello stub o si può addirittura
far si che il client scarichi il codice associato allo stub
da un server HTTP.
In JBoss questo meccanismo è pesantemente utilizzato,
tanto da permettere una notevole semplificazione della procedura
di deploy e di distribuzione del codice degli stub ai client:
infatti poiché al client viene inviato un proxy dinamico
dello stub non si rende necessario precompilare le implementazioni
delle interfacce remote (e difatti in JBoss il deploy avviene
in modo molto semplice rispetto ad altri application server);
soprattutto non vi è la necessità di inviare
ai vari client tali implementazioni.
Dal punto di vista della gestione dei cluster, i proxies dinamici
inviati al client (o smart proxies come riportato nella documentazione
JBoss) inglobano al loro interno tutta la logica per la gestione
delle chiamate remote, per la gestione del FT LB e HA.
In pratica in questo modo ogni client ha un suo dispatcher
che non risulta essere più unico per tutta la partizione,
ma distribuito su ogni client e solo virtualmente unificato.
In questa particolare configurazione un eventuale blocco del
dispatcher locale, porterebbe al blocco di un solo client
(probabilmente tutta l'applicazione client è andata
in errore), mentre il sistema nel suo complesso continuerebbe
a funzionare, così come tutti gli altri client.
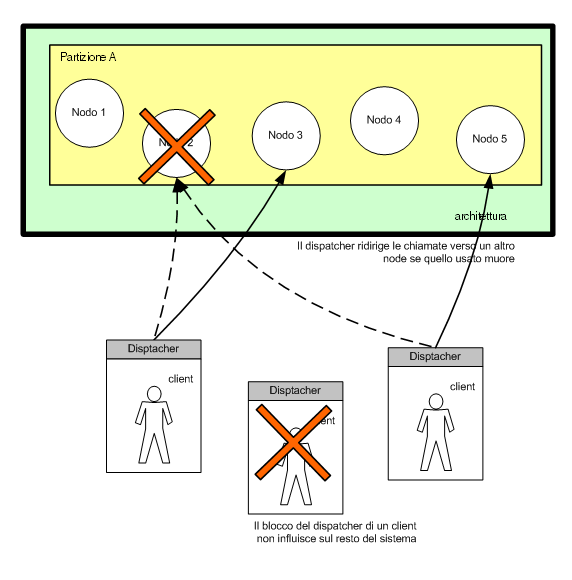
Figura 5 - dispatcher delocalizzato ed inserito in ogni
client permette di risolvere il problema
di un solo dispatcher centralizzato, mantenendo la possibilità
di effettuare il fail over da parte del
client in modo trasparente
Il fatto che il server invii del codice serializzato al client
ad ogni invocazione di una interfaccia remota, permette una
ulteriore importante funzionalità: ogni variazione
della configurazione della topologia del cluster può
essere infatti inviata dal server al dispatcher client-side
in tempo reale senza che la applicazione client se ne possa
rendere conto.
Con un meccanismo analogo (basato però sull'invio di
messaggi UDP in multicast) i vari nodi che compongono la rete
possono essere aggiornati l'un l'altro della configurazione
complessiva e quindi di conseguenza implementare tecniche
di migrazione dei componenti e delle sessioni-client in modo
trasparente (se ne parlerà in seguito).
JNDI
ad alta affidabilità
Fino ad ora si è parlato dei meccanismi che permettono
ai client di connettersi ad una partizione di nodi in modo
indipendente dalla configurazione e come parallelamente i
vari server possano entrare in comunicazione fra loro.
Resta da affrontare un importante aspetto che è legato
a come i nomi dei componenti remoti siano registrati nel cluster,
ovvero come sia organizzato il JNDI Tree internamente alla
partizione.
La registrazione di un componente in un albero JNDI locale
ad un application server rende tale componente disponibile
solo all'interno dell'application server stesso. Quindi la
creazione di una partizione e di un sistema EJB cluster oriented
risulterebbe di scarso interesse senza la presenza di un JNDI
clusterizzato.
JBoss offre a tale scopo la possibilità di gestire
un unico JNDI virtuale a livello di cluster in modo da registrare
componenti remoti in questo albero distribuito e permettere
ai vari dispatcher locali di ottenerne i riferimenti remoti.
Questo meccanismo rientra nella definizione di High Available
JNDI (HA-JNDI). Quando un client si connette ad un HA-JNDI
ottiene tutti i vantaggi del LB e fail over.
Ogni oggetto registrato nel HA-JNDI verrà replicato
su tutti i nodi per cui per ogni incidente che possa accadere
ad un nodo, non avrà ripercussioni sugli oggetti registrati.
La politica con cui i nomi e gli oggetti sono replicati all'interno
della HA-JNDI rappresenta un aspetto molto importante su cui
in genere i produttori di application server pongono molta
attenzione (una replicazione totale e insindacata può
portare ad inutili sprechi di memoria, mentre una politica
di replica minimale può richiedere dal lato client
molte più operazioni di lookup e maggior traffico di
rete).
Regole
di ricerca e registrazione
Se si utilizza JBoss come application server la regola fondamentale
da tenere presente è la presenza di due tipologie di
alberi JNDI: uno presente all'interno di ogni nodo (local
JNDI) ed uno invece che è associato a tutto il cluster
(cluster-wide JNDI).
L'albero cluster-wide lavora con una struttura propria, separata
da quella della versione locale che invece continua a funzionare
in modo autonomo.
Le motivazione per cui siano stati introdotti sia il JNDI
locale che quello cluster sono svariate. La più semplice
ed intuitiva è che in questo modo una applicazione
che funziona perfettamente in un ambito locale (non cluster)
può continuare a funzionare anche se il server in questione
venga aggiunto ad un cluster. L'albero cluster-wide da questo
punto di vista funziona come join-wrapper dei singoli JNDI
locali.
Inoltre in questo modo con poche modifiche ai file di configurazione
si può passare dalla versione locale a quella cluster
senza la necessità di testare nuovamente ogni singola
applicazione o rimappare i vari nomi.
Il
client che desidera ottenere un reference remoto deve effettuare
una operazione di lookup verso il tree HA-JNDI in maniera
del tutto analoga al caso in cui si lavori con un JNDI locale.
Non vi sono particolari differenze dal punto di vista della
programmazione. Quando viene effettuata la lookup sull'HA-JNDI
di un nodo m si possono verificare essenzialmente tre situazioni
diverse:
- l'oggetto
è stato registrato attraverso un cluster-wide JNDI
ed è disponibile all'interno del cluster nel suo
complesso
- l'oggetto
è registrato localmente al JNDI locale del nodo m
- l'oggetto
è registrato localmente al JNDI locale di un altro
nodo
A questo punto il sistema si comporterà nel seguente
modo: se l'oggetto è disponibile nel cluster-wide JNDI
verrà immediatamente trovato e restituito. Se l'oggetto
non è stato registrato all'interno del cluster-wide
tree allora verrà delegata una chiamata all'albero
JNDI locale al nodo m.
Se anche il JNDI locale al nodo non contiene nessun binding
per l'oggetto richiesto, il service HA-JNDI effettua una chiamata
agli altri JNDI locali degli altri nodi.
Se anche questa ricerca fallisce, viene lanciata una NameNotFoundException.
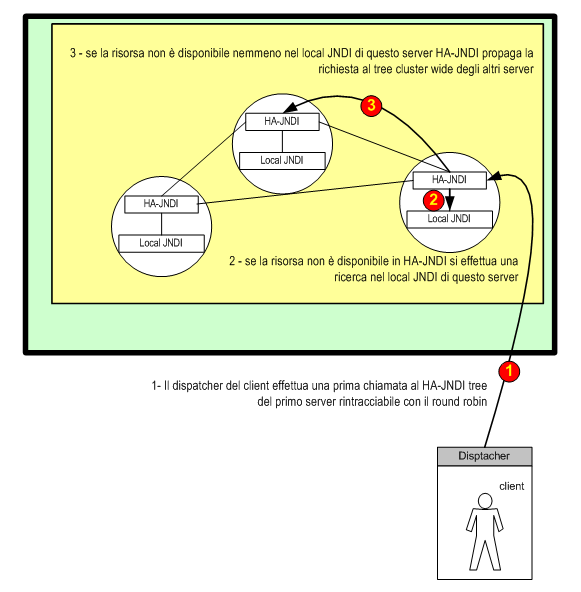
Figura 6 - Workflow che si verifica in concomitanza di
una lookup su un HA-JNDI
Questo
meccanismo mette in evidenza il fatto che una chiamata al
cluster-wide JNDI tree viene comunque evasa da un server appartenente
alla partizione (la politica con la quale viene scelto il
server dipende da diversi fattori di cui si parlerà
in seguito).
Dato che la ricerca avviene prima sull'albero HA-JNDI e poi
su quello locale del nodo m, appare abbastanza evidente che
se un bean viene mappato solo su alcuni nodi della partizione,
la probabilità di effettuare la lookup esattamente
al server giusto si riduce di molto, ed aumenta parallelamente
la possibilità che si debbano effettuare molti inoltri
delle chiamate agli altri nodi del cluster.
Parallelamente se si cerca un oggetto che è stato registrato
in un JNDI locale, non verrà trovato se lo si cerca
nell'albero HA-JNDI.
Quindi dato che sul lato server ogni operazione di lookup
viene effettuata sull'albero locale e non su quello cluster-wide,
l'operazione di IntialContext dovrà essere forzata
ad agire nell'albero HA-JNDI passando esplicitamente i seguenti
parametri di configurazione:
Properties
jndiProperties = new Properties();
jndiProperties.put(Context.INITIAL_CONTEXT_FACTORY, "org.jnp.interfaces.NamingContextFactory");
jndiProperties.put(Context.URL_PKG_PREFIXES, "jboss.naming:org.jnp.interfaces");
// si imposta l'url di connessione per HA-JNDI. Notare che
rispetto alla versione locale cambia solo
// il numero di porta
jndiProperties.put(Context.PROVIDER_URL, "localhost:1100");
return new InitialContext(jndiProperties);
Viceversa sebbene ogni server effettua una bind dell'oggetto
sul JNDI locale, grazie alla presenza dell'HA-JNDI, si ottiene
che l'oggetto sarà disponibile globalmente a livello
di cluster.
Questa organizzazione ha numerosi benefici, fra cui una drastica
riduzione del traffico di rete oltre alla possibilità
di migrare un nodo o una applicazione da un contesto stand
alone ad uno cluster.
Risulta ovvio che conviene nel modo più assoluto cercare
di ridurre la complessità del sistema: limitare ad
esempio la registrazione di implementazioni diverse dello
stesso bean (ad esempio diversa implementazione ma interfacce
uguali) con nomi identici su JNDI locali differenti.
Autodiscovery
di oggetti remoti: parametri di configurazione per InitialContext
Riprendendo in considerazione gli aspetti di connessione al
dispatcher centralizzato analizzati in precedenza (e ripensando
come il problema sia stato brillantemente risolto grazie all'ausilio
di un dispatcher locale ad ogni client aggiornabile dinamicamente
su richiesta del server), rimane da chiarire un aspetto. Il
client la prima volta che si connette a quale indirizzo deve
effettua la sua invocazione di inizializzazione del contesto?
Detto in modo più semplice, il parametro java.naming.provider.url
con quale indirizzo deve essere inizializzato?
In genere si utilizza un file di properties (jndi.properties)
che viene caricato dalla applicazione client per inizializzare
l'IinitialContext.
Una soluzione potrebbe essere quella di passare l'elenco dei
server che gestiscono la HA-JNDI in modo da poterne sempre
trovare almeno uno. Ad esempio
naming.provier.url=MokaServer-1:1100,
MokaServer-2:1100, MokaServer-4:1100
dove
MokaServer-1... MokaServer-n sono i nomi/indirizzi delle macchine
su cui sono eseguiti i vari application server.
Ovviamente questa soluzione non è molto elegante e
non permette nessuna forma di flessibilità.
JBoss permette di lasciare in bianco tale property ed in tal
caso gli smart-proxies effettuano quella che si chiama autodiscovery
della HA-JNDI: di fatto viene effettuata una ricerca in rete
dei server disponibili inviando un messaggio in multicast
all'indirizzo 230.0.0.4:1102.
La
procedura di autodiscovery può essere disabilitata
impostando a true il parametro jnp.disableDiscovery.
Oltre a questo, in ambito HA-JNDI, per configurare l'albero
dei nomi si possono usare alcuni parametri specifici dell'area
HA.
Il jnp.partitionName ad esempio permette di specificare su
quale partizione debba avere effetto l'operazione di autodiscovery;
se si imposta disableDiscovery=true questo parametro non verrà
utilizzato.
Con il parametro jnp.discoveryTimeout (valore di default 5000ms)
si specifica il tempo massimo in millisecondi di attesa in
risposta ad un pacchetto di autodiscovery.
Infine i parametri jnp.discoveryGroup e jnp.discoveryPort
servono per configurare l'invio dei pacchetti multicast: il
primo indica l'address group sul quale inviare i pacchetti
(valore di default 240.0.0.4) mentre il secondo la porta multicast
(default 1102).
Conclusione
Si conclude questo mese questa prima trattazione teorica del
clustering con JBoss. Il prossimo mese passeremo a parlare
di quali siano le procedure da seguire per scrivere applicazioni
cluster-oriented ed in particolare a come clusterizzare session
ed entity beans. E presenteremo un bel po' di pratica.
Bibliografia
[JBCLUSTER] - JBoss/Documentation - http://www.jboss.com/docs/index
[JGROUPS2] - JGroups - A Toolkit for Reliable Multicast Communication
http://www.jgroups.org/javagroupsnew/docs/index.html
|


