|
Introduzione
Queste
applicazioni (che di fatto rappresentano il cuore del sistema)
nel caso di una società di servizi saranno le applicazioni
che amministrano i servizi (conti correnti, polizze assicura-tive),
nel caso di una società manifatturiera saranno le applicazioni
che amministrano la con-tabilità il magazzino e i contatti
con i fornitori.
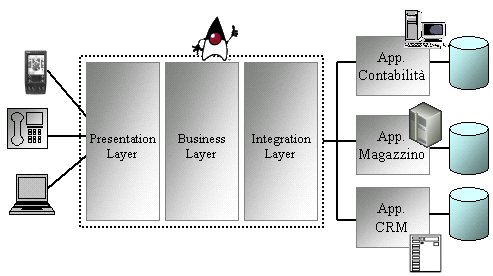
Figura 1: Esempio di integrazione di applicazioni "silo"
Tecnologie
Java per l'integrazione
Java
propone una serie di tecnologie volte all'integrazione di
dati e di applicazioni come JDBC (Java Data Base Connection),
JMS (Java Message Service), JCA (Java Connector Architecture),
CORBA e JAX-RPC (vedere [MOKA_BOOK2]).
JDBC
è un insieme di API che permette l'accesso a DBMS eterogenei
a parità di codice java. JMS
è un insieme di API che consente di creare, spedire,
ricevere, leggere messaggi
utilizzando la maggior parte dei MOM esistenti (sia nella
modalità Point-to-Point e Publish/Subscribe) ed è
utilizzabile sia da client standalone che all'interno di EJB
Message Driver. JCA
è un insieme di API che permette a componenti J2EE
di interagire con sistemi informativi enterprise (EIS) eterogenei
(Legacy, ERP, database non relazionali, …) attraverso
l'utilizzo di un'interfaccia comune (CCI) e di un insieme
di connettori (Resource Adapter) specifici per il particolare
EIS. Con
le API JAX-RPC è possibile sviluppare Web services
utilizzando quindi il protocollo di comunicazione SOAP (HTTP+XML).
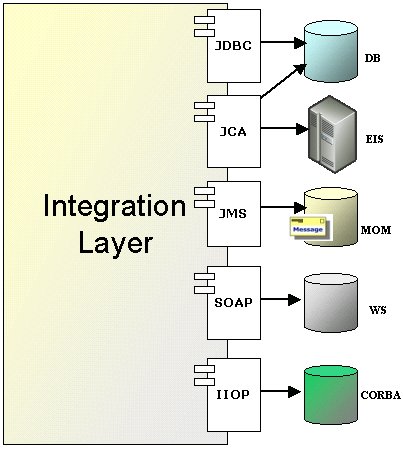
Figura 2 - Tecnologie Java per l'integrazione
Database
operazionali
Le applicazioni di cui si è parlato, e che rappresentano
il cuore del sistema informativo, sopportano la maggior parte
del carico transazionale del sistema informativo e sono dunque
progettate per avere rapidi tempi di risposta.
Queste applicazioni fanno uso di database relazionali (Oracle,
Db2, SQLServer, MySQL) per memorizzare i dati. Al fine di
potere sopportare un alto volume transazionale i database
sono tendenzialmente organizzati in terza forma normale (vedere
[TFN]). Questi
database vengono anche detti database operazionali perché
contengono traccia delle operazioni svolte in azienda, di
conseguenza essi contengono la storia di tutta l'operatività
dell'azienda. L'informazione però non è facilmente
consultabile perché è organizzata secondo la
logica dell'applicazione che la usa che non sempre è
quella di chi esegue le interrogazioni. Inoltre le informazioni
spesso sono parzialmente replicate fra database operazionali.
Per esempio è facile immaginare che nel caso di una
società di servizi il concetto di cliente sia presente
più o meno in tutte le applicazioni, e altresì
vale per il concetto di prodotto per una società manifatturiera.
Il problema che ci si pone diventa dunque come potere eseguire
interrogazioni sulla globalità delle informazioni contenute
in azienda ad es: "quali prodotti ha acquistato un certo
cliente in un certo periodo?"
Enterprise
datawarehouse
Il
problema dell'accesso unificato e omogeneo ai database operazionali
può essere risolto introducendo un elemento architetturale
nel sistema informativo: l'Enterprise datawarehouse (EDWH).
L'EDWH è un database relazionale che raccoglie e storicizza
tutte le informazioni in unico punto.
Esso svolge il ruolo di layer di integrazione dati allo stesso
modo in cui i middleware di integrazione svolgono il ruolo
di layer di integrazione fra applicazioni.
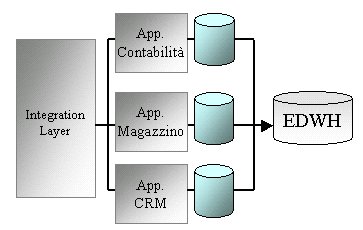
Figura 3: Introduzione di un EDWH nell'architettura del
Sistema Informativo
Se immaginiamo il sistema informativo di un'azienda come un
oggetto con stato l'EDWH rappresenta lo stato, per tale motivo
viene anche detto Single Point of Truth cioè punto
univoco della verità.
L'EDWH è normalmente un database in terza forma normale
che può raccogliere quantità elevate di informazioni
dell'ordine di svariati terabyte.
Essendo L'EDWH un normale database relazionale esso è
concettualmente realizzabile con qualunque dei prodotti RDBMS
già citati (Oracle, DB2, SQLServer, MySQL). Nella pratica
l'EDWH tende a raggiungere dimensioni elevate e inoltre le
interrogazioni che si tendono a fare su questo tipo di database
spesso coinvolge diverse tabelle in join. Questo porta spesso
a performance limitate. Alcuni vendor come Teradata si sono
specializzati nella costruzione di RDBMS con architetture
interne tali da consentire tempi di risposta accettabili anche
con gli ordini di grandezza raggiunti dell'EDWH.
ETL
Come si "carica" un datawarehouse? O meglio come
si trasferiscono i dati dai database operazionali all'Enterprise
datawarehouse?
L'argomento è delicato, infatti se si vuole che le
informazioni contenute nell'EDWH siano corrette bisogna fare
in modo che la fase di caricamento sia assolutamente controllata.
E' necessario definire quali dati scrivere sul datawarehouse
non solo perché non è detto che sia necessario
portare tutti i dati nel datawarehouse, ma anche e soprattutto
perché i dati possono essere presenti su più
database operazionali ed essere disallineati, sia nel valore
(es: stato_rapporto attivo in un database e estinto in un
altro) che nel significato (es: stato_cliente sposato in un
database, premium in un altro). Bisogna dunque sapere quali
dati prendere da quali database operazionali e con quale semantica
Questo tipo di problemi è affrontato dagli strumenti
che ricadono sotto la categoria di ETL (Extract, Trasform,
Load).
L'ETL
è un software data integration che permette di trasferire
dati da una o più sorgenti a una o più destinazioni
secondo l'algoritmo estrazione, trasformazione e caricamento.
Le versioni più evolute di questi strumenti usano le
features di fastdump e fastload dei db, e un set di regole
dichiarative per le trasformazioni. In altri casi le trasformazioni
sono effettuate mediante programmi scritti ad hoc.
Da
un punto di vista del mercato i prodotti più in vista
sono quelli di Ascential e Informatica (vedere [ETL_PROD]).
La definizione delle regole di trasformazione è aiutata
dall'esistenza di un dizionario dati.
Il dizionario dati raccoglie tutti i tipi di dato presenti
nel sistema informati e ne censisce la provenienza e il significato
semantico. Quindi per ogni colonna di ogni tabella del sistema
informativo si censisce indirizzo del DB di provenienza, significato
semantico del dato, formato del dato e valori ammessi.
I
metadati memorizzati nel dizionario dati possono essere salvati
secondo gli standard CWM (Common Warehouse Model) definito
dall'OMG [OMGSITE]. CWM è una serie di specifiche per
il trattamento dei metadati. Queste specifiche forniscono,
fra gli altri, uno standard alla creazione e alla memorizzazione
di metadati e uno standard allo scambio di informazioni contenenti
metadati fra applicazioni differenti mediante interfacce CORBA.
Sfruttando
questi standard di comunicazione sistemi di ETL avanzati possono
collegarsi ai dizionari dati e permettere allo sviluppatore
di comporre l'ETL in maniera visuale.
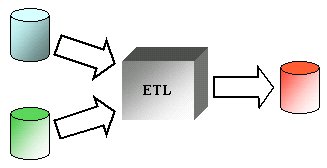
Figura 4 - ETL
Datamart
Come
precedentemente detto l'EDWH contiene una notevole quantità
di dati in forma normale, questo implica che questo database
non sia intrinsecamente adatto ad interrogazioni analitiche,
quelle cioè che richiedono dati aggregati secondo logiche
che spesso comportano molti join fra tabelle.
Per velocizzare questo tipo di interrogazioni si costruiscono
i datamart. I datamart sono database a tema, cioè progettati
per analisi che riguardano specifici argomenti. I datamart
quindi contengono una frazione dei dati presenti nell'EDWH.
Per favorire l'accesso ai dati i datamart vengono progettati
in maniera denormalizzata.
I datamart sono creati basandosi sui concetti di fatti, dimensioni
e misure. Ad esempio se prendiamo come fatti le vendite, le
dimensioni possono essere cosa (il prodotto), quando (in che
data), dove (quale rivenditore). I fatti poi possono avere
associate diverse misure es: peso, costo, numero.
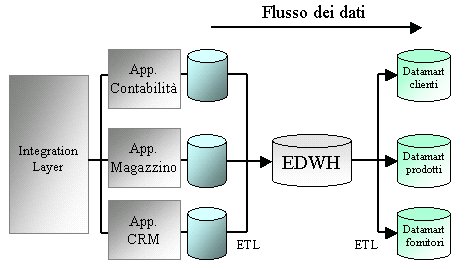
Figura 5 - Il ruol di un Datamart
La
denormalizzazione dei datamart si esegue secondo procedimenti
ormai standardizzati che mirano a modellare correttamente
i concetti di fatti, dimensioni e misure.
Ovviamente
bisogna prevedere un processo di ETL che alimenti il datamart
a partire dall'EDWH.
Business Intelligence
I datamart sono detti anche database analitici. I database
analitici servono, come dice il nome, ad analizzare i dati.
Questo tipo di analisi può avere diversi scopi, quando
serve a prendere decisioni aziendali ricade nel settore della
business intelligence.
Gli strumenti di business intelligence servono a costruire
interrogazioni complesse sui datamart. Fra i player di mercato
in questo campo abbiamo ad esempio BO e SAS.
Normalmente le suite di business intelligence mettono a disposizione
un portale che dà accesso a report predefiniti. Queste
applicazioni normalmente trattano i dati in maniera readonly.
Il valore aggiunto che possono fornire rispetto ad una normale
inquiry su database è la possibilità di manipolare
grandi set di dati creando dunque dei report in modo organico
e mirato, mantenendo sempre una facilità di consultazione
da parte dell'utente. Inoltre queste applicazioni consentono
all'utente di manipolare i suddetti set di dati operando su
di essi delle trasformazioni standard (quali ad es: drill
down, slice&dice e in alcuni casi il data mining [BIOP])
che consentono di creare nuovi report dinamicamente.
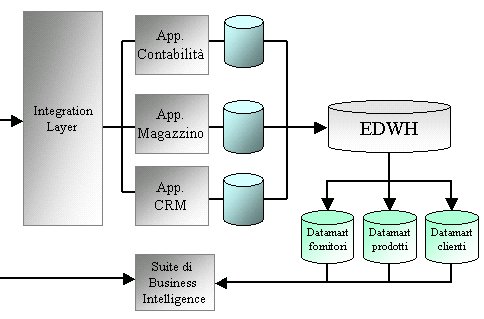
Figura 6 - Introduzione nell'architettura di una suite
di B.I
Business
Intelligence on demand e virtual datawarehouse
Se
consideriamo l'EDWH e i relativi datamart come la capitalizzazione
della conoscenza dell'azienda è naturale pensare che
tale conoscenza debba essere messa a disposizione di tutti
a supporto delle decisioni che devono essere prese.
L'evoluzione
che si sta avendo nel campo della Business Intelligence è
quella di portare la Business Intelligence a disposizione
di tutti i dipendenti della azienda, non solo a dirigenti
e quadri di alto livello, ma anche al ruolo più operativo
come gli impiegati che fino adesso non ne hanno beneficiato.
Risulta dunque necessario integrare le suite di Business Intelligence
con le applicazioni più operative in maniera tale che
l'intelligenza nascosta nei dati aziendali entri in gioco
nelle normali operazioni di business aziendale.
Un
esempio di utilizzo potrebbe essere il seguente: un cliente
si presenta a uno sportello per una normale operazione, il
sistema mentre svolge l'operazione richiesta analizza i dati
del cliente e decide che per questo cliente può avere
senso promuovere un certo prodotto, a questo punto presenta
all'operatore di sportello il prodotto da promuovere e magari
anche una frase commerciale da recitare al cliente.
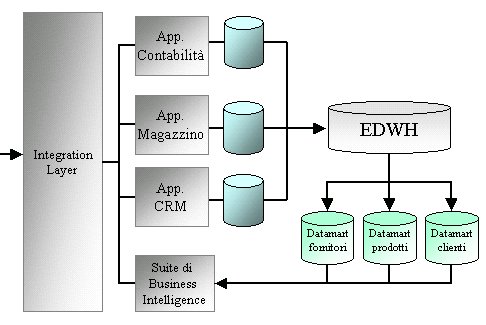
Figura 7 - Integrazione della suite di B.I
Questa nuova frontiera della business intelligence, che è
una possibile modalità di integrazione fra applicazioni,
viene detta business intelligence on demand. Una
tendenza che si sta diffondendo fra alcuni vendor è
quella di eliminare tutta l'infrastruttura dei datawarehouse
e datamart se l'obiettivo è la business intelligence
on demand.
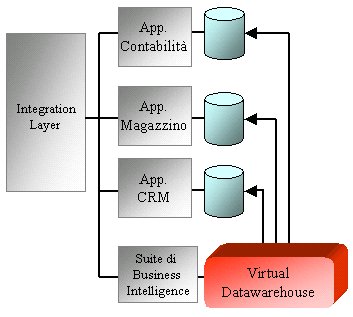
Figura 8: il Virtual Datewarehouse
I
prodotti che consentono di realizzare un Virtual Datawarehouse
sono anche detti database virtuali e rappresentano un mattone
del ramo dell'architettura di integrazione detta EII (Enterprise
Information Integration) in "contrapposizione" alla
EAI (Enterprise Application Integration). Questo ramo dell'architettura
di integrazione si occupa, come afferma l'acronimo, di integrare
le informazioni.
Questi prodotti si basano su un motore che in base a definizioni
di regole simili a quelle che si inseriscono negli ETL vanno
dinamicamente a reperire i dati dai database operazionali.
Quindi,
mentre l'EAI è prettamente "process-centric",
l'EII propone un approccio prettamente orientato ai dati (data-centric).
Esempio
di Virtual Database
Concludiamo l'articolo con un esempio pratico di integrazione
EII mediante un DB virtuale. Negli scorsi articoli di Mokabyte
apparsi nella sezione integrazione, si è visto come
sono possibili due approcci di integrazione: l'approccio verticale
"punto-punto" (vedere [MOKA_INT6]) e l'approccio
centralizzato che prevede l'introduzione di un Middleware
di integrazione(vedere[MOKA_EAI_IM]). Nell'esempio
che si era proposto si era utilizzato come piattaforma d'integrazione
Weblogic Integration (vedere[BEA_WLI]) di Bea.

Figura 9: Suite Bea di integrazione
Bea
Liquid Data (vedere[BEA_LD]) è una soluzione EII che
permette di avere una visione unificata dei dati enterprise
provenienti da data store eterogenei (DB relazionali e non,
file XML, custom file, Web Services, …) come se provenissero
da un unico data source virtuale. Prodotti come Liquid Data
sono quindi in grado di comporre query direttamente sui data
store eterogenei e di aggregare il risultato presentandolo
come se provenisse da un'unica fonte dati. Riprendendo lo
scenario d'esempio proposto nei precedenti articoli, per integrare
le due applicazioni bisogna configurare due Data Source "fisici",
uno per connettersi al DB e l'altro per la lettura del file
XML.
A
questo punto è possibile, in modo visuale (Data View
Builder), creare un Data Source virtuale che di fatto raccoglie
le informazioni necessarie tra i due diversi Data Source secondo
gli opportuni parametri di Join e di Query.
Da
notare che la selezione dei dati avviene in modo grafico e
secondo una schema risultante che porti a fattore comune i
dati da visualizzare dei due diversi data source fisici uno
per connettersi al DB e uno per leggere il file XML.
Figura 10: Il Data View Builder di Liquid Data
Una
volta creata la query di selezione è possibile effettuare
il deploy sul server e renderla accessibile da un Bea Liquid
Data Java Control; il risultato della query verrà reso
disponibile in un XMLBean e sarà accessibile dal Java
Control che sarà invocabile mediante componenti J2EE
come EJB, Servlet e JSP.
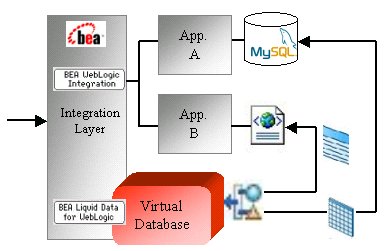
Figura 11: Esempio di integrazione dati con Liquid Data
Conclusioni
In questo articolo si è presentato un possibile percorso
evolutivo del sistema informativo per arrivare a potere sfruttare
le informazioni mediante applicazioni di analisi sui dati.
Tale percorso prevede come tappa fondamentale l'integrazione
delle informazioni contenute nei vari applicativi. L'integrazione
delle informazioni è guidata, come abbiamo visto, dalla
disciplina dell'EII.
Attualmente gli investimenti maggiori nel settore IT fatti
dalle aziende di grande dimensioni sono nel settore dell'Enterprise
Application Integration. Infatti l'EAI permette di standardizzare,
razionalizzare e controllare i processi aziendali per ottenere
vantaggi di business.
L'EII potrebbe essere un futuro settore su cui investire per
ottenere ulteriore competitività da parte delle aziende.
Ne segue abbastanza naturalmente che EAI non è in competizione
con EII, ma che queste due discipline, benché abbiamo
evidenti aree di sovrapposizione, si completino a vicenda
al fine di aumentare l'efficienza dell'azienda.
Bibliografia
e riferimenti
[MOKA_INT6] S.Rossini:Integrazione di applicazioni Enterprise
VI:Il panorama d'insieme,Mokabyte N.83
[MOKA_EAI_IM] S.Rossini-G.Morello: L'Integration Middleware
Mokabyte N.88 - Settembre 2004
[TFN] http://www.html.it/faq/sql/06.htm
[CWM] http://www.omg.org/cwm
[BO_ETLEAI] Next-Generation ETL vs. EAI: Getting Beyond the
Confusion -
http://www.businessobjects.com/resources/wp/next-gen_etl_eai_wp.pdf
[FAQ_EAIETL] EAI vs. ETL - http://eai.ittoolbox.com/documents/document.asp?i=1533
[MOKA_BOOK2] "Manuale pratico di Java: La piattaforma
J2EE", HOPS-2004
http://www.mokabyte.it/manualejava2/download.htm
· Cap.2 JDBC (Venditti)
· Cap.8 EJB (Puliti)
· Cap.9 Java Web Services (Bigatti)
· Cap.12 JCA (Rossini-Morello)
· Cap. 13 JMS (Rossini)
[OMGSITE] http://www.omg.org/cwm
[BEA_WLI] http://www.bea.com/framework.jsp?CNT=index.htm&FP=/content/products/integrate
[BEA_LD] http://www.bea.com/framework.jsp?CNT=index.htm&FP=/content/products/liquid_data
[BIOP] http://www.dwinfocenter.org
http://datawarehouse.ittoolbox.com
[ETL_PROD]http://www.computerworld.com/softwaretopics/software/story/0,10801,84222,00.html?from=story_package
[EII_ONA] Enterprise Information Integration- What Was Old
Is New Again
|

