|
Introduzione
Da diverso tempo ormai il modello che si è andato affermando
sempre più è il modello della applicazione web,
con tutti i pro ed i contro del caso. L'interfaccia HTML dinamica
(gestita in Java tramite applicazioni basate su servlet e
JSP) è in questo momento il sistema più utilizzato
per realizzare applicazioni pervasive: tutti i PC hanno un
browser e quindi potenzialmente l'applicazione che si scrive
può avere un parco di utenza planetaria.
Non è detto che questo scenario resti invariato ancora
per molto tempo ed anzi presto le cose potrebbero cambiare.
Molti sono i problemi derivanti dallo sviluppo di applicazioni
web pure: un maggior tempo necessario per sviluppare i vari
menù, minor potenza espressiva di una pagina HTML e
ridotte funzionalità interattive del modello CGI hanno
da tempo mosso la comunità IT verso diverse evoluzioni
del modello web.
Personalmente trovo il modello web effettivamente piuttosto
rudimentale, ma con alcuni vantaggi talmente importanti da
far dimenticare in un attimo ogni altra limitazione. Penso
alla facilità con cui sia possibile disaccoppiare la
parte di presentazione dalla business logic e magari dare
i template HTML/JSP in gestione ad un buon grafico mentre
il programmatore J2EE spende il suo tempo a progettare e modellare
session ed entity CMP 2.0.
Per non pensare alla potenza di poter inserire varie applicazioni
nell'ambito di un unico portale "amalgamando" il
tutto grazie a poche e semplici istruzioni HTML: il single
sign-on non è mai stato così semplice, dato
che vi è un browser che permette di centralizzare in
sessione tutte le informazioni utente.
Ovviamente il motivo principale per cui il modello ha avuto
successo è quello della indipendenza dalla piattaforma:
avere un browser il cui compito è limitato al parsing
di HTML (e non dovrebbe fare niente di più) elimina
la fase di installazione e manutenzione della piattaforma
client.
Si potrebbe proseguire ancora molto sui costi e benefici di
questo modello di programmazione, ma non è questo il
luogo adatto: le web application sono di fatto attualmente
lo strumento più utilizzato nell'ambito delle applicazioni
distribuite.
Per questo motivo è importante, quando si parla di
alta affidabilità di applicazioni J2EE, preoccuparsi
anche di predisporre le adeguate misure per rendere lo strato
web affidabile.
Sistema affidabile vuol dire preoccuparsi essenzialmente di
due aspetti: load balancing delle chiamate e replica della
sessione HTTP.
Load balancing significa avere diversi web container in funzione
per la stessa applicazione web in modo da garantire la ripartizione
del carico fra i web container minimizzando per quanto possibile
i tempi di risposta del sistema.
La replica della sessione invece permette di sincronizzare
le sessioni utente sui vari container rendendoli di fatto
del tutto equivalenti agli occhi del client. In questo modo
il cosiddetto conversational state verrebbe reso indipendente
dal particolare container, rendendo possibile ad un client
di passare da un web container ad un altro senza che nessun
dato di sessione sia perso.
Se il proprio obiettivo è rendere la architettura il
più affidabile possibile e minimizzare i tempi di indisponibilità
del sistema, allora implementare il load balancing è
sicuramente il primo passo da compiere.
La replica delle sessioni (benché non particolarmente
difficile da implementare) richiede uno sforzo concettuale
maggiore ed implica un carico di lavoro maggiore per il sistema:
per questo motivo si procede in questa direzione solo se strettamente
necessario, ovvero se si desidera realizzare un sistema che
oltre ad essere sempre disponibile, non perda nemmeno una
sessione utente e quindi non perda nessuna informazione o
non invalidi nessun work-flow applicativo.
Se nel sistema in questione il blocco di un container è
un evento che si verifica raramente e se l'applicazione non
maneggia dati sensibili (per esempio denaro o dati personali),
si può pensare di evitare la replica della sessione,
mettendo in conto il fatto che ogni tanto un utente debba
ricominciare la sua procedura di acquisto su un sito di ecommerce,
il login in un forum e così via.
Nota
sui prodotti e tecnologie utilizzate
Come si è avuto modo di accennare nei precedenti articoli,
per brevità concentreremo la trattazione limitando
l'analisi della configurazione e del comportamento ai prodotti
open source attualmente più utilizzati, ovvero Apache-Jakarta
Tomcat (per brevità Tomcat) per la parte web e JBoss
per la parte EJB.
I due server verranno qui analizzati come componenti separati,
anche se si consiglia di utilizzarli in modalità embedded
per il supporto completo dello stack J2EE. Come server HTTP
verrà preso in esame Apache HTTP Server (per brevità
Apache).
Load
balancing
Ripartizione del carico significa associare l'URL a cui risponde
una applicazione ad un numero n arbitrario di server HTTP
e web container.
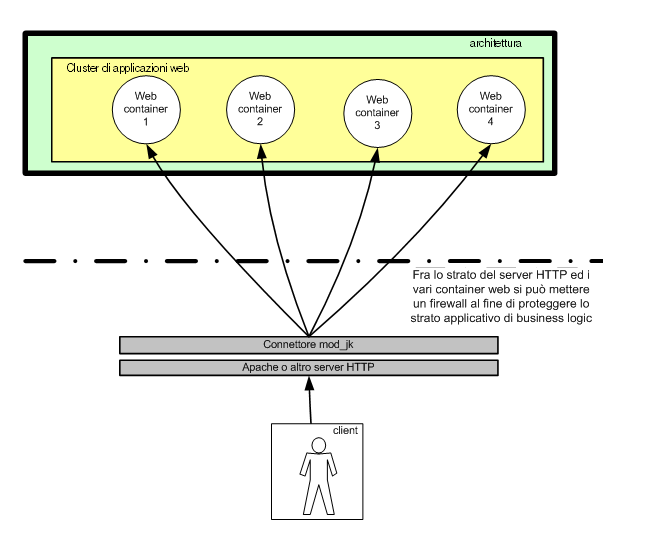
Figura 1 - Una tipica architettura load balanced: il server
HTTP maschera la presenza di n web container
Per
semplicità cerchiamo di scomporre il problema analizzando
singolarmente i vari soggetti che partecipano in uno scenario
del genere: il server HTTP, il connettore lato server HTTP,
il connettore lato web container ed il web container.
Il server HTTP è quel componente che gestisce l'accesso
del client remoto (browser) ad un determinato URL o genericamente
a delle risorse.
Ad esempio nel caso di applicazioni web è compito del
server HTTP mappare un indirizzo del tipo http://www2.mokabyte.it/community
indirizzando le chiamate verso un web container dove sia stata
deployata la web application Community (che nel caso specifico
permette di gestire gli utenti della comunità di MokaByte).
Se il server HTTP è unico il processo di mappatura
è relativamente semplice e viene fatto con poche istruzioni
inserite nel file di configurazione (come verrà mostrato
successivamente).
Ma se il server HTTP si blocca o si rende indisponibile per
un motivo qualsiasi, tutto il sistema rimarrà irrimediabilmente
irraggiungibile. Questo significa che un sistema altamente
affidabile deve prevedere anche la replica del server HTTP,
cosa che implica l'introduzione di un ulteriore strumento
detto director (dal nome del più popolare ed affidabile
strumento commerciale prodotto da CISCO). Questo strumento
è infatti in grado di nascondere i diversi server HTTP
dietro un unico nome di dominio virtuale.
Collegandosi all'indirizzo www.mokabyte.it l'utente verrà
quindi rediretto su uno dei server HTTP disponibili.
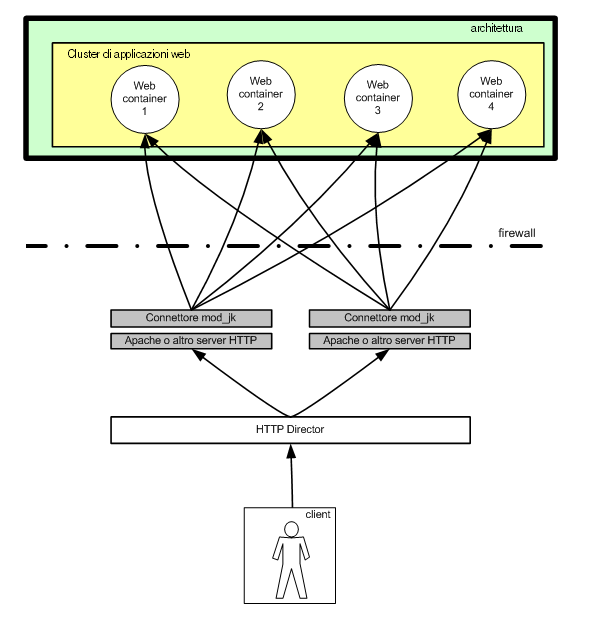
Figura
2
- Per aumentare la affidabilità del sistema si può
pensare di replicare il server HTTP, ponendo di fronte un
Director che unifichi tutti i server sotto un unico dominio
web
Questa
configurazione richiede maggiori investimenti di energie,
conoscenze e denaro: la sua analisi e trattazione esula dagli
scopi di questo articolo, essendo la sua installazione e gestione
una attività tipicamente a carico del reparto sistemistico.
Per questo motivo e per rendere le cose semplici, limiteremo
l'attenzione al caso di un solo server HTTP collegato ad una
batteria di web container: in questo scenario tutte le chiamate
per la web application in questione potranno essere indirizzate
verso un URL in gestione al server HTTP il quale poi le redirigerà
verso uno dei container web collegati.
Varianti e modifiche a questa semplice architettura potranno
essere realizzate in modo semplice operando sulla procedura
di configurazione che è riportata di seguito.
La
connessione Apache-Tomcat in round robin bilanciato
La connessione Apache-Tomcat viene realizzata tramite un apposito
connettore (il più usato è il mod_jk) che può
essere configurato in modo da realizzare un instradamento
delle connessioni in modalità round-robin pesato: ogni
volta che un nuovo client (browser) richiede l'esecuzione
della web application, verrà associato ad uno dei container
web in esecuzione. Tale associazione perdura per tutto il
tempo di vita della sessione dando vita a quella che si definisce
"sticky session", in modo che sia mantenuto il conversational
state.
La procedura di configurazione di una connessione load balanced
fra Apache e Tomcat richiede la definizione di alcune semplici
regole all'interno del server HTTP, mentre poco o nulla deve
essere fatto in Tomcat.
Il connettore che verrà usato per questi esempi è
il Coyote che utilizza come protocollo di comunicazione l'AJP
1.3. Altri connettori e protocolli possono essere utilizzati
come ampiamente mostrato in [MOD_JK].
Per concludere si possono riassumere i punti fondamentali
del load balancing:
- E'
un sistema che permette di connettere un server HTTP con
una batteria di container web.
- Permette
la ripartizione del carico fra tutti i container web, garantendo
migliori prestazioni
- Consente
la realizzazione di sistemi con un elevato livello di HA:
se anche uno o più server dovessero bloccarsi, i
client potranno continuare ad usufruire del sistema dato
che verranno rediretti su un'altra applicazione deployata
su un altro container
- Tutti
i container (e quindi anche le applicazioni) sono equivalenti
fra loro: quando un client inizia la comunicazione con uno
dei server, proseguirà sempre con lo stesso
- Il
sistema non garantisce il mantenimento della sessione: se
in un determinato momento il container si blocca o diviene
indisponibile, i dati di sessione andranno persi e l'utente
dovrà reiniziare da capo la procedura.
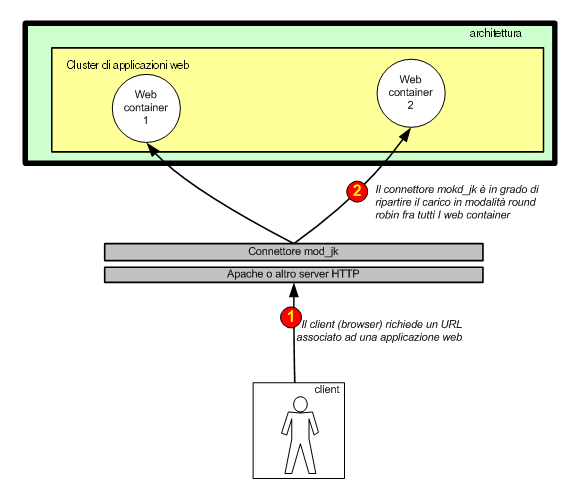
Figura 3 - Il load balancing permette di ripartire il
carico delle chiamate in modo circolare
Load
balancing: la configurazione di Apache
La prima cosa che è necessario fare è decidere
quali URL pattern dovranno essere rediretti da Apache verso
Tomcat: si potrebbe pensare di instradare tutte le chiamate
verso file del tipo *.jsp oppure tutte le request relative
ad indirizzi della forma www.mokabyte.it/servlet/*.
La cosa che si consiglia in genere è realizzare la
soluzione più pulita ed omogenea possibile, ad esempio
definendo un virtual host opportuno, in modo da non "sporcare"
il resto della configurazione del server e non avere sovrapposizioni
fra URL pattern diversi.
Ad esempio i server di mokabyte.it sono configurati per redirigere
tutte le chiamate del tipo www2.mokabyte.it/* verso applicazioni
web in esecuzione su Tomcat.
La definizione di un virtual host è una operazione
che si compie in modo piuttosto semplice tramite il seguente
script da inserire nel file di configurazione di Apache httpd.conf:
<VirtualHost
www2.mokabyte.it>
ServerAdmin someone@mokabyte.it
DocumentRoot /somewhere/here/there/docroot
ServerName nomeserver.mokabyte.it
# definisce il mapping URL-pattern e connessioni virtuali
JkMount /community/* balanced
JkMount /community* balanced
</VirtualHost>
in
questo caso si specifica che all'interno del dominio virtuale
www2.mokabyte.it è definito un URL pattern "community"
per il quale tutte le invocazioni saranno redirette verso
una batteria di Tomcat tramite la connessione definita dal
nome simbolico "balanced".
In questo modo l'invocazione verso la pagina di login della
Community di MokaByte
www2.mokabyte.it/community/login.jsp
sarà
rediretta verso i Tomcat. Per definire una connessione è
necessario inserire alcune regole all'interno di un file di
configurazione di apache detto workers.properties. All'interno
di questo file si definiscono tutte le connessioni verso altrettanti
server Tomcat. Ad esempio supponendo di avere due Tomcat denominati
tom1 e tom2, in workers.properties troveremo:
worker.tom1.port=8009
worker.tom1.host=server1.mokabyte.it
worker.tom1.type=ajp13
worker.tom1.cachesize=1
worker.tom1.lbfactor=10
worker.tom2.port=8009
worker.tom2.host=server2.mokabyte.it
worker.tom2.type=ajp13
worker.tom2.cachesize=1
worker.tom2.lbfactor=10
L'attributo
port specifica la porta (8009 è il valore convenzionale)
sulla quale resta in ascolto il connettore lato Tomcat (quello
che riceve le richieste inoltrate da Apache); l'attributo
type serve invece per specificare il tipo di protocollo utilizzato
per la comunicazione: in questo caso AJP13 indica il protocollo
AJP 1.3.
Ad ogni connessione è poi possibile assegnare un carico
o peso: il parametro lbfactor (il cui valore è un numero
relativo non assoluto) specifica il peso che deve e essere
assegnato ad un particolare server. Si potrebbe ad esempio
volere che il 70% delle chiamate siano redirette verso server1,
in modo da affaticare meno il Tomcat su server2 che potrebbe
a questo punto dedicare risorse di sistema per gestire altri
processi (ad esempio un database server).
Infine
una volta definite tom1 e tom2, è necessario riunirle
per definire il pool di connessioni sulle quali verrà
effettuato il round-robin pesato. Tale operazione di accorpamento
viene effettuata definendo un'altra connessione virtuale (il
cui nome spesso è convenzionalmente "loadbalancer")
specificando come attributo type il valore "lb",
ad indicare una connessione orientata al bilanciamento del
carico:
worker.loadbalancer.type=lb
worker.loadbalancer.balanced_workers=tom1,tom2
worker.loadbalancer.sticky_session=1
worker.loadbalancer.local_worker_only=1
worker.list=loadbalancer
Tramite
l'attributo balanced_workers si definisce la lista delle connessioni
che verranno associate al loadbalancer. L'attributo sticky_session
è particolarmente interessante: se impostato al valore
0 la connessione apache-tomcat avverrà realmente in
modalità round robin, ovvero ogni diversa chiamata
proveniente dallo stesso client viene dirottata su un server
diverso. Questa procedura aumenta il carico di lavoro del
servizio di sincronizzazione della sessione, per cui si raccomanda
di impostare sticky_session a 1 in modo da mantenere le connessioni
di un client sempre verso il medesimo Tomcat. Il round robin
in questo caso interviene solo in caso di blocco della istanza
di Tomcat alla quale ara agganciata la sticky session.
Discorso analogo per local_worker_only: se l'attributo è
presente la connessione offre funzionalità di round
robin ma solo di failover (ovvero lavorerà sempre e
solamente una connessione, mentre la seconda entrerà
in caso di blocco della prima).
Per poter utilizzare con successo il connettore è necessario
attivarne il funzionamento caricando in memoria il modulo
Apache corrispondente. Tale operazione viene effettuata con
questa semplice istruzione che dovrà essere inserita
prima degli script mostrati in precedenza e che facevano uso
del connettore.
LoadModule
jk_module modules/mod_jk.so
In
alternativa se invece si volesse utilizzare il connettore
JK2
LoadModule
jk2_module modules/mod_jk2.so
E'
inoltre necessario specificare dove si trova il file con la
definizione dei workers definendo al contempo livello di log
e locazione del file di log
JkWorkersFile
/etc/apache/workers.properties
JkLogFile /var/apache2/logs/mod_jk.log
JkLogLevel error
La
configurazione di Tomcat: il connettore Coyote
Terminata la parte di configurazione di Apache è necessario
abilitare il connettore lato Tomcat: il più utilizzato
ed aggiornato dal gruppo di Jakarta è il Coyote, che
fra le altre cose è in grado di "parlare"
vari protocolli.
In questo caso si abilita il Coyote per il protocollo AJP
1.3 in ascolto sulla porta 8009
<!--
An AJP 1.3 Connector on port 8009. Used by Apache mod_jk -->
<Connector className="org.apache.coyote.tomcat4.CoyoteConnector"
port="8009" minProcessors="5"
maxProcessors="75"
enableLookups="true"
redirectPort="8443"
acceptCount="10"
debug="0"
connectionTimeout="20000"
useURIValidationHack="false"
protocolHandlerClassName="org.apache.jk.server.JkCoyoteHandler"/>
Il
pezzo di script appena presentato deve essere inserito nel
file di configurazione di Tomcat. Nel caso in cui si usi una
versione JBoss-embedded del server si dovrà invece
lavorare sul file di configurazione tomcat41-service.xml presente
nella directory di deploy.
Nella versione Tomcat stand alone invece il file da modificare
è il server.xml che si trova nella directory di configurazione
(conf) di Tomcat.
Session
replication
Replicare le sessioni HTTP vuol dire sincronizzare i dati
relativi alla sessione utente su tutti i web container che
partecipano al cluster.
La prima cosa che si deve valutare, prima di procedere alla
installazione di un qualsiasi sistema di replica della sessione
è se realmente questa è una funzionalità
necessaria al sistema.
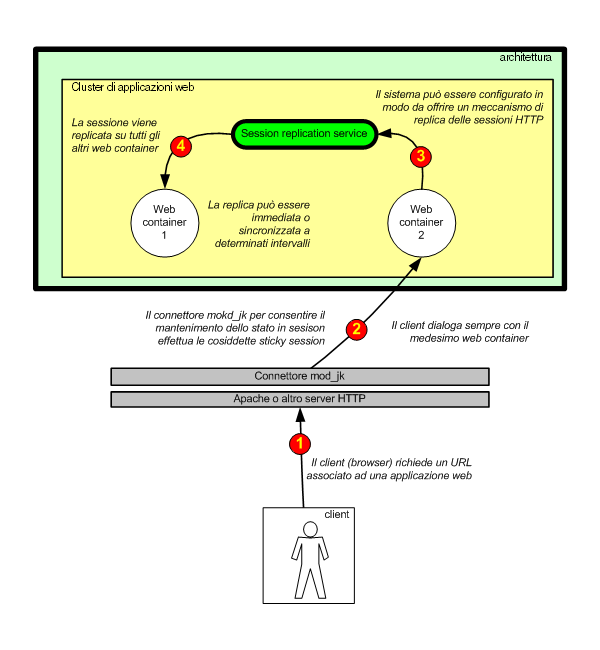
Figura 4 - Il servizio di replica delle sessioni permette
di replicare i dati in modo istantaneo
Session
replication infatti implica, rispetto al semplice round robin,
un salto di qualità non indifferente sia dal punto
di vista concettuale che per quello che concerne la complessità
del sistema (anche se poi all'atto pratico la gestione del
sistema non si complica enormemente).
Adottare la replica delle sessioni infine può significare
e intraprendere una strada che potrebbe non avere fine e che
potrebbe far venire la tentazione di spingersi verso territori
insidiosi e complessi: "già che ci siamo perché
non rendere persistente la sessione distribuita e perché
non ridondare anche il database con un sistema virtual data
server…".
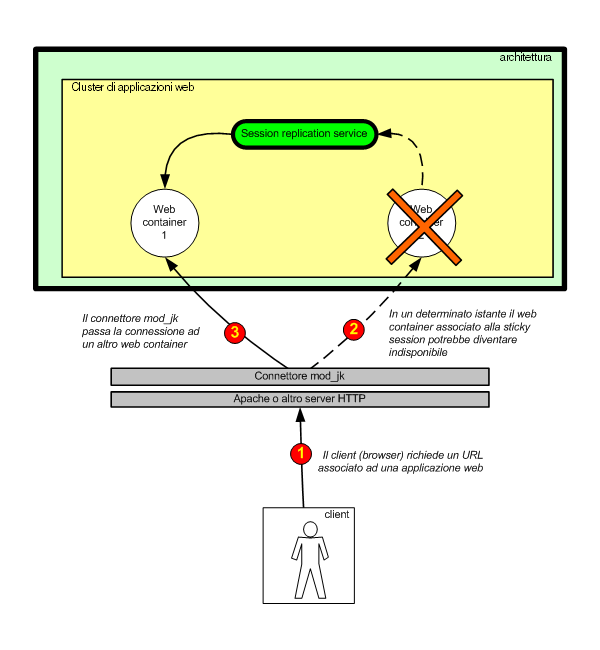
Figura 5 - La session replication entra in funzione se
un server web si blocca
E
sempre tenere presente che le prestazioni possono risentirne
visto che per ogni modifica ai dati in sessione il sistema
dovrà occuparsi di replicare la sessione su tutto il
cluster.
La
replica delle sessioni in Tomcat embedded JBoss
Sulla
base della piattaforma scelta come riferimento per questa
trattazione la parte web verrà servita da Tomcat nella
versione embedded in JBoss. In questo scenario si deve subito
dire che il web container di per sé non fornisce nessun
supporto per la replica della sessione ma si deve far uso
del supporto offerto da JBoss. Tutte le componenti necessarie
per la replica della sessione sono incluse in una serie di
moduli (fra cui il principale è jbossha-httpsession.sar)
sono già opportunamente configurati e deployati nella
all-configuration che si attiva, su piattaforma unix, tramite
il comando
jboss.sh
-c all
o
equivalentemente su sistema Windows
jboss.bat
-c all
Nel
file deploy/jbossha-httpsession.sar sono implementate tutte
le funzionalità di replica della sessione, che sono
indipendenti dal particolare web container utilizzato. Per
questo motivo con le opportune modifiche si potrebbe senza
problemi implementare le replica della sessione per altri
container come ad esempio Jetty o Resin.
Dopo aver attivato la replica delle sessioni è necessario
definire la politica di replica della sessione: immediata
o dilazionata ad intervalli di tempo. Tali impostazioni si
devono definire all'interno del file deploy/tomcat41-service.xml
di cui si riporta di seguito la porzione relativa alla replica
della sessione
<server>
…
<mbean code="org.jboss.web.catalina.EmbeddedCatalinaService41"
name="jboss.web:service=WebServer">
<attribute name="CatalinaHome">&catalina.home;</attribute>
<attribute name="SnapshotMode">instant</attribute>
<!-- you may switch to "interval" -->
<attribute name="SnapshotInterval">2000</attribute>
Il
punto chiave è rappresentato dall'attributo SnapshotMode:
il valore istant abilita la replica immediata delle modifiche
sulla sessione, mentre interval ha l'effetto opposto. In questo
caso si potrà specificare il tempo di intervallo fra
una sincronizzazione ed un'altra tramite l'attributo SnapshotInterval.
Infine per sfruttare le funzionalità di replica della
sessione all'interno di una applicazione web è necessario
abilitarne il funzionamento cluster-wide, cosa che può
essere ottenuta inserendo il tag <distributable/> all'interno
del descrittore di deploy WEB-INF/web.xml.
Ovviamente affinché la sessione sia replicabile è
necessario seguire le indicazioni J2EE in tal senso. La cosa
più importante è far uso di oggetti a scope
session che siano serializzabili.
Conclusione
Load balancing e session replication sono due feautures molto
importanti per garantire il massimo di affidabilità
e disponibilità di una applicazione web.
Per chi si avvicinasse a questi concetti per la prima volta
suggerisco di iniziare con la attivazione di una connessione
Apache-Tomcat con un connettore che metta in contatto un solo
web container per poi passare alla versione balanced.
Infine per coloro che volessero garantire un elevato livello
di disponibilità del servizio si potrà passare
alla realizzazione della replica della sessione.
Bibliografia
e riferimenti
[MOD_JK] - "Apache & Tomcat: come connettere i due
server per realizzare architetture scalabili, sicure performanti.
I parte: introduzione allo scenario e primi con nettori"
e seguenti, di Giovani Puliti MokaByte 82 - Febbraio 2004.
www.mokabyte.it/2004/02
[JK-JB]"UsingMod_jk1.2WithJBoss" - wiki web site
su JBoss. http://www.jboss.org/wiki/Wiki.jsp?page=UsingMod_jk1.2WithJBoss
[JBCLUSTER] - JBoss/Documentation - http://www.jboss.com/docs/index
[JGROUPS2] - JGroups - A Toolkit for Reliable Multicast Communication
http://www.jgroups.org/javagroupsnew/docs/index.html
|


