|
Introduzione
L'insieme degli elementi che partecipano alla realizzazione
dell'editor di testo XML per il Content Management System
è raggruppato in un package a cui è stato assegnato
in via provvisoria il nome "it.mokabyte.cms.applet.editor".
La sua struttura interna è rappresentata dal diagramma
in figura 1
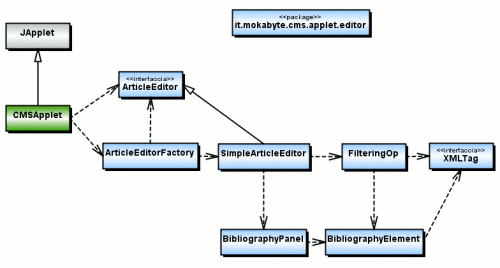
Figura 1 - Le classi dell'applet CMS
La
prima cosa da notare è come l'Applet vero e proprio
sia al momento alieno al package. La posizione riflette una
diversità di scopo tra l'applet in sè ed il
componente che manipola il testo. L'integrazione dell'Applet
nel package dipende in larga parte da un accordo in fieri
circa l'organizzazione degli elementi dell'applet inteso come
client di articoli e si tratta, fortunatamente, di una questione
poco più che formale.
Il
package it.mokabyte.cms.applet.editor, in superficie
Il rapporto che intercorre tra CMSApplet e gli strumenti del
package it.mokabyte.cms.applet.editor è definito in
relazione ai compiti assolti dall'applet rispetto al sistema
CMS generale e dall'editor rispetto all'applet. L'editor si
occupa di produrre il corpo dell'articolo dove "corpo"
è inteso come contenuto di testo formattato. L'applet
rappresenta lo strato di comunicazione ed eventualmente di
integrazione del contenuto dell'articolo. In questo senso,
l'applet contiene il componente editor è dialoga con
esso comunicando ed estraendo un documento XML. L'applet a
sua volta dialoga con il contenitore web in cui è inserito
(ad esempio una pagina JSP) per integrare il documento XML
con gli elementi che possano essere necessari per la pubblicazione
dell'articolo oppure comunica direttamente il documento XML
al server CMS. La distinzione tra l'applet-contenitore e l'editor-contenuto
permette di separare le questioni che riguardano la produzione
di un documento di testo formattato con quelle inerenti alla
sua distribuzione ed alla eventuale integrazione con informazioni
che non attengano alla scrittura in senso stretto.
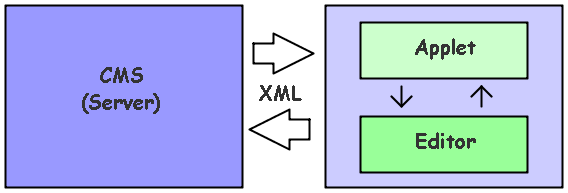
Figura 2 - Distribuzione delle attività
L'oggetto
della conversazione tra applet ed editor è il corpo
dell'articolo. La forma scelta per la comunicazione di un
articolo è una coppia di stringhe, una identifica l'articolo,
l'altra trattiene la versione XML del suo contenuto. La separazione
tra identificatore e contenuto appare necessaria in ragione
della mancanza, in quella parte di documento XML affidata
alle cure dell'editor, di un nodo che conservi lo stesso identificatore
e della necessità di conoscere questa particolare stringa
durante la formazione del documento XML per la composizione
dei nodi "image". Intendendo con il termine "editor"
l'insieme di elementi del package it.mokabyte.cms.applet.editor
(e non solo il componente visuale deputato all'interazione
con l'utente) è facile osservare come l'interfaccia
ArticleEditor rappresenti il protocollo di comunicazione,
mediato dal fornitore ArticleEditorFactory. I due elementi
da ultimo citati rappresentano la connessione tra il componente
che scelga di usare i servizi offerti dal package it.mokabyte.cms.appelt.editor
ed il contenuto effettivo del package stesso. In altri termini,
ArticleEditor ed ArticleEditorFactory sono gli unici elementi
pubblici del package in argomento. Lo scopo di ArticleEditorFactory
è unicamento quello di fornire l'accesso protetto ad
un'istanza concreta di ArticleEditor. Il contenuto di quest'ultima
interfaccia è minimo ma esauriente per gli scopi dell'editor
di testo:
package
it.mokabyte.cms.applet.editor;
/**
* Un oggetto ArticleEditor contiene l'interfaccia di comunicazione
tra
* l'Applet ed il componente GUI deputato alla manipolazione
del contenuto
* dell'articolo. Lo stesso ArticleEditor consente altresì
l'accesso ad una
* istanza del componente GUI affinchè questa sia inserita
in un'interfaccia
* grafica arbitraria.
*/
public interface ArticleEditor {
/**
* Restituisce il contenuto di testo dell'articolo trattato
dall'Editor
* @return testo in formato XML
*/
String getArticleContent();
/**
* Restituisce l'identificatore dell'articolo trattato dall'Editor
* @return una stringa di identificazione
*/
String getArticleID();
/**
* Imposta l'articolo trattato dall'Editor
* @param content il contenuto in formato XML
* @param id la stringa di identificazione dell'articolo
*/
void setArticle(String content, String id);
/**
* Restituisce il componente GUI deputato alla realizzazione
dell'articolo
* @return un oggetto JComponent
*/
javax.swing.JComponent getVisualComponent();
}
Come
si nota, l'interfaccia espone tre metodi di comunicazione
del contenuto ed un metodo che consente all'applet o ad una
qualsiasi interfaccia grafica di inserire tra i suoi componenti
un editor pienamente operativo. Data l'interfaccia ArticleEditor
ed il produttore ArticleAditorFactory, l'inserimento del componente
che manipola il contenuto dell'articolo avviene nella forma
minima:
ArticleEditor
editor = ArticleEditorFactory.getInstance().newArticleEditor();
aContainer.add(editor.getVisualComponent());
Insomma,
tutto fuorché complicato da usare. La scelta di un'esposizione
tanto ridotta del contenuto del package it.mokabyte.cms.applet.editor
è motivata da ragioni pratiche. La concreta realizzazione
dell'editor di testo è il risultato di una serie di
scelte ampiamente discrezionali. Il che significa, principalmente,
che tali scelte potranno e dovranno essere riviste quando
ci si accorga della loro perfettibilità o inadeguatezza.
L'isolamento del contenuto del package garantisce all'applet
l'immunità dai mutamenti che occorrano alla realizzazione
dell'editor. Lo svantaggio è che nulla di ciò
che concretamente produce un risultato nel package è
estensibile. Trattandosi tuttavia di un progetto open source
chiunque potrà lecitamente modificare qualsiasi parte
del package in questione, il che riduce di molto l'inconveniente.
In più, nel rispetto del contratto definito dall'interfaccia
ArticleEditor, quelle modifiche saranno usabili da qualsiasi
applet che si sia appoggiato al package it.mokabyte.cms.applet.editor
nella sua idea originale.
Sotto
la superficie
Abbiamo descritto il metodo per integrare l'editor di testo
nell'applet e le funzioni che l'applet deve poter riconoscere
nell'editor grattando la superficie del package it.mokabye.cms.applet.editor.
Per la concreta realizzazione dell'editor scaviamo nella parte
del package che ne contiene l'implementazione.
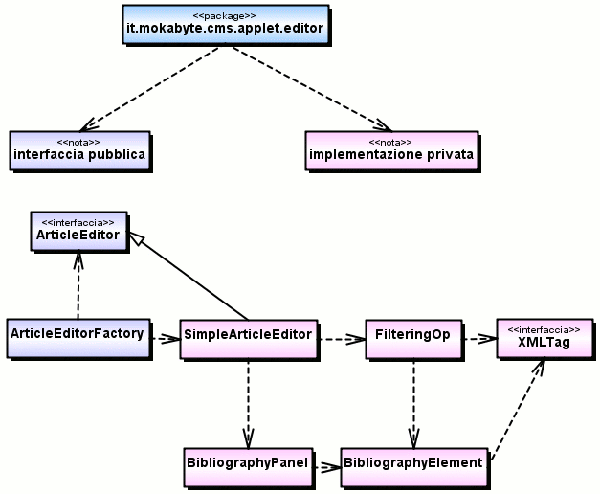
Figura 3 - Schema del contenuto di it.mokabyte.cms.applet.editor
Abbiamo
detto dell'ambito ristretto (package) riservato alle classi
evidenziate in rosa. Vale la pena sottolineare che l'effetto
ottenuto da questa distribuzione delle classi è, per
via delle norme sulla compatibilità binaria del codice
Java, equiparabile a quella che si ottiene in una classe unica
i cui membri siano distinti in parte pubblica (interfaccia
o contratto pubblico) e parte privata (implementazione). Vediamo
il ruolo di ogni "membro privato" (tecnicamente
nè membri, mè privati, chiamiamola metafora
informatica). SimpleArticleEditor contiene l'editor di testo
e gestisce il rapporto tra l'interazione utente ed il sistema
nel suo complesso. Monopolizza la parte più rilevante
di controllo e trattiene un pezzo di interfaccia grafica:
la barra dei comandi e l'editor di testo. Ciò che resta
dell'interfaccia è definito in BibliographyPanel ed
in questa stessa classe è contenuto il controllo dell'interazione
utente riferita alla manipolazione della bibliografia. Il
modello è separato in due parti. La bibliografia risiede
in FilteringOp, il corpo dell'articolo è incapsulato
nel modello dell'editor di testo. Nella sua integrità,
il modello di CMSEditor deve contenere quella parte di articolo
che, secondo il progetto, si è scelto di affidare alle
sue cure. Questo comprende porzioni di testo variamente formattato,
indirizzi relativi a risorse web ed allegati all'articolo
(ad esempio le immagini) ed i riferimenti bibliografici, separati
in quanto porzione logicamente distinta dal contenuto di testo
dell'articolo (benchè formati anch'essi di testo e
indirizzi a risorse estenerne). L'insieme di questi dati entra
ed esce dall'editor in forma di documento XML, attraverso
i metodi dell'interfaccia ArticleEditor. Una volta entrati
nell'editor, i dati vengono filtrati da SimpleArticleEditor
attraverso FilteringOp. Parte finisce nel modello StyledDocument
che alimenta il JTextPane, parte finisce in quel vettore di
riferimenti bibliografici posseduti da FilteringOp. In uscita
si realizza il percorso inverso. SimpleArticleEditor prende
lo StyledDocument ed il vettore di riferimenti bibliografici,
li passa attraverso FilteringOp e restituisce un documento
XML. A conti fatti, FilteringOp altri non è che un
insieme di operazioni e campi usato solo ed esclusivamente
da SimpleArticleEditor. FilteringOp sarebbe stato un eccellente
candidato a diventare almeno una classe interna. Sfortuna
vuole che le procedure di parsing siano piuttosto lunghe.
Dovendo scegliere tra infilare altre quattrocento linee nella
classe SimpleArticleEditor, che occupandosi di interfacce
non è di suo una silfide, e malmenare un po' Java,
ottenendo una classe (SimpleArticleEditor) affiancata da un
"modulo" (FilteringOp), ho preferito la seconda
via. Non è l'unica opzione esistente in Java per realizzare
una separazione "fisica" tra due moduli. A rigore,
un singleton FilteringOp avrebbe assolto allo stesso compito,
con più eleganza. Mi è parso tuttavia che l'uso
di questo strumento potesse mascherare la scelta di creare
un elemento rigido ed intestensibile.
L'editor
L'editor di testo è la coniugazione di due componenti.
La barra dei comandi ed il pannello di testo. La barra dei
comandi contiene l'insieme dei controlli che consentono di
stabilire il formato applicato al testo, il pannello di testo...beh,
serve per scrivere. I due componenti sono creati nella classe
SimpleArticleEditor. Il pannello di testo è un JTextPane,
la barra dei comandi un JPanel con una serie di pulsanti JButton
il cui aspetto è determinato da un delegato UI personalizzato
(CustomButtonUI). In generale, l'applicazione di un formato
di testo conseguente alla pressione di uno dei controlli è
ramificata in due percorsi, scelti a seconda che esista o
meno una selezione di testo. Ad esempio, altro è applicare
il formato "lista" ad una successione di linee selezionate,
altro è applicare il formato testo in un punto del
documento: nel primo caso l'editor trasformerà le linee
selezionate in una successione di elementi appartenenti ad
una lista, nel secondo introdurrà una nuova sezione
di testo di tipo lista, ordinata o non. La maggior parte della
classe SimpleArticleEditor si occupa di decidere ed applicare
formati al pannello di testo, dietro l'impulso dei controlli.
I formati applicabili sono definiti nella classe (modulo)
FilteringOp. SimpleArticleEditor recupera questi stili usando
il metodo FilteringOp.getStyle(Object id). Gli identificatori
per gli stili sono trattenuti come campi publici, statici
e costanti di FilteringOp, dunque il procedemento per ottenere
uno stile si riassume in:
javax.swing.text.Style
stile = FilteringOp.getStyle(FilteringOp.ID_TEXT);
Nel
caso più semplice, SimpleArticleEditor applica al testo
lo stile così ottenuto usando i metodi predefiniti
di JTextPane:
//textPane
è istanza di JTextPane...
textPane.setParagraphAttributes(stile, true);
textPane.setCharacterAttributes(stile, true);
Da
testo a XML: FilteringOp e popXML
Implementando ArticleEditor, SimpleArticleEditor si impegna
a definire il procedimento concreto per trasformare il testo
visualizzato da JTextPane in un documento XML. Lo fa passando
la palla a FilteringOp. FilteringOp possiede, tra l'altro,
due metodi deputati al passaggio da XML a testo formattato
e viceversa. I due metodi sono:
/**
* Inserisce un JTextPane il contenuto di un documento XML.
* @param dest il JTextPane da riempire
* @param source il testo XML da analizzare
*/
static void pushXML(javax.swing.JTextPane dest, String source)
/**
* Trasforma il contenuto di un JTextPane in un documento XML
* @param source il JTextPane contenente il testo da trasformare.
Si assume
* che il pannello di testo sia formattato usando esclusivamente
gli stili
* definiti da CMSFilter
* @param source il pannello di testo che contiene il documento
da analizzare
+ @param dest il buffer di caratteri in cui è destinato
il documento XML
* @param artID la stringa che denomina l'articolo da produrre.
*/
static void popXML(javax.swing.JTextPane source, StringBuffer
dest, String artID)
Il
metodo pushXML analizza la stringa source assumendo che sia
il testo di un documento XML e riempie il pannello di testo
in argomento con la traduzione in forma stilizzata. popXML
ha il compito speculare di tradurre ciò che è
contenuto nel pannello di testo in un documento XML. Il risultato
è introdotto nel buffer di caratteri "dest".
popXML sfrutta a piene mani la struttura di un documento javax.swing.text.Document.
Un Document è ispirato da SGML e si presenta come un
albero di elementi (javax.swing.text.Element) caratterizzati
da un contenuto e da una serie di attributi. Il contenuto
di un Element può essere un altro Element. Un JTextPane
possiede come documento predefinito un'istanza di StyledDocument,
sotto-classe di Document. Uno StyledDocument ha un Element
come radice, suddiviso in tanti Element quanti sono i paragrafi
del testo, dove un paragrafo è definito come una sequenza
di caratteri racchiusi tra due interruzioni di linea. A loro
volta, gli elementi di tipo paragrafo sono divisi in sotto
elementi (anche) di tipo testo. Durante la scrittura del testo,
SimpleArticleAditor altro non fa, attraverso il suo JTextPane,
che creare nuovi elementi associandogli degli attributi o
modificare gli attributi di elementi già in essere.
L'attributo principale assegnato dall'editor ed osservato
dal parser durante la traduzione è "AttributeSet.Name".
Partendo dalla radice del documento, il parser realizzato
in popXML scorre tutti i paragrafi racchiusi come sotto-elementi
della radice, ricava per ognuno di essi l'attributo "AttributeSet.Name"
e confronta il valore ottenuto con un set predefinito di valori.
Ogni paragrafo, e in genere ogni javax.swing.text.Element,
possiede oltre al set di attributi l'indice della posizione
di partenza rispetto al documento cui appartiene ed il valore
di lunghezza, che equivale al numero di caratteri appartenenti
al paragrafo. Nel caso più semplice, quello di un tipo
di paragrafo che sappiamo non possedere elementi annidati,
ad esempio un titolo, la parzializzazione si traduce nel ricavare
la porzione di testo associata al paragrafo ed infilarla tra
due tag XML. Qualora il paragrafo possieda degli elementi
annidati, l'analisi è più tediosa ma non meno
semplice. Come per la radice, si scompone il paragrafo nei
suoi sottoelementi e per ognuno di essi si ricava il "nome"
ed eventualmente gli altri attributi necessari alla costruzione
del nodo XML, inseriti durante la stesura. Ad esempio, quando
si inserisce un collegamento ipertestuale l'editor richiede
con una finestra di dialogo l'indirizzo del collegamento.
Questo indirizzo è applicato ad un set di attributi,
il cui nome (AttributeSet.Name) è "FilterngOp.ID_LINK",
usando la chiave "FilteringOp.ID_URL". Il set di
attributi è poi applicato al pannello di testo come
stile di carattere corrente. Il risultato è che quel
sotto-elemento, di tipo carattere, del paragrafo corrente,
che subisce la modifica, avrà tra i suoi attributi
una coppia ordinata (ID_URL, url inserito), facilmente estraibile
durante il parsing. Questo meccanismo riassume tutta l'opera
di conversione. Quasi. Non avendo definito un tipo personalizzato
di Document, occorre sottostare alle scelte di chi abbia realizzato
lo StyledDocument. In alcuni casi, la struttura dell'oggetto
Document è più frammentata di quanto non ci
si aspetterebbe. Ad esempio, nel caso in cui l'utente spezzi
lo stile di carattere di un paragrafo introducendone un secondo
tipo, come avviene qualora si inserisca un collegamento all'interno
di una sezione di testo, e, successivamente, riporti quella
sezione di testo alle caratteristiche originali, applicando
allo stesso testo o ad una porzione più ampia, che
lo comprenda, il formato "testo", allora l'elemento
paragrafo, pur possedendo un'unico formato di testo, risulterà
spezzato in tanti sottoelementi quante siano state le applicazioni
di formato. E' inoltre possibile che esistano dei sotto-elementi
di tipo carattere a cui tuttavia non sia associato alcun testo.
Ancora, ai fini della produzione del documento XML, certi
elementi devono essere considerati come ininfluenti, come
avviene qualora l'utente inserisca una o più linee
vuote per separare due sezioni di testo. Per queste ragioni,
il parser è addestrato a scartare alcuni elementi qualora
essi non contengano caratteri o ne contengano ma non siano
significativi.
Da
XML a Testo: FilteringOp e pushXML
Nel procedimento di conversione di un documento XML in testo
formattato, FilteringOp si occupa di ricomporre virtualmente
il testo attraverso il metodo pushXML. L'analisi del documento
XML è fatta usando le librerie JAXP (Java Api for XML
Processing) incluse nella versione 1.4 di Java ed in particolare
attraverso il parser javax.xml.parsers.DocumentBuilder. Un
DocumentBuilder è molto maneggevole anche se meno efficiente
di un SAXParser. In particolare, è additato di una
creazione eccessiva di oggetti. Nel contesto dell'Applet,
il DocumentBuilder esiste nell'ambito ristretto di un'invocazione
di pushXML, il che consente al Garbage Collector di occuparsi
con disinvoltura degli sforzi riproduttivi di questo presunto
coniglio dell'OOP. In cambio, DocumentBuilder offre un modello
d'analisi di un documento XML estremamente intuitivo. Al metodo
pushXML il documento XML arriva attraverso una stringa di
testo. La stringa è affidata ad un involucro ByteArrayInputStream
per poi essere data in pasto ad un DocumentBuilder. Questo
restituisce un oggetto org.w3c.dom.Document da cui è
prelevato il nodo radice attraverso il metodo org.w3c.dom.Document.getDocumentElement().
Anche XML è figlio di SGML e questo motiva la similitudine
della conversione da XML a StyledDocument rispetto a quella
da StyledDocument a XML. Il nodo radice è scomposto
nei suoi sotto-nodi. I nodi XML sono riconosciuti dal parser
ricorrendo ad un insieme di costanti contenute nell'interfaccia
it.mokabyte.cms.applet.editor.XMLTag. XMLTag contiene, tra
l'altro, le stringhe usate dal parser per costruire il documento
XML, sempre in forma di costanti. La conversione da XML a
StyledDocument non presenta aspetti di rilievo. Si può
notare solo che in questo procedimento FilteringOp può
decidere alcuni aspetti riguardanti la distribuzione degli
elementi testuali dell'articolo, ad esempio inserendo due
spazi di separazione tra un titolo di paragrafo ed il testo
che lo segue.
Comporre
la bibliografia
La stesura del documento di testo è affidata a pulsanti
di definizione del formato, ad un'area di testo stilizzato
ed alle dita degli autori. La parte relativa ai riferimenti
bibliografici è definita usando un pannello secondario,
attivabile attraverso un controllo sulla barra dei comandi.
Il procedimento di creazione o modfica della bibliografia
è elementare. Il pannello iniziale mostra un elenco
dei riferimenti bibliografici inseriti e consente di modificarli,
cancellarli od inserirne di nuovi. Dietro le quinte, un riferimento
bibliografico è definito come un oggetto it.mokabyte.cms.applet.editor.BibliographyElement.
Un BibliographyElement è un oggetto in grado di trasformarsi
da e per un nodo XML, pensato per essere incluso in una collezione
di oggetti. L'insieme dei riferimenti bibliografici è
"fisicamente" mantenuto in un campo di FilteringOp.
Il campo è nutrito dal procedimento di lettura del
documento XML che è passato a FilteringOp quando l'applet
carica un articolo dal server. Ad ogni attivazione del pannello
dei riferimenti bibliografici, il component BibliographyPanel
riceve questa lista di oggetti BibliographyElement affinchè
sia presentata all'utente. Al termine del procedimento di
modifica (segnatamente, attraverso un pulsante appartenente
a BibliographyPanel), la lista di oggetti BibliographyElement
posseduta da BibliographyPanel è usato per reimpostare
il campo di FilteringOp. In tutto questo, BibliographyPanel
e FilteringOp non sono a conoscenza della reciproca esistenza.
Il processo è mediato da SimpleArticleEditor. Alla
pressione del pulsante "bibliografia", SimpleArticleEditor
prende i dati bibliografici di FilteringOp e li passa a BibliographyPanel.
Il pulsante di BibliographyPanel che termina il procedimento
di modifica della bibliografia è collegato ad un ascoltatore
posseduto da SimpleArticleEditor. Grazie a questo ponte, SimpleArticleEditor
è in grado di capire quando recuperare i riferimenti
bibliografici da BibliographyPanel per reimmetterli in FilteringOp.
Si tratta, in definitiva, del noto sistema dell'oggetto osservato
e di quello osservabile, realizzato direttamente con un ActionListener
anzichè con un'interfaccia apposita.
Conclusioni
Forse l'editor funziona, certamente ha una "to-do list"
piuttosto lunga. Per lo più la lista contiene aspetti
inerenti all'automazione dell'editor. Potendo creare un editor
di testo formattato da zero, il desiderio è quello
che il componente sia arrendevole alle aspettative di chi
lo usi, ad esempio applicando un formato lista come si vorrebbe
e non come farebbe un venusiano. L'aspetto meno simpatico
per chi programmi è che un editor di testo è
un'interfaccia utente tra le più instabili, dal punto
di vista della libertà che l'utente ha ed è
giusto che pretenda di avere. Capita allora che dopo aver
previsto che, nel caso in cui l'utente inserisca una lista
a metà del testo, l'editor debba separare la sezione
di testo in due parti intervallate da una sezione di tipo
lista, si scopra che due trasformazioni successive generino
le più orrende nefandezze. Lo stato attuale dell'editor
è questo. Da un lato occorre comprovare, attraverso
una serie di test, la capacità del sistema di produrre
sempre e comunque un documento XML correttamente formato.
Dall'altro è necessario che sia restio ad inventare
formati durante la stesura.
Bibliografia
La realizzazione di un editor di testo formattato, ed in generale
un'analisi approfondita dell'intero package javax.swing.text
è ad oggi nelle mani di pochi oscuri negromanti. E
da numerose ed ostinate ricerche in rete, pare a chi scrive
che se la tengano ben stretta.
|

