|
Introduzione
Alla base dello sviluppo di un’applicazione
ad oggetti vi è il processo di modellazione
tramite il quale si cerca di individuare le varie
entità concrete che entrano in gioco e
di associare ad esse una classe che le rappresenti
all’interno dell’applicativo, ecco per
esempio che se dovessimo sviluppare un programma
sui fruttivendoli individueremo l’entità
negozio,frutta,proprietario,ecc e le modelleremo
con le rispettive classi che incapsulano le caratteristiche
delle entità.
Con ogni probabilità il nostro applicativo
dovrà essere usato in momenti diversi e
di conseguenza lo stato degli oggetti (istanze
delle classi) che rappresentano, per esempio,
l’insieme delle mele di un negozio dovrà
essere memorizzato in un formato persistente in
modo da poterlo recuperare in futuro. Lo strato
di persistenza maggiormente diffuso (soprattutto
in applicazioni “Enterprise”) è
costituito da database ed in particolar modo da
database relazionali.
Imbattendosi in un’applicazione del genere
ci si rende preso conto che esiste una (stretta)
relazione tra classi e tabelle del nostro DB,
tra oggetti e “righe” delle nostre tabelle
e tra proprietà di oggetti costituite da
altri oggetti del nostro applicativo e relazioni
(uno-uno,uno-molti,molti-molti) tra le varie entità
del DB.
A questo punto ci si trova di fronte ad una scelta:
scrivere “a mano” il codice SQL che
ci serve per creare (INSERT ....), modificare
(UPDATE ...) e recuperare (SELECT) gli oggetti
il cui stato è memorizzato nel database
oppure affidare questo compito (alla lunga ripetitivo)
ad un “motore” di bridging: uno strato
software che si interpone tra l'applicativo e
il database il quale, opportunamente configurato,
mantiene sincronizzato, con il DB sottostante
e a prescindere dal tipo di DB, lo stato degli
oggetti persistiti in modo trasparente allo sviluppatore.
Esistono diversi software in grado di svolgere
il compito descritto (Castor, OJB, ecc.) ma tra
tutti quello che più ha avuto fortuna e
diffusione è Hibernate.
Il meccanismo di bridging è alla base dei
motori di persistenza CMP (Container Managed Persistence)
degli application server vi è però
una sostanziale differenza: le entità in
un sistema j2ee sono modellate da EJB di tipo
entity, tali classi devono implementare interfacce
o essere sottoclassi dello standard enteprise,
per essere usata con Hibernate, invece, una classe
deve essere POJO (Plain Old Java Object) ovvero
un semplice JavaBean costituito dalle proprietà
e i rispettivi getters/setter (quando serve).
Nel suo complesso questo articolo vuole essere
un'introduzione a questa tecnologia avrà
un taglio prevalentemente pratico: si forniranno
esempi su come modellare il caso “del fruttivendolo”
partendo dalle classi base ed arrivando alle relazioni
intercorrenti tra queste classi, verrà
inoltre mostrato, come è possibile integrare
Hibernate con Struts, Spring e Jboss.
La versione di Hibernate a cui faremo riferimento
in questo articolo è la 2.1.6, il DataBase
usato sarà MySql 4.*.
Installazione
e configurazione
Installare Hibernate alla fine di poterlo usare
all'interno della nostra applicazione è
un'operazione semplice, basta rendere “visibili”
le seguenti librerie ricavabili dall'archivio
scaricabile dal sito [1]:
- dom4j
(obbligatorio)
- CGLIB
(obbligatorio)
- Commons
Collections, Commons Logging (obbligatorie)
- ODMG4
(obbligatorio)
- EHCache
(obbligatorio)
- Log4j
(opzionale)
Dai nomi delle librerie appena citate è
intuitivo ricavarsi i nomi dei file jar presenti
nella distribuzioni sotto la cartella “lib”.
Chiaramente occorre utilizzare anche “hibernate2.jar”
presente nella “root” della distribuzione.
Per
poter usare Hibernate abbiamo bisogno di una classe
che implementi l'interfaccia SessionFactory definita
nella distribuzione standard, fortunatamente,
sempre nella distribuzione, ne troviamo un'implementazione
di default: net.sf.hibernate.impl.SessionFactoryImpl.
Questa classe serve per creare nuove sessioni
“di lavoro” tramite le quali è
possibile manipolare gli oggetti persistiti. Il
SessionFactory per poter essere usato necessita
di essere preventivamente configurato per via
programmatica (che non considereremo) oppure tramite
un file di configurazione (che tratteremo in questo
articolo).
Il file di configurazione per default deve essere
visto nella root del nostro classpath, può
essere un file di proprietà (hibernate.properties)
oppure un file xml (hibernate.cfg.xml), è
su quest'ultimo formato che baseremo il nostro
applicativo.
Listato
1 - Esempio di file hibernate.cfg.xml
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration
PUBLIC "-//Hibernate/Hibernate Configuration
DTD//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-2.0.dtd">
<hibernate-configuration>
<session-factory>
<property
name="dialect">net.sf.hibernate.dialect.MySQLDialect</property>
<property name="show_sql">true</property>
<property name="transaction.factory_class">
net.sf.hibernate.transaction.JDBCTransactionFactory
</property>
<!-- Mapping files -->
<mapping resource="lc/hibernate/Frutto.hbm.xml"/>
</session-factory>
</hibernate-configuration>
Il
listato 1 rappresenta una versione molto succinta
del file di configurazione, è importante
far notare che in un'ambiente enterprise un SessionFactory
dovrebbe essere in grado di ricavarsi da solo
le connessioni database, a tal proposito esistono
dei parametri di configurazione, qui omessi, che
consentono di specificare un DataSouce raggiungibile
via JNDI. Con l'esempio che ci accingiamo ad implementare
saremo noi a fornire le connessioni, via programmatica,
al SessionFactory.
Analizziamo le proprietà specificate nel
listato 1:
dialect: sicuramente il parametro più importante,
lega hibernate al DB sottostante implicando il
come le varie operazioni di una sessione vengono
“tradotte” in SQL nativo proprio del
DB.
show_sql: è un parametro booleano utile
per debug, fa in modo che ogni query generata
da Hibernate venga “loggata”
transaction.factory_class: specifica “chi”
si deve occupare delle transazioni, nel nostro
esempio lo strato JDBC, un'altra possibilità
è delegare questo compito a JTA. Naturalmente
se il DB non supporta le transazioni allora il
dialect corrispondente fornisce dei metodi dummy
e di fatto ogni operazione di una singola transazione
avviene in maniera non transazionale.
Le restanti righe indicano al SessionFactory quali
sono i file che specificano le classi persistite,
file che vedremo in seguito
Mappiamo
le nostre classi
La figura 1 mostra il modello che andremo a a
mappare.
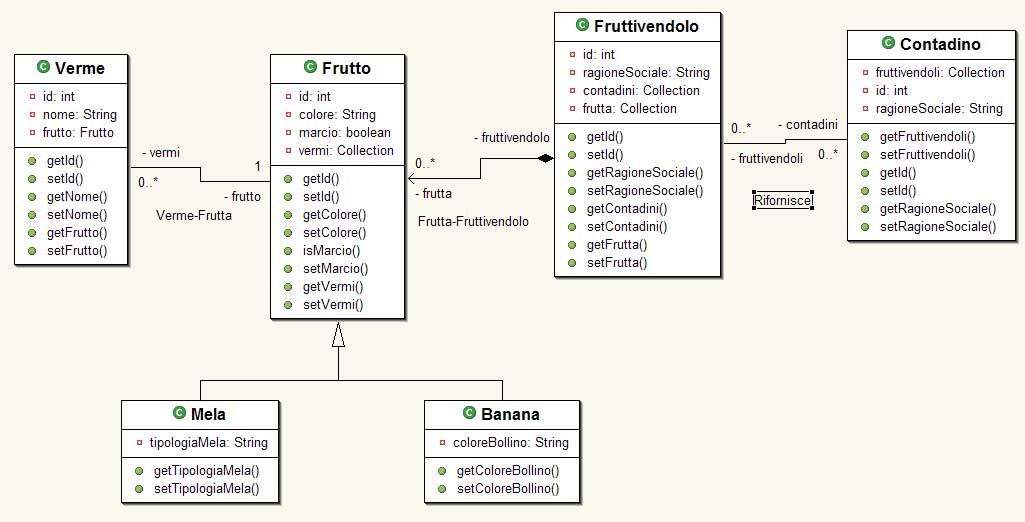
Figura 1 – Diagramma del modello
(clicca sull'immagine per ingrandire)
Nel diagramma notiamo 6 classi, le proprietà
di ciascuna classe sono dichiarate come private
ed ogni proprietà ha il corrispondente
getter e setter entrambi pubblici. Frutto ha 2
sottoclassi. Banana e Mela, Ogni frutto sta in
un fruttivendolo e un Fruttivendolo ha molta frutta,
esiste dunque una relazione uno-molti tra Frutta
e Fruttivendolo. Anche tra Frutto e Verme esiste
una relazione uno-molti ma, a differenza della
precedente questa è navigabile da entrambe
le classi ovvero esiste la possibilità,
avendo il Verme, di ottenere il frutto che lo
contiene mentre prima non è possibile ottenere
il fruttivendolo da frutto. Molti oggetti Contadino
riforniscono i vari oggetti Fruttivendolo: esiste
una relazione molti-molti tra queste ultime due
classi.
Faccio notare come le relazioni con cardinalità
maggiore di uno vengono modellate con oggetti
che implementano l'interfaccia java.util.Collection.
Tutte le classi possono essere definite “anemiche”
nel senso che gli unici metodi di cui sono dotate
sono i getters e i setters, non hanno logica business
al loro interno. La classe che per prima andiamo
a mappare (e unica in questa prima parte) è
Frutto di cui riporto il codice sorgente ne listato
2 omettendone i metodi.
Listato
2 – La classe Frutto
package lc.hibernate;
import
java.util.Collection;
public
class Frutto {
private int id;
private String colore;
private boolean marcio;
private Collection vermi;
//getter
and setter
}
I
file di mapping devono essere file xml, possiamo
mappare una o più classi in un singolo
file, non è obbligatorio creare un file
per ogni classe che rendiamo persistente ciò
nonostante è bene separare i mapping al
fine di rendere più leggibile e di facile
manutenzione il mappaggio.
Creiamo il file Frutto.hbm.xml come mostrato nel
listato 3
Listato
3 - Frutto.hbm.xml: mapping della classe Frutto
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-2.0.dtd">
<hibernate-mapping>
<class name="lc.hibernate.Frutto"
table="frutta" discriminator-value="not
null">
<id name="id" type="int"
column="f_id" unsaved-value="0">
<generator class="identity"/>
</id>
<discriminator column="tipo" type="string"/>
<property name="colore"/>
<property name="marcio" column="is_marcio"/>
<subclass name="lc.hibernate.Mela"
discriminator-value="mela">
<property name="tipologiaMela"/>
</subclass>
<subclass name="lc.hibernate.Banana"
discriminator-value="banana">
<property name="coloreBollino"/>
</subclass>
</class>
</hibernate-mapping>
L'elemento
hibernate-mapping è l'elemento radice all'interno
del quale vi sono una o più elementi class
che definiscono le classi vere e proprie. L'elemento
class del listato 3 ha i seguenti attributi:
- name:
il nome della classe che viene mappata
- table
la tabella del database “sottostante”
che rappresenta contiene le entità frutto
- disciminator-value
è un attributo non obbligatorio ma necessario
qualora, come nel nostro caso, la classe mappata
è dotata di sottoclassi. Il valore “not
null” sta ad indicare che qualsiasi “riga”
della tabella avente un valore non nullo della
colonna discriminante, vedremo in seguito cos'è,
può essere trattato come un oggetto della
classe Frutto
L'elemento
id è senza dubbio l'elemento più
importante: rappresenta la chiave primaria che
identifica univocamente un'istanza di Frutto e
la corrispondente riga del DB; gli attributi sono:
- name:
il nome dell'attributo della classe che funge
da id. Nel nostro caso l'attributo è
id al quale Hibernate ci accederà tramite
getId() e setId(int id).
- Type
(non obbligatorio infatti omessa per le altre
proprietà): il tipo della proprietà
- column:
la colonna della tabella che contiene il valore
della proprietà, è da specificarsi
qualora sia diverso dal nome della proprietà
- unsaved-value:
indica ad Hibernate qual è il valore
che una classe non ancora persistita ha. Nel
nostro caso se un oggetto della classe Frutto
ha id=0 significa che è un nuovo oggetto
e che non è stato ancora salvato. Scegliere
come unsaved-value il valore 0 ha un vantaggio,
creando una nuova istanza di Frutto le sue proprietà
vengono settate al valore di default che nel
caso di un intero è 0; naturalmente non
devono esistere righe nella tabella con valore
della colonna f_id.
L'elemento
Id ha un unico figlio obbligatorio: generator,
indica come Hibernate deve generare i nuovi Id
degli oggetti da persistere. L'attributo class
specifica il tipo di generatore da usare tra tutti
cito i più comuni:
- identity
viene utilizzata la funzione auto incrementale
dei database DB2, MySQL, MS SQL Server, Sybase
and HypersonicSQL.
- Sequence
: usa il concetto di sequenza dei database DB2,
PostgreSQL, Oracle, SAP DB, McKoi
- assigned:
è compito dell'utente assegnare l'id
- foreign:
tipicamente usato quando l'id dell'oggetto dipende
dall'id di una proprietà a sua volta
persistente.
Elemento
discriminator, specifica la colonna discriminante
in caso di ereditarietà. Per capire di
quale classe creare un'istanza, Hibernate, usa
il valore che “una riga” ha nella colonna
discriminante. Il valore della colonna è
gestito in fase di inserimento e modifica totalmente
e obbligatoriamente da Hibernate. E' possibile
creare una proprietà di classe avente come
valore il valore del discriminante ma in tal caso
bisogna dichiarare tale proprietà (in fase
di mapping) come “immune alle modifiche”
(insert=”false”, update=”false”)
ovvero come esclusa dagli Statement di modifica.
Seguono
gli elementi property i quali “banalmente”
mappano le proprietà del bean con la corrispondente
colonna della tabella se non viene specificato
l'attributo column hibernate cerca la colonna
con lo stesso nome della proprietà, altrimenti
associa la proprietà con la colonna specificata.
Creazione
di un oggetto
Come prima cosa creiamo la tabella nel database
relazionale sottostante, nel nostro caso Mysql
e lo facciamo con il codice del listato 4
Listato
4 - Codice SQL per la classe Frutto
CREATE TABLE frutta (
f_id int(10) unsigned NOT NULL auto_increment,
tipo varchar(10) NOT NULL default '',
colore varchar(15) default '0',
is_marcio tinyint(1) unsigned NOT NULL default
'0',
tipologia_mela varchar(15) default NULL,
colore_bollino varchar(15) default NULL,
PRIMARY KEY (f_id)
) TYPE=InnoDB;
Ora
abbiamo la nostra tabella vuota e proviamo a creare
il nostro primo Frutto
Listato
5- Codice Java relativo alla creazione di una
nuova “Mela”
sf = new Configuration().configure().buildSessionFactory();
sess = sf.openSession(c);
Mela mela= new Mela();
mela.setColore("giallo");
mela.setMarcio(false);
mela.setTipologiaMela("golden");
sess.save(mela);
Nella
prima riga ottengo un nuovo SessionFactory, nel
nostro caso questa operazione comporta la lettura
del file di configurazione e dei file di mapping,
ottenuto il factory apro una nuova sessione passando
con c una connessione preventivamente aperta.,
le righe che seguono settano le proprietà
di mela. Con l'ultima riga salvo l'oggetto nel
DB, questa operazione si traduce (trasparentemente)
in una INSERT. Esiste la possibilità di
usare il metodo saveOrUpdate al posto di save
così facendo è il framework che
decide se eseguire una INSERT o un'UDPDATE...
in base a cosa? Hibernate sceglie quale operazione
compiere a seconda del valore che la chiave primaria
ha , non avendo impostato (giustamente) alcun
id il valore che assume per mela è 0 (come
tutte le proprietà primitive non inizializzate
in Java) grazie all'attributo unsaved-value (vedi
listato 3) Hibernate sa che se un oggetto ha quel
valore è un nuovo oggetto quindi lo deve
inserire e non aggiornare.

Figura 2 – Snapshot della tabella
frutta dopo l'inserimento della mela
Dalla figura 2 notiamo (l'id che parte da 11 a
causa delle prove antecedenti) come Hibernate
ha gestito la colonna tipo in base alla classe
di appartenenza dell'oggetto passato al metodo
save, se avessimo creato un'istanza di Banana
il metodo in questione avrebbe comportato l'inserimento
di un nuova entità relazionale (riga della
tabella) con il valore tipo settato su banana
e magari con il colore_bollino diverso da null
con il valore da noi impostato.
Recupero
di un oggetto
Per recuperare l'istanza di un oggetto esistono
diverse strade, in questo articolo prendiamo in
considerazione il caricamento di un'istanza tramite
chiave primaria. Questo tipo di caricamento lo
si ottiene utilizzando i metodi load e get della
classe Session. Eseguendo il codice riportato
nel listato 6 ottendo l'istanza di Mela appena
salvata.
Listato 6 – Caricamento del frutto con Id
11 con parametro Class
Object response=sess.load(Frutto.class,new Integer(11));
Se
non fosse esistito un oggetto della classe Mela
(o delle sue suprclassi) con id uguale a 11 l'operazione
avrebbe generato un'eccezione (net.sf.hibernate.ObjectNotFoundException)
pertanto è necessario sapere con esattezza
il valore della chiave primaria prima di utilizzare
questo metodo. L'operazione di caricamento appena
descritta accetta come input un oggetto della
classe Class oggetto che viene utilizzato per
creare l'istanza da ritornare, Hibernate ritorna
in response esattamente un'istanza di Mela e non
di Frutto perché automaticamente, in base
ai file di configurazione, ricava l'esatta classe
di appartenenza dell'oggetto persistito. Il comportamento
appena descritto può non essere quello
desiderato: potrebbe essere inutile “portarsi
dietro” proprietà di Mela mentre all'applicativo
bastano solo quelle di una superclasse (magari
in un report). Usando il codice del listato 7
si utilizza la versione di load che accetta come
primo parametro istanze di Object invece che di
Class; Hibernate non crea una nuova istanza semplicemente
setta le proprietà dell'oggetto passato
con i valori recuperati dl DB.
Listato
7 – Caricamento del frutto con Id 11 con
parametro Object
Object response=sess.load(new Frutto(),new Integer(11));
In
questo caso response è istanza di Frutto
e non di Mela, questa “versione” di
load si presta bene all'utilizzo all'interno di
un container (instance pooling).
Un'altra
strada che è possibile intraprendere per
recuperare un oggetto persistito di cui si conosce
la chiave primaria è attraverso l'uso del
metodo get dell'interfaccia Session come illustrato
nel listato 8.
Listato
8– Caricameto del frutto con Id 11 tramite
get
Object response = (Frutto) sess.get(Frutto.class,
id);
if (response ==null) {
response = new Frutto();
sess.save(response, id);
}
Il
metodo get si comporta esattamente come load soltanto
che qualora non esista un oggetto con l'id specificato
non lancia un'eccezione ma ritorna null. Nel listato
8, a titolo di esempio, se get non ritorna l'oggetto
(response==null) allora ne viene creato uno nuovo.
Modifica di un oggetto
In questo parte di articolo ci accingiamo a modificare
un oggetto persistito. Come primo passo lo recuperiamo
e poi tramite l'uso del metodo update della classe
Session “accodiamo” la richiesta di
modifica.
Nell'operazione di modifica di un oggetto entrano
in gioco diversi fattori di cui, l'operazione
update sopracitata, ne è solo una parte.
Inanzi tutto un metodo di Session molto importante
di cui parlare è flush, questo metodo,
chiamato all'interno della sessione aperta sincronizza
tutti i cambiamenti effettuati agli oggetti caricati
all'interno della sessione.
Listato
9 - Cambiamento all'interno di una sessisone
sess = sf.openSession(c);
Mela m=(Mela) sess.load(Mela.class,new Integer(11));
m.setColore("rossastra");
m.setTipologiaMela("fuji");
sess.flush();
Nel listato 9 viene caricata la Mela con id 11
ne viene modificato il colore e la tipologia all'interno
della stessa sessione usata per recuperarla da
DB e quindi viene fatto un flush della sessione,
solo alla chiamata del flush viene “accodata”
la richiesta di UPDATE dello stato della mela.
L'UPDATE di cui prima avviene se e solo se lo
stato della mela con id 11 è effettivamente
cambiato: eseguendo il codice del listato 9 più
volte si nota che solo la prima volta avvine l'update
le altre non accade nulla in quanto, via programmatica,
Hibernate verifica se vi sono stati cambiamenti
sullo stato dell'oggetto, solo in caso affermativo
viene accodato l'UPDATE.
Supponiamo
ora di aver già recuperato in una sessione
precedente e ora chiusa, l'oggetto mela con id
11 oppure di aver creato un nuovo oggetto Mela
e avergli impostato id 11 (simuliamo un precedente
recupero) eseguiamo quindi il codice del listato
10 considerando la variabile m come un riferimento
alla Mela recuperata in precedenza.
Listato
10 - Cambiamento dello stato in una sessione diversa
sess = sf.openSession(c);
m.setColore("rossastra");
m.setTipologiaMela("fuji");
sess.update(m);
sess.flush();
Senza l'esecuzione esplicita di update il codice
riportato qui sopra non avrebbe prodotto alcun
risultato nel DB questo perché l'oggetto
Mela referenziato dalla variabile m non è
stato recuperato nella sessione corrente, per
rendere effettivi i cambiamenti si rende necessario
l'esplicito uso di update.
L'esecuzione del metodo flush in caso di aggiornamento,
quindi, è obbligatorio, tramite il metodo
setFlushMode(FlushMode arg1) di Session è
possibile impostare la politica di esecuzione
dei flush da parte del framework. Passando FlushMode.NEVER
come argomento Hibernete non eseguirà mai
un flush automaticamente, è l'utente che
lo deve fare ne l suo codice come visto nei listati
9 e 10. Passando FlushMode.AUTO Hibernate eseguirà
il flush della sessione quando lo ritiene opportuno
e precisamente prima di eseguire altre query in
modo da evitare di reperire dati inconsistenti.
Infine passando FlushMode.COMMIT Hibernate esegue
automaticamente il flush all'esecuzione di un
eventuale commit dell'oggetto net.sf.hibernate.Transaction
sottostante.
Cancellazione
di un oggetto
Questo ultimo paragrafo è dedicato alla
più semplice delle operazioni viste finora,
la cancellazione di un oggetto persistito si ottiene
mediante l'invocazione del metodo delete(Object
o) di Session come illustrato ne listato 11.
Listato 11 - Cancellazione di un oggetto
Mela m=(Mela) sess.load(Mela.class,new Integer(11));
sess.delete(m);
sess.flush();
All'esecuzione
del delete viene accodata l'istruzione sql DELETE
per chiave primaria, anche in questo caso il flush
si rende obbligatorio. Non è necessario
caricare il frutto: nell'operazione di cancellazione
l'unica proprietà che viene utilizzata
è la chiave primaria quindi il medesimo
risultato lo si sarebbe ottenuto creando una nuova
mela con id 11 (ignorando così le altre
proprietà) e passandola al delete.
Conclusioni
In questo primo articolo abbiamo introdotto il
framework illustrandone l'installazione, la configurazione
e tramite esempi le operazioni base di manipolazione
di oggetti persistiti. Nel prossimo articolo andremo
a completare il mappaggio delle classi illustrate
nella figura 1 mostrando come Hibernate si comporta
con le relazioni tra classi.
Riferimenti
[1] Hibernate Official Site, http://www.hibernate.org
Luca Conte è
laureato in Informatica all'univeristà
"Ca' Foscari" di Venezia, dal 1996 si
occupa di sviluppo in ambito Web. Attualmente
è impiegato ,in qualità di senior
java developer/Software Engineer, in un'azienda
specializzata nella realizzazione di portali.
Le sue mansioni comprendono l'analisi UML, lo
studio architetturale e lo sviluppo di applicativi
su piattaforma J2EE, piattaforma di cui cura anche
l'aspetto sistemistico in ambiente Linux.
|


