|
Introduzione
Gli argomenti in questi articoli non hanno la
pretesa di offrire una dettagliata analisi della
tecnologia EJB, ma piuttosto offrire alcune indicazioni
base per la progettazione di una applicazione
multistrato basata su EJB e web application.
E' quindi necessaria una buona conoscenza di Enterprise
Java Beans così come della parte relativa
allo sviluppo di applicazioni web.
Lo
strato EJB
In questo layer troviamo due tipologie di componenti:
entity beans che mappano la struttura dati della
applicazione (articoli ed autori) e session bean
stateless.
Per gli entity bean è stato scelto di utilizzare
il framework CMP 2.0, il quale ha mostrato ottima
capacità di adattarsi al caso in esame,
semplificando enormemente il lavoro di mapping
delle strutture dati (in particolar modo i campi
blob del database sui quali verranno inserite
le immagini e gli allegati dei vari articoli).
I session beans sono in questo caso tutti di tipo
stateless e funzionano come session façade
nei confronti dello strato web. Come si potrà
vedere nel prossimo articolo, i session non forniscono
funzionalità di business logic a grana
fine o gestione del conversational state (che
invece è stata inserita all'interno delle
action del Model dello strato web organizzato
secondo il pattern MVC), ma invece contengono
le macro funzionalità di accesso ai dati,
trasformazioni ed aggregazioni delle varie strutture
dati.
Il mapping dei dati con entity beans CMP
Gli entity beans mappano la struttura dati che
definisce il dominio della applicazione. La figura
1 riporta i legami di relazione con i quali essi
sono legati.
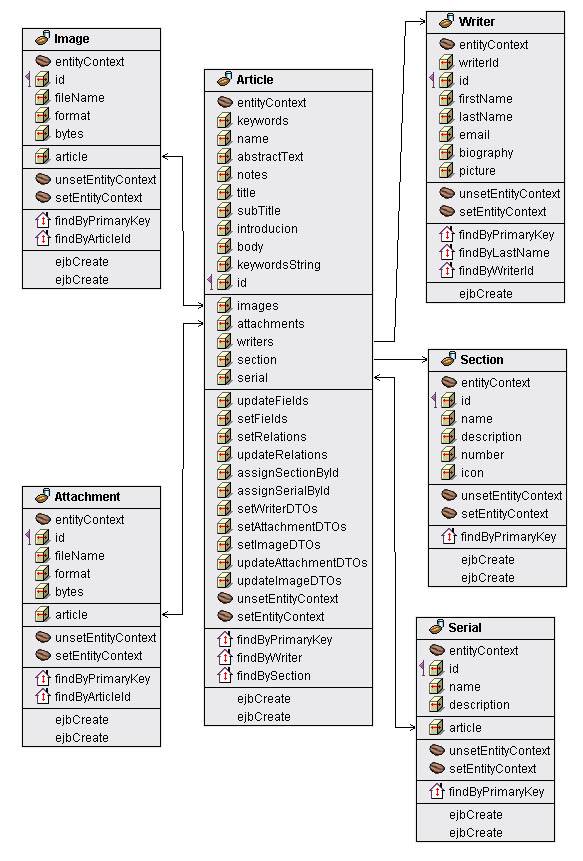
Figura 1 - Schema di relazione fra i vari
entity beans
Di
seguito invece è riportato lo schema che
spiega le "arietà" e la navigabilità
delle relazioni
ArticleBean
(m) ----> (n) WriterBean
ArticleBean (1) ----> (n) AttachmentBean
ArticleBean (1) ----> (n) ImageBean
ArticleBean (n) <---> (1) SectionBean
ArticleBean (1) ----> (n) KeywordBean
SectionBean (1) ----> (n) WriterBean
Il
bean ArticleBean è in relazione con tutti
gli altri bean della applicazione. Con alcuni
di essi il legame è vitale (ad esempio
una immagine non può esistere se non associata
ad un articolo), mentre con altri si ha una relazione
più debole (un autore di articoli può
essere definito ed inserito nel db anche se non
è associato a nessun articolo).
Il significato di tale schema dovrebbe essere
piuttosto intuitivo per cui non ci soffermeremo
oltre.
I vari attributi che definiscono articoli, autori
e quant'altro sono implementati da campi nel database
con una logica piuttosto semplice.
I campi dei vari entity sono mappati sul database
secondo la consueta modalità dettata dalla
specifica EJB CMP 2.0. La configurazione di questa
relazione di mapping avviene in parte all'interno
della applicazione, in parte nella configurazione
dell'application server (per quello che verà
mostrato qui si farà riferimento a JBoss
3.2.x)
All'interno della applicazione per prima cosa
è necessario definire una sorgente dati
sulla
quale verranno mappati i vari entity beans. La
porzione di XML che definisce il mapping sul database
è la seguente deve essere inserita nel
file di deploy specifico per l'application server
utilizzato. Nel caso di JBoss tale file è
il jboss-jdbc.xml:
<jbosscmp-jdbc>
<defaults>
<datasource>java:/MokaCMSDS</datasource>
<datasource-mapping>mySQL</datasource-mapping>
</defaults>
La datasource MokaCMSDS verrà poi configurata
per il database MySQL mokacms: le traduzione
(da nome di datasource a database vero e proprio)
viene gestita dal container J2EE in modalità
pooled.
JBoss viene quindi configurato per connettersi
al database mokacms ed offrire un oggetto di tipo
javax.sql.Datasource associato al nome JNDI MokaCMSDS.
La connessione di JBoss al database viene configurata
tramite apposito file XML che deve essere copiato
nella directory di deploy
JBOSS_HOME/server/<nome_partizione>/deploy
dove
<nome_partizione> è il nome della
partizione JBoss utilizzata.
In questo caso è stato utilizzato il file
mysql-mokacms-ds.xml che ha il seguente contenuto
<datasources>
<local-tx-datasource>
<jndi-name>MokaCMSDS</jndi-name>
<connection-url>jdbc:mysql://localhost/mokacms</connection-url>
<driver-class>org.gjt.mm.mysql.Driver</driver-class>
<user-name>root</user-name>
<password>pippo</password>
</local-tx-datasource>
</datasources>
Tornando
alla configurazione della applicazione si deve
proseguire nello specificare per ogni entity bean
il nome della tabella SQL sulla quale rendere
persistenti i vari campi. Questo può essere
fatto con il seguente XML
<enterprise-beans>
<entity>
<ejb-name>Article</ejb-name>
<table-name>article</table-name>
…
Segue
a questo punto l'elenco dei vari campi del bean
che devono essere resi in qualche modo persistenti.
Nella applicazione in esame si sono identificare
le seguenti tipologie di campi
Campi
persistenti: sono i comuni campi che il framework
rende persistenti sul database tramite opportuno
mapping specificato dal file di deploy XML. Ad
esempio il campo title del bean artiche contiene
il titolo di un articolo e viene mappato sul campo
TITLE del database. Per la completa definizione
di un campo persistente si devono specificare
due informazioni. La prima è quella che
dice che un campo è effettivamente persistente
cosa che può essere fatta all'interno del
file di deploy standard ejb-jar.xml:
<cmp-field>
<field-name>title</field-name>
</cmp-field>
Successivamente
nel file di deploy relativo alla persistenza specifico
per l'application server utilizzato (jboss-jdbc.xml)
si deve dire per ogni campo su quale colonna deve
essere effettuato il mapping
<cmp-field>
<field-name>title</field-name>
<column-name>title</column-name>
</cmp-field>
Campi chiave: sono campi persistenti come gli
altri ma che hanno la particolarità di
essere utilizzabili come chiavi di ricerca del
bean. In genere sono associati ai campi chiave
del database anche se tutti i controlli di unicità
del bean in base a tale campo sono effettuati
"anche" dal container EJB. I campi
chiave, in quanto tali, possono partecipare anche
nella definizione di una relazione con un altro
bean, pur essendo anche campi persistenti (vedi
oltre).
Per dire che un campo è una chiave all'interno
del file di deploy verrà inserito il seguente
codice XML
<primkey-field>id</primkey-field>
Campi
di relazione: un campo di relazione serve per
specificare il legame che unisce due entity beans.
L'unica accortezza che si deve tenere a mente
è che un campo di relazione non può
essere reso persistente (è compito dell'application
server mantenere il legame fra i record del db
sincronizzando i campi corrispondenti). Tale relazione
viene definita nel nel file di deploy relativo
alla persistenza specifico per l'application server
utilizzato (il solito jboss-jdbc.xml). Ecco il
pezzo che definisce la relazione fra un articolo
ed un autore
<ejb-relation>
<ejb-relation-name>article-writer</ejb-relation-name>
<relation-table-mapping>
<table-name>writer_article</table-name>
</relation-table-mapping>
<ejb-relationship-role>
<ejb-relationship-role-name>ArticleRelationshipRole</ejb-relationship-role-name>
<key-fields>
<key-field>
<field-name>id</field-name>
<column-name>artcile_id</column-name>
</key-field>
</key-fields>
</ejb-relationship-role>
<ejb-relationship-role>
<ejb-relationship-role-name>WriterRelationshipRole</ejb-relationship-role-name>
<key-fields>
<key-field>
<field-name>id</field-name>
<column-name>wrtier_id</column-name>
</key-field>
</key-fields>
</ejb-relationship-role>
</ejb-relation>
Per capire come siano gestiti i campi di relazione
all'interno del codice si può prendere
ad esempio la coppia di metodi ejbCreate() ed
ejbPostCreate() del bean Article indicato dalla
specifica EJB infatti tutti i campi di persistenza
devono essere impostati all'internprimo o del
metodo mentre quelli di relazione nel postCreate():
public
String ejbCreate(ArticleDTO articleDTO) throws
CreateException {
logger.debug("--- Enter - Parameters: articleDTO="
+ articleDTO);
this.setId(articleDTO.getId());
this.setFields(articleDTO);
logger.debug("--- Exit");
return "";
}
public void ejbPostCreate(ArticleDTO articleDTO)
throws CreateException {
logger.debug("--- Enter - Parameters: articleDTO="
+ articleDTO);
this.setRelations(articleDTO);
logger.debug("--- Exit");
}
Come
si può notare l'uso di un DTO di tipo ArticleDTO
rende il codice molto pulito e semplice da leggere.
Il metodo setFields() preleva tutti i campi del
DTO per andare ad instanziare i relativi campi
del bean.
public
void setFields(ArticleDTO articleDTO){
logger.debug("--- Enter - Parameters: articleDTO="
+ articleDTO);
this.setAbstractText(articleDTO.getAbstractText());
this.setBody(articleDTO.getBody());
this.setIntroducion(articleDTO.getIntroducion());
this.setName(articleDTO.getName());
this.setNotes(articleDTO.getNotes());
this.setSubTitle(articleDTO.getSubTitle());
this.setTitle(articleDTO.getTitle());
logger.debug("--- Exit");
}
Il metodo setRelations() è invece più
complesso. Se infatti le relazioni sono mantenute
nel database come associazioni fra colonne chiave,
in entity bean le realzioni sono mantenute associando
le relative interfacce local dei vari bean.
Partendo quindi dall'id dell'oggetto in relazione
con l'articolo deve ricercarne l'interfaccia local
ed assegnarla nel campo di relazione di ArticleBean
public
void setRelations(ArticleDTO articleDTO){
logger.debug("--- Enter - Parameters: articleDTO="
+ articleDTO);
….
String sectionId = articleDTO.getSectionId();
logger.debug("Si procede alla assegnazione
della sezione " + sectionId);
this.assignSectionById(sectionId);
….
logger.debug("--- Exit");
}
ed
infine il metodo di assegnazione di una sezione
public
void assignSerialById(String serialId){
logger.debug("--- Enter - Parameters: serialId="
+ serialId);
if (serialId == null){
logger.debug("la serie non è stata
impostata nel DTO.
Si
assegna relazione nulla");
this.setSerial(null);
}
else{
SerialLocal serialLocal;
SerialLocalHome serialLocalHome;
String SerialHomeName = "java:comp/env/ejb/serial";
try {
serialLocalHome = (SerialLocalHome) ServiceLocator.getEjbLocalHome(SerialHomeName);
} catch (ServiceLocatorException sle) {
String msg ="Impossibile procedere perché
la home di Serial non è stata
trovata\n"
+ sle;
logger.error(msg);
throw new EJBException(msg);
}
try {
logger.debug("si assegna la serie");
serialLocal = serialLocalHome.findByPrimaryKey(serialId);
logger.debug("trovata la serie " + serialLocal.getDescription());
this.setSerial(serialLocal);
} catch (ObjectNotFoundException onfe) {
logger.debug("Non esiste una serie con id="
+ serialId +", si lascia non assegnata");
} catch (FinderException fe) {
String msg = "Impossibile procedere nella
assegnazione della sezione -
Exception durante la ricerca\n" +fe;
logger.error(msg);
throw new EJBException(msg);
}
}
logger.debug("--- Exit");
}
I campi blob: i campi blob sono utilizzati in
questa applicazione per rendere persistenti entità
binarie come ad esempio le immagini di un articolo
e gli allegati, così come la foto dell'autore.
Utilizzare un framework di mapping Obejct-Relational
è quanto mai utile in questo caso. Infatti
non è necessario dover manipolare in alcun
modo gli stream di I/O da e verso i campi BLOB
del database (operazione quanto mai scomoda) essendo
questo compito a totale carico dell'application
server.
Nella applicazione i byte di un campo blob potranno
essere acceduti in modo molto semplice tramite
il metodo
public
abstract byte[] getBytes();
che
è astratto dato che il campo BLOB fa parte
del cosiddetto Abstract Persistent Schema.
Per quanto riguarda la definizione della associazione
campo dell'entity colonna del database non vi
è niente di differente rispetto al caso
relativo ai comuni campi di persistenza EJB.
Campi
calcolati: la prima particolarità di questa
applicazione rispetto alla comune pratica di sviluppo
CMP 2.0 è forse legata ai campi calcolati.
Fra le varie proprietà di un articolo,
particolarmente importante sono le parole chiave
ad esso associato; ad esempio l'articolo in questione,
che tratta di EJB ma anche di CMS di CMP e di
editoria web, potrebbe avere le seguenti parole:
{cmp
2.0 entity, sessions, content management system,
cms, web publishing}
Questa
organizzazione permette di trovare anche questo
articolo se si effettua una ricerca di
tutti gli articoli che parlano di CMS o di web
publishing.
E' piuttosto commune che una determinata parola
chiave potrebbe essere associata a più
articoli e per questo motivo si potrebbe pensare
di creare una relazione mn fra ArticleBean e
KeywordBean.
Questa scelta però comporterebbe la creazione
di un sistema di gestione delle parole chiave,
editing, gestione duplicati e molto altro ancora.
Dato che il problema da gestire era piuttosto
elementare si sono volute mantenere le cose semplici:
per questo motivo il ArticleBean ha al suo interno
un campo keywordsString (persistente) di tipo
stringa che contiene la lista di parole chiave
separate da virgola, ed un campo non persistente
keywords che restituisce un array di stringhe.
Tale campo in realtà è fittizio
dato che non corrisponde a nessun campo reale
ma solamente ad una coppia di metodi getKeywords()
setKeyworkds() condizione necessaria per la specifica
JavaBeans per la definizione di un campo.
Tali metodi al loro interno potrebbero essere
così definiti:
public
void setKeywords(String[] keywords) {
logger.debug("--- Enter - Input Parameters:
keywords=" + keywords+",
dimensione:"+keywords.length);
if (keywords == null || keywords.length==0){
logger.debug("le keywords non sono state
impostate nel DTO. Non si modifica");
this.keywords = null;
this.setKeywordsString("");
}
else{
String str = " ";
for (int i = 0; i < keywords.length; i++){
logger.debug("keys[i]="+keywords[i]);
str += "," + keywords[i];
}
// imposta il campo di persistenza CMP
this.setKeywordsString(str.substring(1));
}
logger.debug("--- Exit");
}
public
String[] getKeywords() {
logger.debug("--- Enter");
LinkedList keywords = new LinkedList();
String keywordsString = this.getKeywordsString();
logger.debug("keywordsString: "+keywordsString);
if (keywordsString != null){
StringTokenizer st = new StringTokenizer(keywordsString,
",");
while (st.hasMoreTokens()) {
keywords.add(st.nextToken());
}
logger.debug("travasate le properties su
keywords " + keywords);
String[] returnArray = new String[keywords.size()];
return (String[]) keywords.toArray(returnArray);
}
else{
return new String[0];
}
}
Quindi
dall'esterno tutte le volte che si vorrà
impostare un set di parole chiave si invocherà
il metodo setKeywords() il quale preso l'array
di stringhe comporra la srtinga delle parole chiave
separate da virgola e la assegnerà al campo
CMP persistente keywordsString. Discorso analogo
per il metodo getKeywords().
Per
quanto riguarda la ricerca di un articolo data
una particolare parola chiave si è implementato
un metodo di ricerca che verifica se la stringa
data dal campo contiene al suo interno una o più
parole chiave passate come parametro di ricerca.
Forse non è molto efficiente e probabilmente
in futuro si cercherà una soluzione più
rigorosa.
Come si può facilmente intuire non vi è
niente di particolare rispetto a CMP, si tratta
di una comune tecnica di programmazione nemmeno
troppo sofisticata. Ogni tanto sfatare il mito
di EJB tecnologia complessa non fa male.
Trasferimento
dati tramite DTO
Per rendere quanto visto fino ad ora funzionale
e funzionante, si rende necessario realizzare
un qualche sistema che permetta da un lato di
spostare informazioni fra i vari strati applicativi,
dall'altro di realizzare un meccanismo di cache
sullo strato web.
Questi due obiettivi sono ottenuti grazie alla
presenza di due categorie di oggetti nella applicazione:
gli oggetti di trasporto (pattern Data Transfert
Object, DTO) e gli oggetti di rappresentazione
delle strutture dati (pattern Value Object VO).
Senza entrare troppo nello specifico della teoria
dei pattern appena citati, (ottima la trattazione
che viene fatta in [EJBDesignPattern]), si può
brevemente dire che ogni struttura dati remota
basata su entity è stata replicata con
una struttura isomorfa di DTO e VO.
Il pattern DTO ci dice che ogni volta che si desideri
spostare una struttura dati da uno strato all'altro
(dal layer EJB a quello web e viceversa) si dovrà
creare una apposita struttura dati di trasferimento
(un DTO appunto), popolarlo e spedirlo.
Il DTO è a tutti gli effetti un oggetto
di trasporto e non dovrebbe permettere nessuna
modifica ai dati contenuti ne tantomeno agli oggetti
dipendenti. Alcuni progettisti amano non includere
metodi di setXXX() su un DTO, ma passare tutte
le informazioni direttamente al costruttore.
Per fare un esempio ogni volta che si renda necessario
inviare informazioni relative ad un articolo,
un session bean tramite opportuni metodi di business
logic ricaverà gli entity bean, ne estrapolerà
tutti i dati, creerà una struttura dati
DTO analoga a quella degli entity e la invierà
allo strato web. Qui si potranno effettuare tutte
le modifiche sui VO e per effettuare le modifiche
sul database si dovrà estrapolare il DTO
dal VO e rispedirlo indietro.
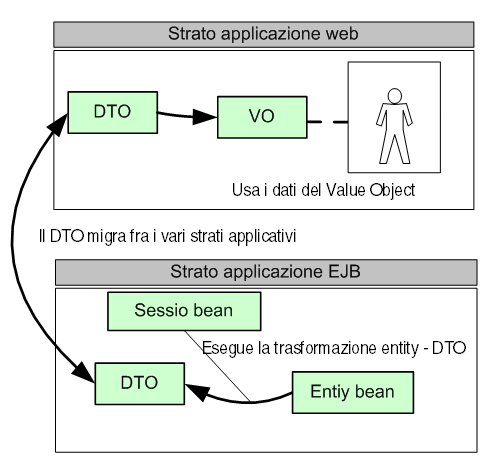
Figura 2 - gestione e trasporto dei dati nei
vari strati applicativi
In
una prima approssimazione e semplificazione si
potrebbe dire che per ogni struttura dati rappresentata
da una aggregazione di entity beans si potrebbe
pensare di crearne una analoga di DTO VO.
In realtà in alcuni casi non è detto
che sia necessario mantenere questo livello di
complessità.
Si pensi ad esempio al caso in cui nello strato
web si debba semplicemente visualizzare l'elenco
di tutti gli autori presenti nel sistema. In un
caso come questo non è necessario inviare
una collezione di DTO che contengano tutti i campi
degli autori, così come probabilmente
non è necessario inviare i DTO relativi
ai bean con i quali WriterBean instaura una relazione.
In questo caso è necessario per lo strato
web semplicemente ricavare una lista di nomi e
cognomi.
Si potrebbe quindi pensare di creare un LightWriterDTO
che contenga al suo interno solo alcune informazioni
elementari dell'autore e nessun legame con i DTO
dipendenti. Certamente questo DTO leggero, pensato
per operazioni di elencazione, non dovrebbe contenere
i bytes relativi alla immagine dell'autore.
Quali DTO creare e come aggregarli è probabilmente
la decisione più diffiicle da prendere:
in genere una buona analisi sugli use case da
implementare è probabilmente lo strumento
più utile.
Il
DTO per gli articoli
Per avere un'idea della strata da seguire nella
progettazione di questo genere di componenti,
si farà una breve analisi dei vari DTO
presenti nella applicazione.
La classe ArticleDTO rappresenta un oggetto di
trasporto relativo ad un articolo.
public
class ArticleDTO implements Serializable {
private
String name;
private String abstractText;
private String notes;
private String title;
private String subTitle;
private String introducion;
private String body;
private String id;
private SectionDTO section;
private SerialDTO serial;
private String sectionId;
private String serialId;
Un
DTO deve essere serializzabile in quanto deve
essere strasferito come parametro di input/output
di metodi RMI. I campi name,title, id etc.. servono
per memorizzare le varie proprietà dell'oggetto.
Esse saranno popolate a partire dai campi dell'entity
bean. Successivamente nella definizione della
struttura della classe si possono trovare i campi
di relazione, implementati da array di DTO dipendenti
private String[] keywords;
private ImageDTO[] images;
private AttachmentDTO[] attachments;
private WriterDTO[] writers;
La
prima cosa da notare è la scelta di utilizzare
array di stringhe per memorizzare la collezione
di parole chiave associate all'articolo: dato
che le parole chiave sono in definitiva "parole"
utilizzare un DTO apposito sarebbe stata una scelta
probabilmente sovradimensionata.
Il fatto che siano state utilizzati array e non
collezioni dinamiche (Collection, List o altro)
è frutto di una importante scelta: in questo
modo infatti si può mantenere un più
forte tipechecking sugli oggetti dipendenti.
Poter disporre del metodo
public
WriterDTO[] getWriters() {
return writers;
}
offre
una impronta più forte dell' equivalente
public
Collection getWriters() {
return writers;
}
dato
che nel primo caso si dice al mondo esterno esattamente
cosa verrà restituito nel set di autori.
Gli array pero' sono oggetti piuttosto scomodi
da trattare, ed è per questo motivo che
sono stati scelti come contenitori solo all'interno
dei DTO ma non negli entity (la specifica EJB
obbliga l'uso di Collection) e nemmeno nei Value
Obects corrispondenti.
Questa precisa scelta si adatta alla perfezione
a quella che è normalmente la natura dei
DTO di oggetti a sola lettura, per cui non dovrebbe
mai essere necessario aggiungere o rimuovere dinamicamente
un WriterDTO ad un ArticleDTO.
Il
DTO per gli allegati e le immagini
Allegati ed immagini sono strutture dati che non
dovrebbero mai vivere indipendentemente dall'articolo
a cui fanno riferimento. I DTO relativi sono semplici
strutture dati serializzabili che contengono informazioni
relative alla immagine o all'allegato ed un campo
byte[] all'interno del quale viene fisicamente
memorizzato il file ZIP o l'immagine JPG/GIF.
public
class AttachmentDTO implements Serializable {
static Logger logger = Logger.getLogger(AttachmentDTO.class.getName());
private String id;
private String fileName;
/** @todo cambiare questa prop in fileExtension
*/
private String format;
private byte[] bytes;
private String articleId;
public AttachmentDTO(){}
public AttachmentDTO(String id, String articleId,
String fileName,
String format, byte[] bytes){
this.id=id;
this.articleId=articleId;
this.fileName=fileName;
this.format=format;
this.bytes=bytes;
logger.debug("AttachmentDTO creato con questi
valori: "+this.toString());
}
public class ImageDTO implements Serializable
{
private String id;
private String articleId;
private String fileName;
private String format;
private byte[] bytes;
public ImageDTO(){}
public ImageDTO(String id, String articleId, String
filename,
String format, byte[] bytes){
this.id=id;
this.articleId=articleId;
this.fileName=filename;
this.format=format;
this.bytes=bytes;
}
Il
DTO per gli autori
La classe WriterDTO rappresenta l'oggetto di trasporto
di un autore di articoli. Essa può essere
utilizzata in maniera autonoma oppure come oggetto
dipendente all'interno di un ArticleDTO.
Non ci sono particolari dettagli di cui tener
conto, se non che al solito è una classe
serializzabile e contiene un array di bytes dove
verranno inseriti i byte della fotografia dell'autore
stesso. Si tenga presente che in questo caso
specifico il DTO potrebbe essere popolato ed inviato
fra uno strato e l'altro anche senza popolare
tale campo: si pensi al caso unin cui si voglia
semplicemente avere informazioni sull'autore senza
visualizzarne la fotografia. In questo caso lasciare
in bianco il campo porta ad un risparmio di tempo
di trasferimento e di memoria.
public
class WriterDTO implements Serializable {
private String id;
private String firstName;
private String lastName;
private String email;
private String biography;
private byte[] picture;
Gli oggetti Value Object e la
conversione da DTO a VO
Per adesso si sono analizzati i vari DTO presenti
nella applicazione. Il mese prossimo vedremo quali
sono le soluzioni per gestire tali oggetti e trasformarli
nei corrispondenti Value Object. Vedremo anche
il ruol svolto in tutto ciò dai vari session
beans.
Conclusione
Per questo mese concludiamo qui la trattazione.
Come si sarà potuto notare l'articolo riporta
una serie di idee e soluzioni progettuali senza
entrare nello specifico della teoria di EJB. Non
è infatti questa la sede dato che una trattazione
completa richiederebbe molto più spazio
di quello qui a disposizione. Spero che quanto
qui proposto possa rappresentare un buon punto
di partenza da cui approfondire l'argomento della
progettazione ed implementazione di architetture
basate su EJB.
Il prossimo mese parleremo dei session beans che
compongono lo strato EJB.
Ricordo a tutti che presto il sistema verrà
rilasciato con tutti i sorgenti nell'ambito del
progetto MokaLab ([ML])
Bibliografia
[ML] - MokaLab il laboratorio virtuale di MokaByte
- http://www.mokabyte.it/mokalab/
[MVC] - MokaPackages: il framework MVC di MokaByte
http://www.mokabyte.it/2004/06/mokapackages-1.htm
[EJBDesignPattern] "EJB Design Pattern"
di Floyd Marinescu Ed. Wiley.
http://www.theserverside.com/books/wiley/EJBDesignPatterns/
|


