|
Il
problema della sincronizzazione
Scrivere programmi concorrenti consiste nel realizzare
algoritmi progettati per girare in parallelo.
Il parallelismo presenta un solo grosso problema:
la comunicazione tra un thread e l'altro. Fino
a quando una coppia di thread lavora in parallelo,
ciascuno sui propri dati, non c'è nessun
problema. I problemi nascono nel momento in cui
un thread deve comunicare con un'altro. Nei prossimi
paragrafi verranno illustrati quattro meccanismi
di sincronizzazione, in ordine crescente di complessità.
La panoramica proposta è vasta, ma non
esaustiva: chi volesse approfondire ulteriormente
l'argomento, può consultare un testo sull'argomento
come [1].
Barriere
Il primo meccanismo di sincronizzazione che verrà
illustrato viene definito "barriera"
per ragioni che diverranno presto chiare. La barriera
è un meccanismo che si utilizza ogni qualvolta
si desidera creare una serie di thread che lavorano
indipendentemente fino al termine della loro vita,
e comunicano tra loro solo alla fine. Un caso
tipico è l'inizializzazione di un'applicazione:
spesso in questa fase vengono lanciati diversi
thread, uno con il compito di inizializzare l'interfaccia
grafica, uno che nel frattempo carica i plugin,
uno che intrattiene l'utente con uno splash screen
animato e così via. Il thread principale
deve attendere che questi abbiano finito prima
di proseguire: per ottenere questo risultato è
sufficiente chiamare il metodo join() sugli oggetti
Thread corrispondenti:
//
crea ed avvia i thread
Thread t1 = new Thread(runnable1).start();
Thread t2 = new Thread(runnable2).start();
….
// Resta in attesa della terminazione dei thread
t1.join();
t2.join();
….
Si
noti il metodo join() è bloccante solamente
quando il thread corrispondente è ancora
in esecuzione; se il thread è morto, la
chiamata a join() torna immediatamente. Per questa
ragione non ha importanza l'ordine in cui vengono
effettivamente chiamate le join(): se il thread
t2 termina prima di t1, il thread principale resterà
in attesa sulla prima join(), mentre salterà
la seconda.
Esempio
di Barriera
Si vuole realizzare un programma multi tread per
il calcolo della somma dei primi 100 milioni di
numeri interi. Il lavoro verrà suddiviso
tra 100 threads: ognuno di essi avrà il
compito di calcolare un preciso intervallo; alla
fine i risultati parziali verranno sommati tra
di loro e verrà mostrato il risultato.
La prima classe dell'esempio è una realizzazione
di Runnable, che calcola la somma tra i numeri
ad essa assegnati come inizio e fine e memorizza
il risultato nella variabile result, accessibile
attraverso un apposito metodo getResult():
public
class RunnableCalculator implements Runnable {
private int id;
private long start;
private long end;
private long result = 0;
public RunnableCalculator(int id,long start,long
end) {
this.id = id;
this.start = start;
this.end = end;
}
public long getResult() {
return result;
}
public void run() {
for(long i=start;i<end;i++)
result = result + i;
System.out.printf("Calcolatore numero %d:
la somma tra %d e %d e' %d%n",id,start,end-1,result);
}
}
Ogni
RunnableCalculator è caratterizzato da
un id numerico: al termine del calcolo viene stampato
a schermo un breve report in cui viene riassunto
il lavoro svolto durante l'esecuzione del rispettivo
thread, qualcosa del tipo:
Calcolatore
numero 64: la somma tra 640000000 e 649999999
e' 6449999995000000
La
seconda classe è quella che avvia il calcolo
vero e proprio, e che rimane in attesa, grazie
ad una barriera, fino a quando i risultati parziali
non sono disponibili:
public
class MultithreadCalculator {
public static void main(String argv[]) throws
Exception {
int max = 100;
int step = 1000000;
RunnableCalculator[] calculators = new RunnableCalculator[max];
Thread[] threads = new Thread[max];
for(int i=0;i<max;i++) {
long start = i*step;
long end = start + step;
calculators[i] = new RunnableCalculator(i,start,end);
}
for(int i=0;i<calculators.length;i++)
threads[i] = new Thread(calculators[i]);
for(int i=0;i<max;i++)
threads[i].start();
for(int i=0;i<max;i++) // Questo ciclo funziona
da barriera
threads[i].join();
long result = 0;
for(int i=0;i<max;i++)
result = result + calculators[i].getResult();
System.out.println("la somma totale e' "+result);
}
}
Gli
interi max e step denotano il numero di thread
coinvolti e l'ampiezza dell'intervallo di valori
che ciascun RunnableCalculator viene chiamato
a calcolare. Si invita il lettore a variare questi
parametri, aumentando il numero dei thread e l'intervallo
di valori da calcolare, in modo da sperimentare
i limiti del proprio sistema: per riferimento,
un sistema basato su Pentim III mobile 800 con
256 MB di memoria riesce a gestire fino a cento
mila thread, mentre entra in crisi se si cerca
di mandarne in esecuzione un milione. Le istruzioni
successive creano due array: il primo conterrà
tutti gli oggetti RunnableCalculator, il secondo
le istanze di Thread ad essi abbinate. Seguono
una serie di cicli for: il primo crea gli oggetti
RunnableCalculator, passando a ciascuno di essi
un identificatore numerico, l'inizio e la fine
dell'intervallo da calcolare; il secondo ciclo
crea un gruppo di oggetti Thread e abbina ciascuno
di essi al rispettivo RunnableCalculator; il terzo
ciclo da il via all'esecuzione dei thread, mentre
il quarto, evidenziato in neretto, costituisce
la barriera vera e propria. Attraverso il metodo
join(), chiamato in sequenza su tutti i Thread,
il programma principale aspetta che tutti i thread
siano giunti alla fine prima di proseguire. L'ultimo
ciclo somma i risultati parziali calcolati in
parallelo dai vari thread, infine una normale
istruzione di stampa a schermo visualizza il risultato.
L'output di questo programma è qualcosa
del genere:
Calcolatore
numero 0: la somma tra 0 e 9999999 e' 49999995000000
Calcolatore numero 3: la somma tra 30000000 e
39999999 e' 349999995000000
Calcolatore numero 1: la somma tra 10000000 e
19999999 e' 149999995000000
Calcolatore numero 2: la somma tra 20000000 e
29999999 e' 249999995000000
[....]
Calcolatore numero 92: la somma tra 920000000
e 929999999 e' 9249999995000000
Calcolatore numero 99: la somma tra 990000000
e 999999999 e' 9949999995000000
la somma totale e' 499999999500000000
Si
noti che ad ogni esecuzione i thread terminano
in un ordine differente, un fenomeno naturale
in un ambiente di esecuzione concorrente.
Questo
esempio presenta due particolarità interessanti.
La prima è che si tratta di un programma
che sfrutta unicamente la CPU, senza ricorrere
a direttive di I/O se non alla fine, con le istruzioni
di stampa a schermo. Se al momento del lancio
il computer sta eseguendo anche altri programmi,
si noterà un sensibile rallentamento dell'intero
sistema. La seconda è che questo è
il tipico programma in cui l'uso del multi threading
non solo è inutile, ma addirittura dannoso.
Lo stesso lavoro può essere svolto da un
programma sequenziale di poche righe come il seguente:
public
class SinglethreadCalculator {
public static void main(String argv[]) {
long result = 0;
for(long i=0;i<100000000;i++)
result = result + i;
System.out.println("la somma totale e' "+result);
}
}
E'
facile dimostrare che quest'ultimo programma,
oltre ad essere molto più compatto, è
anche di gran lunga più efficiente, dato
il pesante overhead necessario all'esecuzione
di un programma multi tread.
Il problema del produttore-consumatore
Uno dei problemi caratteristici della programmazione
concorrente è quello che in letteratura
viene definito produttore-consumatore. Produttore
e consumatore sono due entità software,
ciascuna eseguita su un thread autonomo; una di
queste produce dati a ciclo continuo, l'altra
li consuma in qualche modo. La ragione per cui
di solito si affronta questo tipo di problemi
con la concorrenza è che produttore e consumatore
seguono tipicamente ritmi differenti tra loro.
Un esempio del mondo reale che potrebbe aiutare
a chiarire l'idea è il lavoro in pizzeria:
un buon pizzaiolo (produttore) riesce a preparare
dieci pizze ogni otto minuti, un cameriere (consumatore)
riesce a prelevarne al massimo 3 al minuto. Il
problema del produttore-consumatore ha numerose
varianti: ad esempio è possibile avere
più produttori e/o più consumatori.
La metafora della pizzeria può essere estesa
ad un intero ristorante: in questo caso i produttori
sono il pizzaiolo e i cuochi, mentre i consumatori
sono i vari camerieri. Questo mese verrà
illustrato un meccanismo di sincronizzazione adatto
al caso in cui esiste un solo produttore e un
solo consumatore; il mese prossimo verrà
proposta una soluzione più complessa adatta
al caso generale di n produttori e m consumatori.
PipedStream
Il meccanismo che verrà descritto in questo
paragrafo è molto simile alle pipeline
(tubature, in inglese), un meccanismo di sincronizzazione
molto comune in Unix. Le pipeline sono dei particolari
stream che connettono un thread produttore con
il rispettivo consumatore. Grazie alla possibilità
di concatenare gli stream tra loro è possibile
trasmettere attraverso una pipeline qualunque
cosa, dai caratteri agli oggetti serializzati.
Le classi necessarie per mettere in piedi questa
forma di comunicazione sono PipedReader e PipedWriter
(o le omologhe classi orientate ai byte PipedInputStream
e PipedOutputStream):
PipedReader()
PipedReader(PipedWriter src)
PipedWriter()
PipedWriter(PipedReader snk)
Queste
classi vanno sempre utilizzate in coppia e connesse
tra di loro. In genere prima si crea una, poi
si crea l'altra passando come parametro il reference
alla prima:
PipedWriter
pipeOut = new PipedWriter();
PipedReader pipeIn = new PipedReader(pipeOut);
Gli
stream così creati possono essere utilizzati
così come sono, o possono essere concatenati
a stream di più alto livello:
PrintWriter
out = new PrintWriter(pipeOut);
BufferedReader in = new BufferedReader(pipeIn);
Infine,
la testa e la coda della pipeline (in ed out in
questo esempio) devono essere passati alle classi
che implementano il produttore e il consumatore:
Runnable
pipedProducer = new PipedProducer(out);
Runnable pipedConsumer = new PipedConsumer(in);
In
figura 1 è possibile vedere una rappresentazione
grafica della connessione tra produttore e consumatore
effettuata mediante pipeline. Si noti che la pipeline
viene rappresentata come una vera e propria tubatura
che unisce i due thread, e permette una comunicazione
unidirezionale.
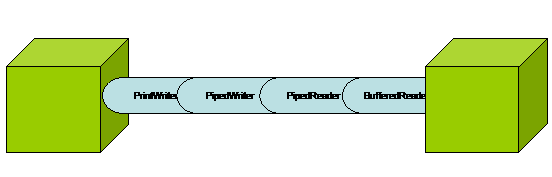
Figura 1 - Esempio di connessione tra produttore
e consumatore attraverso pipeline
Nel
prossimo paragrafo verrà illustrato un
esempio completo.
Uso
pratico di PipedWriter e PipedReader
Per prima cosa è necessario creare una
classe Runnable che implementi il produttore:
import
java.io.*;
public
class PipedProducer implements Runnable {
private PrintWriter out;
public PipedProducer(PrintWriter out) {
this.out = out;
}
public void run() {
for (int i = 0; i < 100; i++) {
for ( char c = 'a'; c <= 'z'; c++)
out.print((char)c);
out.println();
}
out.close();
}
}
Il
codice del metodo run() di un produttore in genere
è costituito da un ciclo all'interno del
quale si produce qualcosa e lo si immette nello
stream di output. In questo caso vengono inviati,
un carattere alla volta, le lettere dalla 'a'
alla 'z' seguite da un carattere di a capo; il
tutto viene ripetuto per 100 volte. Il codice
del consumatore è speculare a quello del
produttore:
import
java.io.*;
public
class PipedConsumer implements Runnable {
private BufferedReader in;
public PipedConsumer(BufferedReader in) {
this.in = in;
}
public void run() {
try {
while ( true ) {
String s = in.readLine();
if(s == null)
break;
else
System.out.println(s);
}
in.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
}
Anche
in questo caso, all'interno del metodo run() si
avvia un ciclo infinito, nel corso del quale i
caratteri vengono letti una linea alla volta,
in modo da sottolineare la differenza di ritmo
tra produttore e consumatore. La classe seguente
crea un PipedReader e un PipedWriter, li connette
tra loro, aggiunge un BufferedReader e un PrintWriter
alle estremità della pipeline infine crea
ed avvia il produttore e il consumatore, passando
loro le estremità della pipeline:
import
java.io.*;
public
class PipedStreamExample {
public static void main(String argv[]) throws
Exception {
PipedWriter pipeOut = new PipedWriter();
PipedReader pipeIn = new PipedReader(pipeOut);
PrintWriter out = new PrintWriter(pipeOut);
BufferedReader in = new BufferedReader(pipeIn);
Runnable pipedProducer = new PipedProducer(out);
Runnable pipedConsumer = new PipedConsumer(in);
Thread producer = new Thread(pipedProducer);
Thread consumer = new Thread(pipedConsumer);
producer.start();
consumer.start();
}
}
Questo
esempio può servire da base per creare
programmi più complessi, o comunque più
utili di questo semplice giocattolo.
Conclusioni
In questo articolo sono stati illustrati due semplici
meccanismi di sincronizzazione tra thread, la
barriera e la pipeline. Per ciascuno di questi
casi è stato illustrato un esempio funzionante.
Il mese prossimo verranno illustrate le direttive
di sincronizzazione presenti nel linguaggio Java,
e grazie a queste verranno realizzati due ulteriori
meccanismi, più complessi ma nel contempo
più flessibili.
Bibliografia
[1] Scott Oaks, Henry Wong Java Threads, 3rd Edition
O'Reilly Ed.
Risorse
Scarica
gli esempi descritti
nell'articolo
|


