|
Introduzione
Business Case: la nostra azienda ha effettuato
cospicui investimenti nel creare e mantenere un
DBMS che contiene ad oggi un significativo patrimonio
informativo aziendale. Le applicazioni che lo
utilizzano andranno nel tempo via via sostituite
da altre da sviluppare ex-novo, e che dovranno
quindi sia fare uso delle informazioni contenute
nel suddetto DBMS, sia essere predisposte agli
interventi futuri di manutenzione evolutiva. Come
affrontare questo scenario in modo affidabile
e integrato, salvaguardando l'investimento di
ieri in un modo che sia anche predisposto al domani?
Il presente articolo tenta di rispondere a questa
domanda, proponendo un approccio integrato a tale
problematica e discutendone poi gli aspetti pratici
tramite un caso concreto.
Il
problema del DBMS Legacy
Legacy significa letteralmente "lascito ereditario",
ed è un termine entrato di fatto nel mondo
informatico a indicare qualsiasi realtà
già esistente quando si affrontano problematiche
di integrazione. Anche un DBMS preesistente quindi
può a buon diritto definirsi "Legacy".
Il problema è quindi come procedere quando
i nostri obiettivi di business richiedono la progettazione
e sviluppo di una applicazione che, oltre a dover
avere determinate caratteristiche (in termini
di requisiti e funzionalità da implementare)
utilizzi dati provenienti da un DBMS che si trova
in esercizio e che "serve" altre applicazioni.
Se il DBMS è di dimensioni non troppo ridotte
e se la applicazione J2EE che dobbiamo sviluppare
è di una certa rilevanza e complessità,
il problema che affrontiamo potrebbe non essere
così banale da risolvere. Come conviene
operare? Costruendo un blocco di codice wrapper
che si interfacci con il DBMS salvo aggiungere
ad esso quanto richiesto dagli obiettivi di business
della nuova applicazione? Non sembra un approccio
particolarmente affidabile....Ci chiediamo allora:
esiste la possibilità di procedere in modo
più organizzato e sistematico, servendosi
ad esempio della modellazione?
MDA:
Forward & Reverse Engineering
La parola modellazione ci suggerisce di esplorare
le potenzialità della Model Driven Architecture,
metodologia standardizzata da Object Management
Group (rif.[1]), che garantisce la possibilità
di ridurre la complessità intrinseca nello
sviluppo servendosi di modelli (business, applicativo,
codice) da svilupparsi in fasi successive, l'uno
derivato dall'altro, come illustrato schematicamente
in figura 1.
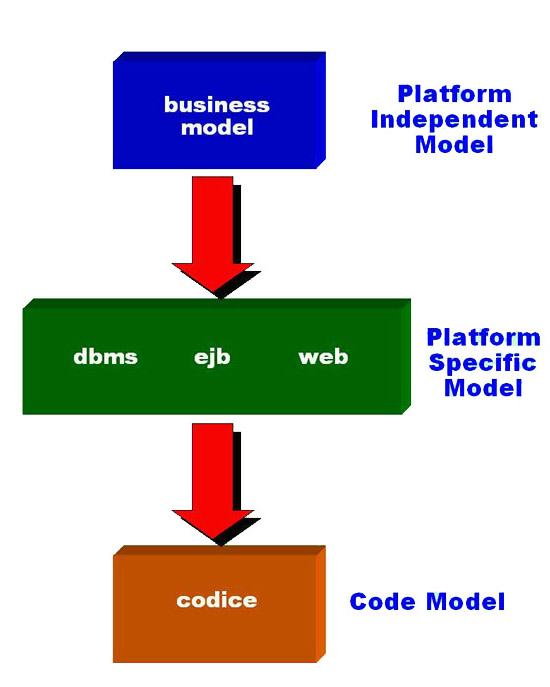
Figura 1 - Model Driven Architecture
Il
concetto di base di MDA risiede nella potenza
espressiva intrinseca nel modello iniziale di
business (Platform Independent Model o PIM) che
permette di modellare il solo core-business aziendale.
Da esso vengono derivati tutti i modelli applicativi
necessari (Platform Specific Model o PSM), uno
per ciascuna delle tecnologie scelte per la futura
implementazione. Nel caso J2EE avremo quindi un
PSM per il Web tier, uno per l'EJB tier e uno
per il DBMS tier. Da ciascuno di essi infine la
derivazione del codice vero e proprio, quello
che costituisce l'applicazione J2EE finale.
La perplessità fondamentale che risiede
in un simile approccio sta proprio nella direzione
da intraprendere per il suo utilizzo: se devo
partire da un modello di business, derivare da
esso i modelli applicativi e infine il codice
che - come richiede il nostro caso - dovrà
far uso dei dati contenuti in un DBMS preesistente,
come faccio a essere sicuro che il codice che
costruisco sarà pienamente integrato con
il DBMS sottostante? C'è qualche accorgimento
particolare che devo seguire nel disegno del modello
di business iniziale dal quale vengono poi derivati
i successivi?
In effetti la strada classica di applicazione
di MDA, detta "forward engineering",
può far nascere alcuni dubbi sulla effettiva
ed efficace applicabilità a situazioni
come quella in esame. Fortunatamente però,
esiste anche quella che alcuni chiamano "l'altra
faccia della medaglia MDA" (rif.[2]), ossia
il concetto di "reverse engineering",
cosa che ha portato alla nascita di una particolarizzazione
di MDA, detta Model Driven Engineering (MDE, vedere
ad es. rif.[3]). Secondo MDE, il focus è
spostato sulla integrazione e il riuso di differenti
"basi di conoscenza", e questo ci porta
molto vicini proprio alla nostra esigenza. Il
nostro obiettivo è quindi applicare MDA
in modalità "reverse engineering"
sfruttando come base di conoscenza un DBMS preesistente.
Procediamo allora!
Inizializzazione
del ciclo di vita
L'entry-point del ciclo di vita della nostra applicazione
è costituito proprio dal DBMS Legacy che
dobbiamo integrare. Il concetto fondamentale da
tenere presente è che tutto quanto siamo
in grado di acquisire da un DBMS in termini di
"inizializzazione" del nostro ciclo
di vita, costituisce un qualcosa di dipendente
dalla tecnologia, e quindi un contenuto di tipo
PSM (Platform Specific Model), per usare la terminologia
MDA. A partire poi da esso e seguendo un procedimento
"a ritroso", deriveremo il nostro modello
di business, il cosiddetto PIM. Infine, prendendo
tale PIM come base e seguendo la classica modalità
"forward" di MDA, costruiremo i restanti
modelli applicativi (PSM) sottostanti, da cui
verrà tratto il codice della nostra applicazione,
pienamente integrato con il DBMS. Non sembra troppo
difficile, no?
Riassumendo, i passi da svolgere saranno:
-
import definizioni DBMS e inizializzazione del
relativo PSM
- generazione
in modalità "reverse engineering"
del "primo embrione" del PIM
- aggiustamento
del PIM togliendo quanto di specifico del "mondo"
DBMS e aggiunta di quanto necessario a renderlo
un "vero" PIM
- generazione
dei PSM sottostanti (EJB, Web etc) e "rigenerazione"
del DBMS sincronizzato
- generazione
del codice J2EE complessivo e test finale della
applicazione
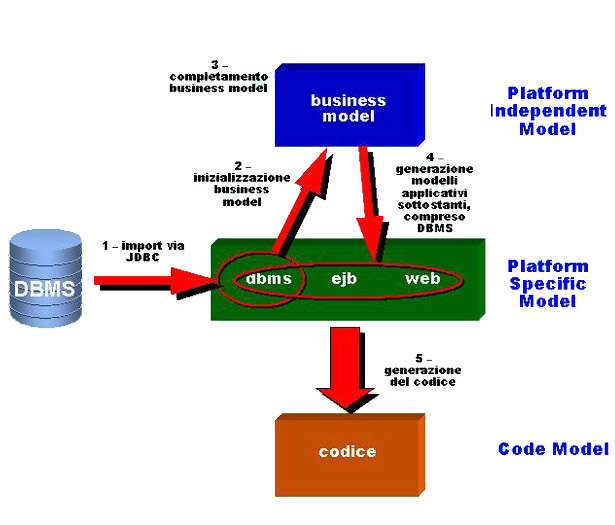
Figura 2 - Reverse Engineering da DBMS
Come
si può notare da quanto sopra descritto,
l'unica fase non "automatica", cioè
per la quale non esiste una serie di passi diretti
o automatizzabili è la fase "aggiustamento
del PIM", proprio perchè è
l'unica che richiede un pò di attenzione
e di cura. Perchè?
Modelli di business e modelli tecnologici
Ecco centrato il nodo essenziale del nostro problema:
il nostro ciclo di vita inizia definendo - a partire
da un import proveniente da un DBMS - un modello
tecnologico, ovvero (secondo quanto dice MDA)
un PSM. Da esso occorre ricavare un modello non-tecnologico,
ossia un PIM. Un PSM relativo al mondo DBMS conterrà
in generale una serie di informazioni tipiche
del mondo DBMS, quali Foreign Key o SQL Index.
D'altra parte, un PIM potrà contenere concetti
quali le Operation (si pensi ad un UML Class Diagram)
che non hanno alcun corrispettivo in un PSM del
mondo DBMS. Ma allora come facciamo a "togliere"
al nostro PSM quanto ha di "tecnologico"
e aggiungere (eventualmente) quanto serve per
"promuoverlo" a modello di business
puro, ovvero PIM? Una cosa è certa, se
partiamo da un PSM-DBMS, per ottenere un PIM occorre
un pò di lavoro. E' quello che ci apprestiamo
a illustrare ora con maggiore dettaglio.
Un esempio pratico
Un caso concreto potrà forse servire a
illustrare meglio quanto abbiamo finora solo discusso
a parole. Il nostro obiettivo è quello
di sviluppare una applicazione J2EE che utilizzi
come dati quelli esistenti in un DBMS "Legacy",
ad esempio un database Oracle.
Per la realizzazione del nostro esempio utilizziamo
lo strumento Compuware OptimalJ (rif.[4]), tool
di sviluppo J2EE completamente aderente alla metodologia
MDA e quindi applicabile tanto in modalità
"forward", quanto "reverse".
Procediamo secondo la roadmap illustrata nella
figura 2. Il primo passo consiste nell'effettuare
un import via JDBC driver delle tabelle disponibili
nel DBMS, selezionando quelle di interesse.
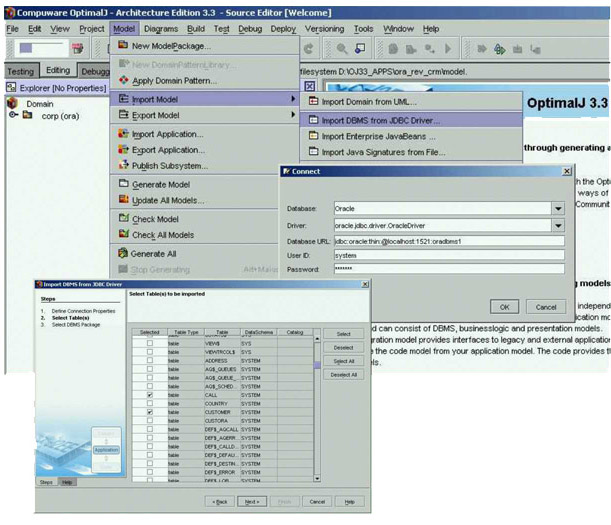
Figura 3 -
Selezione tabelle da DBMS Oracle
Il
nostro patrimonio informativo "Legacy"
è costituito dalle tre tabelle denominate
Customer, Serviceagreement e Call, contenenti
i dati necessari a gestire un sistema di CRM (Customer
Relationship Management).
Dopo aver effettuato l'import, diamo un'occhiata
al PSM DBMS Model. Nella figura 4 è anche
evidenziato il relativo diagramma ER.
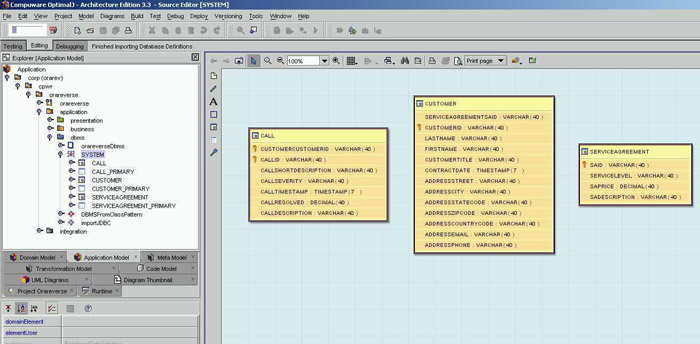
Figura 4 -
Popolamento
del PSM DBMS Model
Appare
evidente, come prima cosa, che nel nostro PSM
DBMS Model alcune informazioni quali l'eventuale
esistenza di relazioni non sono presenti. E' sempre
molto importante la scelta del driver JDBC che
si utilizza, poichè influenza la quantità
e qualità delle informazioni desumibili
da un DBMS. E' compito di ciascun DBMS vendor
mettere a disposizione uno (o più, nel
caso ad esempio di Oracle) driver JDBC che costituiscono,
come specificato con chiarezza in rif.[5], un'
API per la connettività verso database
e anche altre basi informative.
Il passo successivo è ora quello più
critico, cioè il "reverse engineering"
vero e proprio: effettuiamo quindi la generazione
del Class Model che costituirà la base
del nostro futuro PIM (figura 5).
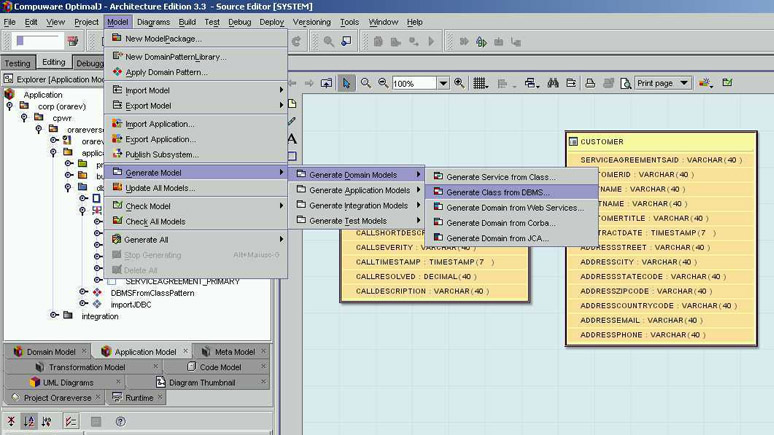
Figura 5 - Generazione del Class Model
Il
risultato è quello riportato in figura
6, e si nota che siamo ancora un pò lontani
da un PIM completo vero e proprio. Mancano infatti
le associazioni, ossia quei legami tra Classi
UML che corrispondono, nel PSM DBMS Model, proprio
alle relazioni.
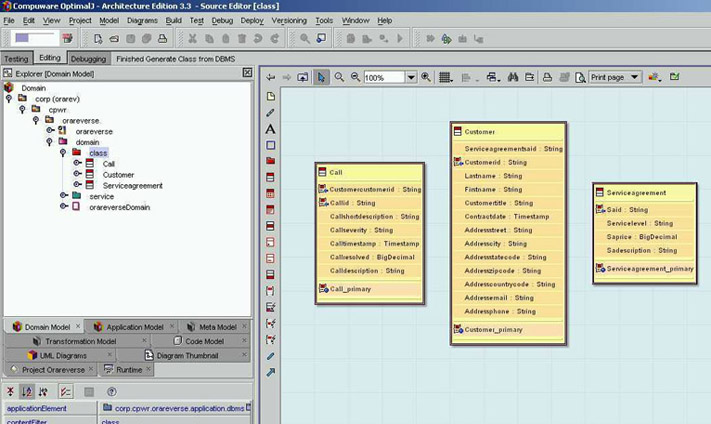
Figura 6 - Base di partenza del PIM
Esaminiamo
quindi il nostro Class Model. Pur non contenendo
in modo esplicito le diverse associazioni, è
abbastanza facile intuire dove sono e di che tipo
sono. Guardando infatti ad esempio la classe Customer,
si nota un attributo "Serviceagreementsaid"
che proviene dal sottostante DBMS Model dove costituiva
una Foreign Key da Customer "verso"
Serviceagreement. Ciò equivale a dire,
nel caso del nostro PIM, che è possibile
"tracciare" una associazione tra le
classi Customer e Serviceagreement con le molteplicità
[0..*] - [1] rispettivamente. Una volta "disegnata"
tale associazione l'attributo "Serviceagreementsaid"
non sarà più necessario e potà
quindi essere rimosso.
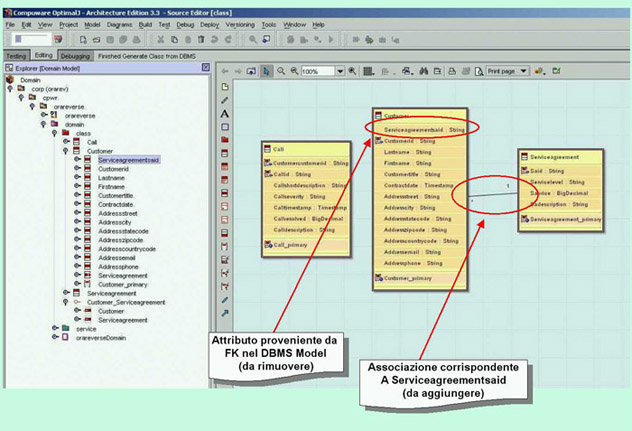
Figura 7 - Rimozione attributo e disegno
associazione
Esaminiamo
ora la classe Call (vedere sempre figura 7). Qui
la cose sono leggermente diverse, giacchè
l'attributo che si riferisce a Customer (Customercustomerid),
è presente nel cosiddetto "unique
constraint", ossia in quella caratteristica
tipica (e unica) di ciascuna classe che porta
a identificarla in modo univoco (e che poi nel
sottostante PSM DBMS Model diverrà Primary
Key). Se guardiamo bene però, il nostro
"unique constraint" è costituito
da due attributi, uno che "conduce"
verso Customer e l'altro invece "proprio"
della classe Call: che significa? Significa che
per poter individuare in modo univoco una istanza
della classe Call, abbiamo bisogno - oltre che
dell'identificativo unico di Call - anche di un
identificativo di Customer, come dire che ciascun
Call è legato completamente (dal punto
di vista del suo ciclo di vita) al "suo"
Customer. Questo concetto, nei Class Diagram,
si esprime tramite quel particolare tipo di associazioni
che va sotto il nome di "aggregazioni".
Modelliamo quindi una aggregazione tra Call e
Customer e rimuoviamo l' attributo "Customercustomerid"
dal constraint di Call: esso non è più
necessario in quanto "rappresentato"
dalla aggregazione stessa.
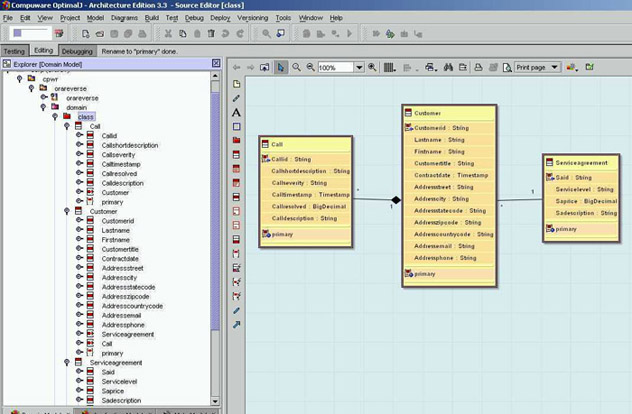
Figura 8 - Class Diagram definitivo - PIM
Il
Class Diagram così ottenuto non contiene
più attributi derivanti da collegamenti
alle altre classi, e possiede tutte le associazioni
di cui necessitiamo per mappare il DBMS sottostante.
Inoltre, non contenendo alcun tipo di elemento
dipendente da alcuna tecnologia, può essere
a buon diritto riguardato come un modello di business
nel senso MDA del termine, ossia un PIM.
A
questo punto, disponendo di un PIM completo e
"scremato" di quegli elementi non necessari,
possiamo eliminare il sottostante PSM DBMS Model
così come ottenuto originariamente dal
database e "rigenerarlo" direttamente
dal nuovo PIM, al fine di ottenere un PSM completamente
coerente e sincronizzato col PIM stesso (stiamo
ora operando in modalità "forward
engineering")
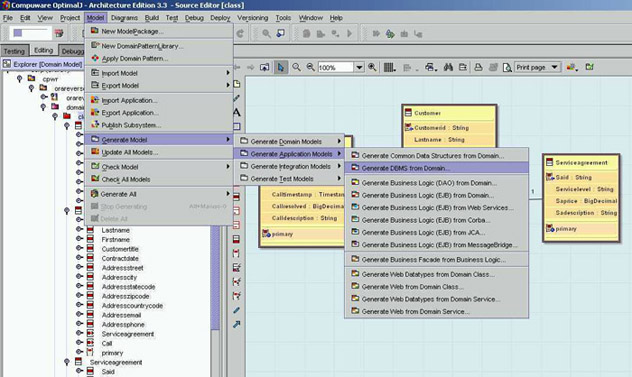
Figura 9 - Rigenerazione del PSM DBMS Model
Se
andiamo a guardare il "nuovo" PSM DBMS
Model notiamo come tutte le azioni svolte sul
soprastante PIM siano state tradotte e mappate
(si notino ad esempio le Primary Key in giallo
e le Foreign Key - in blu - derivanti dalle associazioni).
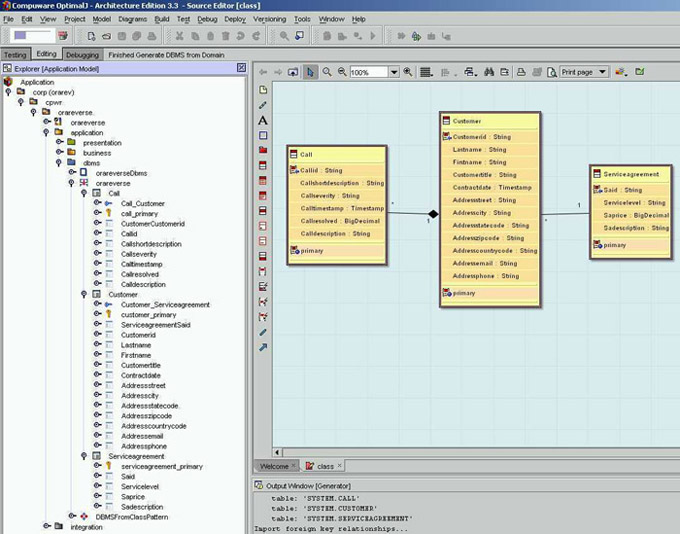
Figura 10 - Nuovo PSM DBMS Model
Il
passo successivo consisterà, con analoga
procedura, nella generazione dei PSM mancanti
(EJB e Presentation Model), e nella successiva
generazione del codice, compilazione e test.
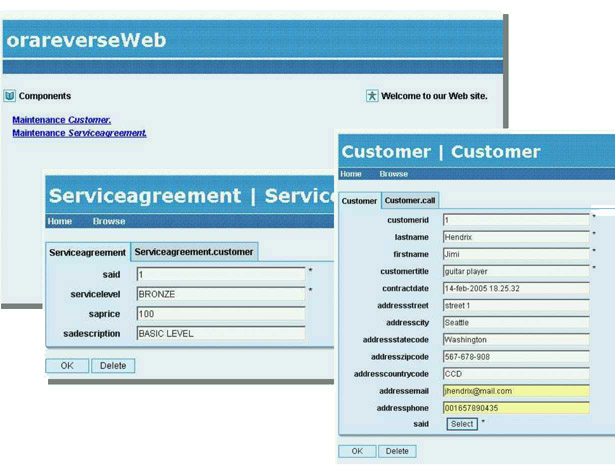
Figura 11 - Test della applicazione
Abbiamo
quindi non soltanto costruito una applicazione
J2EE che utilizza in modo integrato le informazioni
provenienti da un DBMS, ma abbiamo altresì
"modellato" tale applicazione riuscendo
a costruirne il modello di business, riuscendo
quindi ad effettuare un procedimento "inverso"
di modellazione che ci ha permesso di risalire
fino a dedurre un modello completamente indipendente
dalla tecnologia, base per qualsiasi futuro sviluppo.
Conclusioni
Abbiamo visto come ottenere un Platform Independent
Model a partire da una semplice connessione via
JDBC driver con un DBMS. Possiamo renderci facilmente
conto del grande valore aggiunto che un simile
approccio porta con sè. Sarebbe infatti
perfettamente possibile arricchire a piacere il
nostro PIM con ulteriori elementi, nel caso il
nostro business lo richiedesse, ad esempio delle
Domain Operation definite sulle varie classi del
Class Diagram, che andrebbero a corrispondere
a metodi di business nel PSM EJB Model e Web Actions
nel PSM Presentation Model. Costruire un PIM in
modalità "reverse engineering"
a partire da un PSM DBMS Model permette proprio
questo, e cioè di controllare tutti i requisiti
di business da un livello di astrazione più
alto e indipendente dalla tecnologia, seppure
riutilizzando quanto contenuto nel DBMS Legacy,
che viene completamente integrato nella nuova
realtà aziendale. La presenza di un PIM
inoltre permette qualsiasi intervento di manutenzione
evolutiva sull'intera applicazione in maniera
rapida, affidabile e, ancora un volta, completamente
integrata. Un modo vincente per essere veloci
nella risposta ai cambiamenti di business, salvaguardando
nel contempo gli investimenti e i patrimoni informativi
preesistenti.
Bibliografia
[1]
Mokabyte - "Uso della Model Driven Architecture
nello Sviluppo di Applicazioni J2EE", parte
1 http://www.mokabyte.it/2004/07/mda-1.htm e parte
2 http://www.mokabyte.it/2004/09/mda-2.htm)
[2]
Stefan Tilkov, "MDA Reverse Engineering",
http://www.research.ibm.com/journal/rd/485/tai.html
[3]
A. Winter, J.M. Favre, M. Godfrey "MDE &
Reverse Engineering", http://www-db.informatik.uni-hannover.de/emisa/msg00115.html
[4] Compuware Lab "OptimalJ Community"
- http://javacentral.compuware.com[5]
Sun Microsystems "JDBC Technology" -
http://java.sun.com/products/jdbc/index.jsp
Doriano Gallozzi è
nato a Roma nel 1964 e si è laureato in
Ingegneria Elettronica (indirizzo Informatica)
nel 1989. Da sempre interessato a problematiche
di analisi, progettazione e sviluppo di Sistemi
Informativi, ha lavorato per diversi anni in aziende
del settore informatico italiano (gruppo ENI,
gruppo Telecom Italia), dove ha acquisito diverse
esperienze tanto nel campo della progettazione
e sviluppo del software (in ambiente M/F come
in ambiente distribuito) quanto nel campo dei
RDBMS (DBA su diversi progetti per clienti finali
quali Telecom Italia). Da gennaio 2000 lavora
nella Divisione Prevendita di Compuware Italia.
La sua attività verte principalmente sulla
piattaforma J2EE e tecnologie correlate, ma anche
su ambiti tecnologici quali l'Enterprise Application
Integration, i Portali Web, gli strumenti di Business
Process Modeling.
|

