|
Il
contesto
Magneti
Marelli non ha certo bisogno di presentazioni. L'azienda
produce componenti elettronici per il mercato dell'automobile.
La sua divisione Motorsport si dedica in particolare
ai componenti per le auto da competizione (dalla Formula
1 ai rally): sistemi di controllo elettronici, sistemi
di telemetria, acquisizione ed analisi dati, cruscotti
e visualizzatori dati per i piloti (tanto per citare
qualcosa di eclatante: i volanti delle monoposto di
Schumacher e Barrichello), alternatori, regolatori di
voltaggio, centraline di controllo per i motori, sistemi
di ignezione elettronica, sensori vari. In particolare,
il sistema di telemetria di Magneti Marelli è
lo standard de facto in Formula 1 e gli annali ci dicono
che dal 1992 ad oggi ha sempre fornito, tra le altre,
la squadra che ha vinto il campionato.

Figura 1
Ma
in cosa consiste, in sintesi, un sistema di telemetria?
Alcuni componenti, gli acquisitori dati, sono installati
sull'auto. Basati su un sistema di networking interno
chiamato CAN-BUS, queste centraline raccolgono una quantità
enorme di informazioni (più di un migliaio di
canali diversi, dalla velocità e numero di giri
del motore fino a dati di pressione e temperatura delle
varie componenti del motore) che vengono sia memorizzate
dentro una specie di "scatola nera", sia trasmesse
in tempo reale via radio. I ricevitori di questi canali
sono situati in quei camion che si trovano in prossimità
dei box: chiunque abbia guardato in televisione almeno
un paio di gare li avrà sicuramente notati nelle
riprese effettuate dall'elicottero.

Figura 2
Un
camion per ogni scuderia contiene l'apparato radio di
ricezione vero e proprio (in foto si possono notare
le antenne) e i sistemi di networking in grado di fare
il routing del traffico verso la rete interna della
scuderia. Gli altri camion contengono le postazioni
di lavoro degli ingegneri di gara, i quali possono monitorare
i dati sui propri laptop. Altri ingegneri di gara sono
situati dentro il box, con laptop e PC fissi (anche
se, come vedremo tra poco, parlare di PC “fissi”
in una scuderia di F1 è un po' un controsenso).
Il numero di postazioni di lavoro varia da scuderia
a scuderia, ma le più importanti ormai arrivano
a parecchie decine. I software usati dagli ingegneri
di gara consentono di graficare in tempo reale i dati
ricevuti dall'auto, ma anche di compiere operazioni
molto più complesse, come l'analisi con strumenti
matematici per cose tipo il calcolo dell'efficienza
aerodinamica o per scoprire eventuali problemi.
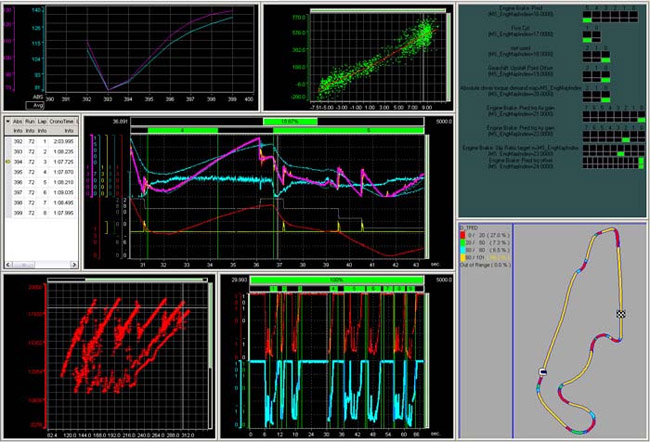
Figura 3
Recentemente,
proprio il numero di utenti del sistema di telemetria,
sempre crescente, ha introdotto il problema della scalabilità,
noto già da parecchi anni nel mondo enterprise
(a questo proposito aggiungiamo che, oltre agli utenti
umani, esistono una serie di client automatici sviluppati
dalle scuderie: software che segnalano allarmi, che
memorizzano i dati nel database interno, in alcuni casi
gateway che trasmettono alcuni dati ad un server web
che a sua volta li diffonde in streaming agli utenti
di Internet). Le classiche soluzioni client-server,
basate in generale su Windows, hanno mostrato quindi
tutti i loro limiti, essendo adatte a gestire un numero
di client molto più basso. Come già detto,
si è riprodotta la stessa situazione nota nel
mondo enterprise già da qualche anno. Proprio
quest'esigenza ha convinto Magneti Marelli della necessità
di progettare un nuovo sistema di distribuzione dei
dati ed è nato il progetto RTTS (Real Time Telemetry
System), condotto congiuntamente da Magneti Marelli
Motorsport e Sun Microsystems Italia.
Specifiche
Possiamo
a questo punto elencare le specifiche di RTTS perché
si possano contestualizzare le soluzioni progettuali
che stiamo per presentare. RTTS deve:
- fornire
un flusso di dati di telemetria in tempo reale (soft
real time);
- pubblicare
e recuperare dati di ambiente (si tratta di valori
che vengono impostati manualmente dagli ingegneri
di gara e che
- consistono
in cose tipo la quantità di carburante imbarcato
all'ultimo pit-stop, i settaggi degli alettoni, la
temperatura dellegomme
(sempre rilevata all'ultimo pit-stop), eccetera;
- fornire
strumenti per la gestione ed il monitoraggio del suo
funzionamento;
- fornire
una Java API per l'integrazione di software ad-hoc
sviluppato dalle scuderie;
- integrarsi
con i dispositivi esistenti richiedendo il minimo
numero di cambiamenti.
Da
un punto di vista non funzionale:
- RTTS
deve gestire fino a sei centraline differenti (due
per auto in ridondanza, con un massimo di tre auto
in pista durante le prove)
- ogni
canale può trasportare più di 2 Mbyte
al secondo di dati;
- la
latenza massima (il tempo che trascorre dalla ricezione
del dato da parte dell'apparato radio fino alla ricezione
sul client) dev'essere inferiore ai 50ms;
- devono
essere supportati fino ad un centinaio di client;
- il
sistema deve effettuare un eventuale switching su
un sistema di backup in pochi secondi da quando viene
rilevato un problema;
- il
sistema deve essere portabile (alcune scuderie usano
Windows, altre Linux);
- opzionalmente,
deve essere possibile garantire di non perdere alcun
dato (mediante bufferizzazione e ritrasmissione) anche
in
- caso
di disconnessione del sistema per alcuni secondi;
- l'installazione
deve essere semplificata al massimo: in particolare
sui client è richiesta la funzionalità
“plug and play” (il sistema
- non
deve richiedere configurazione, ma una semplice installazione
da CD-ROM); i client devono inoltre aggiornare il
software in
- automatico,
richiedendo al massimo una installazione fresca all'anno.
Ci
piace subito sottolineare, a riprova di quanti passi
avanti abbia compiuto Java in questi dieci anni, che
uno dei problemi che non abbiamo avuto è stato
quello della performance. In particolare, sul requisito
della latenza siamo riusciti, senza troppi problemi,
a garantire tempi non superiori a 10ms, molto al di
sotto dei requisiti richiesti (per completezza sarebbe
necessario dare qualche riferimento alla classe di hardware
utilizzato: in sommi capi, perché varia da scuderia
a scuderia, i client sono laptop di fascia altra e i
server tipicamente sono macchine biprocessore di fascia
medio-bassa. Insomma, niente di fantascientifico). Chissà
se in futuro finirà finalmente la leggenda urbana
che dice che “Java è lento”?
Anticipiamo
subito che i punti chiave dei requisiti sono affidabilità
(gestione di eventuali disconnessioni) e della funzionalità
“plug and play”: essi hanno guidato la scelta
delle tecnologie utilizzate, focalizzando la nostra
attenzione in particolare su Jini. È quindi il
momento di parlare delle tecnologie utilizzate.
Tecnologie
utilizzate
Due
sono i pilastri tecnologici di RTTS: Jini e Rio. Per
chi non li conoscesse, vediamo una descrizione a grandi
linee della loro struttura.
Jini
è una piattaforma per la realizzazione di architetture
service-oriented basate su proxy. L'idea è quella
di un sistema distribuito in cui varie parti collaborano
tra di loro ed il progettista si focalizza sulla descrizione
ad alto livello delle loro interfacce, senza doversi
preoccupare troppo dei protocolli di comunicazione sottostanti.
Anzi, questi devono poter essere cambiati con semplicità
senza che il sistema abbia troppi impatti. Inoltre,
i vari componenti devono “trovarsi” automaticamente,
senza conoscere a priori la struttura della rete e la
loro posizione sui vari nodi. A parte un registro centralizzato,
che serve unicamente alla localizzazione, il sistema
è un peer-to-peer: non esiste un componente centrale
che abbia responsabilità di controllo nelle interazioni,
ma ogni coppia di componenti è autonoma. A tale
proposito si dice che Jini consente la creazione di
“federazioni di servizi”.
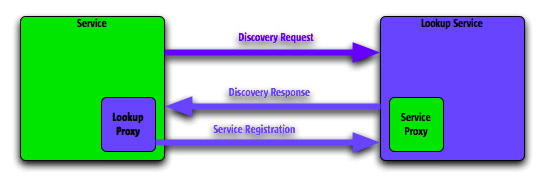
Figura 4
Nella
prima figura vediamo cosa succede quando un nuovo servizio
viene pubblicato (cioè quando viene attivato
per la prima volta). In questi diagrammi abbiamo indicato
in verde un servizio, in giallo i client del servizio
ed in blu i componenti standard di Jini.
Il servizio prima di tutto cerca di scoprire dove si
trovi il registro (chiamato Lookup Service, in breve
LUS) mediante un protocollo di discovery che per default
è basato su multicasting UDP.
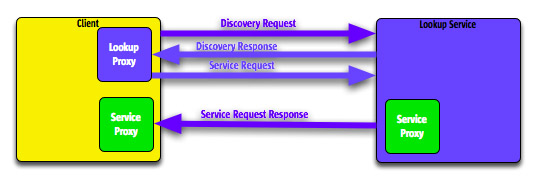
Figura 5
Una
volta individuato, la comunicazione diretta con il LUS
procede con un protocollo punto punto, e in maggior
dettaglio attraverso RMI (Remote Method Invocation).
Il servizio serializza il codice del proprio proxy e
lo trasmette al LUS, il quale lo memorizza permanentemente
al suo interno associandolo al nome del servizio ed
ad un identificativo univoco. Il proxy altro non è
che l'implementazione dell'interfaccia del servizio,
che contiene tutto quanto serve a contattare remotamente
il servizio originale. Tipicamente Jini fornisce un'implementazione
di default per i proxy, basata sul citato RMI; ma è
possibile specificarne anche di customizzate (e, come
vedremo, questa caratteristica è stata fondamentale
per RTTS).
Nella
seconda figura vediamo cosa accade quando un client
chiede la connessione con il servizio. Dopo aver “scoperto”
il LUS, con modalità identiche a quelle descritte
precedentemente, il client specifica al LUS l'identificativo
(o il nome) del servizio richiesto. Il LUS risponde
fornendo il proxy precedentemente pubblicato.
A
questo punto (terza figura) client e servizio dialogano
direttamente tra di loro, per mezzo del proxy, senza
più alcun intervento del LUS.
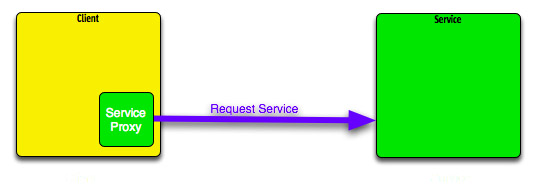
Figura 6
A
questa infrastruttura di base, Jini aggiunge meccanismi
di “service leasing” che servono a verificare
periodicamente che il servizio che sta dietro al proxy
continui ad esistere e che sia raggiungibile. In caso
negativo, al client viene notificato un messaggio di
errore quando si cerca di invocare un metodo del servizio.
Inoltre, il LUS gestisce un sistema di eventi distribuiti,
basati sul pattern “observer” (o “listener”),
attraverso i quali ogni client può avere una
notifica asincrona della pubblicazione di un nuovo servizio
o della sparizione di un servizio esistente.
Jini
fornisce anche un sofisticato sistema di configurazione
dei componenti basato su una specie di linguaggio di
scripting simile a Java, che consente di mescolare definizioni
statiche a variabili valorizzate eseguendo espressioni
Java specifiche.
Jini
supporta anche altre funzionalità, come transazioni
distribuite o sistemi di persistenza distribuiti, ma
non sono state utilizzate da RTTS e pertanto non ne
parliamo.
Da
questa sommaria descrizione si capisce come Jini si
occupi di implementare le funzionalità di installazione
“plug and play” e di gestione della disconnessione
dei cavi. Tuttavia, come vedremo tra poco, esse sono
state notevolmente customizzate dai progettisti di RTTS
per ottenere tempi di reazione compatibili con le specifiche:
di sua iniziativa Jini prende le cose con un po' più
di calma. Fortunatamente, la struttura modulare ed espandibile
di questa piattaforma tecnologica ha reso tutto più
semplice.
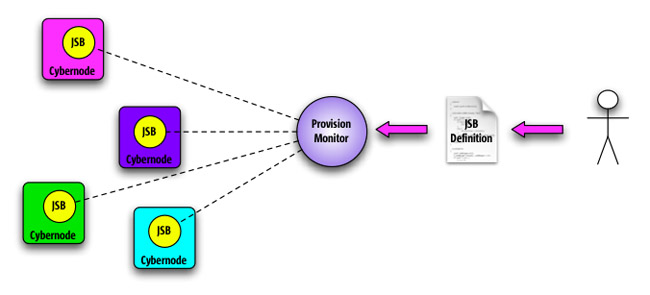
Figura 7
Il
secondo pilastro tecnologico, come anticipato, è
Rio. Rio è una piattaforma open-source, sviluppata
sempre da Sun Microsystems, che si appoggia a Jini (del
quale mantiene le caratteristiche fondamentali) ed aggiunge
alcune funzionalità fondamentali:
Una
struttura container / componente. I servizi Rio sono
implementati sotto forma di ServiceBeans (JSB), cioè
componenti che implementano una specifica interfaccia
che consente al container di controllare il loro ciclo
di vita, in modo simile a quanto avviene con gli EJB
di J2EE. I container vengon chiamati “Cybernode”.
Un sistema di provisioning che controlla dinamicamente
il deploying dei ServiceBean (e qui Rio si differenzia
nettamente da J2EE in quanto gli EJB vengono deployati
staticamente) secondo regole predefinite. Tali regole
possono per esempio basarsi sulla quantità di
memoria e di disco liberi e sulla percentuale di CPU
utilizzata (sì, se qualcuno sta pensando al grid
computing la pensata è giusta: Rio è un
prodotto pensato proprio per questo scopo). La versione
attuale di RTTS, tuttavia, non utilizza Rio in modo
così sofisticato: le regole sono solo statiche
e definiscono semplicemente i profili dei vari nodi
di rete (server primario, server secondario e client).
Rio però risolve egregiamente il problema dell'aggiornamento
del software dal momento che il codice dei ServiceBean
viene sempre scaricato dinamicamente dai client: pertanto,
per aggiornare il sistema è sufficiente aggiornare
il server primario.
Un sistema di fault detection che comprende lo switching
a caldo di un sistema primario con la sua controparte
di backup. Questa funzionalità è stata
utilizzata per gestire il distacco inaspettato di un
cavo di rete o il fallimento del server primario; ma
anche in questo caso si è intervenuti con codice
customizzato per migliorare i tempi di reazione.
Un sistema di monitoraggio che consiste sostanzialmente
in una API Java per verificare la raggiungibilità
e l'operatività dei vari componenti del sistema
(inclusi i ServiceBean). Questa API è stata la
base per sviluppare MoMa, la console grafica di controllo
di RTTS che permette all'amministratore di sistema di
vedere tutto RTTS in un solo colpo d'occhio, inclusi
eventuali segnali di allarme che indicano un malfunzionamento.
A
questi due pilastri già citati aggiungiamo JGroups,
un prodotto (sempre open-source) per l'implementazione
di protocolli di reliable multicasting. Dal momento
che esso serve ad implementare una specifica opzionale,
per la quale gli utilizzatori hanno dimostrato sul campo
una necessità molto inferiore alle loro stesse
aspettative, ne discutiamo brevemente più avanti.
Architettura
di base
A questo punto possiamo finalmente delineare l'architettura
di base di RTTS.
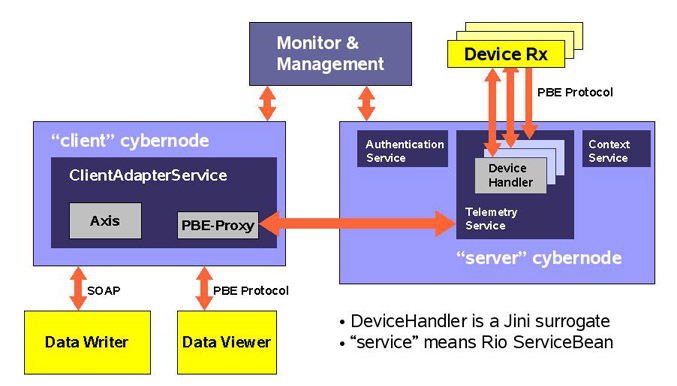
Figura 8
In
figura è stato usato il colore giallo per indicare
i componenti pre-esistenti del sistema: essi sono il
ricevitore radio (“Device Rx”) che fornisce
i dati di telemetria, i visualizzatori dei dati (“Data
Viewer”) e i client che consentono la lettura e
la pubblicazione dei dati di ambiente.
Esistono
due tipi di “cybernode” (container Rio): un
profilo “Server”, che gira solo su una / due
macchine del sistema (in regime di ridondanza) ed un
profilo “Client” che gira su ogni client del
sistema, e quindi in particolare sui laptop degli ingegneri
di gara.
Prima
di RTTS, i “Data Viewer” e i “Device
Rx” colloquiavano direttamente, mediante un protocollo
proprietario di Magneti Marelli chiamato “PBE Protocol”,
basato su pacchetti UDP. In pratica il “Data Viewer”
spedisce al “Device Rx” una richiesta di invio
del prossimo blocco dati, a cui segue in risposta il
blocco dati stesso. Il “Device Rx” ha una
limitata capacità di buffering al suo interno,
e questo meccanismo consente al “Data Viewer”
di gestire eventuali periodi di intensa attività
senza perdere alcun dato, dal momento che è questo
componente a controllarne la frequenza di invio. Una
decina di “Data Viewer” potevano condividere
i dati ricevuti da un “master” mediante tecnologia
COM di Windows.
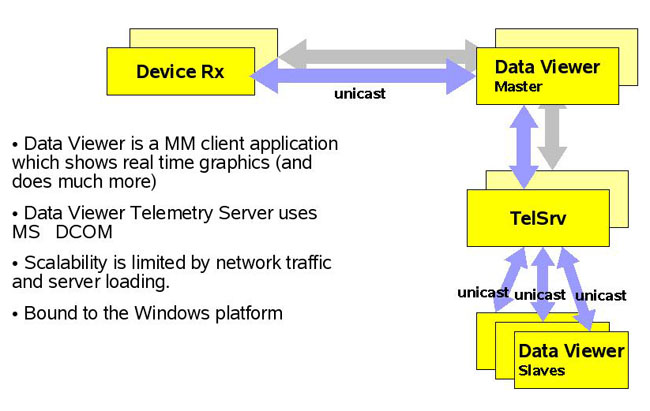
Figura 9
Con
RTTS si è voluta mantenere invariata la modalità
di trasmissione dei dati, pertanto anche RTTS è
capace di gestire il protocollo PBE. Questa volta è
un componente interno, il “Device Handler”,
ad effettuare l'interrogazione in vece del “Data
Viewer”. I dati ricevuti vengono subito inoltrati
ad un canale di multicasting che permette la consegna
contemporanea a tutti i client in ascolto in modo completamente
scalabile (in linea teorica il sistema mantiene le stesse
prestazioni indipendentemente dal numero di client collegati).
I dati vengono ricevuti da un “PBE-Proxy”
che a sua volta li memorizza in un buffer ed espone
al suo “Data Viewer” una emulazione del “Device
Rx”. In questo modo ogni “Data Viewer”
crede di avere a che fare con un “Device Rx”
dedicato e quindi è mantenuta la compatibilità
con il funzionamento esistente.
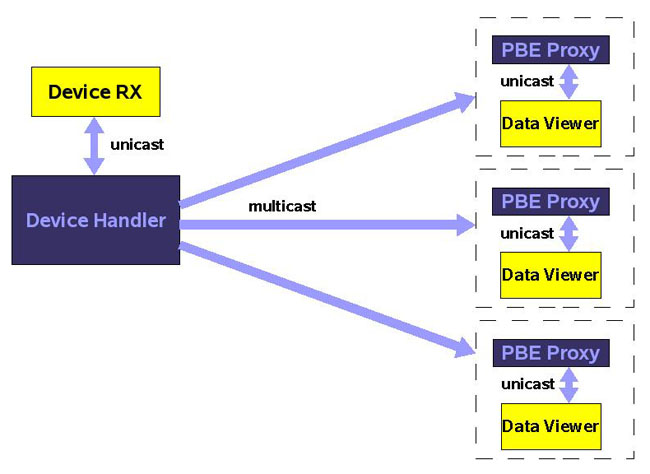
Figura 10
Il
“Device Handler” è implementato come
servizio Jini ed il “PBE-Proxy” ne contiene
al suo interno il proxy (ci si perdoni il gioco di parole).
Pertanto i due componenti possono colloquiare indipendentemente
dal canale di comunicazione, che effettivamente è
interscambiabile. A seconda delle circostanze la scuderia
può affiancare al multicasting standard una versione
di reliable multicasting (implementata attraverso JGroups)
o in casi estremi un canale TCP/IP dedicato. Quest'ultima
soluzione viene usata spesso con i collegamenti con
il muretto dove il direttore tecnico ha la sua postazione;
si tratta di un client molto importante, che però
è servito generalmente da un link laser ad infrarossi
che garantisce una qualità di segnale inferiore
a quella di una rete standard. Il TCP/IP spesso è
l'unica soluzione in grado di garantire la continuità
di trasmissione senza interruzioni. Nonostante questo
approccio sia in grande contrasto con la scalabilità
garantita dal multicasting, il numero estremamente limitato
di postazioni che lo richiedono non pone problemi in
pratica.
I
“Device Handler” sono controllati e contenuti
da un altro componente, il “Telemetry Service”.
Esso monitorizza continuamente lo stato dei “Device
Rx” (verificando la loro responsività alle
richieste di scarico dei dati) e si occupa di far coincidere
il ciclo di vita di ogni “Device Handler”
con quello del device ad esso associato. In pratica,
appena viene acceso (o connesso) un “Device Rx”,
viene pubblicato un “Device Handler”; appena
il “Device Rx” viene spento (o sconnesso)
il relativo “Device Handler” viene tolto di
mezzo. Da questo punto di vista, i “Device Handler”
rappresentano, nella prospettiva degli altri componenti,
in tutto e per tutto le sorgenti di dati delle automobili,
che pertanto risultano “jinizzate”. Questa
soluzione, è chiamata “idioma surrogate”
nel mondo Jini e viene utilizzata tutte le volte in
cui vogliamo rendere disponibile “alla Jini”
un dispositivo dove non è possibile far girare
una macchina virtuale Java.
Il
resto del sistema è relativamente semplice. Il
“Context Service” è un semplice database
persistente in grado di memorizzare e recuperare a richiesta
le variabili di ambiente. La sua struttura dati è
basata su un modello DOM di XML (in poche parole, il
“Context Service” è un semplice naming
service a struttura gerarchica). L'”Authentication
Service” è un adattatore che permette di
recuperare i dati di autenticazione degli utenti, mediante
flat file, accesso a fonti dati JDBC o JNDI.
L'accesso
al “Context Service” viene fornito ai “Data
Writer” per mezzo di un'interfaccia SOAP implementata
da Axis, un prodotto open-source di Apache. Questa soluzione
è stata scelta per disaccoppiare al massimo le
dipendenze tra RTTS e “Data Writers”, che
sono un'applicazione realizzata in C++ da Magneti Marelli.
MoMa
è la console grafica di monitoraggio del sistema
che usa le citate API di Rio per tracciare in tempo
reale lo stato di ogni componente. Essa fornisce una
visione d'insieme di RTTS sia in formato iconico sia
in forma di albero; a titolo di esempio mostriamo la
schermata principale. MoMa consente anche la configurazione
del sistema, come per esempio l'assegnazione di un canale
radio ad una certa auto, che può essere effettuata
mediante drag-n-drop o con maschere di input testuali.
Ovviamente MoMa è stato realizzato con Swing.
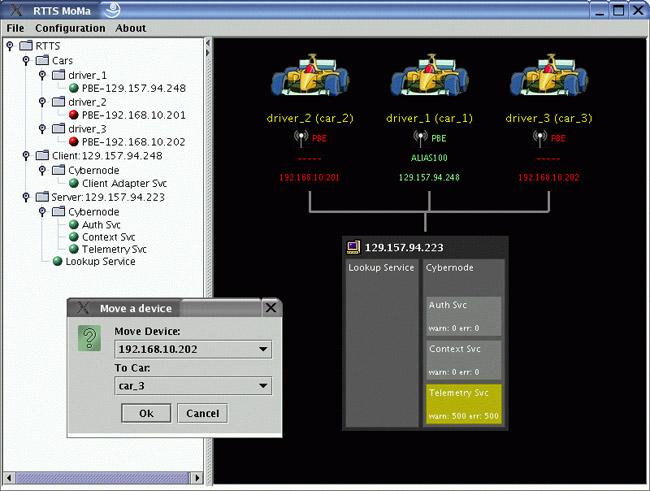
Figura 11
Customizzazioni
Come
accennato precedentemente, le strette specifiche del
progetto ci hanno costretto ad implementare alcune customizzazioni
del sistema. In particolare, abbiamo operato nelle seguenti
aree:
- gestione
della connessione / disconnessione accidentale dei
cavi
- zero
configurazioni sui client anche in presenza di schede
di rete multiple
- alta
affidabilità con switch su un sistema secondario
- reliable
multicasting
Per
quanto riguarda la disconnessione dei cavi, Jini in
realtà ha un suo modo di gestire la situazione.
Ogni due minuti il LUS segnala al mondo la sua esistenza
spontaneamente (cioè senza che nessun client
cerchi di localizzarlo esplicitamente) emettendo un
messaggio “multicast announcement”.
La prima ipotesi che abbiamo preso in considerazione
è stata di ridurre notevolmente il periodo di
emissione di questo pacchetto, portandolo a 500 millisecondi
ed usandolo come un “heartbeat” del server:
in pratica l'idea è che se un client non riceve
più il “multicast announcement” del
LUS, può presumere che il suo cavo sia staccato
ed agire di conseguenza. L'ipotesi è stata scartata:
mentre l'operazione è tecnicamente fattibile
(praticamente tutti i dettagli implementativi di Jini
possono essere facilmente riconfigurati), una frequenza
di announcement così elevata pone seri problemi
di performance (il punto è che Jini fa tutta
una serie di operazioni collegate all'announcement,
che non è stato progettato per funzionare come
un heartbeat).
La seconda ipotesi è stata di utilizzare il supporto
di monitoraggio di Rio. Rio fornisce una propria API
per implementare un heartbeat associato ad ogni ServiceBean.
L'implementazione di default è stata scartata
in quanto basata su TCP/IP: ma questo protocollo non
è scalabile e soprattutto usa timeout di disconnessione
troppo lenti (nell'ordine delle decine di secondi).
Spesso si può intervenire con tuning del sistema
operativo, ma sarebbe stato in contrasto con le specifiche
di “zero configurazione” dei client. Fortunatamente
Rio è facilmente espandibile ed è stato
possibile implementare una gestione ad-hoc di heartbeat
basata su un protocollo multicasting. In questo modo
si sono ottenuti tempi di reazione nell'ordine di pochi
secondi.
Dal punto di vista del design, tutte le operazioni di
gestione della discovery dei servizi Jini sono state
implementte con una classe ad-hoc, RTTSServiceDiscovery,
con la seguente interfaccia:
public
interface RTTSServiceDiscoveryListener {
void serviceAdded (ServiceItem serviceItem);
void serviceRemoved (ServiceItem serviceItem);
void serviceReachable (ServiceItem serviceItem);
void serviceUnreachable (ServiceItem serviceItem);
}
che
aggiunge la semantica di “reachable / unreachable”
a quella “added / removed” fornita da Jini.
In pratica, le disconnessioni “lunghe” vengono
gestite da Jini che le giudica come una rimozione definitiva
del servizio; le disconnessioni “corte” vengono
gestite da RTTS e considerate temporanee.
Esiste
però un'altra circostanza da gestire. Cosa succede
se:
- un
client C viene disconnesso;
- viene
pubblicato un nuovo servizio S;
- successivamente
C viene di nuovo connesso dopo pochi secondi.
Spesso,
la notifica di pubblicazione di S raggiunge C dopo un
periodo medio di un minuto (due minuti al massimo).
È infatti con questa frequenza che il LUS segnala
eventuali cambiamenti allo stato del sistema, mediante
il già citato “multicast announcement”.
Il client C, dal canto suo, non fa richieste esplicite
al LUS dal momento che, dal punto di vista di Jini,
le disconnesioni “corte” non vengono rilevate.
Abbiamo ovviato con l'aggiunta di una nuova classe,
FastServiceDiscovery. Essa monitorizza l'heartbeat di
cui abbiamo parlato precedentemente e, nel caso di una
disconnessione/riconnessione “corta” interroga
esplicitamente il LUS e fa un confronto con l'ultima
situazione nota. In caso di differenze, genera autonomamente
eventi “added / removed” mediante la stessa
infrastruttura di Jini, filtrando eventuali duplicati
che potrebbero essere generati dal LUS. Il bello di
questa soluzione è che è completamente
trasparente, dal momento che ogni client riceve “semplicemente”
gli eventi giusti al momento giusto, ignorando se essi
siano generati dal LUS o da FastServiceDiscovery. Ancora
una volta la facile espandibilità di Jini ci
ha permesso di trovare una soluzione elegante e poco
intrusiva.
Veniamo
al problema delle schede di rete multiple. Alcune scuderie,
per vari motivi, usano una doppia connessione di rete
tra i propri computer (generalmente per ottimizzare
il traffico). Cioè, la maggior parte dei computer
sono dotati di una doppia scheda di rete e questo consente
di avere due alternative per le comunicazioni. Abbiamo
detto “maggior parte”, ma non tutti. Il server
RTTS è tipicamente raggiungibile solo attraverso
una delle due sottoreti. Questo pone un problema a Jini.
Supponiamo che le due sottoreti siano individuate da
due indirizzi differenti, p.es. 192.168.x.x e 192.122.x.x.
Il server sa benissimo quale sia la sottorete “giusta”
(p.es. 192.168.x.x) perché è l'unica che
vede (e comunque qui è tollerabile un minimo
di configurazione). Il server, quindi, aprirà
i propri socket TCP/IP in modo corretto.
Ma
i client? A priori non possono conoscere la risposta
giusta e, purtroppo, Jini è implementato in modo
che ogni nodo apre socket passivi, in modalità
“listen”, cosa che in caso di schede di rete
multiple richiede di fare una scelta esplicita. Se un
client scegliesse erroneamente 192.122.x.x, si pregiudicherebbe
ogni possibilità di comunicazione con il server
(nella pratica le cose sono un po' più complesse
e le connessioni vengono comunque tentate, ma falliscono
con errori tipo “no route to host”). La soluzione
standard di Jini è che ogni nodo dichiari esplicitamente
nei suoi file di configurazione il proprio indirizzo
IP: ma, come detto, sul client le specifiche vietano
ogni tipo di configurazione esplicita.
La
soluzione non è stata complicata. Nel citato
heartbeat, usato per rilevare le disconnessioni, è
stata inserita l'informazione relativa all'indirizzo
di rete usato dal server (per i lettori esperti: in
linea di principio questo indirizzo potrebbe essere
ricavato dinamicamente dalle API dei socket, in quanto
dovrebbe essere possibile capire da quale sottorete
è stato ricevuto un certo pacchetto; ma purtroppo
la cosa funziona su Linux, non su Windows...). Ogni
client, prima di partire, attende l'heartbeat del server
ed estrae l'informazione necessaria. In pratica ciò
è stato implementato in modo molto elegante,
utilizzando l'aspetto dinamico dei file di configurazione
di Jini:
import
NetworkInterfaceSelector;
hostAddress = NetworkInterfaceSelector.getSelectedHostAddress();
serverExporter = new BasicJeriExporter(TcpServerEndpoint.getInstance(hostAddress,
0),
new BasicILFactory(), false, true);
L'esempio
sopra riportato non è codice Java, ma un file
dinamico di configurazione nel quale è possibile
fare riferimento a classi Java, sia di Jini che proprietarie.
NetworkInterfaceSelector è la nostra classe custom
che si mette in attesa dell'heartbeat e getSelectedHostAddress()
è il metodo che restituisce l'indirizzo richiesto.
Questo dato poi viene memorizzato nella variabile hostAddress,
utilizzata successivamente per configurare esplicitamente
tutti i TCP endpoint usati dal sistema. Nella pratica
le cose sono solo quantitativamente più complesse
(ci sono parecchi endpoint da configurare), ma il concetto
è lo stesso
L'alta
affidabilità, cioè la capacità
di utilizzare un canale di backup in caso di fallimento
del canale primario, è stata implementata prendendo
a prestito un pattern di J2EE, il “Business Delegate”.
La situazione è descritta in figura:
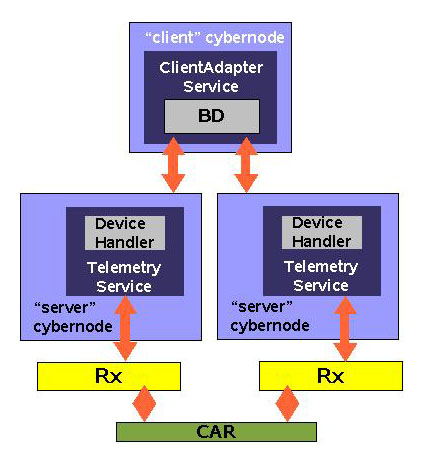
Figura 12
Come
già detto nell'introduzione, ogni automobile
ha due centraline e quindi due canali radio di trasmissione
dei dati di telemetria, che trasmettono in parallelo
gli stessi dati. Il sistema li rappresenta istanziando
due “Device Handler” (surrogate delle centraline).
I due “Telemetry Service” istanziati sui server
primario e secondario cooperano in modo che ognuno gestisce
un “Device Handler” differente. In questo
modo, ogni client ha due canali indipendenti che forniscono
i dati anche se una centralina, una radio o un server
si dovessero rompere (le combinazioni di rottura “incrociata”
di una centralina di un canale e di un server dell'altro
canale sono considerate estremamente improbabili e non
sono prese in considerazione”).
Il
ClientAdapter non interagisce direttamente con i proxy
dei “Device Handler”, ma mediante una classe
intermedia, il “Business Delegate”. Questa
espone sostanzialmente la stessa interfaccia del proxy,
ma rileva eventuali messaggi “removed / disconnected”
ed effettua autonomamente uno switch.
Questa
soluzione ha permesso di gestire con estrema facilità
una richiesta di modifica espressa da una scuderia durante
il progetto. Quando, durante le sessioni di test, un'auto
rientra temporaneamente nei box, l'auto viene collegata
alla rete del garage via cavo. È stato richiesto
di effettuare automaticamente uno switch sul canale
di comunicazione via cavo indipendentemente dalla contemporanea
disponibilità del canale radio, in quanto il
cavo è ovviamente più affidabile. Il canale
via cavo viene rappresentato da un nuovo “Device
Handler” con un funzionamento del tutto analogo
a quelli che rappresentano il ricevitore via radio.
Tutto è stato gestito all'interno del “Business
Delegate” semplicemente associando un profilo di
priorità tra diversi “Device Handler”,
per cui alcuni prendono il sopravvento su altri indipendentemente
dalla rilevazione di disconnessioni.
Infine,
un accenno al citato problema del reliable multicast.
Il multicasting, come già detto, è la
soluzione più elegante al problema della scalabilità,
dal momento che (almeno in linea teorica) svincola la
banda disponibile dal numero di client collegati. Purtroppo,
essendo una soluzione basata su protocollo UDP, non
è “affidabile”, nel senso che nessuno
garantisce che alcuni pacchetti non vengano persi (cosa
che può accadere in reti non sufficientemente
dimensionate o durante un picco di carico su un client).
La soluzione è quella di effettuare un compromesso
ed usare un protocollo di “reliable multicast”:
un'infrastruttura dedicata numera i pacchetti e i client
possono così rilevare quelli persi e richiederne
la ritrasmissione, con varie modalità. La scalabilità
non è più infinita, perché è
limitata dal traffico generato dalla ritrasmissione
(che è proporzionale al numero di client). Ma
con il giusto dimensionamento si può ottenere
il risultato voluto.
Il problema sta nei dettagli, come spesso accade. È
molto difficile realizzare un protocollo di reliable
multicast “in casa”, visto che la sua progettazione
richiede un accurato modello matematico della rete utilizzata.
D'altro canto esistono parecchi protocolli di reliable
multicast noti, ma un'analisi preliminare ci ha permesso
di verificare che nessuno di essi era il compromesso
auspicabile per RTTS: alcuni garantivano troppo poca
affidabilità, altri erano troppo onerosi computazionalmente.
Inoltre andavano escluse le implementazioni non 100%
Java. Come coniugare l'esigenza di un protocollo ad-hoc
con l'oggettiva difficoltà di progettarlo?
La
soluzione è venuta da JGroups, una libreria open-source
realizzata dal gruppo JBoss. Essa fornisce alcuni “mattoni
fondamentali” (aderenti ad una specifica standard,
la RFC 3048) che possono essere composti insieme in
varie combinazioni per ottenere il compromesso desiderato
tra affidabilità e performance. L'integrazione
in RTTS è avvenuta in modo del tutto trasparente
e non intrusivo, mediante il già citato meccanismo
dei proxy di Jini. Tuttavia, JGroups oggi non è
sostanzialmente utilizzato sul campo: la percentuale
di CPU utilizzata da RTTS sui client, estremamente bassa,
e il dimensionamento della rete ethernet (una gigabit)
fanno sì che la percentuale di pacchetti persi
dal multicast standard sia assolutamente trascurabile.
Conclusioni
Dobbiamo
dire subito una cosa: il progetto è stato stressante,
ma ci siamo divertiti: non capita molto spesso di poter
utilizzare una tecnologia di frontiera, come Jini e
Rio, in un ambito così delicato e challenging
come la Formula Uno. È stata una grande soddisfazione
portare a termine la realizzazione di un progetto così
difficile (oltretutto in pochi mesi e con un sostanziale
rispetto dei tempi) in un'area dove in molti non avrebbero
scommesso a priori l'effettiva usabilità di Java.
Oltre all'assoluta affidabilità delle tecnologie
usate, oltretutto customizzabili in tutti i loro aspetti,
ci piace concludere con una considerazione collegata
al metodo di sviluppo. Abbiamo usato Unified Process,
iterativo ed incrementale: possiamo dire semplicemente
che funziona. Il progetto, su un elapsed time di sei
mesi, è stato diviso in tre iterazioni: ad un
mese e mezzo dall'inizio era pronto il primo propotipo
da laboratorio e a tre mesi dall'inizio eravamo già
a provare il sistema in pista, a Jerez de la Frontera.
Questo ci ha permesso di affrontare fin da subito, e
quindi portare sotto controllo, tutti i rischi collegati
specialmente all'integrazione di RTTS in un ambiente
così complicato. Ovviamente una chiave di volta
del successo è stata l'elevata competenza delle
due aziende coinvolte, Magneti Marelli e Sun, sia per
le rispettive tecnologie utilizzate che, per quanto
riguarda Magneti Marelli nello specifico, nell'esperienza
di pista. Senza un esperto che vi assista, vi assicuriamo
che è difficile monitorare e debuggare un sistema
sotto test dovendo sincronizzare le vostre operazioni
con gli unici due minuti in cui, periodicamente, la
macchina rientra al box e in cui potete mettere le mani
sul laptop dell'ingegnere di pista!
Infine,
essendo supporter del concetto di open-source, ci piace
ricordare che tutte le tecnologie usate, da Java a Jini
a Rio a JGroups, sono – in vari modi – proprio
tecnologie open-source; a completamento di questa visuale,
va ricordato che alcune scuderie usano Linux per i propri
server. Questo per convincere gli scettici che l'open-source
può realmente funzionare anche in ambienti così
sofisticati.
Fabrizio
Giudici ha iniziato ad occuparsi di Java durante
il suo dottorato di ricerca, concluso nel 1998 presso
l'Università di Genova e focalizzato sulle applicazioni
industriali della tecnologia di Sun. In quegli anni
ha iniziato la collaborazione con Mokabyte, scrivendo
articoli tecnici e partecipando al gruppo di consulenti
che iniziavano a tenere i primi seminari su Java in
Italia.
Sempre nel 1998, insieme a due amici, ha fondato un'azienda
di consulenza e progettazione, iniziando tra ll'altro
la collaborazione con Sun Microsystems Educational Services.
Sin dal 1998 si è occupato, tra l'altro, di docenza
qualificata sull'area Java, in particolare su Java 2
Enterprise Edition e sui metodi di Analisi e Progettazione
ad Oggetti.
Dal 2001 Fabrizio ha iniziato a lavorare come libero
professionista, sia nel campo della formazione che della
progettazione di sistemi informatici (J2EE in particolare,
ma con frequenti incursioni in area J2ME), avendo tra
i propri clienti un gran numero di piccole, medie ed
aziende italiane. Nel 2003 è iniziata la colalborazione
con Sun Microsystems Professional Services per le attività
di progettazione, in qualità di Senior Architect
e Project Leader.
Dalla fine del 2005 Fabrizio opera di nuovo con una
piccola azienda da lui fondata, la Tidalwave, che si
occupa di consulenza, formazione, progettazione e project
management.
Dall'inizio della sua carriera Fabrizio ha progettato
e realizzato un gran numero di applicazioni software
e servizi - inizialmente in C/C+ + e successivamente
in Java - in varie aree industriali, dal settore finanziario
alle telecomunicazioni alle competizioni automobilistiche.
Nel 2004 ha diretto per conto di Sun Microsystems e
Magneti Marelli il team che ha progettato e realizzato
un sistema di telemetria in tempo reale per la Formula
Uno, basato su tecnologia Jini.
Fabrizio è membro dell'IEEE (Institute of Electrical
and Electronics Engineers).
Antonella
Balduzzi è in Sun dal 2001e fa parte del
gruppo Enterprise Web Services presso la sede di Milano.
Si occupa di progettazione e sviluppo di soluzioni basate
su tecnologia Java e del supporto ai progetti basati
sulle tecnologie J2EE e RFID. In precedenza si e' occupata
di varie tematiche legate a Java, dalla performance
analisys, alla code review e alla realizzazione di progetti.
Antonella ha circa 10 anni di esperienza nella realizzazione
di progetti software in Java ed in altri linguaggi ed
ha svolto la sua attività, prima di Sun, presso
System Integrator italiani e stranieri.
|

