Tutte le considerazioni
fatte in precedenza in definitiva riguardano gli aspetti
relativi alla comunicazione fra i vari strati applicativi,
la modalità con la quale i dati debbano essere
manipolati e manenuti sul presentation layer: niente
(o quasi) per adesso è stato detto circa quello
che si nasconde “dietro” il Session Façade
(del resto questo è un risultato cercato e ottenuto
grazie alla motivazione di questo pattern).
Rimane da capire come sia possibile trasferire i dati
contenuti all’interno del DTO da e verso il sistema
di persistenza (tipicamente il database relazionale
sul quale tutta l’applicazione si poggia). Utilizzando
una terminologia Java Enterprise, quello che ancora
non si è detto è come utilizzare con profitto
un framework di mapping Object-Relational al fine di
nascondere tutti i dettagli relativi alla gestione della
connessione con il database.
Si vedrà anche come sia possibile gestire in
maniera trasparente la trasformazione oggetto-tabella
con particolare riferimento alle relazioni e aggregazioni
di oggetti, cancellazioni a cascata e simili.
NOTA:
la specifica Java EE impone che l'applicazione in esecuzione
all'interno del container non debba e non possa gestire
direttamente la connessione al database, essendo questo
un compito a totale carico dell’application server.
Questo, dopo aver instaurato una connessione fisica
con il server dati, mette a disposizione una connessione
virtuale con il supporto di un connection pooling, sicurezza,
transazionalità e tutti i servizi tipici di una
applicazione di alto livello.
Al programmatore resta da scegliere lo strumento tramite
il quale effettuare il mapping Object-Relational (OO-RDB)
ed eseguire tramite tale strumento la sincronizzazione
dello stato degli oggetti con i dati residenti nel database.
L’evoluzione tecnologica
degli ultimi anni ha ampiamente giustificato e anzi
fortemente consigliato l'utilizzo di strumenti di mapping
Object relational per sincronizzare lo stato di un oggetto.
Lo stato dell’arte attuale vede lo scenario dominato
da framework e tecnologie quali Hibernate, JDO, CMP
2.0 (con EJB 3.0 + Hibernate in fase di rilascio).
Quanto vedremo non deve essere considerata come l’unica
soluzione possibile, dato che nella realtà dei
progetti enterprise sempre più spesso si vedono
mescolare con successo tecnologie differenti in modo
da rispondere alle varie esigenze e requisiti del progetto.
Tanto per fare un esempio in questo particolare momento
è molto in voga per la realizzazione di applicazioni
enterprise, l’utilizzo di session beans per la
parte di business unitamente ad Hibernate per la parte
di mapping.
Parlando invece di applicazioni “solo” EJB
(oggetto di questa serie di articoli) lo strumento che
andremo a vedere è il Container Managed Persistence,
tecnologia giunta ormai alla versione 2.0.
In realtà CMP 2.0 non è altro che un pezzetto
della specifica EJB, ma a causa della importanza della
tecnologia e la diversità rispetto alle versioni
precedenti (che non venivano considerate come una parte
a se stante ma integrate a tutti gli effetti in EJB
1.0, 1.1), spesso viene indicata da sola per rafforzarne
l’importanza.
Nota importante sulle motivazioni della serie
Questo nuovo gruppo di articoli dedicati alla persistenza
con CMP, e facenti parte della serie sullo sviluppo
di applicazioni enterprise con EJB, non è stato
pensato per essere un corso teorico su EJB ne sui trucchi
di CMP.
Lo scopo è piuttosto quello di fornire un approccio
concreto per utilizzare alcune delle tecniche di progettazione
più in voga attualmente; come fatto nei precedenti
articoli dedicati allo strato session, si cercherà
di mostrare come usare pattern e tecniche di progettazione
al fine di progettare e implementare lo strato di persistenza
cercando di perseguire gli obiettivi mostrati in precedenza,
ovvero flessibilità, scalabilità, prestazioni,
semplicità di manutenzione.
Non si seguirà una trattazione rigorosa e meticolosa
su cosa sia un Enterprise Java Beans CMP, ne scenderemo
nel dettaglio di aspetti come il ciclo di vita di un
entity CMP o sulla miriade di messaggi che il bean e
il container si scambiano durante tutto il corso della
vita di un componente come questo.
Per questo genere di argomenti si può fare riferimento
a un qualsiasi manuale su EJB (come ad esempio [EJB])
compresa la serie di articoli pubblicata in passato
su MokaByte confluita infine nel capitolo su Enterprise
Java Beans del Manuale Pratico di Java, realizzato dalla
redazione di MokaByte (vedi [MokaEJB]).
Cosa è
un entity bean
Un bean entity è un componente EJB il cui scopo
principale è quello di rappresentare una entità
astratta, come insegna comunemente un qualsiasi processo
di analisi a oggetti. Un oggetto di questo tipo rappresenta
quindi un dato semplice o un aggregato, il quale possiede
attributi di stato e di relazione (con altri oggetti/entità).
Importante tenere sempre ben presente che un CMP vive
all’interno di un application server il quale
mette a disposizione alcuni servizi: il più importante
è certamente il meccanismo di persistenza dello
stato dell’oggetto, ma non si devono trascurare
la transazionalità, la gestione della sicurezza,
la gestione del ciclo di vita delle varie istanze di
oggetti gestiti in modalità pooled.
Tralasciando il punto di vista dell’application
server e ponendosi invece dal punto di vista del business
logic layer (che sarà l’utilizzatore dei
componenti EJB) si potrebbe dare una definizione molto
sintetica e pragmatica: un CMP è un componente
che mappa una entità astratta che potrà
essere utilizzata nel workflow applicativo essendo sicuri
che l’application server svolgerà per noi
una serie di operazioni.
Non ci si preoccuperà
quindi di transazionalità, sicurezza, resistenza
al carico di lavoro (grazie al pooling di istanze) e
persistenza: con la consapevolezza che l’application
server svolge queste queste mansioni, si concentrerà
l’attenzione su quelle tecniche e pattern architetturali
che possano soddisfare le necessità del business
layer, senza ostacolare il lavoro del container ma anzi
facilitandone il compito.
Prima
regola: stato si, comportamento no
La programmazione ad oggetti ci ha da sempre insegnato
che unitamente allo stato, un oggetto possiede anche
un comportamento (reso possibile grazie all’uso
dei metodi), cosa che lo distingue da strutture dati
tipiche dei linguaggi di programmazione non ad oggetti.
In una applicazione multistrato di fascia enterprise,
sebbene la specifica non lo imponga e nemmeno lo preveda
ufficialmente, è buona norma adottare una regola
universale che porta a una sostanziale differenza fra
un oggetto comune e un entity bean: essendo questo un
elemento che rappresenta una entità astratta,
dovrebbe sempre memorizzare uno stato e non offrire
nessuna logica di business.
Una entità quindi non deve contenere metodi di
business logic ma eventualmente metodi che consentano
di gestire lo stato della entità stessa: si dovrebbero
quindi inserire metodi accessori/modificatori (getXXX
e setXXX) o metodi che compiano una qualche conversione
dei dati stessi, possibilmente senza alterare lo stato
del bean. Ad esempio se il bean contiene una variabile
di tipo data che memorizza la data di nascita di una
persona, potrebbe essere utile disporre di un metodo
che restituisca tale data in formato stringa o che esegua
una qualche conversione da data in formato europeo a
formato statunitense.
Prendendo ad esempio il caso introdotto più avanti
nell’articolo, se si considera una entità
rappresentante un conto in banca o un bancomat, è
lecito che sia possibile interrogare il conto per conoscere
il saldo, ma è certamente poco piacevole che
il conto corrente eseguire operazioni autonomamente
senza il controllo di un soggetto attivo (il cassiere
o genericamente la business logic controllata dal sistema
web di home banking).
Solo interfaccia
locale
Altra regole molto da seguire nella progettazione di
una applicazione multistrato è quella di non
implementare mai l’interfaccia remota di un entity
bean (ovvero permettere ad un client di accedere direttamente
all’entity senza l’intercessione dello strato
di logica): se un entity rappresenta una struttura dati
astratta che mappa in un qualche modo una entità
del data model, risulta semplice comprendere quanto
sia controindicato fornire diretto accesso alla applicazione
client a tale entità. Per una moltitudine di
ragioni è più saggio e corretto fornire
accesso al data model tramite l’apposito strato
di business logic dove si potranno concentrare tutti
controlli su sicurezza, coerenza sui dati, e procedere
secondo le regole imposte dal workflow applicativo.
Con un esempio un po’ pittoresco, si potrebbe
pensare al caso in cui si debba effettuare un pagamento
presso un negoziante di fiducia fornendo direttamente
il bancomat con tanto di codice, piuttosto che usare
il bancomat per eseguire il pagamento tramite POS. In
questo caso il cliente del negozio svolge il compito
di session façade agli occhi del negoziante:
è lui che conosce il codice del bancomat e lo
tiene segreto (session-security), ed è lui che
sfrutta la logica di business per accedere in maniera
controllata al datamodel (il conto corrente).
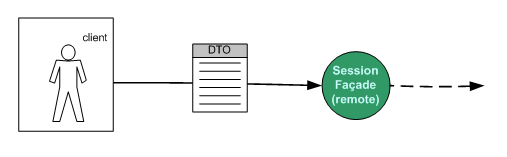
Figura 1 – Il client interagisce con
un session façade con il quale scambia informazioni
e dati per mezzo di DTO.
Cosa avvenga “dietro” al façade è
ignoto per il client.>>
La creazione di un bean
Come dovrebbe essere noto, non è possibile creare
direttamente un entity bean: come molti altri aspetti
relativi al ciclo di vita del componente, anche la procedura
di creazione dell’oggetto viene gestita dal container,
il quale in un determinato momento del ciclo di vita
del bean ne invoca il metodo ejbCreate() e ejbPostCreate().
Supponendo il caso in cui si debba procedere alla creazione
di un bean con i dati inserite dall’utente tramite
un form HTML: tali dati fluiscono tramite un DTO dallo
strato web, passano per quello di business logic per
arrivare all’entity bean in questione. Il DTO
potrebbe contenere solamente le informazioni necessarie
alla creazione della entità che si deve aggiungere
al sistema, oppure anche dati (chiavi o DTO completi)
relative a entità con le quali il nuovo oggetto
dovrà instaurare relazioni di vario genere. Questi
concetti sono stati ampiamenti analizzati negli articoli
in cui si è parlato delle possibili tecniche
di gestione dei DTO (vedi [DTO1] e [DTO2]).
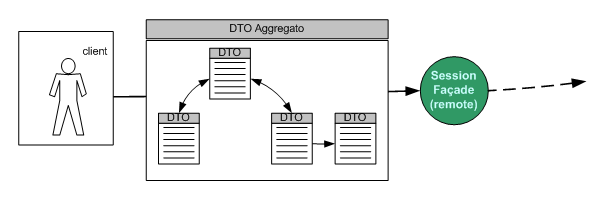
Figura 2 – Il DTO potrebbe essere
composto come un aggregato di DTO a grana più
fine. Client e session façade non si preoccupano
di questi aspetti, limitandosi a trasferire un DTO indipendentemente
dalla sua composizione e organizzazione interna.>>
Il metodo ejbCreate()
è quindi il luogo deputato per eseguire il trasferimento
dei dati dal DTO al bean.
Per rendere più chiara la trattazione è
utile prendere un esempio concreto per spiegare i vari
passaggi; al solito l’applicazione di riferimento
è MokaByteCMS, il CMS open source sviluppato
dal team di sviluppatori di MokaByte.
Si immagini quindi che si debba procedere nella creazione
di un articolo da inserire nel CMS.
Per tale scopo il session bean ArticleManager (avente
funzione di session façade) espone tramite la
sua interfaccia remota il seguente metodo
public void createArticle(ArticleDTO articleDTO) throws
FacadeInvocationException, SectionNotFoundException
Tale metodo viene in
genere invocato all’interno di una classe dello
strato web della applicazione (tipicamente una action
MVC). Ad esempio si potrebbe sintetizzare con le seguenti
operazioni la sequenza delle operazioni svolte all’interno
del client
//
inizializza la connessione con la interfaccia remota
del session façade
String FACADE_NAME = "ArticleManagerSF";
Class FACADE_CLASS = com.mokabyte.cms.ejb.ArticleManagerSFHome.class;
ArticleManagerSFHome articleManagerSFHome;
try {
ServiceLocator locator = ServiceLocator.getInstance(jndiProperties);
articleManagerSFHome = (ArticleManagerSFHome)
locator.getEjbHome(FACADE_NAME, FACADE_CLASS);
if (articleManagerSFHome == null) {
throw new Exception("Impossibile
ricavare la home interface " + FACADE_NAME);
}
//
ricava l’interfaccia remota del session façade
articleManagerSFRemote = articleManagerSFHome.create();
}
catch (ServiceLocatorException e) {
throw new Exception(e.getMessage());
}
...
try {
logger.debug("invocazione di SF remoto");
// invoca il metodo remoto per la
creazione dell’articolo
articleManagerSFRemote.createArticle(articleDTO);
}
catch (RemoteException re) {
String msg = "Errore di invocazione
remota sul metodo di façade createArticle() \n"
+ re;
logger.error(msg);
throw new FacadeInvocationException(msg);
}
Il codice di esempio appena riportato è stato
così riassunto per esigenze di sintesi e chiarezza,
ma nella realtà è eseguito dal client
non direttamente ma tramite gli ormai noti pattern Business
Delegate e Service Locator.
Passando al session
façade, all’interno del metodo createArticle()
si delega la creazione del bean al bean stesso invocandone
il metodo create(), il quale riceve il DTO ricevuto
dalla strato client.
Per fare questo il session bean dovrà aver precedentemente
ricavato l’interfaccia home locale del bean Article:
questa operazione in genere viene effettuata all'interno
del metodo setSessionContext() che rappresenta il punto
di ingresso del ciclo di vita di un session:
public
void setSessionContext(SessionContext sessionContext)
{
this.sessionContext = sessionContext;
try
{
//
inizializza le home interfaces
if
(articleLocalHome == null) {
try
{
ServiceLocator
locator = ServiceLocator.getInstance();
//
ricava la home interface con l’ausilio del service
locator
articleLocalHome
= (ArticleLocalHome) locator.getEjbLocalHome(ENTITY_NAME);
}
catch
(ServiceLocatorException e) {
throw
new EJBException(e.getMessage());
}
}
}
catch (Exception e) {
throw
new EJBException(e.getMessage());
}
}
A questo punto può
essere invocato il metodo createArticle() che al suo
interno potrebbe essere così organizzato:
public void createArticle(ArticleDTO articleDTO) throws
EJBException {
try
{
//
crea il bean invocando il metodo create sulla sua Home
interface
ArticleLocal
articleLocal = articleLocalHome.create(articleDTO);
}
catch
(Exception e) {
throw
new EJBException(e.getMessage());
}
//
Esegue altre operazioni di sincronizzazione dello stato
.
. .
}
Si noti la presenza di ulteriori operazioni relative
alla creazione di un articolo: ad esempio si potrebbe
rendere necessario aggiornare un contatore che memorizza
il numero complessivo di articoli presenti nel sistema.
Esse potranno essere eseguite all'interno del metodo
certi che ogni modifica al sistema sarà coerente
con il processo di creazione dell'articolo, essendo
il contesto processato in maniera transazionale.
A questo punto il container,
dopo avere effettuato i debiti controlli sulla validità
dei parametri passati e dopo aver ricavato dal pool
di oggetti il bean opportuno (vuoto se si sta creandone
uno nuovo come in questo caso), scinde la chiamata del
metodo create() nei due corrispettivi ejbCreate() e
ejbPostCreate().
Non si entrerà nei dettagli di quelle che sono
le regole relative alla firma (parametri ed eccezioni)
dei vari metodi create(), ejbCreate() ed ejbPostCreate():
per quello che concerne la creazione del bean è
sufficiente ricordare che è necessario inserire
nel metodo ejbCreate() tutta la logica relativa alla
valorizzazione degli attributi semplici del bean, rimandando
al metodo ejbPostCreate() la assegnazione delle relazioni
fra il bean e i suoi bean dipendenti (operazione che
verrà mostrata in seguito).
Dovrebbe essere quindi piuttosto intuitivo il significato
del contenuto del metodo ejbCreate() riportato qui di
seguito
public
String ejbCreate(ArticleDTO articleDTO) throws CreateException
{
this.setId(articleDTO.getId());
this.setAbstractText(articleDTO.getAbstractText());
this.setBody(articleDTO.getBody());
this.setIntroducion(articleDTO.getIntroducion());
this.setName(articleDTO.getName());
this.setStatus(articleDTO.getStatus());
this.setNotes(articleDTO.getNotes());
this.setSubTitle(articleDTO.getSubTitle());
this.setTitle(articleDTO.getTitle());
this.setSerialName(articleDTO.getSerialName());
this.setColumnName(articleDTO.getColumnName());
this.setKeywords(articleDTO.getKeywords());
return
"";
}
Si tratta di una semplice impostazione delle variabili
del bean semplici; tutti gli attributi di relazione
verranno assegnati in seguito nel metodo ejbPostCreate().
La
creazione del DTO: il legame con il DTOAssembler
Dopo aver analizzato il flusso di dati relativo al processo
di creazione di un entity bean, flusso che vede migrare
un DTO dallo strato client a quello server, potrebbe
essere interessante prendere in considerazione il percorso
inverso che i dati intraprendono: dal bean verso il
client.
Questo tragitto è quello che usualmente viene
effettuato in corrispondenza di una interrogazione del
client sullo strato di business logic, ad esempio per
una comune ricerca per chiave primaria.
In questo caso il session effettua la ricerca dell’entity
utilizzando i parametri di ricerca ricevuti e preleva
i dati dell’entity bean individuato per immetterli
in un DTO che viene poi inviato al client.
Per prima cosa il client invoca il metodo di ricerca
sul session façade: come mostrato negli articoli
precedenti, tale invocazione verrà eseguita all'interno
del business delegate associato al façade, ma
per semplicità tralasceremo questo dettaglio,
dando per già fatto (come mostrato in precedenza)
le operazioni di lookup della interfaccia remota di
ArticleManagerSF;
ArticleDTO
articleDTO = null;
try {
articleDTO = articleManagerSFRemote.articleFindByPrimaryKey(articleId);
}
catch (RemoteException re) {
String msg = "Errore di invocazione
remota sul metodo di façade." + re;
logger.error(msg);
throw new FacadeInvocationException(msg);
}
Il metodo remoto del
session façade articleFindByPrimaryKey() è
semplice nella sua implementazione:
public
ArticleLocal articleFindByPrimaryKey(String id) throws
EJBException {
try
{
ArticleLocal
articleLocal = articleLocalHome.findByPrimaryKey(id);
return
ArticleDTOAssembler.createDto(articleLocal);
}
catch (ObjectNotFoundException onfe) {
logger.debug("nessun
articolo trovato con Id=" + id);
return
null;
}
catch
(Exception e) {
throw new EJBException(e.getMessage());
}
}
Si noti l'invocazione
del metodo statico createDTO() sull'oggetto ArticleDTOAssembler.
Questo era stato già presentato in un articolo
precedente della serie ma per semplicità verrà
qui riproposto:
public
static ArticleDTO createDto(ArticleLocal articleLocal)
{
ArticleDTO
articleDTO = new ArticleDTO();
if
(articleLocal != null) {
articleDTO.setName(articleLocal.getName());
articleDTO.setAbstractText(articleLocal.getAbstractText());
articleDTO.setBody(articleLocal.getBody());
articleDTO.setColumnName(articleLocal.getColumnName());
articleDTO.setId(articleLocal.getId());
articleDTO.setIntroducion(articleLocal.getIntroducion());
articleDTO.setKeywords(articleLocal.getKeywords());
articleDTO.setNotes(articleLocal.getNotes());
articleDTO.setSerialName(articleLocal.getSerialName());
articleDTO.setStatus(articleLocal.getStatus());
articleDTO.setSubTitle(articleLocal.getSubTitle());
articleDTO.setTitle(articleLocal.getTitle());
articleDTO.setImpressions(articleLocal.getImpressions());
if
(articleLocal.getArticlelink() != null){
articleDTO.setLinkPosition(articleLocal.getArticlelink().getPosition());
}
//
crea i DTO dipendenti e li lega al DTO da restituire
come risposta del metodo
articleDTO.setFigureDTOs(FigureDTOAssembler.createDtos(articleLocal.getFigures()));
articleDTO.setIconDTO(IconDTOAssembler.createDto(articleLocal.getIcon()));
articleDTO.setLightSectionDTO(SectionDTOAssembler.createLightDTO(articleLocal.getSection()));
articleDTO.setWriterDTOs(WriterDTOAssembler.createDTOs(articleLocal.getWriters()));
articleDTO.setAttachmentDTOs(AttachmentDTOAssembler.createDtos(
articleLocal.getAttachments()));
}
return
articleDTO;
}
Interessante
osservare l'uso come nella parte conclusiva del metodo
ci si preoccupi di procedere ad assegnare gli oggetti
DTO dipendenti (DTO per le figure, icone, sezione, autori,
allegati).
Il come siano gestiti gli oggetti dipendenti nel bean
e conseguentemente anche nei DTO è un aspetto
di cui ci occuperemo nel prossimo articolo.
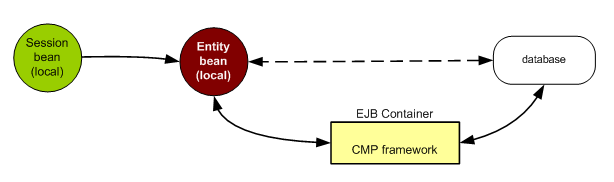
Figura 3 – La sincronizzazione
dello stato del bean è una operazione sotto la
completa responsabilità del container
EJB che tramite il framework utilizzato gestisce la
persistenza delle informazioni memorizzate nell’entity
bean.
Conclusione
In questo primo articolo dedicato alla persistenza si
è iniziato un cammino piuttosto lungo: gli argomenti
appena introdotti rappresentano la base per gli approfondimenti
delle puntate successive.
E’ importante comprendere lo spirito di questa
serie e soprattutto l'obiettivo principale: non un corso
di EJB ma una raccolta di indicazioni utili sia in senso
assoluto che per sfruttare nel migliore dei modi quanto
appreso negli articoli precedenti.
Nel prossimo articolo parleremo di campi di relazione
e dell'importante ruolo che ricoprono sia nella gestione
delle relazioni fra i vari Entity Beans, sia nel trasferimento
dei dati su i DTO.
Bibliografia
[EJB] – “Enterprise Java Beans” di
Richard Monson-Haefel, Bill Burke, and Sacha Labourey.
O'Reilly Media, Inc. ISBN: 059600530X.
[MokaEJB] –
Capitolo su EJB del “Manuale Pratico di Java”,
II Ed. - volume 2. - http://www.mokabyte.it/libri/manualejava2/
[DTO1] “Architetture
e tecniche di progettazione EJB - III parte: la trasmissione
dei dati fra gli strati tramite il pattern DTO (introduzione)”
di Giovanni Puliti, MokaByte 102 – Dicembre 2005
- http://www.mokabyte.it/2005/12/ejbarchitectures-3.htm
[DTO2]
“Architetture e tecniche di progettazione EJB
- III parte: la trasmissione dei dati fra gli strati
tramite il pattern DTO (approfondimenti)” di Giovanni
Puliti, MokaByte 103 - Gennaio 2006 - http://www.mokabyte.it/2006/01/ejbarchitectures-4.htm

