|
Introduzione
Agli
albori dell'informatica un saggio architetto di sistema
disse: "non si può gestire un'applicazione
che non si può monitorare". In molti casi
documentare il design di una nuova applicazione, lasciamo
stare poi documentare come potrebbe essere monitorata,
è oltre lo scopo del progetto. Questo articolo
descrive un meccanismo riutilizzabile per ottenere le
statistiche di performance su applicazioni J2EE altamente
distribuite.
Fondamentalmente
le applicazioni devono essere preparate per supportare
dei livelli di servizio (Service Level Agreement). In
alcuni casi i SLA possono avere una granularità
fine come, per esempio, dichiarare il tempo medio atteso
per realizzare la persistenza dei dati relativi ad una
persona. L'architettura mostrata in figura 1 è
stata implementata per gestire un modulo d'ordine via
Internet comprendente un mezzo per permettere ad un
cliente di aggiornare il proprio profilo.
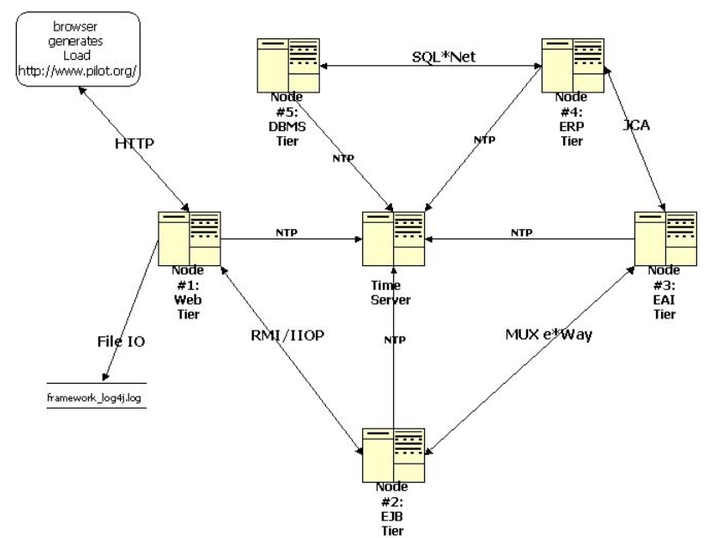
Figura 1 - Una architettura distribuita J2EE
Poiché
era previsto alto traffico l'applicazione utilizza le
transazioni distribuite EJB, che possono essere aggregate
in cluster e pool per ottenere alta disponibilità
e scalabilità. Le applicazioni altamente distribuite
non devono essere realizzate pensando solamente al punto
di vista degli oggetti distribuiti, ma anche dalla prospettiva
del bilanciamento del carico e del clustering. L'architettura
in figura non mostra i dettagli dell'implementazione
del clustering e del bilanciamento del carico.
Questo
testo descrive una metodologia di base per i test di
performance su un'architettura distribuita, in particolar
modo tratta del design e del codice necessario per ottenere
una stima di base della velocità di una applicazione
distribuita.
Architettura
distribuita e sincronizzazione del tempo
L'applicazione J2EE in figura si basa su cinque strati:
Web, EJB, EAI (Enterprise Application Integration),
ERP (Enterprise Resource Planning) e DBMS. Un client
da internet invia una richiesta HTTP allo strato Web
il quale ritrasmette la richiesta allo strato EJB tramite
RMI o IIOP. Lo strato EJB comunica con lo strato EAI
"SeeBeyond" utilizzando un MUX e*Way della
SeeBeyond. Lo strato EAI comunica con l'applicazione
CRM (Customer RelationShip Management) della PeopleSoft
all'interno dello strato ERP utilizzando un adattatore
della PeopleSoft. Per finire l'applicazione CRM comunica
con un DBMS Oracle attraverso SQL*net.
Una
delle parti chiave di ogni ambiente distribuito è
il time server. La nostra metodologia raccoglie le metriche
sul server dove il codice viene eseguito, quindi è
importante che tutte le macchine all'interno dell'architettura
distribuita J2EE abbiano l'orario di sistema sincronizzato.
Nell'ambiente Unix IBM AIX si utilizza il demone xntpd
per settare l'ora di ogni macchina. Tale servizio è
usato per sincronizzare gli orari con una macchina esterna
utilizzzando il protocollo NTP (Network Time Protocol).
In genere esiste un computer che funge da time server
(sul quale non è necessario che giri Unix o AIX)
al quale tutti gli altri computer di una organizzazione
si sincronizzano alla partenza (in realtà si
sincronizzano anche periodicamente).
Alternativamente
una macchina si può sincronizzare con un time
server esterno su Internet. Il demone xntpd è
configurato spento di default quindi le varie informazioni,
come per esempio l'indirizzo IP del time server, vanno
configurate nel file "ntp.conf". Poiché
la precisione richiesta per le metriche è a livello
di secondi o addirittura di millisecondi eventuali discrepanze
fra le varie macchine possono condurre a statistiche
errate.
Specifiche
degli oggetti e comportamento della strumentazione
L'architettura
J2EE proposta si basa su vari design pattern famosi
come per esempio: Business Delegate (conosciuto meglio
come Proxy) , Data Access Object, Model View Controller,
Session Facade e Transfer Object (conosciuto anche come
Value Object). Un "transfer object" è
una classe serializzabile che raggruppa attributi simili
per formare un valore composto. Nell'architettura il
"value object" è utilizzato come tipo
di ritorno di un metodo business remoto come appunto
negli Enterprise Java Bean. Ottenere attributi multipli
attraverso un unico value object in un sola interazione
con il server diminuisce il traffico di rete e minimizza
la latenza e l'utilizzo delle risorse del server.
La
figura 2 descrive l'oggetto PersonValueObject che implementa
le interfacce IpersonValueObject e Serializable. Il
bean PersonWorkerBean usa un PersonValueObject per contenere
gli attributi di una persona e delle temporizzazioni.
Gli attributi delle temporizzazioni sono di tipo long
e contengono il valore ottenuto da System.currentTimeMillis().
L'oggetto PersonValueObject include anche metodi di
accesso per tutti gli attributi.
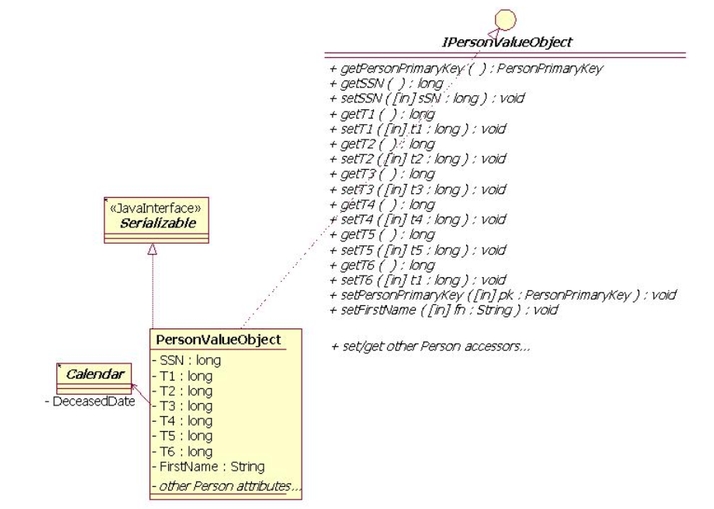
Figura
2 - diagramma UML del pattern Value Object, noto
anche
come Tranfer Obejct
(clicca sull'immagine per ingrandire)
Mentre
è una buona pratica OO quella di provvedere dei
metodi di accesso invece che manipolare direttamente
le variabili d'istanza bisogna tenere conto che accedere
ad una variabile attraverso un metodo rallenta l'esecuzione
del programma. È utile avere dei metodi di accesso
che nascondano l'implementazione di get e set e che
permettano alle sottoclassi di cambiare il tipo di sincronizzazione
di get e set, ma anche questo comporta dei costi aggiuntivi.
I value object possono essere estesi tramite subclassing
oppure possono avere associazioni con altri value object.
Per esempio se le specifiche richiedono che tutti i
value object di una applicazione debbano essere testati
per la performance, è raccomandabile effettuare
il refactoring dei metodi per il test raggruppandoli
in un FrameworkValueObject. In questa specifica alternativa
per la figura 2 l'oggetto PersonValueObject estende
il FrameworkValueObject e implementa l'interfaccia IpersonValueObject;
l'interfaccia IpersonValueObject estende IframeworkValueObject.
Comunque le operazioni di IpersonVAlueObject sono le
stesse di figura 2 per entrambe le versioni. Il vantaggio
di usare questo modello è quello che tutti i
value object estendono FrameworkValueObject e quindi
possiedono metdodi per effettuare i test. Questa è
una relazione molto complessa e, nonostante sia corretta
dal punto di vista dell'linguaggio UML, aggiunge comunque
un costo all'applicazione.
Per
i value object che hanno un'associazione diretta con
altri value objcet, queste relazioni sono implementate
come variabili d'istanza di classe. UML raccomanda che,
per un value object che sia in relazione di aggregazione
o di composizione con altri value object, questa relazione
sia implementata come una Collection. Una Collection
è l'interfaccia radice di tutta la gerarchia
delle Collection Java. Una Collection rappresenta un
gruppo di oggetti, conosciuti col nome di "elementi".
Quest interfaccia è tipicamente usata per manipolare
insiemi di oggetti qualora sia richiesta la massima
generalità. Per esempio un oggetto PersonValueObject
contiene una relazione uno a molti verso una Collection
di AddressValueObject. Comunque questa relazione non
è inclusa nel diagramma perché non riguarda
i test cronometrati, ma è importante conoscerla
ugualmente perché si usa nelle applicazioni reali.
Il
processo di raccolta dei dati strumentali.
L'obiettivo
di questo progetto è:
- di
stimare il tempo totale impiegato per trattare e rendere
persistente un PersonValueObject all'interno dei componenti
middleware;
- di
determinare quali livelli o quali parti sono quelle
computazionalmente più costose e che quindi
richiedono un'ottimizzazione;
- di
poter fare il log dei test sui tempi di vari livelli
in un singolo file di log per semplificare l'analisi
del report.
Dopo
che all'oggetto valore sono stati aggiunti i metodi
per raccogliere i tempi, sono necessarie delle modifiche
anche al codice in J2EE e SeeBeyond. È necessario
identificare gli oggetti che settano le stime dei tempi
nel value object responsabile per il suo livello, e
inoltre quale oggetto debba essere responsabile per
ottenere le stime e scriverle nel log. La decisione
dei posti dove mettere del codice per raccogliere i
tempi è stata arbitraria. Si è trovato
che i seguenti oggetti dovevano essere modificati
- PersonWorkerBean
del livello Web - che deve diventare responsabile
per settare gli attributi dei tempi (cioè T1
e T6) sul PersonValueObject per determinare il tempo
totale speso nel trasmettere l'oggetto EJB Session
remoto dal livello Web, e per prendere le stime dei
tempi dall'oggetto PersonValueObject e scriverle in
un singolo file di log.
- il
SessionBean EJB del livello EJB - responsabile per
il settaggio delle stime dei tempi (T2 e T5) sul PersonValueObject
per determinare il tempo impiegato nel livello EJB
per ottenere una connessione a SeeBeyond e per trasformare
il PersonValueObject in una stringa da far processare
SeeBeyond.
- PersonDAO
(Data Access Object) del livello EJB - responsabile
per settare le stime dei tempi (T3 e T4) del PersonValueObject
per determinare il tempo totale impiegato nel livello
EAI.
Limitazioni
dell'architettura
L'input
per il test dell'applicazione è stato generato
usando LoadRunner della Mercury Interactive ma non parleremo
di questo perché è oltre gli obiettivi
di questo testo. Il tempo di trasferimento dati dal
server HTTP al browser non è raccolto dal value
object; i tempi impiegati dal download da intranet si
calcolano sottraendo il tempo raccolti nel log framework_log4j.log
dal PersonValueObject dai tempi ottenuti da LoadRunner.
L'output
di log4j.log può essere salvato su file, su un
OutputStream, su un java.io.Writer, su un server log4j
remoto, su un server remoto syslog Unix o addirittura
su un logger di eventi di Windows NT. La performance
di log4j è molto buona. Su un AMD Duron a 800mhz
col JDK 1.3.1 occorrono 5 nanosecondi per stabilire
se un comando di log deve essere effettivamente scritto
sul log o no. Anche la fase di scrittura su log è
piuttosto veloce, a partire da 21 microsecondi utilizzando
la configurazione standard.
È
importante far notare che lo scopo di questa metodologia
non è quello di fare il profiling della memoria
o della cpu, in quanto in tal caso si potrebbe utilizzare
JProbe di QuestSoftware oppure OptimizeIt della Borland.
Gli unici strumenti che sono specifici per il controllo
distribuito della performance in maniera simile a quanto
suggerito in questo articolo sono PathWAI Dashboard
di Candle Corp e Introscope di Wily Technology.
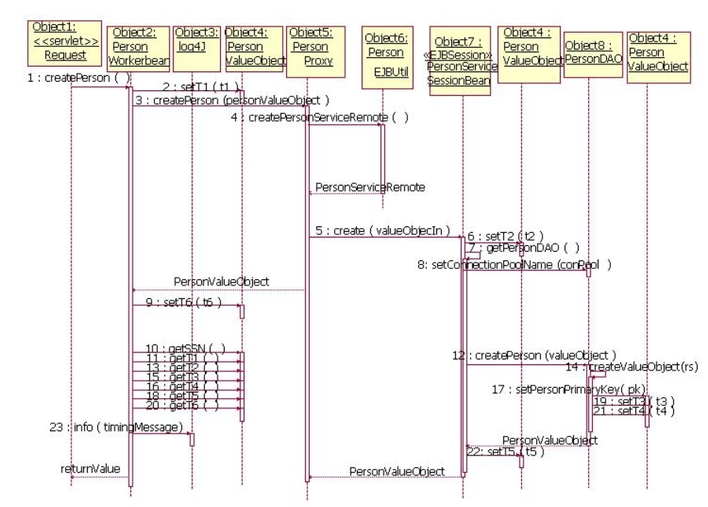
Figura
3 - diagramma UML sequence: fase di creazione del
PersonValue Object
(clicca sull'immagine per ingrandire)
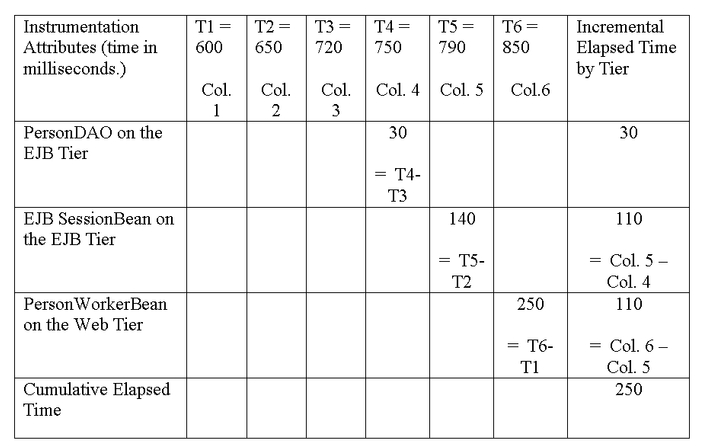
Una esecuzione corretta della applicazione dallo step
1 (createPerson) allo step 23 (PersonWorkerBean) produce
nel file Log4j una singola riga che può essere
trasformata nella seguente matrice. I tempi sono raccolti
in millisecondi. La tabella qui sotto è usata
per descrivere il tempo passato per i processi nel livello
applicazione, che generalmente è una decisione
arbitraria basata sulle specifiche. In effetti varie
combinazioni di stime di tempi possono essere realizzate,
se il programmatore/analista ha una comprensione avanzata
del contesto in cui la stima dei tempi è stata
catturata. Per esempio 250 rappresenta il tempo totale
consumato manipolando l'oggetto PersonValueObject dal
livello Web attraverso il resto dell'applicazione, mentre
invece la colonna Incremental Elapsed Time è
un tempo stimato per il processo attraverso i livelli.
Dettagli
dell'implementazione
Passo 1: Implementare il codice per gestire i
tempi nell'interfaccia IPersonValueObject per la classe
PersonValueObject (vedi figura 2).
Passo
2: Implementare il codice per la classe PersonValueObject
(vedi figura 2).
Passo
3: Implementare il codice per log4j.xml che setta
i livelli di priorità per il logging dell'applicazione
nel file framework_log4j.log. Log4j necessita un file
di configurazione per impostarne il funzionamento. È
possibile anche cambiare i livelli di log (DEBUG, INFO,
WARN, ecc) dinamicamente.
<?xml
version="1.0" encoding="UTF-8"?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration
debug="true">
<appender name="TEMP"
class="org.apache.log4j.FileAppender">
<param name="File" value="framework_log4j.log"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d
- %m%n"/>
</layout>
</appender>
<category name="proofofconcept">
<priority value="info"
<appender-ref ref="TEMP"/>
</category>
</log4j:configuration>
Passo
4: Implementare codice per PersonWorkerBean (vedi
figura 3). Il PersonWorkerBean scrive sul file framework_log4j.log
i tempi invocando il metodo statico log4j.info della
classe Log4j Logger. Le classi chiave in realtà
sono due: la classe PropertyConfigurator e la classe
Logger. Il metodo PropertyConfigurator.configure è
usato per dire dove si trova il file di configurazione.
La classe Logger si usa per settare i messaggi di log,
i livelli di log, e per identificare per quali classi
dell'applicazione si vuole effettuare il log degli errori.
Per estendere la classe Logger si consiglia di racchiuderla
con un'altra classe (wrapping) o di crearne un riferimento.
È invece sconsigliato estendere Logger col subclassing.
Log4j prevede la possibilità di settare dinamicamente
i livelli di log o di fornire i livelli tramite un file
di configurazione. Settando il livello ad "info"
tutti i messaggi di tipo "info" o superiori
verranno scritti sul file di log. Nel file di log dovrebbe
esserci un unico messaggio di livello info (tranne nel
caso che venga lanciata un'eccezione) che riporta le
stime dei tempi per tutti i livelli di middleware.
Passo
5: Implementare codice per il PersonServiceSessionBean
(vedi figura 3). Il metodo create dell'oggetto PersonSessionBean
riceve una copia serializzata del PersonValueObject,
setta le stime nel PersonValueObject e chiama createPerson
dell'oggetto PersonDAO. Nel modello l'oggetto DAO è
usato per ottenere una connessione al SeeBeyondEAI application
server, e quindi il PersonValueObject non è reso
persistente direttamente nel DBMS. Il punto è
che, nella maggior parte delle applicazioni J2EE, il
pattern Data Access Object è utilizzato per specificare
come rendere i dati persistenti nel DBMS.
Passo
6: Implementare codice per la classe PersonDAO (vedi
figura 3). Il metodo createPerson del PersonDAO invia
l'oggetto PersonValueObject all'application server SeeBeyond
utilizzando il protocollo sincrono MUX e*Way. Per questa
implementazione gli attributi di PersonValueObject sono
inviati come messaggi di testo perchè il server
SeeBeyond supporta solo questi ultimi. Il messaggio
di ritorno di SeeBeyond deve essere convertito a PersonValueObject
tramite uno StringTokenizer in quanto arriva sotto forma
di stringa. Il codice scritto assume che ci siano 3
token in questo formato: "Id^timestamp1^timestamp2".
Il codice Id è generato da SeeBeyond e rappresenta
la chiave primaria per l'oggetto PersonValueObject creato.
Il
server SeeBeyond provvede i "timestamp" per
l'integrazione con il CRM della PeopleSoft. SeeBeyond
restituisce anche la chiave primaria generata che può
essere necessaria per rendere persistenti i value object
associati come per esempio AddressValueObject. Questo
non si vede dal diagramma sequenza UML perché
il tema centrale qui è come raccogliere stime
di tempi da livelli disparati.
protected
IPersonValueObject createValueObject(
String rs )
{
IPersonValueObject valueObject = null;
try
{
valueObject = getPersonValueObject();
if ( valueObject == null ) // create one
{
valueObject = new PersonValueObject();
}
StringTokenizer st =
new StringTokenizer(rs, "^");
PersonPrimaryKey pk =
new PersonPrimaryKey(st.nextToken());
valueObject.setPrimaryKey( pk);
valueObject.setT3( Long.parseLong(st.nextToken()));
valueObject.setT4( Long.parseLong(st.nextToken()));
}
catch ( Exception exc )
{
printMessage("PersonDAO:createValueObject()-"
+
exc );
}
return( valueObject );
}
Implicazioni
architetturali
Idealmente
il miglior design dovrebbe permettere di passare un
oggetto ValueObject a tutti i livelli del middleware.
SeeBeyond per il livello EAI attualmente possiede un
supporto asincrono che utilizza messaggi di testo JMS
(java messaging service), ma non quelli di tipo JMS
ObjectMessage. La maggior parte degli implementatori
preferirebbero i messaggi di tipo ObjectMessage. Per
esempio, utilizzando un tipo JMS ObjectMessage, il PersonValueObject
non dovrebbe essere convertito in un oggetto String,
ma potrebbe essere inviato direttamente. Gli ObjectMessage,
che contengono oggetti Java serializzati, specificano
meglio al programmatore quali tipi di dati e di attributi
stanno ricevendo o spedendo. Col supporto per JMS ObjectMessage,
l'oggetto PersonEAI descritto in figura 4 avrebbe potuto
essere implementato in SeeBeyond, che avrebbe potuto
manipolare direttamente gli oggetti PersonValueObject.
Per iprogrammatori ad oggetti distribuiti questo è
tutto quello che serve: trasferire oggetti attraverso
la rete.
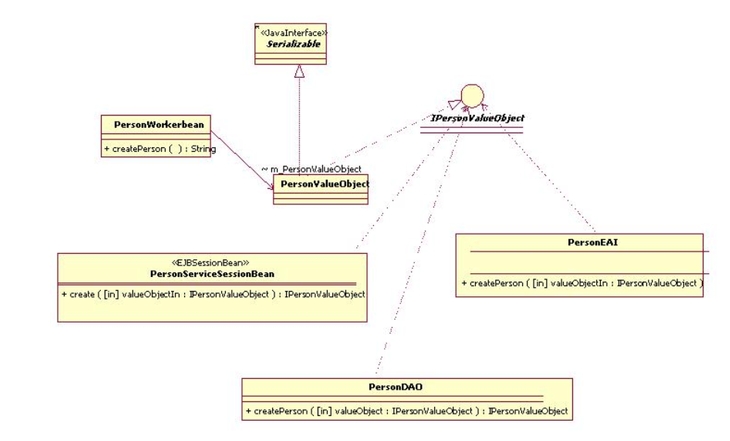
Figura
4 - diagramma UML con vista delle classi che partecipano
al
Sequence Diagram: fase di creazione del PersonValue
Object
(clicca sull'immagine per ingrandire)
A
proposito dell'autore
Frank
è un capo architetto specializzato in design
di applicazioni J2EE e implementatore di applicazioni
aziendali a tutto campo. Può essere raggiunto
a frank_teti@hotmail.com
L'articolo
è stato originariamente pubblicato su TheServerSide.com
|
