|
Tutti
i programmi interattivi forniscono due funzioni basilari:
ricevere l'input dell'utente e mostrare i conseguenti
risultati. Le web application implementano questo comportamento
usando due metodi HTTP che sono, rispettivamente, POST
e GET. Questo semplice protocollo va incontro a dei
problemi, però, quando l'applicazione restituisce
una pagina web in risposta a una richiesta POST. Le
peculiari caratteristiche del metodo POST, in combinazione
con le idiosincrasie dei diversi browser conducono spesso
a spiacevoli inconvenienti sperimentati dagli utenti
e possono produrre uno stato non corretto nell'applicazione
server. Questo articolo mostra come progettare una web
application che si comporta nel modo giusto attraverso
l'uso della redirezione.
Il
problema del doppio invio
I due metodi HTTP di request usati più frequentemente
sono GET e POST. GET recupera risorse da un server web,
le quali sono identificate dalla collocazione base ed
eventualmente da parametri di ricerca opzionali.. Generalmente,
i parametri della request GET vengono utilizzati per
restringere l'ambito dei risultati e non cambiano lo
stato del server. La medesima request GET può
essere inviata al server per tutte le volte che sia
ritenuto necessario.
Al contrario, i parametri presenti in una request di
tipo POST contengono in genere dei dati input che possono
modificare lo stato dell'applicazione sul server. Inviare
i medesimi dati per due volte consecutive può
produrre dei risultati non desiderati, come un doppio
prelievo da un conto corrente bancario o l'aggiunta
di uno stesso articolo per due volte nel carrello di
un sito di commercio elettronico. L'invio dei medesimi
dati per più di una sola volta in una request
POST è una situazione non desiderabile e prende
il nome di "problema del doppio invio".
Prendiamo il caso d'uso standard con un FORM HTML inviato
al server. I dati contenuti nel form vengono elaborati
e immagazzinati nel database e, successivamente, il
server invia una pagina di risposta contenente i risultati
dell'operazione.
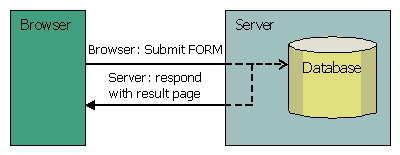
Figura 1
Nel
caso appena visto, la medesima request POST può
essere inviata nuovamente secondo una delle seguenti
tre possibilità:
-
ricaricare la pagina di risultati utilizzando la funzionalità
Refresh/Reload del browser (ricaricamento esplicito
della pagina, reinvio implicito della request);
- effettuare
un click sui bottoni Back/Indietro e poi su Forward/Avanti
del browser (ricaricamento implicito della pagina,
reinvio implicito della request);
- ritornare
nuovamente al FORM HTML dopo averlo inviato e premere
nuovamente il bottone di Invio sul form (reinvio esplicito
della request).
Proprio
in considerazione dell'importanza dei dati POST, i browser
mostrano un avviso quando una medesima request POST
sta per essere nuovamente inviata al server. Ma si tratta
di un messaggio troppo tecnico e poco comprensibile
per l'utente medio e, inoltre, alcuni browser non chiedono
affatto tale conferma. A causa di ciò, molti
siti web mostrano dei messaggi di avvertimento: quante
volte vi capita di vedere messaggi del tipo
"Per favore, non premere il bottone Back/indietro
e non ricaricare questa pagina!" quanfo effettuate
un pagamento online?
I messaggi di avvertimento e le finestre di dialogo
che chiedono conferma tendono però a rendere
l'interfaccia più disordinata e a innervosire
l'utente, non mettendolo a suo agio e facendolo preoccupare
per la paura di commettere costosi errori. Se un sito
web fa affidamento sugli avvertimenti prodotti dal browser
ma non controlla realmente il problema del doppio invio,
il database del server può essere sottoposto
a modifiche sbagliate, mentre l'utente perderà
fiducia nelle transazioni via Internet.
È possibile liberarsi di questi fastidiosi avvertimenti?
Sì. Il metodo di invio di FORM HTML può
essere cambiato da POST a GET. Ai browser non viene
rischiesto di proporre una finestra di conferma quando
viene reinviata una request GET, pertanto questo cambiamento
rende l'interfaccia utente più amichevole. Ma
questa "soluzione" infrange la semantica del
metodo GET: non impedisce un reinvio, ma si limita a
nascondere il problema all'utente.
Il
pattern PRG
La risposta al problema del doppio invio è la
redirezione. Si tratta di una tecnica nota, ma che non
è ancora diventata uno standard per i risultati
"successivi al POST". Per quanto ne so, non
ha un nome ben definito: proporrei allora di chiamare
questa tecnica "pattern PRG". dove l'acronimo
sta per POST - REDIRECT - GET.
Il pattern PRG suddivide una richiesta in due parti:
invece di restituire una pagina di risultato immediatamente
in risposta a una request POST, il server risponde con
una redirezione alla pagina risultante. Il browser,
quindi, caricherà la pagina di risultato come
se si trattasse di una risorsa separata. Dopo tutto,
sono due i compiti diversi che vanno svolti: primo un
POST dei dati di input al server, secondo, un GET dei
dati di output al cliente.
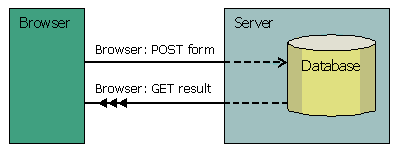
Figura 2
Questo approccio fornisce una soluzione pulita basata
sull'architettura Model-View-Controller. Tutti i dati
di input vengono salvati, in modo permanente o temporaneo,
nel Model sul server durante la prima fase. La seconda
fase carica una View che riflette lo stato corrente
del Model. Quando un utente prova a effettuare un aggiornamento
della pagina risultante, il browser provvede a reinviare
una request GET "vuota" al server: vuota perché
questa request non contiene alcun dato di input e quindi
non modifica lo stato del server. Si limita solamente
a ricaricare la vista precedente. Se lo stato del server
non è stato modificato da altri processi/utenti,
il server risponde con la medesima pagina inviata prima
dell'operazione di refresh.
Caricare le risorse utilizzando il metodo GET è
la pietra miliare dell'approccio suggerito in questo
articolo. La pagina caricata con una request GET può
essere aggiornata in maniera sicura e trasparente. Sicura
poiché non vengono inviati dati di input al server.
Trasparente perché il browser non mostra messaggi
di avvertimento. Il veicolo che rende possibile la transizione
da POST a GET è la redirezione.
Con questa tecnica, il feel dell'utente migliora in
maniera enorme. Niente più messaggi inquietanti
con avvertimenti di difficile interpretazione; niente
più brividi nel fare click sui pulsanti di Back/Indietro,
Forward/Avanti o Refresh/Aggiorna; nessuna paura di
fare danni sui dati del server. Il pulsante di Refresh/Aggiorna
ricarica la pagina con i risultati con una semplice
request GET. Il pulsante Back/Indietro riporta un utente
alla pagina con il form. Un click susseguente sul pulsante
Forward/Avanti ricarica la pagina di risultato usando
di nuovo una GET. Assoluta libertà di navigazione?
Un momento… Che cosa accade se si fa click sul
pulsante Submit/Invia del form dopo essere ritornati
alla pagina in cui è contenuto? Il form verrebbe
inviato nuovamente, no? E quindi a che servirebbero
tutti gli sforzi per la redirezione, se si limitano
solo i problemi derivanti da un'inavvertito aggiornamento
della pagina?
Mantenere
viva la vista
I browser non hanno sempre mantenuto in cache le pagine
web. Agli esordi di Internet, le cose erano molto semplici:
dato a un browser il medesimo indirizzo , il browser
recuperava sempre la stessa risorsa dal server, per
tutte le volte. I browser moderni sono più intelligenti:
sulla base di diversi fattori, tentano di determinare
se la pagina deve essere caricata ex novo dal server
oppure no. In caso negativo, recuperano la pagina da
una cache in cui era stata precedentemente salvata,
con un netto risparmio di traffico e tempo, molto importante
specie per le connessioni non a banda larga.
Ma la comodità del salvataggio in caching influenza
il comportamento standard. Ecco la domanda: che cosa
vedrebbe un utente se, dopo aver inviato un form, fa
click sul pulsante Back/Indietro del browser? Lo stesso
form appena inviato con i valori immessi? Perché?
Perché il browser ha salvato la pagina nella
cache nel caso potesse essere ancora necessaria?
Be', dimenticatevi browser intelligenti e cache delle
pagine: ciascuna finestra o pagina in una web application
interattiva è una View che rappresenta un Model
applicativo. Affinché la View sia corretta e
coerente con il Model deve essere rigenerata nuovamente
ogni volta che viene presentata all'utente.
In parole pover: il caching deve essere proibito nelle
web application. Libri, vocabolari, immagini online
possono essere salvati in cache. Ma per favore, caro
browser, non salvare istantanee di un programma "vivo",
poiché esse potrebbero non rappresentare più
lo stato corrente del Model. Va già male quando
una vista ormai superata viene visionata (meglio se
salvi le foto delle modelle nude…), ma è
dieci volte peggio quando una vista ormai scaduta viene
utilizzata per modificare il modello.
Vi faccio nuovamente la stessa domanda: che cosa vedrebbe
un utente se fa click sul pulsante Back/Indietro del
browser, dopo aver inviato un form? Già sapete
la risposta corretta: l'utente di una web application
ben progettata vedrebbe una vista che rappresenta lo
stato corrente del modello. Questa View sarebbe presentata
in una maniera tale da rendere impossibile il reinvio
dei dati già inviati precedentemente.
Un
nuovo trucco per il vecchio FORM
Guardiamo da vicino al caso d'uso standard con un FORM
HTML e una pagina di risultati. Il form può essere
utilizzato per modificare un'entità presente
nell'applicazione o per crearne una nuova. Dopo che
il modulo sarà stato inviato, i suoi dati saranno
immagazzinati nel database e i risultati dell'operazione
saranno mostrati come vista.
Secondo il pattern PRG, la pagina di risultato non deve
essere restituita come response a una request POST,
poiché un tentativo di ricaricarla causerebbe
i problemi connessi con il doppio invio. Al contrario,
il browser deve caricare la pagina di risultato separatamente,
usando il metodo GET.
Possiamo definire i seguenti moduli di elaborazione
(action, se vogliamo parlare in gergo Struts) per il
presente caso d'uso: Create Item (crea l'elemento),
Display Item (mostra l'elemento), Store Item (salva
l'elemento) e Display Stored (mostra l'elemento già
salvato).
Questi moduli vengono combinati in coppie input/output:
-
Create Item/Display Item - crea un nuovo elemento
vuoto, poi mostra il nuovo elemento usando il form
HTML Item Page HTML che permette di immettere i valori
dell'elemento;
- Store
Item/Display Stored - salva l'elemento, poi mostra
l'elemento salvato (reso persistente nel database)
in modalità solo lettura su una pagina Stored
Result;
- Store
Item/Display Item - se il salvataggio in persistenza
non va a buon fine, mostra un elemento non valido
insieme agli errori, usando lo stesso form HTML;
- Display
Item viene mostrata separatamente per visualizzare
e aggiornare un elemento già esistente nel
database.
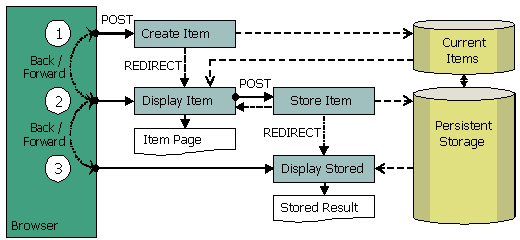
Figura 3 - Moduli di elaborazione: creazione e modifica.
1 - Create Item viene chiamato da un link, su qualche
altra pagina web, quando deve essere creato un nuovo
oggetto. Questa azione costruisce un oggetto vuoto dell'applicazione
e lo salva in un'area temporanea denominata Current
Items, la quale può essere salvata nel database
o nella sessione; successivamente avviene una redirezione
a Display Item.
2.1 - Display Item carica da Current Items l'oggetto
business costruito e lo mostra sulla Item Page, che
è il form HTML. Questo modulo può essere
aggiornato in ogni momento, tanto il browser si limiterà
a richiedere l'azione Display Item per ottenere e mostrare
di nuovo il business object.
2.2 - L'utente compila il form HTML con i valori dell'oggetto
e lo invia all'azione Store Item. Se l'oggetto non è
accettato, viene mantenuto nell'area Current Items,
il server effettua una redirezione all'azione Display
Item, la quale legge gli oggetti non validi insieme
con i messaggi di errore da Current Items e mostra nuovamente
il form. Se la Item Page deve essere aggiornata, carica
nuovamente lo stesso oggetto dalla Current Items.
3 - Se l'oggetto è accettato dall'azione Store
Item, viene resto persistente nel database e rimosso
dall'area temporanea. Dopo questo, il browser viene
rediretto a una azione Display Stored che mostra la
pagina Stored Result. Può mostrare l'oggetto
che è stato appena resa persistente. La pagina
di risultato può essere tranquillamente sottoposta
a refresh: caricherà nuovamente l'oggetto presente
nel database.
Se
un utente fa click sul bottone Back/Indietro della pagina
risultante (3) dopo che un nuovo oggetto sia stato creato
e salvato con successo, ritornerà all'azione
Display Item (2). L'oggetto temporaneo è già
stato rimosso dall'area temporanea. Display Item non
ha nulla da mostrare e mostrerà una pagina di
errore invece del form per immettere i dati dell'elemento,
notificando all'utente che l'oggetto non può
essere mostrato semplicemente perché non esiste
più. E in questo modo l'utente non potrà
reinviare nuovamente l'oggetto.
Una situazione simile dovrebbe verificarsi se, durante
la creazione di un nuovo oggetto, l'utente abbandona
la pagina con il form (2) per ritornare a una pagina
che la precede (1). Per l'applicazione ciò significa
che l'utente ha deciso di eliminare il nuovo oggetto.
Il nuovo oggetto viene rimosso da Current Items. Quando
l'utente fa click sul pulsante Forward e ritorna a Display
Item (2), vedrà un errore di tipo "Object
not found".
È possibile agire in maniera migliore, invece
di mostrare una pagina di errore quando un oggetto è
ormai stato rimosso dall'area temporanea. Create Item
genera degli ID di oggetto ed effettua una redireazione
a Display Item con l'ID dell'oggetto come parametro
di request. L'azione Display Item legge l'oggetto dalla
sessione e confronta il suo ID con quello passato come
argomento, poi mostra l'oggetto all'utente. Dopo che
l'utente ha immesso i valori dell'oggetto e li ha inviati
a Store Item, l'ID di oggetto diventa la chiave primaria
per tale oggetto.
Ora, quando l'utente ritorna indietro dalla pagina con
i risultati (3) dopo aver inviato un oggetto, il browser
invoca l'azione Display Item che passa ad esso la stessa
request, contenente l'ID di oggetto (2). L'oggetto è
stato rimosso dalla sessione, ma è stato salvato
nel database. L'azione Display Item legge l'oggetto
dal database, lo copia in Current Items e lo mostra
all'utente. A seconda delle regole dell'applicazione,
questo oggetto può essere reso di sola lettura,
in maniera tale che il form diventa una pagina semplice,
che mostra il contenuto dell'oggetto ma non permette
un suo nuovo invio. Oppure, al contrario, il form potrà
consentire modifiche e reinvio delle stesse. Nell'ultimo
caso, il titolo del form dovrebbe cambiare da "Crea
nuovo oggetto" a "Modifica oggetto esistente".
Se l'utente invia questo oggetto, non viene considerato
un caso di doppio invio. Si tratta di una modifica intenzionale
di un oggetto esistente.
La modifica di oggetti esistenti è facile: si
tratta di un caso già trattato, almeno nei suoi
aspetti basilari. Ci occorre solamente di assicurarsi
che Display Item non faccia differenza tra l'oggetto
nuovo e quello esistente. Display Item accetta l'ID
dell'oggetto come parametro di request, poi ricerca
il business object innanzitutto nei Current Items. Se
l'oggetto non viene trovato, esso viene ricercato nel
database, copiato in un'area temporanea e poi mostrato
(2). Dopo l'aggiornamento dell'oggetto e il suo invio,
esso viene salvato nel database. Quando l'untente fa
click sul pulsante Back/Indietro a partire dalla pagina
di risultato (3), la form dell'elemento ricarica nuovamente
l'oggetto dal database (2) in maniera che possa essere
modificato e reinviato ancora una volta. Si tratta di
un caso di doppio invio? No. Si tratta di una modifica
deliberata di uno stesso oggetto da parte di un utente.
Ovviamente, è possibile creare tutte le business
rule che si desiderano, anche quella che impedisce di
modificare un oggetto prima che sia trascorso un certo
tempo dalla sua creazione o ultima modifica.
Completiamo il caso d'uso analizzando le modalità
con cui l'oggetto viene eliminato.
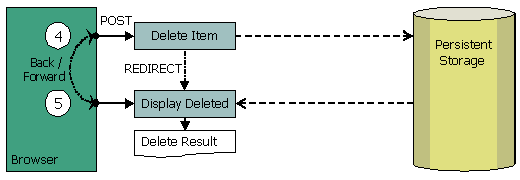
Figura 4 - Moduli di elaborazione: eliminazione.
L'eliminazione è semplice. Si prende l'ID come
parametro di request, lo si passa alla azione Delete
Item (4) che cancella l'elemento nel Model ed effettua
la redirezione alla pagina di risultato (5) la quale
verifica con il database che quel particolare oggetto
non esiste più. La pagina di risultato può
tranquillamente essere ricaricata senza produrre un'altra
richiesta di cancellazione e senza messaggi di avvertimento.
Quando viene utilizzato il pulsante Back/Indietro sulla
pagina di risultati (5), il browser ritorna alla pagina
che invoca la azione Delete Item (4). Se questa azione
è nuovamente chiamata con lo stesso ID di oggetto,
essa verrà applicata al Model, ottenendo un'eccezione
di "oggetto non trovato" e la corrispondente
pagina di errore. Anche qui, non si tratta di un caso
di doppio invio, ma di un tentativo esplicito di cancellare
nuovamente il medesismo oggetto… che tanto è
già stato cancellato.
Penso che l'idea generale sia chiara. Ma prendiamo un
altro esempio veloce: il negozio online.
Salvare alcuni articoli identici nel cestino non è
un problema fino a quando l'utente sta ancora facendo
le sue scelte. Basta mostrare il contenuto esatto del
cestino e la quantità di ciascun articolo. Quel
che davvero conta è di essere sicuri che il pagamento
venga elaborato esclusivamente una sola volta, secondo
lo schema seguente:
-
Viene creato un cestino della spesa a cui viene assegnato
un ID di cestino unico.
- Se
un utente fa click sul pulsante Back/Indietro dopo
aver aggiunto un elemento al cestino, il browser ricarica
dal server le informazioni aggiornate relative al
cestino mostrando all'utente che l'articolo è
ancora nel cestino. È l'utente che aggiunge
eventualmente un altro articolo identico.
- Quando
viene inviato il cestino, il suo contenuto sarà
"scaricato" su un sottosistema di acquisto;
a questo punto, il cestino viene invalidato, il suo
numero di transazione viene salvato in una tabella
con lo storico delle operazioni, se necessario, e
poi eliminato dal contesto dell'applicazione.
-
Quando un utente fa click sul pulsante Back/Indietro
dopo che l'acquisto è stato effettuato, il
browser cercherà di ricaricare il cestino ma
non ci riuscirà, poiché il cestino,
il suo ID e il suo contenuto sono già stati
distrutti. Il browser mostrerà un messaggio
di errore, invece del cestino: inviare due volte il
medesimo cestino è impossibile.
- In
caso di un browser o di un proxy che effettuano il
caching, un tente che ha fatto click sul pulsante
Back/Indietro vedrebbe lo stesso cestino che è
stato appena inviato al sottosistema di avquisto.
Il tentativo dell'utente di reinviare nuovamente il
cestino fallirà, poiché l'ID di individuazione
del cestino è già stato distrutto insieme
al cestino stesso. Un modo cortese con cui il server
può presentare tale situazione agli utenti
di browser che effettuano il caching è di mostrare
un errore che spieghi che il cestino già inviato
non esiste più.
Il
mantra
Il pattern PRG può essere riformulato come segue:
- Mai
mostrare pagine in response a POST
- Caricare
pagine usando sempre GET
- Muoversi
da POST a GET usando REDIRECT
- Ripetere
questi versi prima di andare a dormire.
- Pensare
in termini di risorse
Le
applicazioni di tipo desktop sono incentrate sulla presentazione.
Quando si seleziona una voce del menu, più o
meno si sa già che tipo di finestra sarà
mostrata e l'aspetto che avrà. A seconda dello
stato del Modello, potrà mostrare informazioni
diverse, ma l'aspetto generale della finestra sarà
lo stesso. Le interfacce utenti delle applicazioni locali
di tipo desktop sono relativamente statiche e in gran
parte vengono definite nella fase di sviluppo.
Le web application dovrebbero essere incentrate sulle
risorse. Possono puntare a una maggiore flessibilità
di presentazione, invece di sviluppare in modo fisso
una particolare pagina. I browser dovrebbero effettuare
la richiesta di una risorsa da un server, ovvero di
una entità dell'applicazione, non di una pagina.
A seconda della disponibilità e dello stato della
risorsa, il server genererà una presentazione
diversa per tale risorsa, che potrà essere una
pagina web "sola lettura", un form con controlli
per l'immissione di dati, o un messaggio per comunicare
che la risorsa non è disponibile o che è
stata rimossa in maniera permanente. Occore pensare
in termini di risorse, non di pagine.
Lavorare
con gli oggetti
Quando si ottengono dati in input, occorre pensare a
quali oggetti tali dati appartengono. Quando si mostrano
dati, occorre conoscere a quale oggetto appartiene il
contenuto mostrato. In ogni momento, si deve sapere
con quali oggetti si sta lavorando. Occorre usare gli
ID di oggetto per caricare, mostrare e salvare gli oggetti.
Passare gli ID di ogetto come parametri delle request.
È bene usare la sessione, o altri sistemi di
immagazzinamento lato server a breve termine, come buffer
per gli oggetti che in quel momento vengono modificati
o visualizzati. Assicurarsi che le proprie Viste rappresentino
sempre lo stato corrente del Modello.
Proteggere
il Model
Una pagina web è solamente un involucro per quello
che gli sta dietro: il Model, gli oggetti appartenenti
all'applicazione, il database. Quel che viene mostrato
a un utente è importante, ma ancor più
importante è quello che è salvato nel
Model. Proteggete il Model, consolidatelo, costruitegli
intorno tutti i possibili sistemi di gestione degli
errori. Dopo tutto, un'interfaccia utente inconsistente
è un fastidio rimediabile; il caos comincia quando
va all'aria il modello.
Accesso e aggiornamento del Model dovrebbero avvenire
secondo poche modalità ben definite. In generale,
il Modello non dovrebbe consentire aggiornamenti concorrenti
da parte del medesimo utente. Mantenere il Model valido
e aggiornato è la garanzia più sicura
per difendersi dalle incoerenze tra gli strati di presentazione
e quelli di elaborazione e dipersistenza.
Occorre definire regole di business/persistenza molto
chiare e non fare affidamento sullo strato web per validare
i dati in input. I dati possono provenire da qualsiasi
origine: da un utente di una pagina web, da un web service,
da un'applicazione di terze parti o anche dagli extraterrestri,
ma non si deve fare cieco affidamento su essi: i dati
in input vanno validati direttamente nel cuore dell'applicazione,
nel Model.
Evitare
i doppi invii
Includete l'ID dell'oggetto e i dati relativi al momento
della modifica (timestamp) nelle pagine con i form,
fornite il tempo di modifica per tutti gli oggetti business
nel model. Usate gli ID per effettuare la lookup del
business object nel meccanismo di salvataggio persistente
e anche i timestamp per riconoscere un doppio invio
effettuato da una pagina presente in cache.
È possibile prendere in considerazione l'applicabilità
dei token. Un token consente di individuare un doppio
invio a partire da una pagina scaduta contenente un
form. Il token viene salvato nella sessione prima che
il form venga inviato per la prima volta; lo stesso
valore del token viene inserito nel form http. Quando
il form viene inviato, con esso viene inviato anche
il valore del token. L'applicazione verifica che il
token sia presente nella sessione, accetta i dati in
input e rimuove quel token dalla sessione. Se un form
non più "vivo" viene inviato nuovamente,
il token del form non troverà più la sua
controparte nella sessione. I token possono essere usati
come soluzione puramente di strato web; Struts include
già il supporto per i token.
Il model può gestire i doppi invii in maniera
più affidabile rispetto ai token. Se un form
viene utilizzato per aggiungere o eliminare dati, meglio
applicare i valori di input direttamente al Model: se
è realizzato in maniera corretta, il modello
lancerà un'eccezione di inserimento o di cancellazione.
Se un form è usato per la modifica di oggetti
esistenti, è bene confrontare il timestamp del
form con quello del database, e non accettare input
con un timestamp precedente a quello dei dati già
resi persistenti.
Controllare i dati con il Model rende tutto più
semplice; è possibile notificare a un utente
che i dati appena reinviati sono già presenti
nel database: "Grazie. Per favore smetti di fare
click sul pulsante e di ricaricare la pagina. Il form
di input originario è già stato elaborato,
ma il tuo browser ancora lo mantiene nella cache".
Impedire il caching di pagine dell'applicazione, inserendo
<meta
HTTP-EQUIV="Pragma" content="no-cache">
e
<meta
HTTP-EQUIV="Expires" content="-1">
nelle
proprie pagine. Una pagina sarà considerata scaduta
appena caricata dal server.
Separare l'input dall'output
È meglio usare classi diverse per elaborare l'input
e l'output. Se si usa Struts, creare delle classi separate
per i form di input e output, il che funziona molto
bene con il pattern PRG a due fasi:
-
La request POST è ricevuta dal server;
- Struts
popola la classe del form di input con i parametri
della request;
- la
classe del form di input valida i dati immessi;
- il
Model viene aggiornato e le informazioni connesse
all'operazione corrente vengono salvate nella sessione
per l'uso con le request GET che seguiranno;
-
il browser viene rediretto all'action di output e
carica la pagina risultante utilizzando GET;
-
il server ricerca l'oggetto corrente nella sessione
e/o nel modello e riempie il form di output;
-
viene creata una vista a partire dai dati presenti
nel form di output e tale presentazione viene inviata
al browser.
Nel
form di input è possibile definire solo metodi
di impostazione (set), mentre nel form di output vengono
definiti solo metodi di recupero (get): ciò rende
le classi form più facili da leggere e assicura
che Struts non popolerà i campi del form di output
con parametri della request.
Sarà il caso di suddividere anche le grandi classi
di action in actiondi input e di output.
Usare oggetti dell'interfaccia utente in visibilità
di sessione
Il pattern PRG un percorso che riporta al browser, in
cui i dati della request vanno perduti. Esistono due
possibilità per conservare i dati inviati con
il POST: tasferirili su una response di redirezione
e poi in una request GET, oppure salvarli sul server.
Il primo approccio è pesante e non privo di inconvenienti
poiché ci si ritroverebbe con due tipi diversi
di request GET: una per mostrare nuovamente il form
HTML con tutti i suoi dati precedenti e un'altra per
mostrare l'oggetto applicativo proveniente dal database
che usa solo il suo ID.
Pertanto, il modo corretto risulta quello di salvare
dati temporanei sul server e fornire solo la request
GET con l'ID. In tal modo, l'azione di output non sarà
neanche a conoscenza del fatto se l'oggetto sia stato
appena creato o caricato a partire dal database.
I dati temporanei corrispondono all'oggetto che al momento
è modificato o visualizzato, e comprendono sia
i dati dello strato business che quelli dello strato
di presentazione, come:
-
valore dell'oggetto;
-
messaggi di errore inerenti il determinato oggetto;
- titolo
della pagina.
Dal
momento che questo oggetto temporaneo definisce la presentazione
di un oggetto business, lo denomino "oggetto UI"
(User Interface, "interfaccia utente"). Con
Struts, è possibile usare come oggetti UI le
classi di form in scope di sessione: si tratta del modo
più semplice per trasformare una normale applicazione
di "inoltro" in una di "redirezione"
one.
A quanto pare, la stessa classe di form sarebbe utilizzata
sia nelle azioni di input che in quelle di outpu, pertanto
l'action di output potrebbe accedere a valori impostati
nella fase di input. Il ricorso alle classi di form
in scope di sessione viene quindi inficiato dal fatto
che Struts effettua un ripopolamento dei campi del form
con ciascuna request. Ciò non è desiderabile,
pertanto gli operatori di modifica dovranno necessariamente
verificare il nome delle corrispondenze con l'azione
corrente e non dovranno aggiornare i valori dei campi
per l'azione di output. Struts invoca il metodo reset
prima di popolare il form e validate dopo questo. Se
tali metodi vengono usati sia in input che in output,
il nome della corrispondenza corrente dovrebbe essere
verificato, in maniera che possa essere utilizzato il
codice opportuno.
Le classi di form in scope di sessione vengono mantenute
in memoria durante la sessione del client, il che può
trasformarsi in un problema. Se la classe del nostro
form ha riferimenti a grandi oggetti, potrà essere
necessario rilasciare questi oggetti in maniera manuale.
Un altro problema sorge quando deve essere creata più
di un'istanza del form: come è possibile farlo
a partire dal codice dell'applicazione se le classi
di form vengono gestite da Struts?
Quindi, nonostante la sicura comodità di classi
di form in scope di sessione, suggerisco di creare i
propri oggetti UI. È possibile avere un migliore
controllo su di essi e decidere se vogliamo salvarli
nella sessione o nel database, con una conseguente maggiore
astrazione dal framework Struts e un più facile
porting verso altri framework.
Le classi di form sono pensate per due semplici obiettivi:
recapitare i dati input immessi in un form HTML e visualizzare
i dati output su una pagina web. Le classi form sono
solo oggetti di valori, migliorati grazie a funzionalità
aggiuntive quali la validazione. Meglio mantenerle in
scope di request e non usarle per salvare UI o dati
business.
Struts: usare la classe ForwardAction nelle azioni di
output
Se è stata effettuata la separazione tra classi
form di input e di output, ci si ritroverà con
due serie di metodi di reset e di validazione. Tali
metodi vengono invocati da Struts prima di passare il
controllo a una classe action. È possibile usare
i metodi validate nel form di input per il loro scopo
originario: verificare i dati di input. Il form di output,
dal canto suo, non ha molto da validare, visto che è
usato sostanzialmente per costruire la pagina di risultato.
Pertanto è possibilespostare il codice dal metodo
execute della classe action al metodo validate della
classe form di output e sbarazzarsi della classe dell'action
custom.
Struts:
non esporre le View
Le viste, che sono generalmente delle pagine JSP, non
devono essere disponibili per un acesso diretto dal
browser. Scordatevi del fatto che JSP può elaborare
la request e considerate le JSP come HTML con accesso
ai dati, da usare solamente per la presentazione dell'output.
Occorre sempre passare il controllo attraverso la classe
dell'action e/o del form. Ciò assicura una netta
separazione tra le diverse componenti e consente al
Controller di controllare tutte le request. Meglio nascondere
le pagine web nella directory WEB-INF e mostrarle solo
a partire dalle loro rispettive action.
Configurare la cache
Ai browser non viene richiesto di elaborare i tag di
controllo della cache presenti nelle pagine web, ma
obbediscono in genere ai campi degli header HTTP della
response. Aggiungete <controller nocache="true"/>
al file struts-config.xml: Struts modificherà
l'header di ciascuna response nel modo seguente:
response.setHeader("Pragma",
"No-cache");
response.setHeader("Cache-Control", "no-cache");
response.setDateHeader("Expires", 1);
I
corrispondenti campi dell'header http prodotti da Tomcat
4.0.6 hanno il seguente aspetto:
"Pragma:
No-cache"
"Cache-Control: no-cache"
"Expires: Thu, 01 Jan 1970 00:00:00 GMT"
Usare browser migliori
Nonostante gli sforzi per proibire il caching, alcuni
browser web come Firefox non ne tengono conto. Salvare
le pagine in cache funziona alla grande con le semplici
applicazioni di forward con cui impedisce i doppi invii
impliciti. Ma salvare nella cache una pagina che si
suppone rifletta lo stato corrente del server rovina
l'usabilità da parte dell'utente e introduce
nuovamente il problema del doppio invio.
Altri browser quali Opera possono reinviare request
POST senza presentare messaggi di conferma. Ciò
può invalidare lo stato dell'applicazione che
non effettua il controllo sul doppio invio, e un utente
non se ne accorgerebbe nemmeno.
Il vecchio Netscape Navigator funziona bene, secondo
me, ma per qualche ragione si blocca per alcuni secondi
quando sta inviando una request POST su un server Tomcat.
Altri browser non mostrano tale strano comportamento.
Internet Explorer si comporta nel modo giusto quasi
in tutto, ma è piuttosto fastidioso nei messaggi:
quando si renvia nuovamente una request POST, mostra
una finestra in cui comunica che la pagina è
scaduta e poi una finestra di dialogo che chiede se
si deve continuare. Nel caso si decida di non farlo,
la nostra attuale pagina va perduta. Ma, dal momento
che l'applicazione non soffrirà inconvenienti
da doppio invio, i nostri clienti non avranno problemi
se non questi fastidiosi messaggi.
Perché
funziona redirect
È interessante il fatto che il pattern PRG sfrutti
un comportamento non standard dei browser e dei server
web. L'HTTP 1.1 definisce svariati codici di redirezione
della response con i numeri 3xx. Alcuni di questi codici
richiedono che il browser usi lo stesso tipo di request,
altri richiedono di cambiare il POST in GET, altri ancora
richiedono di ottenere una conferma da parrte dell'utente.
Emerge però che molti di questi requisiti non
sono implementati da parte dei browser più diffusi,
i quali hanno invece dei comportamenti comuni ormai
acquisiti de facto, quali la redirezione del POST in
GET senza richiedere conferme nel caso venga ricevuto
un codice 302. Questa è la caratteristica sfruttata
dal pattern PRG.
Questo comportamente sarebbe sbagliato per il codice
302 ("Found") ma è assolutamente corretto
per il codice 303 ("See Other"). Eppure, pochissimi
server restituiscono un codice 303 quando sarebbe richiesta
una redirezione con il metodo GET. Il metodo HttpResponse.sendRedirect
non consente di impostare codici di response, ma restituisce
sempre il 302. È possibile emulare il comportamento
di sendRedirect(url) usando i seguenti metodi:
res.setStatus(res.SC_SEE_OTHER);
res.setHeader("Location",url);
dove
SC_SEE_OTHER è il corretto codice 303, ma sendRedirect
fornisce alcuni ulteriori servizi quali la risoluzione
degli indirizzi relativi, quindi non si tratta proprio
di una soluzione semplice e diretta. La discrepanza
tra il comportamento del browser e lo standard HTTP
può essere risolto se i codici 302 e 303 fossero
considerati come uguali, ma venisse anche creato un
nuovo codice per il comportamento standard 302.
In ogni caso, dubito che i produttori di browser cambieranno
l'implementazione del codice di response 302, poiché
troppe applicazioni fanno affidamento su di esso. L'aspetto
positivo è che i browser più moderni capiscono
ed elaborano correttamente il codice 303, pertanto,
se proprio si vuole stare al sicuro, è meglio
restituire il 303 invece che il 302.
Riferimenti
"GET after POST" di Adam Vandenberg:
http://theflangynews.editthispage.com/stories/storyReader$1118
"A
Fast Introduction to Basic Servlet Programming"
d Marty Hall:
http://www.informit.com/articles/article.asp?p=29817&seqNum=7
"Redirect
in response to POST transaction" di A.J.Flavell:
http://ppewww.ph.gla.ac.uk/~flavell/www/post-redirect.html
"Post/Redirect/Get
pattern for web applications" di Michael Jouravlev:
http://www.theserverside.com/patterns/thread.tss?thread_id=20936
"So,
You Don't Want To Cache, Huh?" d Joe Burns:
http://www.htmlgoodies.com/beyond/nocache.html
RFC
1945, Hypertext Transfer Protocol -- HTTP/1.0 di T.
Berners-Lee, R. Fielding, H. Frystyk:
http://www.ietf.org/rfc/rfc1945.txt
RFC
2616, Hypertext Transfer Protocol -- HTTP/1.1 di R.
Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter,
P. Leach, T. Berners-Lee:
http://www.w3.org/Protocols/rfc2616/rfc2616.html
L'autore
Michael Jouravlev è laureato in Informatica presso
l'università dell'Aeronautica di Mosca, Russia
e ha più di 10 anni di esperienza nello sviluppo
di applicazioni sulle piattaforme MS-DOS, Windows e
Java, e si è dedicato negli ultimi cinque anni
principalmente ad applicazioni lato server in Java.
Attualmente è impiegato come ingegnere del software
press la International Lottery and Totalizator, Inc.,
www.ilts.com
|
