 INTRODUZIONE INTRODUZIONE
Il
2 Febbraio 1995 Sun comunica la volontà di penetrare il mercato
dell'elettronica di consumo e dei sistemi emebedded con due serie di microprocessori
chiamati microJava e ultraJava. Il primo dei quali è destinato a
integrare il core picoJava messo a disposizione di chi volesse integrarlo
nei propri prodotti tramite una licenza d'uso.
La
specifica picoJava è rivolta a tutti coloro che operano nei
mercati dei Network Computer, PDA, telefonini intelligenti, elettrodomestici
di basso costo e basso consumo energetico.
Per
quanto concerne l'offerta Sun sono previste due serie di processori: microJava
e ultraJava.
I
processori microJava, basati sul core picoJava, integrano funzioni di comunicazione
e controllo. Si rivolgono ai mercati dei Network Computer, dispositivi
di basso costo per reti di computer, PDA, controllori, apparecchiature
per telecomunicazioni, giochi.
I
rocessori ultraJava sono rivolti ai mercati dei network computer, intrattenimento,
grafica tridimensionale ed applicazioni di trattamento delle immagini.
Per questi non è chiaro se verrà usato il core picoJava mentre
verrano integrate funzioni multimediali e la la tecnologia VIS (Visual
Instruction Set) già usata nei prodotti SPARC di Sun.
Questo
articolo descriverà la specifica picoJava dando notizia della prossima
uscita (nel tardo 1998) del processore microJava 701 che integra la seconda
versione della specifica a cui si fa pure cenno.
LA
MACCHINA VIRTUALE JAVA
Prima
di cominciare va tenuto conto che un javaChip integra la macchina virtuale
Java (Java Virtual Machine, in seguito JVM). Quindi è bene richiamare
alcuni concetti legati ad essa ed in particolare il modo di gestire le
chiamate ai metodi e le aree di memoria associate.
Ogni
thread ha un proprio registro chiamato Program Counter (PC) che contiene
l'indirizzo dell'istruzione che deve essere eseguita dalla JVM. All'avvio
della JVM viene attivato il thread di default. Il mutlithreading, può
essere realizzato in hardware con più processori tra i quali si
distribuisce l'esecuzioni dei thread attivi o con la divisione del tempo
(time slicing) su uno stesso processore.
Ogni
thread è eseguito prelevando dati da uno stack creato contemporaneamente
al thread in esecuzione. In esso, di volta in volta, vengono allocati i
frame legati ai metodi invocati. Ed ogni volta che i metodi terminano viene
liberato lo spazio occupato dai corrispondenti frame nello stack.
Tutti
i thread condividono la heap. Essa è la regione di memoria dove,
a runtime, vengono memorizzate le istanze degli oggetti e gli array. Essa
è creata all'avvio della JVM. Su di essa opera il Garbage Collector.
L'area
dei metodi (Method Area) fa parte della heap. E' analoga alla memoria del
codice compilato nei linguaggi tradizionali. Contiene oltre alla Constant
Pool (regione di memoria conentenente la costant_pool del file .class,
una sorta di tabella dei simboli contenete i riferimenti a tipi di dato
ed oggetti passati come parametri) dati relativi ai metodi e ai loro argomenti
ed il codice per i metodi e i contruttori.
I
frame sono usati per memorizzare dati e risultati parziali e per implementare
il linking dinamico, per restituire valori a metodi chiamanti oltre che
per sollevare eccezioni. I frame vengono allocati all'interno dello stack.
Un frame è creato all'invocazione di un metodo al quale è
legato. Ogni frame contiene il proprio insieme di variabili locali (quelle
del metodo corrente), ed il proprio stack degli operandi (operand stack).
Dallo stack degli operandi molte istruzioni acquisiscono i propri dati.
Contiene le variabili locali, i risultati parziali e gioca un ruolo fondamentale
nella chiamata dei metodi e nel ritorno ai metodi chiamanti. Lo stack è
implementato in hardware e chiamato tack cache unit costituito da 64 elementi
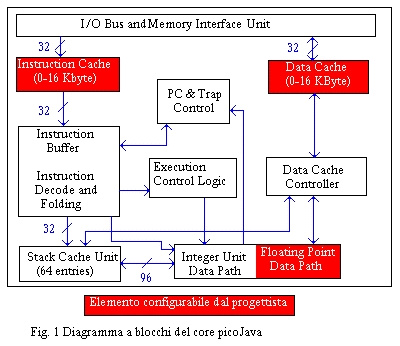
da 32 bit (vedi fig. 1).
LO
STACK E IL MECCANISMO DI DRIBBLING
Nello
Stack Cache Unit (in seguito, per brevità, Stack) vengono memorizzati
i dati relativi ai metodi correntemente in esecuzione e vengono prelevati
i dati di elaborazione. Principalmente viene usato come deposito di informazioni
per la chiamata ai metodi. Quando un metodo viene invocato si memorizzano
all'interno dello Stack il frame corrispondente, che diventa il frame corrente.
Il puntatore allo stack punta alla cima del frame appena creato.
Ad
esempio se durante l'esecuzione del metodo MetodoChiamante(), che occupa
lo stack sino al registro 34 (cima del frame), avviene una chiamata
ad un'altro metodo, sia MetodoChiamato(), allora a partire dal registro
35 il javaChip memorizzerà il frame legato a MetodoChiamato() ed
il puntatore allo stack si sposterà alla cima del frame corrente
(il frame di MetodoChiamato).
Se
il frame non trova sufficiente spazio nello stack, perché ha raggiunto
il sessantaquattresimo registro, interviene un meccanismo detto di Dribbling
in modo da evitare che si perdano le informazioni contenute nel frame di
MetodoChiamante(). Per realizzare il meccanismo di Dribbling si sfrutta
un'area di memoria detta Dribbler che può essere ritagliata dalla
cache dati, ad esempio.
Quando
si intercetta un overflow memory error il Dribbler sposta il contenuto
di una quantità di registri quanti ne servono al frame corrente
regisdtrandoli nel Dribbler. Quando, a conclusione dell'esecuzione del
metodo, il frame di MetodoChiamato() viene eliminato vengono prelevati
i dati dal dribbler riposizionandoli nel primo indirizzo di memoria libera.
Così che lo stack viene gestito dal dribbling come un buffer circolare,
assicurando la crescita e la contrazione dello stack in modo da evitare
overflow e perdita di dati. Oltre a questo meccanismo il dribbling si prende
la briga di riposizionare nello stack i frame dei metodi in anticipo rispetto
al loro uso.
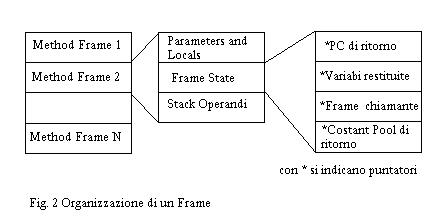
Lo
stack è progettato in modo che sia permessa la sovrapposizione di
metodi in modo da consentire un passaggio diretto dei parametri senza la
necessità di aggiuntive operazioni di copia dei parametri. I valori
dei parametri vengono spinti alla cima dello stack degli operandi (che
è pure la cima del frame) diventando parte delle variabili locali
del metodo chiamato (parte iniziale del frame). Si faccia riferimento alla
Fig.2.
Per
velocizzare l'esecuzione del codice picoJava I prevede una operazione di
ripiegamento (folding). In un'architettura a stack tradizionale gli operandi
sono recuperati dalla cima dello stack ed i risultati delle operazioni
su di essi vengono restituiti alla cima dello stack. Unica regione di accesso
ai dati. Questo impone che variabili non presenti alla cima dello stack
ma che debbono essere utilizzate vengono memorizzate in aree di memoria
per poi essere successivamente spostate alla cima dello stack.
Lo
stack picoJava evita queste operazioni con un accesso allo stack a singolo
ciclo . Spesso, un'istruzione che accede ai dati nella regione delle variabili
locali, sposta tali dati alla cima dello satck ed immediatamente opera
un operazione di calcolo. Il decoder intercetta tale operazione ed unisce
le due istruzioni in un singolo passo di esecuzione. Cosicche l'operazione
viene condotta a termine come una sola. Se la variabile locale non dovesse
essere presente nello stack l'operazione di ripiegamento non sarebbe possibile.
Sun afferma che tale operazione di folding elimina il 60% delle inefficienze
intrinseche all'architettura a stack.
LA
PIPELINE E IL GARBAGE COLLECTOR
Per
ottimizzare l'esecuzione del bytecode picoJava prevede un meccanismo di
pipeline a quattro stadi. La pipeline è una catena di montaggio
funzionale. Si progetta l'hardware a partire da unità fuzionali
per poi unirle con percorsi di segnale. Così quando l'istruzione
viene elaborata da uno stadio, viene passata al successivo e lo stadio
che si è appena liberato inizia l'elaborazione dell'istruzione successiva.
I
quattro stadi sono :
-FETCH, durante il quale il processore recupera una linea di 4 byte (dalla
instruction cache o dalla memoria principale) e la memorizzza nel buffer
delle istruzioni;
-DECODE, durante il quale vengono decodificate sino a due istruzioni per
volta e vengono attuate le operazioni di Instruction Folding (per la esecuzione
simultanea di più istruzioni);
-EXECUTE & CACHE, durante il quale viene eseguito il codice decodificato,
questa operazione può essere ripetuta per uno o più cicli;
-WRITE-BACK, durante il quale i risultati vengono restituiti allo stack
degli operandi.
Le
istruzioni di calcolo operano esclusivamente su dati prelevati dallo stack
cache unit e mai da dati prelevati dalla memoria. Questo aiuta nell'ottimizzazione
del percorso di pipeline. Altro elemento di ottimizzazione risiede nella
implementazione di specifici operazioni legate ai programmi OO all'interno
della pipeline. Per esempio l'invocazione dei metodi, la sincronizzazione
dei thread e la garbage collection. Per consentire quest'ultima è
stato necessario introdurre delle barriere alla scrittura (write barrier).
Esse sono costituite da bit associati ad ogni oggetto.
IL
CORE
Tutto
questo è integrato nel core picoJava I il cui aspetto è mostrato
in figura 1. L'architettura è semplice e consente al progettista
di circuiti embedded, il mercato di riferimento, di addattare il core alle
sue esigenze con tre elementi configurabili: la ALU (Arithmetic Logic Unit)
che può contenere o meno la FPU (Floating Point Unit), le le due
cache per le istruzioni e per i dati le cui dimensioni massime sono di
16Kbyte.
Le
istruzioni implementate in hardware sono solo quelle che direttamente contribuiscono
al migliorameneto del bytecode Java. Tra quelle non presenti sul silicio
quelle ritenute critiche per il funzionamento del sistema sono eseguite
attraverso microcodice o stati macchina mentre le poche rimanenti sono
intercettate ed emulate (PC & Trap Control). La maggior parte delle
istruzioni vengono eseguite in 2 o 3 cicli.
Il
buffer delle istruzioni (Instruction Buffer), di 12 byte, separa la cache
di istruzioni dall'unità di esecuzione. Può essere scritto
nel buffer una parola di 4 bytes alla volta, mentre può essere letta
una parola di 5 byte alla volta. Considerando una media di 1,8 byte come
lunghezza delle istruzioni eseguite, il processore può leggere più
di una istruzione per ogni ciclo.
La
stack cache unit (con 64 elementi analoghi a registri di 32 bit ciascuno)
contiene sia interi che floating point. Non c'è nessuna sovrapposizione
nelle operazioni di passaggio degli operandi tra le unità FPU e
IPU (Integer Processing Unit) e la stack Cache Unit.
Le
due cache e la pipeline comunicano tramite un datapath di 32 bit. Infine
per integrare il core con il resto del processore c'è l'apposito
bus di I/O e l'interfaccia di memoria.
PICOJAVA
2.0
Sta
per arrivare l'evoluzione 2.0 della specifica picoJava. Prevederà
una pipeline a 6 stadi ed un più esteso ricorso alla composizione
delle istruzioni (Instruction Folding). Questa composizione permetterà
di combinare sino a quattro istruzioni da eseguire in un solo ciclo di
clock, riducendo i tempi di esecuzione di qualsiasi codice.
PRODOTTI:
MICROJAVA 701
microJava
701 è il primo processore della serie microjava 701, la cui produzione
in volume è attesa per la seconda metà del 1998. Oltre a
implementare il core picoJava 2.0 supporterà l'esecuzione di codice
C/C++ per assicurare una migliore transizione tra codice C/C++ e codice
Java. Integra funzioni di di sistema, eliminando la necessità di
ASIC esterni. Tra queste funzionalità ci sono il controllore ed
il bus di I/O che sarà compatibile con lo standard PCI 2.1. Il bus
locale consentirà il collegamento con slave di I/O a basso costo
a 8/16/32 bit. Il controllore della memoria, anch'esso integrato nel 701
consentirà la scelta tra un interfaccia a 16 o 32 bit verso memorie
EDO DRAM o SDRAM.
Conterrà
sia una FPU (Floating Point Unit) sia una cache dati di 16KB che una cache
istruzioni di 16KB. Sarà prodotta in tecnologia CMOS da 0.25 micron
ed avrà una frequenza di 200 MHz.
Il
fatto che Sun lo consideri oltre che adatto agli scopi dichiarati per la
famiglia microJava anche per l'automazione industriale indica,se non altro,
la fiducia di Sun sulle prestazoni
in
tempo reale. Tanto più quanto che gli sforzi di adattare la piattaforma
Java al mercato dell'automazione induztriale sono ancora in fase di sperimentazione
(conivolgendo partener quali: Westinghouse PCD, Genentech, Lawrence Liermore
Laboratory, Intuitive Controls) arà integrata nei primi chip microJava
la cui produzione è prevista per la seconda metà del 1998.
PRODOTTI
PICOJAVA EMBEDDED
Ancora
una volta, il marketing cooperativo a spinto Sun a cercare partner strategici.
In questo modo vanno viste le firme di intenti tra Sun e diversi produttori
di sistemi e circuiti integrati tra i quali: Toshiba, LG Semicon, Mitsubishi,
NEC e Samsung, Rockwell Collins. Ad esempio Toshiba ha firmato una lettera
di intenti per lo sviluppo congiunto di microprocessori Java a basso consumo
rivolti al mercato del mobile computer. La LG Semicon ha stipulato un memorandum
per sviluppare un processore Java progettato per network computer internet-ready
di nuova generazione, per internet TV, set-top-box e chioschi elettronici.
Rokwell Collins ha stipulato un accordo di licenza e scambio tecnlogico
per lo sviluppo di core per processori Java per applicazioni a consumo
molto basso come: telefonini cellulari, dispositivi per GPS e per avionica.
Infine, Thomson Sun Interactive ha firmato una lettera di intenti per il
porting del Sistema Operativo OpenTV su microJava.
Bibliografia:
-
Java: the inside story
http://www.sun.com/sunworldonline/swol-07-1995/swol-07-java.html
- The
Unprecedented Opportunity for Java Systems
http://www.sun.com/sparc/whitepapers/wp96-043.html
- The
Visual Instruction Set (VIS): On Chip Support for New-media Processing
http://www.sun.com/sparc/whitepapers/wp95-022/
- Javachip
http://www.sun.com/sparc/java
- Sun
Gambles on Java Chips by Peter Wayner Byte Volume 21, number 11.
- The
Java Virtual Machine Specification.
http://java.sun.com/docs/books/vmspec
- Patrick
Naughton "The Long Strange Trip to Java" in "The Java Handbook".
|


