|
MokaByte Numero 14 - Dicembre 1997 |
|||
|
|
|
REQUEST
|
|
|
|
di |
Un supporto per la riformulazione delle interrogazioni su Web | |
|
MokaByte Numero 14 - Dicembre 1997 |
|||
|
|
|
REQUEST
|
|
|
|
di |
Un supporto per la riformulazione delle interrogazioni su Web | |
![]() Premessa.
Premessa.
Internet
scoppia di informazioni, ma non sempre è facile trovarle.
Quando non sappiamo dove trovare un sito, un documento,
un'informazione che ci interessa, siamo costretti a rivolgerci ai cosiddetti
"motori di ricerca" (Altavista, Yahoo, Excite, Lycos, tanto per citarne
alcuni) a cui sottoponiamo un'interrogazione (query); tali sistemi ci rispondono
in generale con una lista più o meno lunga di link a documenti remoti
desunta dal loro archivio. Senza il loro aiuto esplorare la rete sarebbe
come cercare un'informazione in una libreria dove i libri sono messi alla
rinfusa e dove il catalogo è scomparso.
I
risultati sono però spesso scoraggianti: non si trova ciò
che si desidera e ci si imbatte invece in una quantità enorme di
informazioni irrilevanti, il cui esame è un processo lungo e dispendioso
e il più delle volte costringe l'utente a cambiare strada o ad abbandonare
gli scopi che si volevano perseguire.
Pertanto,
anche se l'utilità di questi sistemi è fuori discussione,
ci dovremmo domandare quanto tempo si passa ad interrogarli, ad esaminare
i risultati e quante volte si è costretti a riformulare l'interrogazione
perché i documenti ritornati non rispondono alle nostre esigenze,
non sono centrati sul problema.
Mentre
molti sforzi commerciali e di ricerca si sono focalizzati sui sistemi di
recupero, indicizzazione ed ordinamento dei documenti, relativamente poco
è stato fatto nell'aiutare l'utente nel processo di riformulazione
dell'interrogazione.
Ci
sono almeno due aspetti primari che sono coinvolti nella riformulazione
interattiva dell'interrogazione. Il primo è una migliore comprensione
di come le parole chiave hanno influenzato i risultati ottenuti, in quanto
la logica, che esiste dietro al meccanismo di scelta dei documenti da ritornare
da parte del motore, è in gran parte oscura all'utente. Il secondo
aspetto, non meno importante, è la scelta di nuovi termini chiave
per espandere la query. In quest'ultimo caso l'approccio tradizionale è
quello dell'uso di thesauri (insiemi di parole di significato simile);
un approccio che invece sta prendendo consistenza è quello di esaminare
i documenti ritrovati cercando nel loro contenuto parole simili ai termini
iniziali della query.
Il
sistema REQUEST (REformulating QUEries by Substituting Terms) cerca di
dare una risposta a questi problemi, REQUEST è un sistema di recupero
da archivi Web che fornisce all'utente un supporto user-friendly per capire
a fondo gli effetti delle parole chiave sui risultati ottenuti e per espandere
l'interrogazione con nuovi termini.
![]() Lo
schema funzionale.
Lo
schema funzionale.
La
prima richiesta che ci siamo posti nell'affrontare il problema è
di avere un'interfaccia unica per presentare all'utente tutte le informazioni
utili in una sola schermata (grafico, lista dei documenti e lista di parole
simili).
Analizziamo ora a grandi linee il funzionamento del sistema:
Durante la riformulazione o in attesa della risposta del motore di ricerca, l'utente può eventualmente recuperare e visualizzare i documenti referenziati. La figura 1 illustra l'architettura ed il funzionamento del sistema.
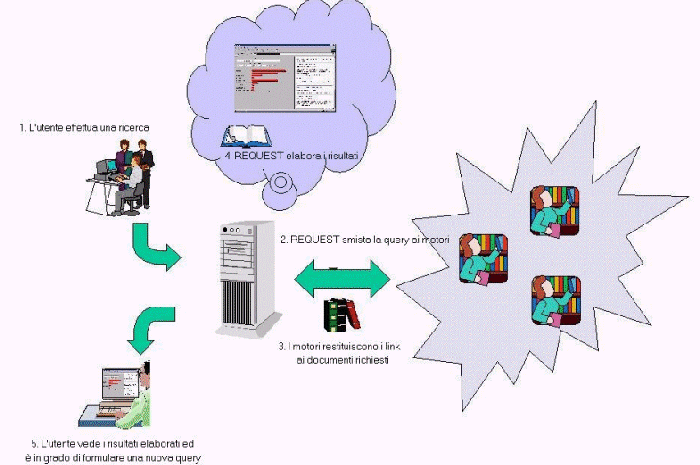
Figura
1: Schema funzionale di REQUEST.
![]() Visualizzazione
dei risultati.
Visualizzazione
dei risultati.
Dato
un insieme di termini che formano la query base, REQUEST considera tutte
le possibili subquery (termini singoli o combinazioni di termini) che possono
essere generate da questi e calcola la distribuzione di ciascuna subquery
nei documenti ottenuti in risposta alla query base. REQUEST visualizza
la distribuzione complessiva mediante una rappresentazione a stella, in
cui ciascun raggio corrisponde ad una subquery ed ha una lunghezza proporzionale
al numero di documenti in cui è presente la subquery (figura 2).
Le subquery possono essere ordinate per cardinalità o frequenza.
Questo tipo di visualizzazione è quello utilizzato nell'analisi
dei cluster per problemi di piccole dimensioni.
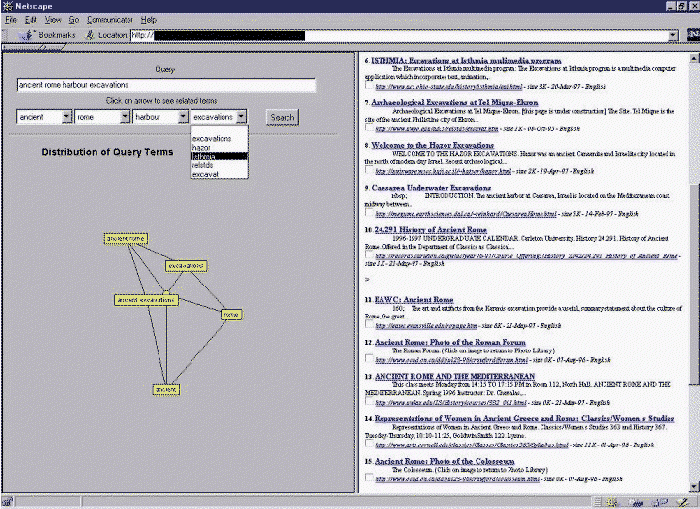
Figura 2: La risposta di REQUEST ad una interrogazione.
Sono possibili anche altre rappresentazioni come quella classica ad istogrammi (figura 3).
La
semplice pressione nella zona in cui è presente una subquery comporta
la visualizzazione dei soli documenti comprendenti questi termini. Le parole
chiave vengono colorate in modo da evidenziare possibili vicinanze tra
termini; questa è una delle caratteristiche implicite su cui si
basano i motori di ricerca nel calcolare il ranking dei documenti.
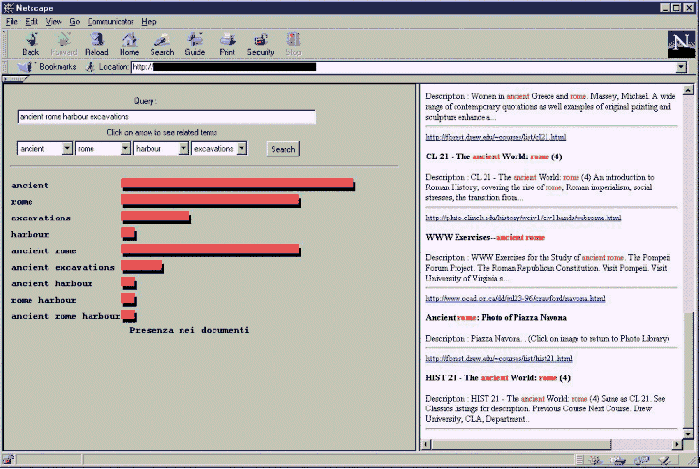
Figura
3: Rappresentazione ad istogrammi di una interrogazione
![]() Espansione
della query.
Espansione
della query.
Per ciascun termine della query, REQUEST presenta un insieme di termini simili trovati analizzando i risultati ottenuti. Seguendo i concetti dell' Information Retrieval, due termini sono tanto più simili quanto sono più presenti negli stessi documenti, così come due documenti sono detti simili quando contengono gli stessi termini. Questa è l'idea di base che viene impiegata per calcolare i coefficienti di similarità tra termini presenti nei documenti e quelli delle query. I termini di uso comune (pronomi, articoli, etc. ) vengono scartati attraverso l'uso di una stop list che viene aggiornata periodicamente dal server.
L'espansione
della query comporta diversi vantaggi, oltre a quello di fornire una serie
di termini con cui raffinare l'interrogazione; ad esempio, da una analisi
dei termini presentati, l'utente può accorgersi che nei documenti
ritornati è presente un termine con un significato diverso da quello
che aveva spinto l'utente ad inserirlo nelle parole chiave. Associare ogni
singolo termine della query ad una lista costituisce una delle differenze
fondamentali di REQUEST da Live Topics di AltaVista in cui vengono suggerite
query simili a quella di base ma senza che vi sia la possibilità
di espandere i singoli termini della query.
![]() L'implementazione.
L'implementazione.
Tecnicamente per la parte grafica si è preso spunto dagli esempi forniti da SUN con i vari JDK, ma si è stati molto attenti allo sviluppo di interfacce tra i vari oggetti in modo da poter agevolmente variare le rappresentazioni in un futuro anche seguendo i gusti dell'utente.
Da questa esperienza si possono offrire alcuni utili consigli pratici:
import java.net.*;
import java.io.*;
class FMultiServer {
public static void main(String[] args) {
ServerSocket serverSocket = null;
boolean listening = true;
try {
serverSocket = new ServerSocket(); catch (IOException e) {
}
System.err.println("Could not listen on port: "" ++ ", "" + e.getMessage());
System.exit(1);
}
while (listening) {
Socket clientSocket = null;
try {
clientSocket = serverSocket.accept();
} catch (IOException e) {
System.err.println("Accept failed: "" ++ ", "" + e.getMessage());
continue;
}
new FMultiServerThread(clientSocket).start();
}
try {
serverSocket.close();
} catch (IOException e) {
System.err.println("Could not close server socket." + e.getMessage());
}
}
}
HtmlSearcher invia la query ai motori di ricerca e struttura le risposte in uno standard predefinito (link per il recupero del documento, un titolo ed un abstract del contenuto)
Normalmente i motori di ricerca utilizzano per l'interazione con l'utente, a fini della comunicazione dei termini dell'interrogazione tra utente e motore stesso, una form CGI scritta in Perl o C. Il metodo per processare le richieste (GET o POST) determina la maniera nella quale i dati contenuti nella form sono inviati al programma CGI.
Se è usato il metodo GET, la stringa della query è attaccata all'URL del CGI e può essere acceduta attraverso la variabile d'ambiente QUERY_STRING. Nel caso del metodo POST, i dati sono passati mediante lo standard input. E' responsabilità del programma CGI l'analisi sintattica della form, il recupero del metodo (GET o POST), la corretta ricezione dei dati e la necessaria elaborazione.
Nel caso del metodo GET, ad es., il codice qui riportato rappresenta un esempio della estrema versatilità della classe URL delle JDK di Java.
E' presente una classe HtmlConf che gestisce il passaggio dei file di configurazione tra client e server (tag html e stop list).public class HtmlSearcher {
static String intesta = new String("http://./cgi-bin/esearch.pl?");
//esearch.pl un perl-cgi program di smistamento e controllo del tutto simile ai classici programmi CGI dei motori di ricerca
public String query = new String();
//Document una classe proprietaria che include URL, titolo e descrizione
public Document[] listaref = new Document[maxdoc];
public int nrdoc = 0;
String[] keyquery;
.
// ritorna la stringa contenente tutta la pagina
public String Create(String[] args) {
try {
keyquery = args;
// costruisci interrogazione
String pagefound = new String();
String stringToSend = new String();
String stringtemp = new String();
int j = 0;
while (j < args.length && args[j] != null && args[j] != "") {
stringtemp = URLEncoder.encode(args[j]);
if (stringtemp != null && stringtemp != "")
stringToSend = stringToSend + "+" + stringtemp;
j++;
}
query = intesta + "query=" + stringToSend.substring(1) + "";
URL url = new URL(query);
URLConnection connection = url.openConnection();
DataInputStream inStream = new DataInputStream(connection.getInputStream());
String inputLine;
boolean continua = true;
// salva pagina recuperata nella variabile pagefound
while (((inputLine = inStream.readLine()) != null) && continua) {
String testo = new String();
// elaborazione del testo recuperato
testo = Parsing(inputLine);
pagefound += testo + "";
//stop ad es. al 200esimo doc. recuperato
if (nrdoc >= 200)
continua = false;
}
inStream.close();
return (pagefound);
} catch (UnknownHostException e) {
return("Don't know about host: .");
} catch (IOException e) {
return("Couldn't get I/O for the connection to . : "" + e.toString() );
}catch (Exception e) {
return("Generic Error :" + e.toString());
}
}
.
| Ezio Berenci e' un ricercatore del gruppo "Sistemi Informativi" della Fondazione Ugo Bordoni di Roma. Ha conseguito la laurea in Ingegneria Elettronica presso l'Universita' di Roma "La Sapienza" nel 1994. Dal 1995 al 1997 ha lavorato nella Divisione Sanità della Bull HN come analista e sistemista. Ha ricoperto il ruolo di responsabile allo sviluppo client/server nell'ambito di applicazioni orientate ad ospedali e A.S.L. (Sistema informativo integrato radiologico, CUP, refertazione assistita, ..) per poi concentrarsi verso le soluzioni intranet nell'ambito di progetti di cartelle cliniche multidimensionali per ditte farmaceutiche. Attualmente e' coinvolto nello studio di interfacce grafiche e di sistemi per il recupero di informazioni multimediali. |
|
|
||
|
|
||
|
|
MokaByte
rivista web su Java |
 |
|
|
||

