|
MokaByte
Numero 16 - Febbraio 1998
|
|||
|
|
Java e CORBA? |
|
|
|
Ennio Grasso |
|||
|
MokaByte
Numero 16 - Febbraio 1998
|
|||
|
|
Java e CORBA? |
|
|
|
Ennio Grasso |
|||
Executive Summary
Che relazione tra Java e CORBA?
Ritengo che esistano due risposte possibili a questa domanda.
La prima risposta possiamo definirla "collaborativa" e parte dall'osservazione che mentre Java è un linguaggio di programmazione, CORBA è un'architettura di distributed computing. Quindi, secondo la visione "collaborativa" Java e CORBA possono complementarsi a vicenda: usare Java per implementare un ORB (Object Request Broker) CORBA, così come attualmente si usa C, C++ e Smalltalk. In effetti esistono diverse proposte che adottano la visione "collaborativa", quali JIDL Visibroker, e OrbixWeb. Con il recente annuncio di Netscape, la prossima versione del browser Navigator supporterà in modo nativo un ORB CORBA scritto in Java permettendo al browser di agire da client di servers CORBA in rete.
La seconda risposta alla domanda può essere definita "competitiva" e parte dal presupposto che Java è nato come linguaggio di programmazione ma si sta espandendo in molte direzioni trasformando Java "il linguaggio" in Java "l'architettura". Una delle aree che Java "l'architettura" sta esplorando è quella del distributed processing. Secondo questa visione Java ha la forza di imporre un proprio standard di distributed processing alternativo a CORBA. Perché competere con CORBA invece di collaborare? La visione "competitiva" parte dall'osservazione che CORBA soffre di una serie di problemi quali complessità d'uso, mancanza di servizi, problemi di portabilità, e altri problemi evidenziati nel seguito della nota. In particolare, la complessità d'uso di CORBA deriva dal fatto che si opera in ambiente eterogeneo dovendo accomodare diversi linguaggi di programmazione, sistemi operativi e piattaforme hardware. Se il mondo fosse omogeneo le cose sarebbero molto più semplici. Detto in atri termini, se tutti "parlassero" Java sarebbe possibile un modello di distributed computing veramente facile da usare e in grado di sfruttare le caratteristiche intrinseche di Java, come la migrazione del codice e il loading dinamico delle classi.
In questa nota intendo esplorare gli aspetti sopra accennati. CORBA come architettura di distributed computing rappresenta uno standard consolidato. Ma mentre lo standard è maturo i prodotti commerciali che lo implementano soffrono di alcuni problemi. D'altro canto la tecnologia Java sta subendo un'evoluzione che nessuno poteva prevedere solo un anno fa. Dopo una panoramica sulle caratteristiche che distinguono Java da altri linguaggi, mi soffermo per chiarire il fatto che Java applica il paradigma di mobile code e non quello di distributed computing, prerogativa invece di CORBA. Ora però le cose stanno cambiando. Java RMI estende Java e si propone come alternativa a CORBA (visione "competitiva"). JIDL propone Java per realizzare un ORB CORBA. Meglio la visione "competitiva" o quella "collaborativa"? Difficile rispondere. Il problema è che stiamo fotografando una situazione in corso di evoluzione per cui è difficile anticipare cosa potrà succedere domani.
In questa nota non ho l'ambizione di rispondere in modo definitivo alla domanda: meglio "competitiva" o "collaborativa". Non credo nemmeno che nessuno sia in grado di farlo. L'obiettivo è di stimolare il lettore proponendo alcune osservazioni, descrivendo gli elementi tecnici più interessanti delle proposte oggi disponibili e lasciando a ciascuno di elaborare una propria opinione sull'argomento.
Introduzione
L'abbinamento distributed computing da un lato e object oriented modelling dell'altro ha ormai raggiunto unanime consenso. Non a caso i modelli architetturali di distributed processing (standard o proprietari) si ispirano tutti a paradigmi object oriented.
In una precedente nota [FBO] ho descritto la differenza sostanziale che esiste tra architetture distribuite a oggetti e linguaggi di programmazione object oriented. Mentre nell'OOP (Object Oriented Programming) gli oggetti hanno significato solo all'interno del programma che li definisce, nelle architetture distribuite gli oggetti diventano componenti "visibili" al di fuori dell'applicazione. Nella stessa nota ho cercato di descrivere quale sia la filosofia alla base del componentware, ossia componenti plug & play che possono essere assemblate tra loro, scoprire dinamicamente l'esistenza le una delle altre e i possibili modi di cooperazione. Questo ulteriore livello di "intelligenza" di componenti plug & play richiede l'introduzione di architetture sofisticate basate su modelli a frameworks che, come dice la parola, costituiscono ambienti di lavoro per le componenti che fissano le regole di interazione, di comportamento e di cooperazione semantica tali da permettere il plug & play. Il concetto di framework, così come quello di Business Object, sono attualmente buzz words ricorrenti che rivestono un'importanza non trascurabile nel panorama del distributed processing perché introducono nuove filosofie di organizzazione del software.
"Standard" è importante
Potremmo dilungarci a parlare delle architetture distribuite a oggetti e della loro più moderna evoluzione verso modelli a componenti plug & play nonché della loro utilità per coloro che sviluppano, acquistano, e soprattutto mantengono il software. In realtà nessun modello concettuale è utile o fattibile se non confortato da una realizzazione reale che lo istanzia e ne dimostri non solo la fattibilità (seppur necessaria), ma soprattutto l'utilità. Eccoci allora a discutere dell'argomento di standard architetturali. Già perché condizione necessaria affinché un'architettura distribuita a oggetti possa servire è il fatto di essere basata su uno standard o, detto altrimenti, che costituisca essa stessa uno standard. Infatti, un'architettura introduce un insieme di concetti generali descrittivi e un insieme di regole di strutturazione e interazione (interfacce e protocolli) per permettere alle componenti distribuite di comunicare tra loro. Affinché un'architettura sia veramente utile è necessario che si diffonda in modo pervasivo, significando che sono disponibili implementazioni dell'architettura:
- per diverse piattaforme hardware;
- per diverse piattaforme software (sistemi operativi);
- da diversi vendors;
Non è comunque vero che tutti i criteri sopra indicati siano sempre soddisfatti. In alcuni casi non vale nessuno di questi principi e tuttavia è possibile parlare di architettura standard. Un esempio? Microsoft!
Con l'architettura di compound document OLE (Object Linking & Embedding) e il modello a componenti ActiveX, Microsoft ha effettivamente definito uno standard de facto avendo ormai in mano il mercato desktop. Ma resta pur sempre uno standard proprietario (solo Microsoft), disponibile solo per piattaforme Intel e comunque il sistema operativo è Windows. Se alcuni ritengono che sarebbe auspicabile avere un unico vendor con il monopolio del mercato in modo da eliminare completamente problemi di interoperabilità e portabilità del software, personalmente non oso pensare cosa accadrebbe se un simile scenario diventasse realtà. Il monopolio non solo è un deterrente all'innovazione, ma comporta il non trascurabile inconveniente per chi acquista il software di soggiogare alle regole dettate da chi vende: "se non ti va bene così com'è e a questo prezzo arrangiati". Ecco perché ritengo che chi acquista il software dovrebbe cercare di premiare i vendors che tendono ad aderire ad uno standard generale, invece di piegarsi alle più lusinghiere offerte di soluzioni proprietarie. Quanto detto mi è servito per introdurre lo standard CORBA.
CORBA: la soluzione?
Se da un lato Microsoft rappresenta la soluzione proprietaria per le architetture distribuite a oggetti, CORBA ne costituisce l'antagonista più rappresentativo. CORBA (Common Object Request Broker Architecture) è un'architettura standard definita dal consorzio OMG (Object Management Group) che comprende quasi 700 membri tra cui IBM, HP, Digital, Sun, Oracle, Netscape, ecc. Pensate a un software vendor che in qualche modo fornisca soluzioni nel campo dell'object technology e vedrete che le probabilità che questi sia membro OMG sono molto alte. Non è questa la sede per descrivere l'architettura CORBA. Ricordiamo solo che l'architettura CORBA definisce un linguaggio dichiarativo IDL (Interface Definition Language) per la descrizione delle interfacce degli oggetti e il "bus" di comunicazione, l'ORB (Object Request Broker), che realizza la trasparenza della distribuzione, localizzazione e attivazione degli oggetti. Nell'architettura CORBA gli oggetti sono in grado di comunicare tra loro senza essere a conoscenza della loro ubicazione reciproca: è l'ORB che dinamicamente è in grado di localizzare gli oggetti distribuiti, di attivare la loro implementazione e di permettere la comunicazione astraendo da protocolli di trasporto, differenze hardware e di linguaggi di programmazione.
CORBA non è un prodotto. CORBA è uno standard architetturale. Chiunque può implementare le specifiche e offrire un prodotto commerciale. Attualmente esistono almeno una dozzina di prodotti CORBA, tra cui quelli di IBM, Sun, HP, Digital, IONA, Expersoft, ICL, Visigenic, ecc. L'aderenza allo standard CORBA risolve i problemi menzionati sopra, ossia disponibilità di prodotti da parte di vendors diversi, ciascuno disponibile su più piattaforme hardware e software. Non solo. Le specifiche CORBA 2.0 definiscono il protocollo di comunicazione usato dall'ORB permettendo a prodotti di vendors diversi di interoperare tra loro in modo trasparente alle applicazioni.
Per coloro che tipicamente sono diffidenti verso i consorzi di standardizzazione dico che anche io mi ritengo tale. Solo che OMG adotta un principio di standardizzazione diverso dal solito. Affinché una certa soluzione possa essere standardizzata occorre dimostrare che la soluzione proposta sia fattibile esibendone un'implementazione funzionante. Questo approccio si discosta notevolmente dalla classica procedura top down in cui chi definisce le specifiche non ha la più pallida idea di quali siano i problemi della loro realizzazione: "tanto è solo un problema implementativo" è la frase ricorrente. Adottare specifiche già implementate se non altro risolve i problemi di fattibilità delle stesse.
È quindi CORBA la soluzione ai problemi di distributed computing? Apparentemente sì: è uno standard pervasivo (ad eccezione di Microsoft), permette la strutturazione del software in componenti, realizza la trasparenza della distribuzione. Seguo l'evoluzione dello standard CORBA da almeno tre anni e devo ammettere che recentemente c'è stata un'esplosione del fenomeno. Sembra che CORBA sia in al momento. Me ne rallegro. Sono sempre stato un sostenitore di CORBA, anche perché appartengo alla schiera di coloro che vede il monopolio Microsoft una calamità non naturale. Tuttavia Ebbene, tuttavia recentemente mi sono sorti alcuni dubbi. Proprio ora che CORBA sta riscuotendo considerevole consenso avanzo dei dubbi? Non dico che CORBA non sia la soluzione da tutti auspicata, solo che non ne sono più sicuro come un tempo. Quali dubbi? Ecco alcuni esempi:
Java: hype o realtà?
Cosa c'entra Java con CORBA e più in generale con le architetture distribuite a oggetti? Per alcuni Java è solo un linguaggio per animare le pagine HTML della Web e nulla più. Per altri Java può essere considerato un linguaggio general purpose per costruire applicazioni grafiche à la Visual Basic per così dire: si usa Java per creare l'interfaccia grafica e il codice di "colla" che richiama le altre applicazioni, così come avviene in generale nei linguaggi di script interpretati. Infine, per altri ancora, e tra questi il sottoscritto, Java ha incominciato come linguaggio per la Web, è evoluto in un linguaggio general purpose e sta diventando un'architettura a tutti gli effetti, invadendo decisamente il campo che prima era prerogativa di CORBA e Microsoft. Ma cos'è Java? Analizziamo brevemente in cosa consiste Java e vedremo che effettivamente si tratta di molto di più di un linguaggio.
- Il codice interpretato è ancora disponibile per effettuare i controlli di sicurezza necessari. Uno dei baluardi della sicurezza di Java è dato proprio dal fatto di essere in un ambiente interpretato che realizza uno strato di protezione tra il codice e le risorse della macchina. Con il JIT il codice compilato non sostituisce il codice intermedio ma si affianca: prima si effettua il controllo di sicurezza e poi si esegue il metodo in forma compilata.
- Infine non dimentichiamo che un elemento fondamentale di Java è la JVM che definisce una macchina virtuale astratta indipendente dalle caratteristiche hardware della macchina sottostante. Se si risolvesse il problema dell'inefficienza di Java con un semplice compilatore Java in codice binario si avrebbero gli stessi problemi di portabilità dei linguaggi tradizionali e la migrazione del codice non sarebbe possibile. Invece, la JVM resta elemento centrale nell'architettura Java e il codice continua a essere distribuito in forma intermedia permettendone la migrazione. Se poi in una particolare macchina è disponibile il JIT, la forma intermedia verrà compilata "al volo" in codice nativo e in modo trasparente. Se invece il JIT non è disponibile, nessun problema, il codice funziona lo stesso.
Personalmente mi trovo concorde con coloro che considerano Java una tecnologia importante, da monitorare costantemente perché in continua evoluzione e, soprattutto, da conoscere perché ritengo che il mondo software parlerà sempre più Java in futuro.
Distributed computing & mobile code
Da quanto descritto finora dovrebbe essere chiaro che Java non identifica semplicemente un linguaggio ma un'architettura. Comunque, a scanso di equivoci, chiariamo subito che attualmente Java non è un'architettura di distributed computing come CORBA, almeno per ora. Sì è vero, il codice Java può migrare in rete e essere caricato e eseguito dinamicamente, ma questo si chiama mobile code computing, non distributed computing. Spieghiamo la differenza.
Il distributed computing è il modello client/server, ossia la possibilità di avere applicazioni distribuite su macchine diverse in grado di comunicare tra loro. L'evoluzione ultima del distributed computing è l'architettura ORB (Object Request Broker) in cui le applicazioni sono formate da componenti distribuite e la comunicazione avviene tramite l'ORB che è in grado di localizzare e attivare le componenti a seguito di invocazioni. La differenza tra il modello ORB e il classico modello RPC (Remote Procedural Code) è duplice:
- la trasparenza. Nel modello ORB le invocazioni delle operazioni di componenti distribuite avvengono allo stesso modo delle invocazioni di componenti locali: l'ORB maschera completamente la distribuzione. Il vantaggio è che il partizionamento delle componenti sulle varie macchine e sui vari processi può essere delegato a una fase successiva dello sviluppo. Invece, nel modello RPC il programmatore è consapevole di come sono distribuite le applicazioni e le chiamate remote tipicamente hanno sintassi diversa dalle chiamate locali.
- l'attivazione. Nel modello ORB a seguito di un'invocazione di operazione l'ORB è in grado di localizzare e attivare la componente destinataria. Nel modello RPC le applicazioni devono già essere attive per comunicare tra loro.
Il mobile code computing è un modello introdotto da Java e altri linguaggi come Telescript che permettono al codice di migrare in rete. Grazie alla portabilità totale del codice garantita dalla presenza della JVM, la possibilità di caricare codice dalla rete diventa realtà. Il meccanismo è legato alla caratteristica di dynamic loading di Java per la quale le classi Java che formano un programma non vengono caricate immediatamente quando il programma viene attivato. Invece, le varie classi vengono caricate "su richiesta" la prima volta che i loro metodi vengono richiamati. Il codice delle classi può essere cercato sul file system locale o anche in rete. Si noti che questo non è distributed computing: una volta caricate le classi dalla rete il programma viene eseguito localmente e non si ha comunicazione remota con altre applicazioni.
Quindi se Java non è un'architettura di distributed computing, qual'è la sua relazione con CORBA? Possono i due modelli completarsi a vicenda o esistono alcune incompatibilità?
Java RMI
Java è in continua evoluzione. Non passa una settimana senza che venga annunciato un nuovo framework di classi, un'estensione del linguaggio, una nuova astrazione architetturale.
Tra le astrazioni architetturali che estendono Java una delle più importanti recentemente introdotta è quella col nome di RMI (Remote Method Invocation) sviluppata da JavaSoft.
Sopra abbiamo chiarito che l'architettura Java è nata con ambizioni di mobile code computing, non distributed computing. Ebbene, l'intenzione della RMI è proprio di invadere quel campo che prima era prerogativa di CORBA, ossia rendere Java un'architettura di distributed computing. La RMI non cerca di avvicinare Java a CORBA, ma di offrire un'alternativa a CORBA. Ma cos'è la RMI? Si tratta di un modello architetturale molto interessante che meriterebbe un'ampia descrizione. Nel seguito cercherò di delinearne le caratteristiche principali.
La prima considerazione è la seguente: mentre CORBA presume l'esistenza di un ambiente eterogeneo, con molti linguaggi di programmazione, protocolli di comunicazione, hardware e sistemi operativi diversi, l'obiettivo della RMI è di definire un modello di distributed computing specifico per Java, in ambiente omogeneo Java, tale da sfruttare le prerogative del linguaggio e offrire ai programmatori uno strumento facile da usare e vicino alla filosofia del Java. Prima di descrivere il modello architetturale della RMI è opportuno rivedere i passi richiesti nello sviluppo di un'applicazione CORBA e paragonarli con l'uso della RMI.
In CORBA si parte specificando le interfacce degli oggetti in IDL (Interface Definition Language). L'IDL rappresenta la "lingua franca" di descrizione delle interfacce che astrae dal linguaggio di programmazione. Però le applicazioni CORBA devono essere implementate utilizzando un linguaggio di programmazione e OMG ha standardizzato come mappare i tipi dell'IDL (interi, stringhe, strutture, sequenze, riferimenti di interfacce, ecc.) nei tipi del linguaggio di programmazione usato per sviluppare l'applicazione. Dopo aver specificato le interfacce IDL, si utilizza un compilatore che traduce la specifica IDL in un insieme di stubs che contengono la logica necessaria per eseguire il marshalling/unmarshalling dei parametri e per accedere ai servizi di trasporto per l'esecuzione dell'invocazione remota. Infine si definisce l'implementazione dell'applicazione e si "lega" l'implementazione con le stubs (linking) realizzando così un'applicazione CORBA. Il problema di questo approccio è duplice:
- il mapping IDLlinguaggio di programmazione non è sempre lineare e spesso in OMG hanno dovuto ricorrere a forzature per mappare modelli diversi tra loro;
- il processo di compilazione IDLlinguaggio di programmazione non permette un meccanismo di reverse engineering. Se sorgessero esigenze di design durante la fase implementativa tali da richiedere la modifica delle interfacce, non è generalmente possibile ricavare una specifica IDL a partire dal codice sorgente dell'implementazione, ossia procedere nel senso linguaggio di programmazioneIDL.
Invece, per la RMI Java è IL linguaggio per cui non esiste la necessità di un linguaggio IDL. Con la RMI, le interfacce degli oggetti accessibili remotamente sono definite usando il concetto di interfaccia già presente nel linguaggio Java. Semplicemente, affinché un'interfaccia Java possa essere accessibile remotamente deve ereditare dall'interfaccia Remote. L'interfaccia Remote non definisce operazioni ma serve a marcare la possibilità di invocazione remota:
interface Remote {}Per definire un'interfaccia Bank in Java accessibile remotamente è sufficiente indicare che eredita da (extends) Remote e definire le operazioni supportate:
public interface Bank extends Remote {Questo è quanto richiesto per indicare che un'interfaccia Java è accessibile remotamente ed equivale alla definizione IDL dell'interfaccia. Il passo successivo è di fornire un'implementazione indicando una classe Java che implementa (implements) l'interfaccia. La classe che implementa un'interfaccia accessibile remotamente (ossia che eredita da Remote) deve a sua volta ereditare dalla classe UnicastRemoteServer. Nel nostro esempio avremo:public void deposit(float amount);
public void withdraw(float amount);
public float balance();
}
public class BankImpl extends UnicastRemoteServer implements Bank {La compilazione di un programma Java con il precompilatore rmic genera le stubs di comunicazione per le classi che ereditano da UnicastRemoteServer.public void deposit(float amount ) {....}
public void withdraw(float amount {....}
public float balance() {....}
}
Esiste anche la possibilità di avere oggetti remoti senza dover ereditare dalla classe UnicastRemoteServer. Questa possibilità si rivela preziosa quando si vuole rendere remota una classe B che eredita da una classe A. Poiché Java non permette l'ereditarietà multipla non è possibile per B ereditare sia da A che da UnicastRemoteServer. Per risolvere il problema la classe UnicastRemoteServer offre l'operazione exportObject che dato un oggetto che supporta l'interfaccia remota crea una stub per quella interfaccia:
public RemoteStub exportObject(Remote obj)Ma oltre al fatto di essere integrato nel linguaggio Java e semplice da usare, la RMI presenta altre caratteristiche decisamente interessanti per un'architettura di distributed computing, vediamone alcune.
Proprietà della RMI
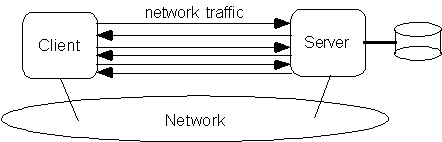
pass-by-reference: la comunicazione è remota
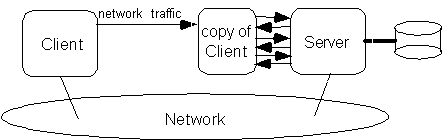
pass-by-value: l'oggetto viene copiato e la comunicazione diventa locale
Ma esistono altri casi in cui una semantica pass-by-value per gli oggetti sarebbe molto utile. In particolare, tutte le volte che si ha la necessità di indicare tra i parametri delle strutture dati inerentemente complesse che sono più naturalmente modellate sotto forma di oggetti piuttosto che ad esempio records o arrays. In CORBA, per passare per valore strutture dati modellate sotto forma di oggetti il programmatore è costretto a trasformare le strutture in una rappresentazione non object oriented anche se l'approccio a oggetti sarebbe il più naturale. OMG ha riconosciuto la necessità di estendere CORBA per permettere semantica pass-by-value per gli oggetti e ha recentemente emesso un RFP (Request For Proposal) in tal senso.
Ebbene, la RMI nasce intrinsecamente con supporto pass-by-value per gli oggetti. Con la RMI è possibile specificare un qualunque oggetto Java tra i parametri di un'interfaccia remota (che eredita da Remote come visto sopra). Nell'invocazione remota gli oggetti indicati tra parametri sono sempre passati per valore, a meno che il parametro non sia esso stesso un'interfaccia che eredita da Remote: in quel caso l'oggetto viene passato per riferimento. Il passaggio per valore degli oggetti sfrutta un meccanismo di serializzazione di Java che trasforma lo stato interno di un oggetto in uno stream di dati usato a destinazione per inizializzare la copia dell'oggetto. Si noti che passare gli oggetti per valore in Java è molto semplice perché la JVM assicura un ambiente omogeneo tra chiamante e chiamato annullando ogni problema di marshalling/unmarshalling dei parametri tra ambienti eterogenei.
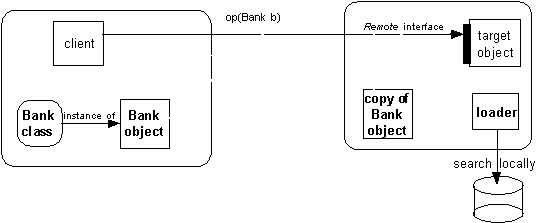
Bank object è passato come parametro. Il loader cerca la classe localmente
Se invece la classe non viene trovata localmente, il loader carica la classe dalla macchina da dove è stata inoltrata la chiamata.
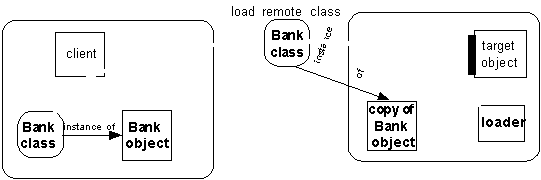
Se il loader non trova la classe localmente, viene caricata da rete
In generale, nelle architetture distribuite per accedere remotamente a un'interfaccia il client deve avere una stub che maschera l'accesso all'interfaccia remota. Ciò implica che in quando il client viene sviluppato è necessario aggiungere nel codice (linking) le stubs di tutte le possibili interfacce che saranno accedute dal client in fase di esecuzione. In alcuni casi sarebbe utile poter definire un client senza predeterminare i tipi di interfacce che questi utilizzerà così da permettere l'invocazione di servizi dei quali non si è a conoscenza quando il client viene costruito.
Con la RMI il meccanismo che permette di copiare gli oggetti assieme alle loro classi viene sfruttato anche nel caso delle stubs: quando un client riceve il riferimento a un'interfaccia remota viene copiata nel client la stub per accedere a tale interfaccia. La stub stessa è in realtà un oggetto Java istanza di una certa classe ed è possibile che tale classe non sia disponibile nel client. Come nel caso di oggetti copiati per valore, anche in questo caso il loader permette di trasferire la classe che implementa la stub dalla rete secondo un meccanismo detto dynamic stub loading.
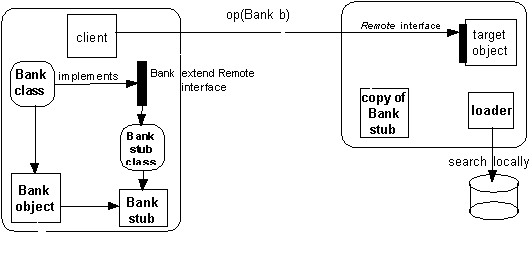
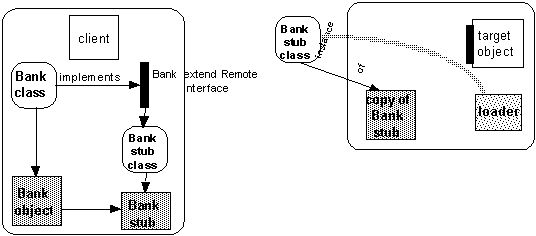
Così un client è in grado di ricevere e usare il riferimento a un'interfaccia remota senza avere predefinito in fase di compilazione la stub per l'accesso a quella interfaccia. Si noti che anche CORBA offre un meccanismo analogo detto Dynamic Invocation Interface (DII) che permette la costruzione dinamica di un'invocazione tramite l'accesso a un Repository di interfacce per ricavare la descrizione delle stesse. Il problema di questo approccio è però duplice:
- la DII è estremamente complessa da utilizzare e certamente poco efficiente perché implica una serie di accessi al Repository di interfacce per ricavare la descrizione dell'interfaccia desiderata;
- il modello di utilizzo della DII è completamente diverso dal modello tradizionale che utilizza stubs linkate al codice in fase di compilazione. Il programmatore deve decidere se vuole utilizzare nel proprio codice il modello della DII o il modello a stubs.
Invece, con la RMI esiste un unico modello: quello a stub. È poi la JVM che dinamicamente è in grado di recuperare le classi corrispondenti alle stubs senza che il programmatore debba utilizzare modelli complessi come la DII.
- il livello di gestione dei riferimenti che definisce la semantica dell'invocazione;
- il livello di trasporto che effettua la connessione remota.
Il livello di gestione dei riferimenti permette diverse semantiche di invocazione, ad esempio punto-punto, multi-punto, invocazione su un gruppo di oggetti replicati, supporto di riferimenti a oggetti persistenti (con l'attivazione degli oggetti stessi), varie strategie di riconnessione, ecc. La versione attuale della RMI supporta una sola semantica di comunicazione remota data dalla classe UnicastRemoteServer in cui i riferimenti sono transienti (non c'è supporto per oggetti persistenti) e la comunicazione è di tipo punto-punto su protocollo di trasporto TCP. Comunque il framework della RMI è stato concepito per estendere la semantica delle comunicazioni remote, per cui è prevedibile che nuove classi saranno presto disponibili.
Se la RMI può essere considerata un'alternativa a CORBA, un ORB Java, il JIDL costituisce invece lo sforzo per integrare la tecnologia Java con CORBA.
JIDL sta per Java Interface Definition Language e rappresenta il mapping IDLJava. L'IDL è un linguaggio di descrizione delle interfacce indipendente dal linguaggio di implementazione. OMG ha definito il mapping dell'IDL su diversi linguaggi di programmazione, tra cui C, C++, Smalltalk e ADA. JavaSoft ha definito JIDL e l'ha sottoposto a OMG affinché questi venga standardizzato. Mentre la filosofia della RMI è "viva la semplicità, viva Java, definiamo un ORB Java", la filosofia della JIDL è "CORBA esiste già, non c'è solo Java, usiamo Java per accedere a CORBA". Con il JIDL, quindi, Java continua a rivestire il ruolo di linguaggio di programmazione senza invadere i confini di CORBA pertinenti alla comunicazione distribuita. Il JIDL è formato da:
- un insieme di classi che permettono ad applicazioni Java di comportarsi da clients di servers CORBA;
- un insieme di classi che permettono ad applicazioni Java di comportarsi da servers CORBA;
- un compilatore IDLJava che genera automaticamente le stubs Java a partire da interfacce IDL;
La versione attuale di JIDL utilizza un protocollo proprietario non conforme al protocollo IIOP di CORBA 2.0 per cui l'ORB del JIDL non è in grado di comunicare con altri ORBs CORBA. Comunque JavaSoft ha annunciato l'intenzione di fornire una prossima versione con supporto all'IIOP così da rendere JIDL conforme totalmente alle specifiche CORBA 2.0.
Oltre alla proposta JIDL di JavaSoft, altri vendors propongono integrazioni Java e CORBA. In particolare ricordimo che Visigenic ha definito Visibroker, un ORB CORBA completamente scritto in Java con supporto al protocollo IIOP. L'elemento rilevante in questo caso è che Netscape ha annunciato che la prossima versione del suo famoso browser disporrà al proprio interno dell'ORB di Visigenic così da permettere al browser di comportarsi da client di servers CORBA. Inoltre, IONA ha definito OrbixWeb, la versione Java del loro prodotto di successo Orbix.
Confronto RMI e JIDL
Il mapping IDLJava del JIDL soffre dei problemi che in generale affliggono tutti i mappings IDL verso i vari linguaggi di programmazione: la non linearità del risultato. Ogni linguaggio di programmazione presenta ovviamente delle differenze rispetto all'IDL per cui quando si definisce un mapping occorre scendere a dei compromessi. Lo sanno bene i programmatori CORBA che quando devono implementare le applicazioni sono costretti a utilizzare meccanismo "poco naturali". Ovviamente, più il linguaggio di programmazione è "simile" all'IDL e meno evidenti sono i problemi. C++ e Java sono linguaggi object orieneted e ciò facilita in parte il mapping con l'IDL, ma solo in parte.
Se consideriamo Java, ogni interfaccia IDL viene mappata su tre interfacce Java più due classi Java. Questo già suggerisce il fatto che si è ricorso a un meccanismo "poco naturale" come detto prima. Una delle interfacce Java corrisponde all'interfaccia IDL e contiene le operazioni definite in quest'ultima. La seconda interfaccia Java contiene le operazioni definite dallo standard CORBA per accedere e manipolare i riferimenti di interfaccia. La terza interfaccia Java implementa le operazioni CORBA lato server. Infine, le classi Java rappresentano la stubs rispettivamente lato client e server.
Un altro problema è il passaggio dei parametri. In Java i parametri sono sempre di tipo in secondo la terminologia CORBA e non è possibile definire parametri out o inout. Per risolvere il problema il mapping definisce delle classi intermedie per tutti i parametri passati come out o inout nella definizione IDL. In questo modo si risolve il problema ma ancora una volta siamo di fronte ad un meccanismo "poco pulito" ma necessario per poter mappare linguaggi con caratteristiche diverse.
Dire se è migliore RMI o JIDL è difficile. Come detto si tratta di due approcci diversi per trattare le problematiche di distributed computing con Java. La scelta su quale usare dipende dalla risposta alla seguente domanda: voglio che sia Java o CORBA la mia "lingua franca"? Attualmente CORBA è più generale di Java, ma la velocità con cui vengono proposte estensioni per integrare Java con l'eterogeneità dei sistemi ha dell'incredibile, ad esempio JDBC per accedere a database relazionali.
La situazione attuale vede CORBA vincente anche perché Java soffre ancora di problemi prestazionali. Però Java evolve a ritmi incredibili e non è escluso che in un prossimo futuro tutto il mondo parlerà Java.
Java Beans
Non vorrei qui ripetere il discorso sul componentware e le architetture di compound document [FBO], [ACD]. Esempi di architetture di compound document sono Microsoft OLE/ActiveX e OpenDoc recentemente standardizzato da OMG. Entrambe queste architetture di compound document sono definite al di sopra delle più generali architetture distribuite, rispettivamente DCOM e CORBA.
JavaSoft ha recentemente annunciato la prossima disponibilità di un'architettura di componenti per Java dal nome Java Beans. Di che si tratta?
Java Beans definisce un framework per costruire e usare componenti e contenitori Java introducendo un ulteriore livello di flessibilità e riuso coprendo cinque aree tecnologiche:
- Publishing & discovery di interfacce. Le componenti sono in grado di scoprire dinamicamente i servizi offerti le une dalle altre;
- Event handling. Le componenti sono in grado di effettuare comunicazioni event-driven con il vantaggio di separare l'emissione di un messaggio dai possibili interessati a riceverlo;
- Persistenza. Lo stato delle componenti viene memorizzato nel contesto dei loro contenitori e in relazione con le altre componenti;
- Layout, ossia rappresentazione su schermo. Ci sono due tipi di controllo del layout: il primo è il fatto che una componente definisce la propria rappresentazione visuale nello spazio di rappresentazione del contenitore; il secondo è la politica di condivisione delle varie componenti nello spazio di rappresentazione dello stesso contenitore;
- Supporto per tools. Le componenti devono fornire interfacce di descrizione delle loro proprietà e comportamento affinché tools di sviluppo possano determinare le caratteristiche delle componenti e modificare la rappresentazione grafica o il comportamento delle componenti stesse. In pratica, oltre a fornire le normali interfacce di servizio, le componenti devono fornire interfacce di controllo sulla loro "programmabilità".
Le caratteristiche di Java Beans rispetto alle altre architetture di compound document sono:
- Compattezza e facilità d'uso. Mentre molte architetture di compound document sono state definite cercando di passare da applicazioni monolitiche a aggregati di componenti a granularità grande/media (è il caso di OLE), Java Beans utilizza l'approccio inverso: si parte da componenti corrispondenti a semplici widgets e applets per passare a componenti più grandi e infine a applicazioni complesse.
- Portabilità totale: è Java!
- Utilizzo delle proprietà di Java. Java Beans sfrutta le innate caratteristiche di introspezione di Java senza richiedere l'aggiunta di nuove parti per permettere il supporto alle componenti. Anche il meccanismo di dynamic loading di Java viene sfruttato da Java Beans.
- Possibilità di distributed computing. Java Beans di per sé non definisce un'architettura di distributed computing ma permette l'integrazione con la RMI e il JIDL per questo scopo.
- Integrazione con altre architetture. Java Beans potrà essere integrato con altre architetture di compound document come OLE/ActiveX, OpenDoc e Live Connect di Netscape. Contenitori OLE/ActiveX e OpenDoc potranno contenere componenti Java Beans al loro interno.
Allo stato attuale (Settembre '96) è disponibile una versione beta di Java Beans nonché la documentazione che ne specifica il framework. L'intenzione di JavaSoft è di rilasciare Java Beans come parte integrante della prossima versione del JDK 1.1. Dopo la RMI Java Beans sembra essere un ulteriore passo di Java everywhere.
Conclusioni
Pare proprio che Java sia destinato a diventare sempre più pervasivo nel panorama del distributed computing. Mi riferisco a Java l'architettura della quale Java il linguaggio è solo uno degli elementi fondamentali. Occorre ammettere che Sun ha operato strategicamente bene nel promuovere la Java. È anche vero che i concetti introdotti da Java non sono nuovi. Ad esempio, il concetto di mobile code computing è stato introdotto da altri linguaggi quali Telescript e Modula3 Networked Objects. Anche i concetti di object orientation, multi-threading, exception handling e garbage collection sono già stati sperimentati nel dominio del software. Per non parlare dell'ingresso di Java nel campo del distributed computing, sicuramente recente rispetto a architetture consolidate come CORBA. Tuttavia è la prima volta che tutti questi concetti vengono integrati in modo omogeneo in un'unica architettura che risolve problemi di interoperabilità, portabilità, migrazione, indipendenza, facilità e flessibilità.
Riuscirà Java RMI a imporsi come standard nelle applicazioni di distributed computing? Se il mondo parlasse solo Java allora direi di sì. Ma attualmente il mondo è più complesso e eterogeneo per cui CORBA ha ancora qualcosa da offrire.
Riferimenti
[ACD] E. Grasso, "Architetture di Compound Document", nota tecnica CSELT n. PG/T/P-95-052.
[VDP] E.Grasso, A. Lagna, G. Lo Russo, G. Martini, "Valutazione tecnologica di piattaforme per DP", documento tecnico CSELT, draft 1.0.
[FBO] E. Grasso, "Frameworks e Business Objects", nota tecnica CSELT n. PG/T/A-96-002.
[OMG] P.G. Bosco,
E. Grasso, "Lo standard OMG-CORBA", nota tecnica CSELT n. PG/T/P-95-
Ennio Grasso
appartiene alla linea di Tecnologie Softeware di CSELT. Occupandosi di
object-oriented distributed computing da quando è entrato in CSELT
nel 1992, ha maturato una certa esperienza sia progettuale che implementativa.
È rappresentante CSELT in OMG e segue lo standard CORBA sin dalle
prime fasi. Autore del modello transazionale dell'architettura TINA, ha
studiato l'applicazione di concetti transazionali rilassati per sistemi
distribuiti dove il concetto di "transazionalità" deve essere adattato
al dominio applicativo. Ultimamente la sua area di competenza si è
concentrata sugli aspetti architetturali di Java, in particolare per gli
aspetti di distrubuted computing, migrazione di codice e mobile agents.
|
|
||
 |
MokaByte ricerca
nuovi collaboratori.
|
 |
|
|
||