|
MokaByte
Numero 16 Febbraio 1998
|
|||
 |
|
||
|
Giovanni Puliti |
|
||
|
MokaByte
Numero 16 Febbraio 1998
|
|||
|
|
|
||
|
Giovanni Puliti |
|
||
Parliamo di
programmazione distribuita e implementazione distribuita mediante la tecnologia
Java.
Analizziamo
il nuovo set di API introdotte da Sun nel JDK 1.1, le cosiddette Remote
Method Invocation (RMI) API, che mettono a disposizione tutti gli strumenti
necessari a tale scopo.
Tale modello
di lavoro si basa, come è facilmente deducibile dal nome, sul meccanismo
di invocazione remota dei metodi di un oggetto. Grazie a tale meccanismo
una applicazione può comandare una serie di oggetti in esecuzione
su uno o più server remoti, dando luogo ad una applicazione distribuita
costituita da tante unità periferiche al servizio di una centrale.
Lo scopo del presente articolo è quello di permettere al lettore
di comprendere innanzi tutto cosa sia possibile fare con RMI, e successivamente
di analizzare l'architettura tipica ed i passi necessari per poter implementare
una applicazione distribuita in Java.
Prima di affrontare i concetti fondamentali legati alla tecnologia Remote Method Invocation, cerchiamo di comprendere, con qualche esempio, come essa possa essere utilizzata, o meglio, in quali situazioni può risultare vantaggioso il suo impiego.
Come primo esempio possiamo pensare ad una pagina html che una volta caricata in un browser, permetta di manipolare un database remoto e magari di visualizzarne i vari record. Per poter realizzare una struttura di questo tipo possiamo pensare di inserire una applet all'interno della pagina html, e di permetterle di gestire una serie di oggetti remoti: saranno infatti questi ultimi a colloquiare con il DBMS in questione, inviando poi i risultati delle interrogazioni o della modifiche alla applet, che a sua volta le visualizzerà all'interno della pagina html. In tale scenario, detto comunemente Architettura a 3 strati, l'applet assume il ruolo di client RMI, mentre l'applicazione remota viene detta server RMI: essa è costituita da un programma standard fornito col JDK 1.1 (una specie di demone Unix), e da una serie di oggetti remoti.
Il compito del demone è quello di intercettare le richieste provenienti dall'esterno e, di conseguenza, gestirne gli oggetti remoti. Al momento dell'implementazione del lato server ci si deve quindi solo preoccupare degli oggetti remoti, non dell'applicazione che li gestisce.
Un altro esempio tipico in cui la programmazione distribuita, ed in particolare RMI, risolve la maggior parte dei problemi, è quello del commercio elettronico o comunque delle transazioni monetarie. L'organizzazione della struttura è molto simile al caso precedente, mentre la terminologia e la funzionalità dei vari oggetti è un po' differente. Il client (applet nella pagina html) ad esempio potrebbe essere pensato come una specie di sportello bancario virtuale, col quale poter effettuare delle transazioni sulla banca centrale (il server RMI). Si tenga presente che, da un punto di vista logico, il fulcro della struttura è in genere sul server RMI (ad esempio il database), mentre da un punto di vista della invocazione dei metodi, è il client che comanda. Come si è potuto osservare in questo tipo di discussione, termini come remoto, locale, client e server, compaiono abbastanza frequentemente: dato che in Java non è sempre automatico individuare tali elementi, anche se non molto propriamente definiamo locale o client l'applicazione che esegue le chiamate agli oggetti remoti, mentre remota sarà sempre l'applicazione in esecuzione altrove, contenente oggetti invocabili dal client.
Il programma
locale prende il nome di client RMI mentre l'altro diviene il server RMI.
macchine virtuali in esecuzione su computer diversi collegati da una rete.
Architettura di RMI
Dopo aver visto cosa significa RMI e come si può sfruttare, passiamo adesso ad analizzare la struttura tipica di una applicazione RMI. Osservando la Figura 1 possiamo vedere come essa sia organizzata orizzontalmente in strati sovrapposti, ed in due moduli verticali paralleli fra loro: questa seconda suddivisione vede da una parte il lato client, e dall'altra il server.
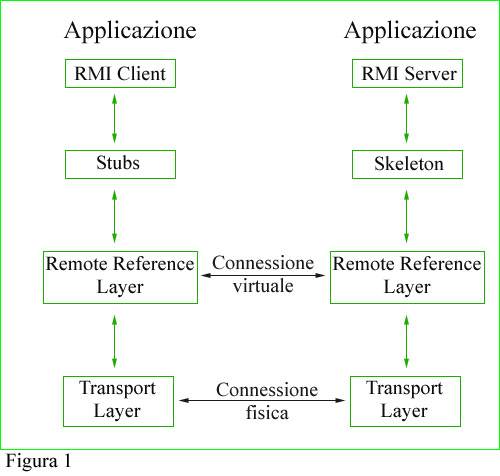
Lo strato più alto del grafico è costituito su entrambi i lati (client e server) dall'applicazione che viene eseguita sulla Java-Machine: nel caso del client come accennato precedentemente, si tratta di una applicazione vera e propria che durante il suo ciclo di vita esegue delle chiamate a dei metodi di oggetti remoti; se fosse possibile sostituire tali elementi con equivalenti locali, si avrebbe una normale applicazione del tutto svincolata dal concetto di programmazione distribuita. Per quanto riguarda invece l'applicazione server, per sua natura, ha un ciclo vitale indipendente dal client e di fatto ignora la sua presenza. Subito sotto il livello applicazione troviamo i due protagonisti di tutto il meccanismo RMI, lo stub e lo skeleton, due rappresentanti della stessa entità. Per capire il motivo di questa doppia presenza, è bene fare un piccolo passo indietro, riconsiderando il caso non distribuito: in tal caso, quando un oggetto desidera invocare un metodo di un altro oggetto, deve prima ricavarne un riferimento (indirizzo), istanziandolo direttamente o ricevendone l'indirizzo dall'esterno, e successivamente eseguire una istruzione del tipo:
nome_oggetto.nome_metodo(lista parametri)
Nel caso distribuito
invece le cose sono un po' più complicate, in quanto si deve, fra
l'altro, ricavare il riferimento all'oggetto remoto e invocarne i metodi
a distanza. La soluzione proposta da RMI, consiste nello scaricare in locale
un rappresentante dell'oggetto remoto e di considerarlo come se si trattasse
a tutti gli effetti di un elemento locale. È la tecnologia RMI che
si occupa in maniera del tutto trasparente di forwardare le richieste di
esecuzione dei vari metodi all'oggetto remoto residente sul server RMI:
in tal modo il client ha l'impressione di maneggiare una risorsa locale,
ma in realtà il codice viene eseguito dal processore residente sul
server remoto. I due oggetti che implementano questo meccanismo, il rappresentante
locale, ed il reale oggetto remoto ad esso collegato, sono detti stub (letteralmente
surrogato), e skeleton. Grazie a questo meccanismo il codice necessario
ad invocare un oggetto remoto è praticamente identico al caso precedente,
infatti basta scrivere:
nome_oggetto_remoto.nome_metodo(lista parametri)
In conclusione
il programmatore dell'applicazione lato-client, non ha che in minima parte
la percezione del fatto che sta interagendo con un oggetto remoto, e la
maggior parte del lavoro è delegato alla macchina virtuale estesa
per mezzo di RMI.
L'equivalenza al caso non distribuito in riferimento all'invocazione dei metodi, vale anche per i parametri passati: ad un metodo remoto infatti può essere passato un parametro elementare, un oggetto di complicazione arbitraria, e perfino una struttura o aggregati di oggetti.
Non esistono
limiti da questo punto di vista, a patto che l'oggetto in questione sia
serializzabile. Anche dal punto di vista sintattico niente cambia, infatti
possiamo scrivere:
nome_oggetto_remoto.nome_metodo(nome_Tipo_serializzabile valore)Gli strati RRL e TL
Passiamo adesso ad analizzare gli strati sottostanti dello schema riportato in Figura 1: i lati server e client, sono collegati con il sottostante Remote Reference Layer (RRL) che a sua volta si appoggia al Transport Layer (TL)
Il primo dei due ha il compito di instaurare un collegamento logico fra i due lati, di codificare le richieste del client, inviarle al server, decodificare le richieste ed inoltrarle allo skeleton.
Ovviamente nel caso in cui quest'ultimo fornisca dei risultati per il particolare tipo di servizio richiesto, il meccanismo di restituzione di tali valori avviene in maniera del tutto simile, ma in senso opposto. Al livello RRL viene instaurato un collegamento virtuale fra i due lati, client e server, mentre fisicamente la connessione avviene al livello sottostante, quello definito Transport Layer. Tale collegamento è di tipo sequenziale ed è per questo che si richiede la serializzazione dei parametri da passare ai metodi. Il collegamento virtuale del RRL si basa su un protocollo di comunicazione generico ed indipendente dal particolare tipo di stub o skeleton utilizzati: questa genericità permette di mantenere la massima indipendenza dal livello stub/skeleton, tanto che è possibile sostituire il RRL con versioni successive meglio ottimizzate. Per quanto riguarda invece il protocollo di conversione delle invocazioni dei metodi, la gestione dei riferimenti ai vari oggetti, e tutto quello che riguarda la gestione a basso livello, una prima conversione dall'astrazione del livello stub/skeleton avviene dal RRL, ma gran parte del lavoro viene fatto dal TL, in cui si perde la concezione di oggetto remoto e/o locale, ed i dati vengono semplicemente visti come sequenze di byte da inviare o leggere verso certi indirizzi di memoria.
Quando il TL riceve una richiesta di connessione da parte del client, localizza il server RMI relativo all'oggetto remoto richiesto: successivamente viene eseguita una connessione per mezzo di un socket appositamente creato per il servizio. Una volta che la connessione è stabilita, il TL passa la connessione al lato client del RRL ed aggiunge un riferimento dell'oggetto remoto nella tabella opportuna. Solo dopo questa operazione il client risulta effettivamente connesso al server, e lo stub è utilizzabile dal client.
Il TL è responsabile del controllo dello stato delle varie connessioni: se un periodo di tempo significativo passa senza che venga effettuato nessun riferimento alla connessione remota, si assume che tale collegamento non sia più necessario, e quindi viene disattivato. Mediamente il periodo di timeout scatta dopo 10 minuti.
L'ultimo livello che però non viene incluso nella struttura RMI, è quello che riguarda la gestione della connessione al livello di socket e protocolli TCP/IP. Questo aspetto segue le specifiche standard di networking di Java e non offre particolari interessanti dal punto di vista di RMI.
Dopo l'introduzione e la teoria, vediamo in pratica quali sono i passi da compiere per realizzare una applicazione distribuita. Affronteremo questo aspetto in una specie di step to step che guidi nella realizzazione dell'applicazione. Tutte le classi ed i metodi necessari per lavorare con RMI, compresi quelli che andremo adesso ad analizzare, sono contenuti nei package java.rmi e java.rmi.server.
In base alle direttive di Sun, si definisce oggetto remoto un oggetto i cui metodi possono essere eseguiti da una applicazione client non residente sulla stessa macchina virtuale.
Una interfaccia remota invece è una interfaccia il cui scopo è quello di offrire al mondo intero, il set di metodi disponibili per l'invocazione a distanza. Per poter definire un oggetto remoto, partiamo dalla definizione della classe corrispondente: supponiamo quindi di aver un oggetto (per il momento locale) MyServer così definito:
public class MyServeril metodo Compute esegue una concatenazione fra i due argomenti passati in input restituendo in uscita la stringa risultante. Tale metodo è molto semplice, ma, come accennato nel paragrafo introduttivo, non ci sono limiti alla complessità delle operazioni eseguibili, e dei parametri ricevuti in input o restituiti al termine delle operazioni.{
public void String Compute
(String a, String b)
{
return a+b;
}
}
Ora che abbiamo definito questa semplice classe per renderla visibile al mondo esterno dobbiamo definire la sua interfaccia remota:
public interface MyServerInterfacePer costruire una interfaccia remota è necessario estendere java.rmi.Remote, che è vuota e serve solo per verificare, durante l'esecuzione, che le operazioni di invocazione remota siano possibili.extends java.rmi.Remote
{
public void String Compute
(String a, String b)
RemoteException;
}
Di fondamentale importanza è l'obbligatoria gestione dell'eccezione java.rmi.RemoteException: infatti, dato che si fa uso di un canale di comunicazione, si deve tener conto di eventuali problemi derivanti da un non corretto funzionamento della connessione. Ad esempio, potrebbe verificarsi che il server remoto non sia raggiungibile o che un certo oggetto remoto non sia disponibile.
Quindi la classe di partenza, dovendo implementare l'interfaccia definita poco sopra, dovrà essere modificata nel seguente modo:
public class MyServer implementsCome si può notare oltre a dichiarare di implementare l'interfaccia precedentemente definita, dobbiamo anche estendere la classe UnicastRemoteServer, una classe predefinita che serve per referenziare l'oggetto remoto.MyServerInterface
UnicastRemoteServer
{
public void String compute
(String a, String b)
throws java.rmi.RemoteException
{
return a + b;
}
}
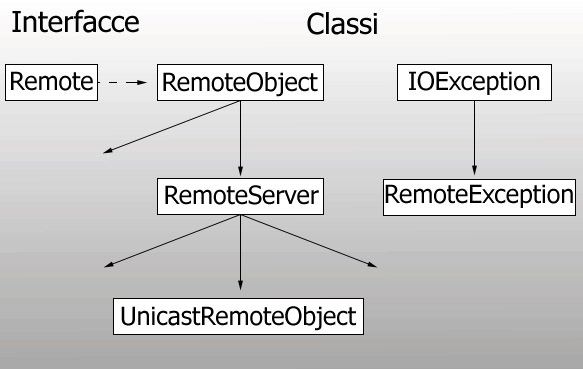
UnicastRemoteServer deriva da altre due classi, RemoteServer (una superclasse comune per tutte le implementazioni di oggetti remoti) e RemoteObject (che semplicemente ridefinisce i metodi hashcode() e equals() in modo da far funzionare correttamente i confronti tra oggetti remoti). L'utilizzazione della classe RemoteServer permette di utilizzare implementazioni di oggetti remoti diverse da UnicastRemoteServer, anche se per il momento quest'ultima è l'unica supportata. La struttura che si viene a creare è raffigurata in Figura 2.
A questo punto l'oggetto è visibile dall'esterno, ma ancora non utilizzabile dal meccanismo di RMI: si devono infatti creare i cosiddetti stub e skeleton. Essi sono ottenibili in maniera molto semplice per mezzo di un tool inserito nel JDK 1.1: si tratta di un compilatore dedicato (rmic), il quale, partendo direttamente dal bytecode ottenuto al termine della compilazione standard, permette di ottenere le due classi relative. Ad esempio se si dispone del file relativo all'oggetto remoto sotto forma di file MyServer.class con un comando da shell del tipo
rmic MyServer.classsi ottengono i due file MyServer_stub.class e MyServer_skel.class.
Ultimo passo da compiere è definire il nome con cui tale l'oggetto remoto può essere invocato da un client.
Sul lato server l'applicazione che gestisce lo skeleton, deve rendere pubblico al mondo che possiede al suo interno un oggetto abilitato all'invocazione remota.
Per far questo è necessario utilizzare il metodo statico java.rmi.Naming.bind che associa all'istanza dell'oggetto remoto un nome logico con cui tale oggetto può essere identificato in rete:
public static void main (String[] args)Questa operazione, detta registrazione, ovviamente può fallire, ed in tal caso un'opportuna eccezione viene lanciata dal Naming.bind().throws Exception{
MyServer server = new MyServer();
java.rmi.Naming.bind("MyServer", server);
}
Tutte le registrazioni eseguite sono poi gestite da un apposito programma, detto rmiregistry, che deve essere stato preventivamente mandato in esecuzione sul lato server. È questo il demone di cui si è precedentemente parlato, e di fatto il suo compito è quello di mettersi in attesa su una porta di sistema (per default la 1099) per rispondere ad eventuali richieste di utilizzazione dell'oggetto remoto registrato.
Tali richieste devono essere effettuate sul lato client subito prima del collegamento con l'oggetto remoto:
public static void main (Strings[]Il metodo statico Naming.lookup() esegue una ricerca in rete in base al parametro URL passatogli, che specifica il nome della macchina che ospita l'oggetto remoto e, ovviamente, il nome con cui l'oggetto è stato registrato. Nella stringa di definizione dell'url, non si deve specificare il protocollo di trasmissione, infatti, essendo ovviamente RMI, la JVM gestisce automaticamente tale informazione.args) throws Exception{
MyServerInterface server =
(MyServerInterface)
java.rmi.Naming.lookup
(
System.out.println
(server.compute("Hello ",
"world!"));
}
Si noti che l'oggetto
server non è dichiarato come MyServer, ma come MyServerInterface:
infatti in virtù del meccanismo di sdoppiamento messo in atto dalla
coppia stub-skeleton, il metodo lookup() invocato sul client, restituisce
un MyServer_stub e non un oggetto di tipo MyServer.
Class Loader,
Security Manager e Garbage Collection
Fin qui abbiamo
parlato dei vari meccanismi che permettono di dar vita ad una struttura
distribuita, cioè abbiamo affrontato la questione dal punto di vista
del programmatore. Rimarrebbero da affrontare due aspetti fondamentali,
che riguardano la gestione della sicurezza ed il garbage collector.
Per quanto riguarda
la sicurezza, la sola differenza col caso locale, è la presenza
di un security manager apposito (il java.rmi.SecurityManager) il
quale deve essere esplicitamente installato da dentro l'applicazione client
prima di tentare ogni richiesta di servizio remoto per mezzo di una istruzione
del tipo:
java -Djava.rmi.server.codebase = //myhost MyClient
Conclusione
Abbiamo visto
come Sun ha risolto il problema della computazione distribuita, funzionalità
ormai indispensabile per la maggior parte delle applicazioni WEB. La cosa
veramente importante è la semplicità con cui, utilizzando
il package java.rmi, si possono realizzare applicazioni distribuite.
Al momento della
stesura dell'articolo l'unico browser che permette di utilizzare RMI nelle
applet è HotJava, ma sicuramente questa carenza da parte di Netscape
e Microsoft verrà presto colmata.
|
|
||
 |
MokaByte ricerca
nuovi collaboratori.
|
 |
|
|
||