|
MokaByte
Numero 18 - Aprile 1998
|
|||
 |
II parte |
||
|
Michele Sciabarrà |
|
||
|
MokaByte
Numero 18 - Aprile 1998
|
|||
|
|
II parte |
||
|
Michele Sciabarrà |
|
||
Lo sviluppo
di JRC comincia a prendere forma. Questa volta definiamo e implementiamo
il protocollo del server, e possiamo cominciare ad usare il sistema.
La volta scorsa abbiamo definito sia la classe che accetta le connessioni (AppServer), che la classe base che elabora le connessioni (AppServerExec). L'AppServer accetta una connessione e crea una nuova istanza di AppServerExec; ogni istanza di questa classe avvia un nuovo thread, che gestisce l'interazione con i client connessi. In realtà non sarà AppServerExec a gestire le connessioni ma una sua classe derivata, JRCServerExec, che d'ora in poi chiamiamo l'esecutore. Questa classe comunque si appoggia ad altre classi accessorie che gestiscono i buffer, il registro dei nickname e l'analisi dei comandi. L'esecutore in pratica è un interprete di comandi che esegue le richieste provenienti dai client. I comandi implementati sono quelli definiti nel protocollo di comunicazione tra il client e il server.
L'esecutore di AppServerExec è rudimentale: fa solo l'echo di quanto gli invia il client, e riconosce il comando quit per chiudere la connessione.
D'ora in poi
lo sviluppo del server prosegue completando l'implementazione dell'esecutore
secondo quando specificato dal protocollo: già in quest'articolo
gli daremo abbastanza forma per fare delle chat.
Il protocollo
del JRC
Come in tutti
i sistemi client/server, l'approccio seguito è quello di definire
per prima cosa il protocollo che consente l'interazione tra il client e
il server. Nella migliore tradizione dei protocolli di Internet, quello
che definiamo è testuale: la comunicazione avviene scambiandosi
righe di comando; queste righe contengono solo caratteri ASCII stampabili,
e ogni riga è terminata con un newline. In questo modo il protocollo
può anche essere utilizzato manualmente: infatti è possibile
interagire col server come se si utilizzasse un programma con interfaccia
a linea di comando. Questa tecnica rende semplice il testing e ci consente
anche di utilizzare il nostro server, sia pur in maniera scomoda, anche
senza aver ancora implementato il client. Basta infatti utilizzare il programma
telnet disponibile, aprendo la porta del nostro server (6789) per
interagire con esso. Naturalmente la vera interazione avverrà utilizzando
il client scritto appositamente, che analizzeremo nei prossimi articoli.
In Tabella 1 sono riassunti i comandi pianificati nel protocollo
completo, anche se è possibile che ci sia qualche ripensamento durante
l'implementazione.
Comando e Significato |
|
Vediamo in dettaglio le parti del protocollo che implementiamo. La logica d'uso è che il client per prima cosa si identifichi, specificando con il comando NICK il proprio nickname (ovvero lo pseudonimo che si utilizza solitamente nelle chat per identificarsi). A quel punto, il client potrà intervenire nelle discussioni. Il comando per mandare un intervento a tutti è TALK, mentre per leggere gli interventi degli altri si utilizzerà il comando READ (da usare quindi esplicitamente). Il client dovrà quindi:
1) effettuare una READ
2) se l'utente è intervenuto (cioè ha digitato un intervento in una apposita casella di testo) mandare il proprio intervento con TALK
3) aspettare qualche secondo (per non intasare il server con richieste continue)
4) Ritornare al punto 1)
Naturalmente ci sono delle complicazioni delle quali ci occuperemo più avanti nel progetto (cosa fare, ad esempio, se l'utente vuole inviare comunicazioni private, o se vuole cambiare stanza?).
Per ora ci limitiamo a descrivere e implementare un subset del protocollo che consenta di parlare tra più utenti utilizzando una unica "stanza" (o canale) di conversazione.
Il protocollo
in dettaglio
Dopo l'invio
di ogni comando ci si attende una riga di risposta, che inizia con un codice
numerico seguita da altre eventuali informazioni. I codici delle possibili
risposte sono mostrate in Tabella 2, che descriveremo secondo il
loro nome simbolico piuttosto che con il codice numerico. In realtà
la risposta del server è sempre <codicenumerico> <codicesimbolico>
<testodescrittivo> ma al client basterà interpretare il codice
numerico per capire la risposta; il resto è per una questione di
leggibilità.
| Codice | Valore | Significato |
| OK
DATA SYNTAX NOCMD NOAUTH NONICK NOROOM UNDEFINED |
0
1 2 3 10 11 12 255 |
Comando riuscito
senza dati
Comando riuscito, seguono dati Errore di sintassi Comando non esistente Autorizzazione negata Nickname non esistente Stanza non esistente Errore generale indefinito |
|
|
Dopo il codice di risposta possono seguire altre informazioni (per esempio in risposta al codice DATA seguono esplicitamente dei dati che il client dovrà leggere).
Il comando NICK <nickname> consente di specificare il nickname. Le risposte possibili sono OK se il nickname è stato accettato e NOAUTH se il nickname esiste già.
Il comando TALK <intervento> consente ad un client di intervenire nella discussione Le risposte possibili sono OK se è stato possibile inviare il messaggio e NOAUTH se il nickname non è stato definito.
Il comando READ consente di leggere tutti gli interventi finora non letti. Se ci sono appunto interventi, la risposta sarà composta da più linee ognuna contenenti :
1) La stringa "DATA"
2) Un numero, che indica la quantità di linee che seguiranno
3) Le linee rappresentanti gli interventi degli altri client connessi.
Verrà risposto semplicemente "OK" nel caso che non ci fossero interventi da leggere.
Il comando QUIT
consente al client di disconnettersi e va sempre dato per terminare una
sessione (anche se l'implementazione prende qualche precauzione nel caso
il client non lo faccia).
Architettura
del JRC Server
Vediamo ora
i dettagli implementativi del server.
Ogni oggetto esecutore (JRCServerExec) ha un suo buffer degli interventi (ChatBuffer). Ogni volta che qualcuno interviene nella discussione, il suo intervento viene aggiunto ai ChatBuffer degli esecutori destinatari, ovvero a tutti nel caso si faccia una TALK. e al solo destinatario nel caso di una SEND.
Quindi deve esistere un registro degli esecutori attivi in un dato momento, ovvero il NickRegister. Ogni esecutore sarà identificato nel registro utilizzando il nickname specificato dell'utente. Quando l'utente specifica il proprio nickname (col comando NICK), l'esecutore provvede a registrarsi (appunto) nel registro.
Quindi, inviare
un intervento a tutti equivale a scrivere l'intervento nel ChatBuffer
di tutti coloro che sono registrati nel NickRegister. Inviare
un intervento a qualcuno in particolare, significa consultare comunque
il NickRegister per sapere dove trovare il ChatBuffer di
quell'utente per scrivervi . Infine, avremo una classe che si occupa dell'analisi
dei comandi, CmdParser, pensata appositamente per analizzare linee
di comando nel formato solitamente accettato dai server.
Programmazione
concorrente
Dato che il
nostro sistema è multithreaded, ci dovremo preoccupare di alcuni
problemi tipici della programmazione concorrente. Infatti, abbiamo degli
oggetti (ovvero il NickRegister e di vari ChatBuffer) che
sono accessibili a più thread contemporaneamente. Se due thread
potessero accedere contemporaneamente ad uno stesso oggetto senza protezione,
le conseguenze potrebbero essere dannose: per un esempio dettagliato vedere
Java Multithreading, in [1]. Anche se normalmente non ci si fa caso, quando
si usa un metodo di un oggetto si causa in esso una transizione da uno
stato valido prima dell'esecuzione ad un altro stato valido dopo l'esecuzione.
Ma se durante l'esecuzione di un metodo il thread che lo stava eseguendo
venisse interrotto, un altro thread potrebbe agire sull'oggetto mentre
si trova in uno stato non valido. Supponiamo ad esempio di avere
uno stack: un thread potrebbe venire interrotto mentre sta effettuando
una push. Un altro thread potrebbe quindi entrare in azione eseguendo a
sua volta un'altra push, mentre probabilmente il puntatore al top dello
stack risulterebbe corrotto proprio a causa della prima push ancora in
esecuzione.
Il debugging in una situazione come questa sarebbe quantomeno difficile. Quel che è peggio, è che gli errori dovuti all'esecuzione concorrente non protetta sono casuali e imprevedibili, e potenzialmente disastrosi.
Java mette a disposizione un meccanismo generale, semplice ma potente, che mette al riparo da problemi di accesso contemporaneo ad un oggetto condiviso: i metodi sincronizzati. Per definire un metodo come sincronizzato, si usa lo specificatore synchronized. Per ogni diversa istanza dell'oggetto stack, quando un thread esegue un metodo sincronizzato, nessun altro thread può eseguire un altro metodo sincronizzato su quello stesso oggetto. Riconsideriamo l'oggetto stack, e supponiamo che la push sia synchronized. Supponiamo, nel caso visto prima, che un secondo thread tenti di eseguire una push mentre il primo è stato interrotto nell'esecuzione della prima push: questa volta il secondo thread sarebbe messo in attesa fino alla terminazione completa del primo.
Si dice in questi casi che sull'oggetto è presente un semaforo, che crea una coda di thread in attesa mentre l'oggetto è occupato. Gli accessi all'oggetto vengono detti serializzati (ovvero eseguiti uno dopo l'altro), mentre i metodi sincronizzati sono chiamati atomici, nel senso che l'azione da loro eseguita è indivisibile e non può essere interrotta.
Il meccanismo
dei metodi sincronizzati ci consente di risolvere in maniera semplice i
problemi della programmazione concorrente ma non ci mette del tutto al
riparo da errori: occorre riconoscere esplicitamente gli oggetti soggetti
ad un accesso concorrente e dichiarare opportunamente i metodi. Inoltre
l'uso indiscriminato di metodi sincronizzati va evitato in quanto può
portare a sensibili inefficienze.
java.util.Vector
Gli array in
Java sono di dimensione fissa: una volta creati, non è possibile
variarne la dimensione. Se occorresse aggiungere un nuovo elemento, sarebbe
necessario crearne uno nuovo più grande, e ricopiarvi il contenuto
di quello vecchio. Questa operazione in generale è complicata e
inefficiente.
La classe java.lang.Vector, molto utilizzata nella programmazione in Java, implementa un array dinamico ed aiuta a gestire le operazioni di ridimensionamento di array.
La logica d'uso è semplice: basta creare un nuovo vettore con Vector v = new Vector(), per poi aggiungere nuovi elementi in coda con v.addElement(). Naturalmente, poiché Java non supporta l'operator overloading, l'accesso agli elementi non viene effettuato utilizzando l'operatore [] ma tramite un metodo, elementAt(); come gli array, se il Vector contiene n elementi, gli indici vanno da 0 a n1; è possibile sapere il numero di elementi contenuti grazie al metodo size(), simile alla length degli array. Un'altra importante differenza tra i Vector e gli array, è che non è possibile tipizzare gli elementi contenuti nel Vector: sono tutti Object. Questo significa che il programmatore deve sapere che cosa ha messo nel suo Vector per ripristinare il tipo nel momento in cui estrae gli elementi. Quindi se si aggiunge una stringa s in un Vector v con v.addElement(s), estraendola si dovrà eseguire un cast:
s = (String)v.elementAt(0).
Il Vector può essere utilizzato in modo elementare utilizzando i pochi metodi finora elencati. Tuttavia è possibile ottimizzarne l'uso di memoria avendo alcune informazioni sul numero massimo di elementi che saranno inseriti. Il Vector è progettato per essere espandibile, e per questo motivo la vera dimensione del vettore non è data da size() ma da capacity() (che è sempre >= size()). Nel momento in cui il numero degli elementi diventa uguale alla capacità, quest'ultima viene incrementata del valore dato dalla proprietà capacityIncrement. I costruttori consentono di specificare, opzionalmente, sia la capacità che l'incremento di capacità. Avendo una stima del massimo numero di elementi che potranno essere inseriti e dell'incremento medio di capacità, è possibile ottimizzare l'uso del vettore. Quando la dimensione del vettore si è stabilizzata, si può utilizzare trimToSize() per eliminare lo spazio inutilizzato e portare la capacità pari alla dimensione effettiva.
Ci sono altre importanti caratteristiche dei Vector che consentono di utilizzarlo quasi come una lista generica. È infatti possibile inserire elementi "in mezzo" e rimuoverli: insertElementAt(object, i) inserisce l'elemento object alla i-esima posizione , shiftando di una posizione tutti i successivi; removeAllElements() svuota il vettore; removeElementAt(i) rimuove l'elemento di indice i; removeElement(object) rimuove la prima occorrenza dell'object nel vettore (uno stesso oggetto ovviamente può trovarsi più volte in un vettore).
È possibile
effettuare una ricerca lineare in avanti (a partire dal primo elemento
verso l'ultimo): indexOf(object) ritorna l'indice dell'oggetto nel
vettore, o -1 se non è stato trovato, mentre indexOf(object,
n) ritorna l'indice dell'oggetto nel vettore cercandolo a partire dalla
posizione n; si comportano analogamente lastIndexOf(object)
e lastIndexOf(object, n) che effettuano la ricerca scandendo
il vettore dall'ultimo elemento verso il primo.
ChatBuffer
e NickRegister
La classe ChatBuffer,
mostrata nel Listato 1, utilizza sia i meccanismi di sincronizzazione
che i vettori. Ogni esecutore possiede un suo ChatBuffer; questa classe
ha solo due metodi, put e get. Poiché un buffer può
essere utilizzato da più esecutori contemporaneamente, i metodi
sono sincronizzati, garantendo in questo modo che non ci siano dannose
interferenze. Il buffer internamente è un Vector e il metodo put
non fa altro che aggiungere un elemento al buffer. Il metodo get
invece ricopia il contenuto del vettore in un array e lo ritorna al
chiamante (che ha quindi la possibilità di manipolare liberamente
i dati ricevuti).
Listato 1
La classe NickRegister,
mostrata nel Listato 2, fa uso della Hashtable di
cui parleremo prossimamente. Esiste una sola istanza di questa classe,
che è una sorta di variabile globale. Ho posto tutti gli oggetti
che sono in qualche modo globali come elementi statici della classe principale.
JRC.nicks è il registro dei nickname. Forse il nome
NickRegister non è proprio azzeccato, in quanto la classe
si occupa anche di registrare i nickname, e di aggiungere gli interventi
ai vari chat buffer. Questa organizzazione sarà probabilmente soggetta
a ristrutturazione.
public synchronized
boolean add(String s, ChatBuffer cb){
if(register.containsKey(s))
return false;
register.put(s, cb);
return true;
}
public synchronized
boolean del(String s){
if(!register.containsKey(s))
return false;
register.remove(s);
return true;
}
public synchronized
boolean replace(String old, String curr){
if(register.containsKey(curr) || !register.containsKey(old))
return false;
Object obj = register.get(old);
register.remove(old);
register.put(curr, obj);
return true;
}
public synchronized
boolean send(String to, String msg) {
if(!register.containsKey(to))
return false;
ChatBuffer cb = (ChatBuffer)register.get(to);
cb.put(msg);
return true;
}
public synchronized
void talk(String msg){
ChatBuffer cb;
for(Enumeration e = register.elements() ; e.hasMoreElements() ;){
cb = (ChatBuffer)e.nextElement();
cb.put(msg);
}
}
}
Listato 2
Il NickRegister
è a conoscenza di tutte le informazioni necessarie per il chat.
Sono sono quindi definiti anche i metodi talk e send che
consentono di aggiungere interventi ai ChatBuffer. Con talk
si invia un intervento a tutti, ovvero si aggiunge nei ChatBuffer di ogni
esecutore registrato il proprio intervento, mentre con send si invia
l'intervento soltanto ad un ChatBuffer, individuato attraverso il
nickname.
java.util.StringTokenizer
Questa classe
di libreria è un utile strumento per suddividere le stringhe in
sottostringhe (token).
L'uso tipico di questo strumento è l'analisi di file di configurazione o dati in input. Per la verità esiste un tokenizzatore più potente, lo java.io.StreamTokenizer, che però utilizza degli stream come input ed è adatto all'analisi di interi file. Questa classe è invece più adatta per l'analisi di stringhe dalla struttura più semplice. In realtà lo StringTokenizer non basta per i nostri scopi, e lo utilizzeremo come base per implementare il CmdParser, che vedremo più avanti. Comunque si tratta di uno strumento molto utile che vale la pena di conoscere.
Lo StringTokenizer analizza le stringhe spezzettandole in sottostringhe (token) in base a singoli caratteri che fanno da separatori. Per default i separatori sono di spazi e tab. Ecco un esempio di uso:
Si estraggono i singoli token uno a uno usando nextElement(), mentre hasMoreElements() indica se ci sono altri token da estrarre. È possibile specificare come argomento di nextElement una nuova stringa di delimitatori (che cambia quella specificata col costruttore); infine è possibile contare i token in una stringa utilizzando il set di corrente di delimitatori.
CmdParser
Il CmdParser
è una classe che ho scritto di tempo addietro per semplificare
l'analizzatore di comandi di un altro server che stavo sviluppando. L'analizzatore
era diventato gigantesco, eppure si ripeteva spessissimo la stessa sequenza
di codice: spezzettamento dei token, controllo dei tipi e verificava di
errori. Generalizzando quella impostazione ho scritto un parser di comandi,
il cui scopo era di analizzare righe di comandi: la struttura di una riga
di comando era una sequenza di token separati da spazi, in cui il primo
token specificava il comando, mentre i successivi erano argomenti che potevano
essere numeri o stringhe. Prendiamo in esame, ad esempio, la seguente stringa:
PUT 123 ciao
PUT è il comando, mentre 123 e ciao sono gli argomenti, il primo numerico mentre il secondo stringa. Questa impostazione è adattabile perfettamente al protocollo del JRC. Per usare CmdParser occorre innanzitutto creare un oggetto istanza di tale classe, e definire quindi - tramite il metodo add - i comandi che può analizzare. A questo punto per analizzare una riga di comando basta utilizzare il metodo parse; i risultati dell'analisi possono essere letti con getCode, getString, getLong, getDouble, e rimangono disponibili finché non si usa nuovamente parse.
Vediamo ora in
dettaglio come eseguire tutte queste operazioni.
Innanzitutto
bisogna creare un nuovo analizzatore di comandi, tramite la riga:
cmd = new CmdParser()
Il metodo add(String cmd, int code, String param) accetta i seguenti parametri:
· il cmd è la stringa del comando
· code è un intero che rappresenta un codice numerico per il comando
· param specifica il numero e il tipo dei parametri che il comando può accettare.
Per esempio:,
cmd.add("MODE", 7, "wns")
Questa riga dice al CmdParser di accettare un comando MODE il cui codice è 17 e che prende come parametri una stringa non contenente spazi, seguita da un intero e infine una stringa contente spazi. In particolare, l'iesimo carattere di param indica il tipo dell'iesimo argomento che può essere accettato dal comando.
Ogni carattere ha, ovviamente, un significato:
· la n specifica di accettare interi
· la f specifica di accettare numeri in virgola mobile
· la w rappresenta stringhe non contenenti spazi o tab
· la s rappresenta stringhe contenenti spazi.
Attenzione: poiché la s è in grado di "assorbire" ogni cosa fino a fine linea, può essere utilizzato solo come ultimo carattere in una stringa di parametri.
Se scrivessimo per esempio:
cmd.parse("MODE on 15 prova generale").
Il valore ritornato da parse sarebbe CmdParser.PARSE_NOCMD se il comando non esistesse, CmdParser.PARSE_SYNTAX se ci fosse un errore di sintassi (i parametri non corrispondono ai tipi previsti, sono troppi o troppo pochi), e CmdParser.OK se non ci fossero problemi. In tal caso è possibile esaminare il codice del comando riconosciuto con cmd.getCode(): i comandi specificati ovviamente possono essere più di uno, e il codice ritornato per il comando è quello specificato con la add. I comandi vengono specificati per codice invece che per stringa, in quanto un intero può essere utilizzato in uno switch. I parametri possono essere esaminati per tipo con getXxx(int): nel nostro caso, cmd.getCode() ritorna 7, cmd.getString(0) ritorna "on", cmd.getString(1) ritorna "prova generale" mentre cmd.getLong(0) ritorna 15.
L'esecutore:
JRCServerExec
Siamo giunti
all'implementazione dell'esecutore, mostrato nel Listato 3. Si tratta
di una classe derivata da JRCServerExec. Come avevamo detto la volta
scorsa, questa classe deve implementare un metodo detach() per creare
una nuova istanza di sé stessa, e un metodo run() che implementi
il ciclo principale di fetchexecute. Come campi, abbiamo un ChatBuffer,
un CmdParser e una stringa che conservi il nickname corrente.
I costruttori e il detach() sono banali. Quello che è interessante
è JRCServerExec.run().
// errors
public final
int RES_OK = 0;
public final
int RES_DATA = 1;
public final
int RES_SYNTAX = 2;
public final
int RES_NOCMD = 3;
public final
int RES_NOAUTH = 10;
public final
int RES_NONICK = 11;
public final
int RES_NOROOM = 12;
public final
int RES_UNDEFINED = 255;
private String
result(int code) {
switch(code) {
case RES_OK:
return RES_OK+" OK ok";
case RES_DATA:
return RES_DATA+" DATA some data available";
case RES_SYNTAX:
return RES_SYNTAX+" SYNTAX syntax error";
case RES_NOCMD:
return RES_NOCMD+" NOCMD no such command";
case RES_NOAUTH:
return RES_NOAUTH+" NOAUTH authorization denied";
case RES_NONICK:
return RES_NONICK+" NONICK no such nickname";
case RES_NOROOM:
return RES_NOROOM+" NOROOM no such room";
case RES_UNDEFINED:
default:
return RES_UNDEFINED+" UNDEFINED undefined error";
}
}
private ChatBuffer
chatBuffer = new ChatBuffer();
private String
nickname = null;
JRCServerExec() throws IOException { super(); }
JRCServerExec(int
id, Socket socket, Logger logger) throws IOException
{
super(id,socket,logger);
}
public void detach(int
id, Socket socket, Logger logger)
throws IOException
{
(new JRCServerExec(id, socket, logger)).start();
}
public void
run()
{
try {
CmdParser cmd = new CmdParser();
cmd.add("QUIT", CMD_QUIT, "");
cmd.add("NICK", CMD_NICK, "w");
cmd.add("TALK", CMD_TALK, "s");
cmd.add("SEND", CMD_SEND, "ws");
cmd.add("READ", CMD_READ, "");
String line = "";
String nick;
String msg;
boolean res;
String[] as;
// loop fetch-execute
loop:
while(true) {
line = getLine();
log(line);
// analize command line
switch(cmd.parse(line))
{
case CmdParser.OK:
break;
case CmdParser.PARSE_NOCMD:
putLine(result(RES_NOCMD));
continue loop;
case CmdParser.PARSE_SYNTAX:
putLine(result(RES_SYNTAX));
continue loop;
default:
putLine(result(RES_UNDEFINED));
continue loop;
}
// execute commands
switch(cmd.getCode())
{
//------------------------------------------------
case CMD_NICK:
nick = cmd.getString(0);
if(nickname==null)
res = JRC.nicks.add(nick, chatBuffer);
else
res = JRC.nicks.replace(nickname, nick);
if(res)
{
nickname = nick;
putLine(result(RES_OK));
} else
putLine(result(RES_NOAUTH));
break;
//------------------------------------------------
case CMD_TALK:
if(nickname==null)
putLine(result(RES_NOAUTH));
else {
JRC.nicks.talk("["+nickname+"] "+cmd.getString(0));
putLine(result(RES_OK));
}
break;
//------------------------------------------------
case CMD_SEND:
if(nickname==null)
putLine(result(RES_NOAUTH));
else {
msg = "["+nickname+"] "+cmd.getString(1);
if(JRC.nicks.send(cmd.getString(0),msg)
&& JRC.nicks.send(nickname,msg))
putLine(result(RES_OK));
else
putLine(result(RES_NONICK));
}
break;
//------------------------------------------------
case CMD_READ:
as = chatBuffer.get();
if(as==null)
putLine(result(RES_OK));
else {
putLine(result(RES_DATA));
putLine(""+as.length);
for(int i=0; i<as.length; ++i)
putLine(as[i]);
}
break;
//------------------------------------------------
case CMD_QUIT:
putLine(result(RES_OK));
break loop;
//------------------------------------------------
default:
putLine(result(RES_UNDEFINED));
break;
}
}
} catch(Exception e) {
System.err.println(""+e);
} finally {
if(nickname != null)
JRC.nicks.del(nickname);
try {
socket.close();
} catch(Exception e) { }
}
}
}
Listato 3
Analizziamo l'implementazione dei vari comandi.
Nel caso di un comando NICK, occorre registrare nel NickRegister globale, ovvero JRC.nicks, il nickname e il ChatBuffer. Questo comando è utilizzato sia per registrare un nuovo nick, sia per cambiarne uno esistente: il programma dovrà quindi effettuare tutti i controlli in merito all'uno ed all'altro caso.
I comandi SEND e TALK sono molto simili, e in ogni caso si appoggiano al NickRegister: tutto quello che fanno è chiedere al NickRegister di accodare nei ChatBuffer dei destinatari la stringa letta sulla riga di comando.
Il comando READ svuota il ChatBuffer e lo stampa. Ricordo che il protocollo richiede che si ritorni il numero di righe in output prima delle righe vere e proprie (in modo che il client abbia una idea chiara di quanto output gli arriverà).
Il comando QUIT non fa altro che chiudere la connessione. In ogni caso prima di uscire (nel caso si terminasse prematuramente con una eccezione, se il client chiude bruscamente la connessione) la clausola finally fa in modo che ci si deregistri dal NickRegister.
Conclusioni
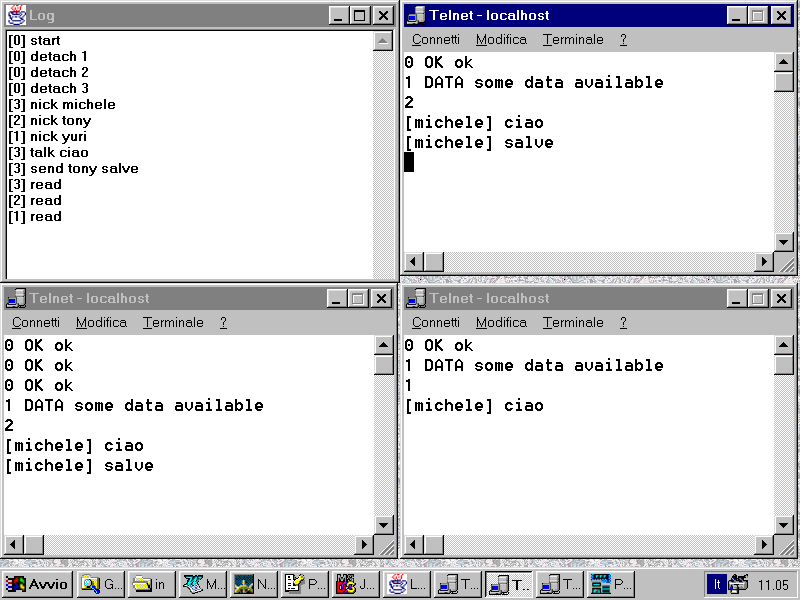
Già si
comincia a vedere qualcosa. In Figura 1 possiamo vedere una sessione,
ottenuta interagendo con il server ed utilizzando il telnet di Windows.
Ho aperto tre connessioni, specificando il nickname per ognuno e poi ho
inviato prima una comunicazione a tutti, poi una comunicazione privata
ad un utente. Nelle sessioni di telnet non sono mostrati i comandi di input
in quanto il server non fa l'echo di quanto digitato: sono visibili
solo gli output del server. Comunque è possibile seguire l'intera
sessione esaminando il log, nella finesta apposita. Il server può
ancora essere arricchito di funzioni, ma non ce ne occuperemo subito. Piuttosto,
la prossima volta scriveremo una applet client capace di comunicare con
il server appena implementato, in modo da poter "toccare con mano" i risultati
ottenuti.
Bibliografia
[1] Michele Sciabarrà
"Lezioni di Java" Computer Programming 53, 54, 55, 56, 57,
58 Edizioni Infomedia 1996/1997
[2] Michele
Sciabarrà "Cos'è Java" e "Dissolvenze in Java"
, Computer Programming 48, Edizioni Infomedia 1996
[3] Yuri Bettini
"OOP e Java" Dev 38, 39 Edizioni Infomedia 1997
[4] James Gosling
"The Java Programming Language", AddisonWesley 1996
[5] Gary Cornell
"Core Java", AddisonWesley 1996
[6] David Flanagan
"Java in a Nutshell", O'Reilly & Associates 1996
Michele Sciabarrà è consulente informatico e scrittore tecnico, specializzato in sistemi e applicazioni Internet ed Intranet. Si occupa di consulenza, amministrazione e sviluppo software per ambienti di rete e siti Web.
|
|
||
|
|
||
 |
MokaByte ricerca
nuovi collaboratori
|
 |
|
|
||