|
MokaByte
Numero 22 - Settembre 1998
|
|||
|
di
|
Socket o RMI? |
||
|
MokaByte
Numero 22 - Settembre 1998
|
|||
|
di
|
Socket o RMI? |
||
Introduzione
In un'applicazione
distribuita esistono molti modi per far interagire gli oggetti attraverso
una rete. I sistemi di Remote Procedure Call (RPC), ovvero
la possibilità di richiamare procedure di programmi operanti su
un diverso host, hanno migliorato le capacità di interazione, mascherando
la spedizione esplicita dei dati necessaria con i socket.
Con Java si
possono seguire due strade per realizzare l'interazione fra oggetti distribuiti:
la prima è usare Remote Method Invocation (RMI) che
è incorporato nel JDK 1.1 e può funzionare solo fra oggetti
Java; la seconda è rappresentata dal fatto che lo standard CORBA
consente di sviluppare applicazioni distribuite che integrano Java ed altri
linguaggi.
In questo articolo,
dopo una breve descrizione di RMI (consultate [1] per approfondimenti)
viene presentata una applicazione three-tier, derivata da quella
descritta in [2], in cui le comunicazioni fra client e middle tier
avvengono con il modello di RMI. Sono analizzate ed confrontate due diverse
implementazioni di interazione con metodi remoti, una che usa i socket
e una basata su RMI.
RMI in Java
Il concetto
base di RMI è molto simile al meccanismo di RPC, in uso in linguaggi
come il C: la sigla RMI esprime l'analogo ad oggetti del concetto
espresso dalla sigla RPC. Una differenza è che un metodo
deve essere sempre associato ad un oggetto; in particolare RMI richiede
che l'oggetto invocato (attraverso il metodo opportuno) sia già
operativo. Lo schema utilizzato da Java RMI per collegare oggetti in spazi
di indirizzamento diversi è detto publish and subscribe:
chi ha dei servizi da offrire li espone pubblicamente, mentre chi necessita
di un servizio si iscrive presso il fornitore. Il "documento" che specifica
i servizi disponibili è l'interfaccia remota, cioè un'interfaccia
Java che estende java.rmi.Remote.
Un oggetto che
attraverso l'interfaccia remota mette a disposizione dei metodi è
un server, mentre un oggetto che invoca tali metodi è un
client. Un dato oggetto può essere contemporaneamente sia
server sia client, questi termini individuano soltanto il chiamante ed
il chiamato in relazione ad una particolare azione. Il client invoca il
metodo del server RMI usa lo stub o rappresentante remoto ([1]),
ossia una "vista remota" dell'oggetto server, che contiene i metodi che
dovranno essere invocati. Lo stub viene creato sull'host dove opera il
client e viene considerato come se si trattasse a tutti gli effetti di
un elemento locale. I canali di comunicazione di RMI si occupano in modo
trasparente di trasmettere le richieste di esecuzione dei vari metodi all'oggetto
server RMI, che può risiedere su un'altra macchina. In tal modo
il client interagisce con una risorsa in apparenza locale, ma in realtà
il codice viene eseguito dal processore del server remoto.
Una caratteristica
molto importante di RMI è che gli oggetti possono essere passati
come parametri alle chiamate ai metodi remoti, trasmettendo uno stub degli
oggetti originari. L'oggetto reale rimane sempre sulla macchina dove è
stato inizialmente creato. Lo stub passato come parametro inoltra le chiamate
che riceve all'oggetto originale attraverso i meccanismi di comunicazione
di RMI.
In questo modo
un client può trasmettere un proprio stub al server, permettendo
ad esso di invocare i propri metodi. Ma con RMI si possono anche trasmettere
interi oggetti attraverso la rete, con l'unica condizione che siano serializzabili
(per esempio bottoni ed oggetti AWT); questa capacità di migrazione
dinamica del codice, simile al meccanismo delle applet, è una speciale
caratteristica di Java che diviene molto utile nelle applicazioni distribuite.
Si veda [3]
per approfondimenti sull'importante concetto di serializzazione. In un
sistema distribuito un client deve avere modo di trovare i server di cui
ha bisogno; RMI fornisce per questo un naming service, noto anche
come RMI registry, attraverso cui i client possono ottenere gli
stub per un dato server a partire dal nome del server stesso. L'invocazione
del server viene effettuata tramite la sintassi URL RMI, ossia con un'istruzione
del tipo
desiredObject=(cast a desiredObject) Naming.lookup("rmi://ServerHostName:port/oggettoServer"); |
Applicazione
gestionale 3-tier
Come esempio
viene ora descritta un'applicazione di accesso ad un database secondo il
modello three-tier, derivata da quella presentata in [2], il cui
sorgente lo potete torvare sul sito Ftp di Infomedia. Il primo livello
dell'applicazione (client tier) contiene l'interfaccia utente, lo strato
intermedio (middle tier) contiene le regole di accesso ai dati e la definizione
delle interfacce utente possibili, e il terzo livello è costituito
dal database con i dati veri e propri memorizzati su file. Le comunicazioni
fra il livello intermedio ed il database avvengono mediante JDBC, come
in [2]. Per quanto riguarda l'interazione fra client e middle tier,
si vuole realizzare una struttura attraverso cui sia possibile l'invocazione
di metodi remoti. Per meglio comprendere i meccanismi di funzionamento
di tale interazione, vengono presentate due diverse realizzazioni: nella
prima tutti i meccanismi di comunicazione fra oggetti sono costruiti "dal
basso" a partire dai socket, mentre nella seconda viene sfruttato RMI.
L'interazione attraverso metodi remoti suggerisce l'uso del design pattern
Proxy ([4]): si deve cioè costruire un oggetto che faccia
le veci del middle tier entro il client tier e che trasmetta le chiamate
ai metodi attraverso la rete. Per far gestire molti client al middle tier,
seguendo la struttura tradizionale dei programmi client-server di Internet,
ad ogni connessione l'applicazione crea una nuova istanza del middle tier,
seguita dalla creazione di un nuovo oggetto in un thread Java separato.
Pertanto vi sarà un oggetto MiddleTierFactory con cui il
client tier si connette all'inizio e che crea in un thread separato un
oggetto MiddleTier, ogni volta che arriva un nuovo client. Da questo
momento è l'oggetto MiddleTier che serve le richieste del
client, accedendo al database con JDBC ed il MiddleTierFactory rimane
libero per i client futuri. Tale meccanismo è mostrato nella figura
seguente
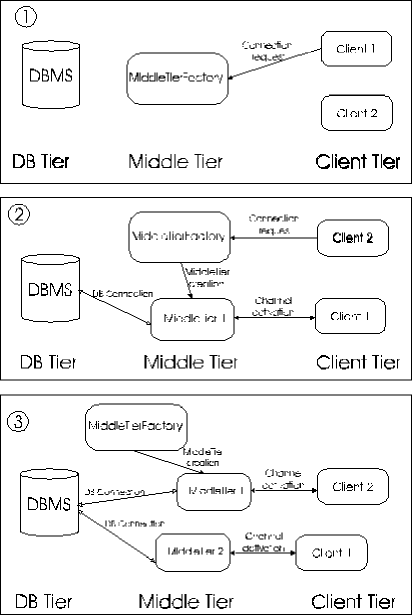 |
| Figura 1 |
Possiamo descrivere
le funzionalità che devono essere accessibili remotamente con due
interfacce Java, riportate di seguito:
interface MiddleTier { |
 |
| Figura 2 |
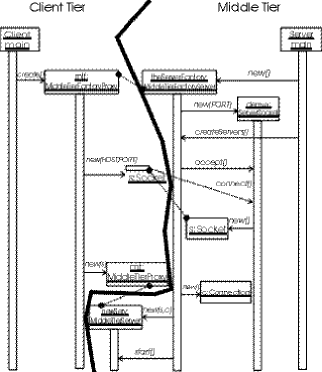
Il client tier
istanzia un MiddleTierFactoryProxy, che si collega via socket al
MiddleTierFactoryServer presente sul middle tier. Quando arriva
il messaggio di connessione le due parti creano le metà corrispondenti
di un nuovo oggetto MiddleTier (MiddleTierFactoryProxy crea
un MiddleTierProxy e MiddleTierFactoryServer istanzia un
MiddleTierServer), che vengono collegate con il socket ottenuto
durante la connessione. Il MiddleTierProxy viene poi restituito
al client, mentre il MiddleTierServer viene lanciato in un thread
separato. Ora ci sono due metà di un oggetto MiddleTier collegate
da un socket ed il client tier ha un riferimento alla sua metà;
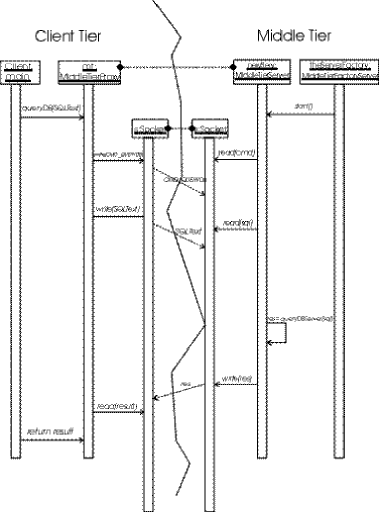
la Figura 3 mostra cosa accade quando il client
chiama mt.queryDB, ossia il metodo che produce l'interrogazione
del database da parte del MiddleTier.
 |
| Figura 3 |
Per prima cosa
la chiamata viene servita dall'oggetto mt di classe MiddleTierProxy,
il quale assembla un messaggio di richiesta e lo spedisce al MiddleTierServer
sull'altra macchina. Questo, ricevuto il messaggio, lo analizza e agisce
a seconda del suo contenuto, cioè effettua la interrogazione del
database tramite il JDBC, poi spedisce indietro il risultato opportuno,
ossia i dati ottenuti dal database, attraverso il socket. La comunicazione
è analoga nel caso del metodo getRule(), con il MiddleTierServer
che stabilisce l'interfaccia appropriata in base alla qualifica trasmessa
come argomento.
Realizzazione
con RMI
La struttura
generale è simile alla versione con i socket, ma in RMI sono già
disponibili molti dei meccanismi che, usando i socket, è stato necessario
implementare esplicitamente nel codice sorgente.
In particolare,
una volta creati i file .class, occorre generare da questi stub
e sketeton con il compilatore rmic. In tal modo i proxy nel codice
non sono più necessari. Le classi contenenti gli stub (aventi nome
nomefile_Stub.class a partire dal file nomefile.class) devono
essere copiate sul client host, mentre le classi contententi gli skeleton
(aventi nome nomefile_Skel) devono stare sul server. Le classi che
hanno originato stub e skeleton devono essere disponibili su entrambi gli
host. Il marshaling automatico evita di scrivere nel codice la conversione
esplicita degli oggetti in dati trasmissibili sul socket. Per questi motivi
il codice della versione RMI risulta più snello. Una volta avviato
l'RMI Registry sul server host ed avviato il MiddleTierServer si
è pronti per rispondere alle richieste dei client. Per la stesura
del codice, poiché RMI specifica i servizi con le interfacce remote,
una soluzione naturale sarebbe definire due interfacce remote come immagine
corrispondente alla interfaccia "originale" presente nel middle tier, come
riportato nel sorgente che segue:
interface MiddleTierRMI extends java.rmi.Remote, MiddleTier {Purtroppo Java vieta di estendere un'interfaccia non remota con una remota e da questo nasce un problema di disadattamento, ossia le classi non possono comunicare a causa delle interfacce diverse. Una soluzione a questo frequente problema è offerta dal pattern Adapter. Si definiscono due classi come segue:
// ...
}
interface MiddleTierFactoryRMI extends java.rmi.Remote, MiddleTiereFactory {
// ...
}
class MiddleTierAdapter implements MiddleTier { |
Si è scritta
una classe MiddleTierAdapter (remota) che incapsula l'oggetto MiddleTierRMI
(non remoto) e una classe MiddleTierFactoryAdapter che incapsula
MiddleTierFactoryRMI. Nel codice precedente non compare per semplicità
tutta la gestione delle eccezioni. Pertanto il funzionamento del sistema
è il seguente: la classe Client dispone, attraverso i suddetti
incapsulamenti secondo il pattern Adapter, di una istanza locale (ovvero
del proxy) sia della classe MiddleTier sia del MiddleTierFactory.
Durante la compilazione vengono generati i "collegamenti" RMI con gli skeleton
che appartengono al package MiddleTier e che sono istanziati entro la classe
servers. All'avvio del client entrambi gli stub sono inizializzati a null.
Durante l'esecuzione, al login il client richiede al naming service di
RMI di poter collegarsi con il server RMI contenuto nel middle tier. In
tale modo viene attivata nel middle tier, con un parametro diverso in funzione
della identificazione avvenuta da parte dell'utente, la classe MiddleTierFactory,
che crea a sua volta un'istanza del MiddleTier con cui il client interagirà
Questo processo
di creazione è sostanzialmente analogo a quello con i socket, rappresentato
in Figura 1. Le comunicazioni esplicite con i socket, rappresentate in
Figura 3, sono ora totalmente trasparenti per il programmatore (a parte
la richiesta iniziale di accesso al server RMI), in quanto avvengono attraverso
i canali interni di RMI, ed il resto del sistema non è cambiato.
Anche in questo caso il server sfrutta il multithreading nativo di Java
e ottiene ogni istanza di MiddleTier in un diverso thread, garantendo le
migliori risorse alle richieste dei client.
Conclusioni:
confronto RMI/Socket
Nell'applicazione
descritta, essendo la trasmissione centrata sui dati, non si ha una necessità
effettiva di comunicare a livello oggetti, ossia di potere trasferire oggetti
generici o invocare metodi remoti. In generale invece ciò può
essere necessario (o quanto meno molto utile), oppure può essere
una evoluzione naturale al crescere della complessità della applicazione
stessa.
Si è
visto quanto implementare una flessibilità di questo genere costi
in termini di codice, avendo solo a disposizione i socket, mentre RMI facilita
notevolmente questo compito.
RMI dispone
di tutti i meccanismi di marshaling necessari per effettuare il trasferimento
di oggetti oltre che di "semplici" dati. Quindi, se occorre trasferire
oggetti o farli interagire fra loro con metodi, non è necessario
dover scrivere esplicitamente tutti i metodi per l'handling di oggetti
di vario tipo. Il compilatore rmic garantisce la generazione automatica
di stub e skeleton, senza che si debba implementare esplicitamente il meccanismo
di proxy e server. RMI consente sia di trasferire lo stub di un oggetto
presente sul server, sia di trasferire oggetti veri e propri (migrazione
del codice). In generale quindi l'approccio garantito da RMI è molto
più object-oriented: le comunicazioni sono "mascherate" ed il programmatore
vede solo oggetti che interagiscono fra loro; alcuni di tali oggetti sono
dei proxy di oggetti remoti. Esistono però anche alcuni svantaggi.
La comunicazione
esplicita tramite socket è più efficiente: anche dovendo
implementare i metodi per il marshaling di alcuni oggetti, si può
ottenere codice più efficiente, a prezzo però di un notevole
impiego di tempo-uomo per la scrittura di meccanismi che RMI rende già
disponibili. Non appena la complessità dell'applicazione (ad esempio
il numero di classi che devono essere trasferite, e quindi il numero di
metodi di marshaling che devono essere scritti) aumenta, l'uso di RMI può
divenire indispensabile. Il maggiore difetto di RMI è il fatto di
essere solo specifico di Java ([5]). Attraverso i socket si possono
ottenere facilmente comunicazioni fra programmi scritti in diversi linguaggi,
come per esempio Java, C, C++ , mentre con RMI tutti i componenti di una
applicazione distribuita devono essere necessariamente scritti in Java.
Per potere disporre di caratteristiche simili a quelle di RMI a fronte
di componenti scritti in linguaggi diversi, occorre usare CORBA ([5]).
Bibliografia
 |
MokaByte Web 1998 - www.mokabyte.it MokaByte ricerca nuovi collaboratori. Chi volesse mettersi in contatto con noi può farlo scrivendo a mokainfo@mokabyte.it |
 |