Continua la
serie sulla progettazione con UML. Stavolta parliamo dei Design Pattern:
un modo di vedere il software in maniera quasi-astratta, parlando per modelli,
cercando di generalizzare e far emergere meccanismi spesso usati ripetutamente
senza rendersene conto (magari ripensandoli ogni volta da capo!).
Pattern alla
crema
Si mangiano?
Cosa saranno mai 'sti Pattern?
Parafrasando
dal libro (vedere bibliografia) si puó dire che i pattern sono semplicemente
"descrizioni di problemi e della loro (possibile, ma non unica) soluzione".
Quando affrontate
un problema software cosa dovete produrre? Dovete disegnare un modello
(un sistema) che rappresenti in una certa misura l'idea che ha in testa
il cliente (se siete fan di Guglielmo Cancelli, costruite qualcosa, non
importa cosa, e poi fate il lavaggio del cervello al cliente ;-). Il mito
del "riuso del software" vorrebbe promettervi che man mano che andate avanti
negli anni vi potete costruire una libreria di SW riutilizzabile per scopi
futuri. In realtá non é infrequente che le uniche cose che
ci si porta dietro tra un progetto e l'altro siano le proprie idee!
I pattern
sono proprio questo! IDEE, meccanismi, strutture ad alto livello, non (necessariamente)
legate a qualche linguaggio di programmazione. Descrivono un problema,
una soluzione e le possibili conseguenze della soluzione
adottata (ho messo i termini usate nel libro in neretto). Nel libro sono
catalogati per tipologia e ogni pattern é documentato stile man
di Unix, io faró un racconto meno sistematico e legando tutto il
discorso all'uso in Java.
Se scorrete
il libro trovate:
_schemi di
classi, per capire il modello in termini dei suoi componenti
_qualche diagramma
degli stati, nei casi in cui é significativo vedere il comportamento
nei dettagli
_pezzi di
codice, benché i pattern possano essere trattati indipendentemente
dal linguaggio di programmazione é anche vero che poi devono essere
implementati per essere utili...
_note
sull'uso e sulla genesi di quel particolare pattern, qui trovate aneddoti
interessanti sui motivi per cui nascono certe scelte tecnologico-design-implementative
Scrivere un pattern
vuol dire soltanto riordinare e formalizzare una propria idea in modo che
sia facilmente riutilizzabile (perché é stata generalizzata)
e facilmente associabile ad un nuovo problema.
Conoscere i
pattern vuol dire sapere che esistono delle analogie tra modelli e che
tali analogie si possono sfruttare per non dover ripensare da capo tutto
ogni volta. É un po' lo stesso discorso (piú ad alto livello)
degli algoritmi: quando dovete scrivere un SORT non vi mettete a pensare
(vero!?), ma allungate una mano verso il Knuth... Idem con i pattern, mentre
progettate un sistema vi accorgete che dovete realizzare ad esempio un
sistema di notifica dei cambiamenti, non vi mettete a pensare, ma allungate
una mano verso il GOF (come é informalmente chiamato il libro) e
cercate un pattern utile (guarda caso esiste: Observer/Observable).
Vediamone qualcuno,
fra i piú semplici, tanto per vedere se é un argomento interessante
come affermo ;-)
Observer/Observable
Vi sono familiari
queste due parole? Se avete usato a fondo Java avrete incontrato queste
due classi (in realtá una é una interfaccia).
Quando vi serve
un meccanismo per cui un oggetto controlla (nel senso di monitoraggio)
lo stato di un altro (esempio classico: un widget di interfaccia utente
che deve aggiornarsi quando l'oggetto che rappresenta cambia stato), ma
il controllato deve sapere il meno possibile del controllante, cosa vi
serve?
Una coppia Observer/Observable!
Questo pattern si chiama anche Publisher/Subscriber... provate a capire
perché... ;-)
La situazione
é questa, facciamo uno scenario ipotetico:
_ho un oggetto
che rappresenta una tabella di dati da visualizzare (potrebbe essere un
foglio elettronico)
_i dati sono
visualizzabili in piú forme (tabella, grafico a torta, istogramma,
funzione, etc.)
_voglio avere
piú "viste" contemporanee
_voglio che
al cambiare dei dati (potrebbero essere dati estratti costantemente da
un sensore, quindi aggiornati in tempo reale) vengano aggiornate
TUTTE le viste attive in quel momento
Voglio troppo? No,
e poi usando questo pattern é veramente semplice da realizzare...
Diciamo che
la tabella dei dati da visualizzare venga chiamata OSSERVABILE (per ora
non sappiamo cosa significa), lei sa solo che se deve notificare un proprio
cambiamento di stato puó mandare un messaggio del tipo: "ehila!
ho cambiato stato!".
Diciamo anche
che ogni widget per rappresentare i dati venga chiamato OSSERVATORE, lui
sa solo che puó ricevere messaggi del tipo di cui sopra e che saprá
chi é il mittente del messaggio.
Se collego opportunamente
le istanze degli oggetti tabella (Observable) con alcune istanze degli
oggetti widget (Observer), a runtime questi si scambieranno messaggi del
tipo: "guarda che ho cambiato stato!" e "ah giá! aspetta che aggiorno
la visualizzazione!".
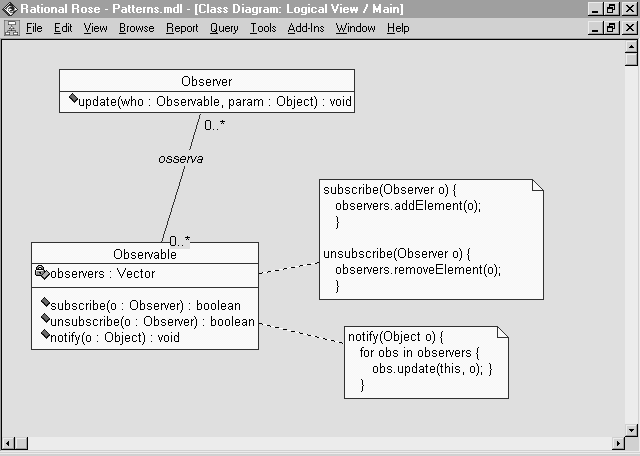
Formalmente:
_l'Observer
deve implementare il metodo update(), cioé deve poter ricevere
il messaggio ("ehila!") dall'Observable
_ogni Observer
si "iscrive" nella lista degli Observer(s) di uno o piú Observable
(infatti un Observer puó monitorare piú Observable), in pratica
deve dichiarare quali gli interessano
_l'Observable
NON SA (e non gli interessa sapere) CHI si é iscritto alla sua lista,
quando cambia stato e decide cha vale la pena farlo sapere in giro, butta
fuori un messaggio di notifica che raggiungerá tutti gli Observer
iscritti in quel momento
Nel caso dei widget
di visualizzazione dati tabellari, proviamo a buttar giú qualche
idea:
_ho una classe
TableData che estende Observable e che magari é un Runnable (cosí
gli faccio fare il polling del sensore da cui estrarre i dati)
_ho una classe
BarGraphView che implementa Observer e che magari é un Component...
_ho una classe
IstogramView che implementa Observer e che magari é un Component...
_ho una classe
GraphView che implementa Observer e che magari é un Component...
Da qualche parte
nel codice basta fare:
TableData t = new TableData(...);
...
BarGraphView b= new BarGraphView(...);
IstogramView i=new IstogramView(...);
GraphView g=new GraphView(...);
Panel p=new Panel(...);
... // aggiungo i Component (le
viste) al Panel
// collego gli Observer all'Observable
t.subscribe(b);
t.subscribe(i);
t.subscribe(g);
...
// non appena t lancia un notify...
b, i e g se ne accorgono...
|
Singleton
e Singleton "esteso"
J. B. Singleton,
un famoso scrittore di libri gialli... no, forse mi sbaglio... Stavo scherzando,
quello che si chiama "Singleton" é uno dei pattern piú semplici
che si possono incontrare. É facile da spiegare e da comprendere
(sempre nell'ottica di "entrare nel giro") e consta, nella versione "base",
di una sola classe.
Quando vi serve
una classe che generi una sola istanza (per singola JVM, ovviamente)
cosa fate? Bé... usate un Singleton. Provate a dargli un'occhio:
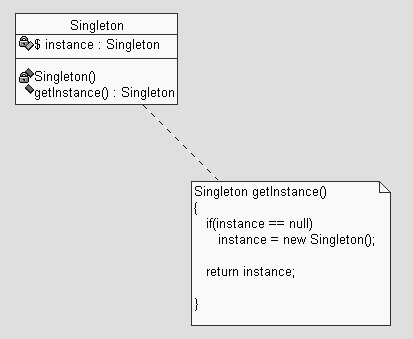
Le sue caratteristiche:
_un Singleton
ha tutti i costruttori privati, infatti non deve essere possibile istanziarlo
a piacere
_ha un attributo
STATICO "a se stesso" (in realtá ad una singola istanza di
se stesso)
_pubblica un
metodo getInstance() che ritorna l'istanza (il reference instance)
Il succo del funzionamento
del Singleton é tutto nell'implementazione del metodo getInstance(),
tale metodo infatti ritorna SEMPRE un'istanza (l'unica) di Singleton, ma
la crea solo LA PRIMA VOLTA CHE VIENE CHIAMATO.
Una prima estensione
del Singleton si ha nel caso in cui si voglia controllare anche l'accesso
all'istanza (per esempio tramite password), basta variare un po' sul tema:
pensate per esempio ad un metodo getInstance(String password) che
prima di effettuare il return controlla se la password passata é
valida...
L'estensione
piú articolata, che io chiamo "Singleton esteso", non la trovate
sul libro dei Pattern, ma la ritengo interessante, soprattutto quando si
ha a che fare con i database. Eccola:

Come funziona?
Il meccanismo é analogo al precedente, solo espanso per gestire
una collezione di istanze, attraverso una Hashtable. il getInstance()
stavolta vuole una chiave di accesso e restituisce l'istanza associata
a quella chiave (istanziando se necessario).
Perché
ho detto che si incontra spesso usando i database? Se le istanze degli
oggetti (di solito ALCUNI oggetti, i piú significativi, non tutti)
sono sincronizzate con un database (cioé lo stato dell'oggetto é
memorizzato in una o piú tabelle del db e ogni modifica sull'oggetto
si ripercuote sul db) é ovvio che sará meglio NON AVERE PIÚ
ISTANZE DI QUEGLI OGGETTI in giro. Facciamo un esempio pratico: un sistema
per modellare una azienda avrá quasi sicuramente una classe Dipendente,
se ho DUE istanze di Dipendente("Mario Rossi - matricola 777") e su una
modifico il livello aziendale mentre sull'altra modifico l'indirizzo, che
succede? Nella peggiore delle ipotesi l'ultimo (oggetto) che si aggiorna
nel DB fa fede, l'altro "ciccia". Nella migliore vengono modificati solo
i valori cambiati, ma poi restano degli oggetti in giro NON AGGIORNATI
COL DB.
A maggior ragione
se ho dei metodi sincronizzati nella classe che sto trattando. I lock sugli
oggetti sono per singola istanza... ;-)
Avere o Essere
?
Se vedete uno
schema del genere e vi dicono di implementarlo in Java, cosa rispondete?
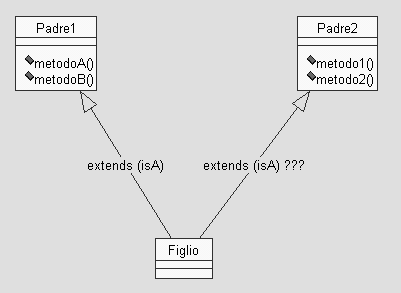
Ereditarietá
multipla? Ma se in Java non c'é! Cosa vai dicendo!
In effetti non
é possibile implementare direttamente (nel senso di una mappatura
1 a 1) in Java lo schema precedente, ma ci terrei a mostrarvi la soluzione
(banalissima quando l'avrete vista!) perché mi serve da spunto per
un certo discorso... e per capire perché questo paragrafo si intitola
cosí!
Lo schema di
soluzione é questo:
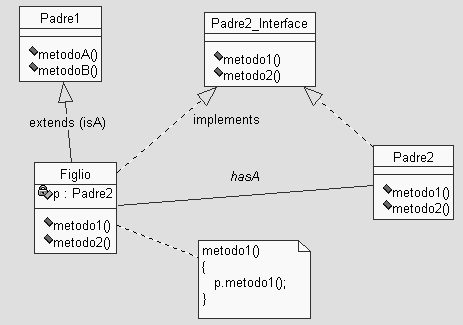
Detto a parole:
_si costruisce
l'interfaccia di una delle due classi che deve fare da padre (e sulla scelta
si apre un commento...), nel senso che la si scrive a partire dalla classe
_sia Padre2
(la classe scelta) che Figlio devono "implementare" l'interfaccia creata
_si aggiunge
un "link" (in questo caso implementato con un reference) tra Figlio e Padre
(notate: Figlio conosce Padre2, ma non viceversa, come é normale
fra classi e superclassi)
_si implementano
"trivialmente" (direbbero gli inglesi) i metodi dell'interfaccia Padre2_Interface
nella classe Figlio, il corpo di ogni metodo non fa che "forwardare" la
chiamata alla classe Padre2 (si puó dire che forwarda il messaggio,
che fa scaricabarile, in senso buono)
Cosí facendo
avremo una classe (Figlio) che al mondo esterno apparirá come "figlia"
di DUE classi contemporaneamente (Padre1 e Padre2). L'interfaccia di Figlio
infatti sará l'unione delle due interfacce e gli utilizzatori della
classe Figlio vedranno accettati (e serviti) tutti i messaggi (o chiamate
di metodi se preferite) compatibili con Padre1 e Padre2. Avremo una classe
"semanticamente" figlia di altre due, mentre "sintatticamente" solo di
una.
Gli "ottimizzatori"
e i puristi ora salteranno su a dire: bé, ma é una soluzione
lenta, si aggiunge uno step all'esecuzione di ogni metodo di Padre2! Io
risponderó: certo che sí, ma in generale anche il normale
meccanismo di binding di un linguaggio a oggetti (non tanto dissimile da
questo!) non é che sia proprio velocissimo... in ogni caso provate
a vedere se vi convince il seguente commento...
Quale delle
due classi taglio? Intendo dire: tra le due che dovrei "estendere", quale
"implemento"? Direi che ci sono almeno TRE "approcci di taglio" che si
possono adottare:
1. SEMANTICO:
fra le due classi padre, qual'é quella che é "piú
padre" dell'altra? Ad esempio: un automobile con le ali é piú
AUTO o piú AEREO? (dovete scegliere voi, dipende anche dal contesto
applicativo). Ovviamente taglio quella "MENO padre"...
2. PRESTAZIONALE:
visto che il meccanismo aggiunge lentezza, quale delle due classi padre
viene "chiamata" piú spesso? Taglio quella meno chiamata...
3.PRAGMATICO:
quale delle due classi ha meno metodi? Voglio scrivere di meno (!!!) e
taglio quella che ha meno metodi...
Dei tre io preferisco
il PRIMO (é il piú coerente con la progettazione a oggetti),
ma ovviamente ogni sviluppatore é libero di scegliere la strada
che gli é piú congeniale.
Il perché
del titolo di questo paragrafo si evince (!!!) giá guardando i due
schemi: siamo passati da una situazione in cui Figlio isA Padre2
ad una in cui Figlio hasA Padre2 (e isA Padre2_Interface),
cioé ad una situazione in cui possedere un altro oggetto permette
di "diventarlo". Naturalmente non mi interessa fare discorsi sul cosa é
meglio (l'Avere o l'Essere), in questo ambito si discute solo sul "cosa
si puó poi realizzare effettivamente".
L'ultima frase
del paragrafo precedente mi permette di agganciare ancora un commento:
quando si progetta con UML (come con altri formalismi similari), non é
detto che ció che si disegna abbia una implementazione straightforward,
immediata, al volo, 1 a 1, etc. Molto spesso il progetto ad alto livello
descrive una situazione astratta (dall'implementazione), é un disegno
che cattura la struttura e la funzione, ma senza entrare nei dettagli (implementativi
appunto) dovuti al particolare linguaggio utilizzato per realizzarlo. Detto
questo, c'é da domandarsi se, progettando, si devono produrre schemi
ad alto o a basso livello (piú o meno vicini a quella che sará
l'implementazione effettiva), la mia risposta é: dipende dal contesto,
a volte é necessario "stare bassi" (vicini all'implementazione),
a volte "stare alti" (macro schema, overview, etc.) e a volte puó
valer la pena produrre entrambi (come se fossero vari livelli di "zoom").
Bibliografia
É pressoché
la stessa dell'articolo precedente (UML e OOP), l'unica ripetizione che
valga la pena fare é:
Design Patterns:
Elements of Reusable Object-Oriented Software by Erich Gamma, Richard
Helm, Ralph Johnson, John Vlissides (Gang Of Four) Addison Wesley
1994
Vorrei citarvi
solo una frase dalla prefazione: "Una parola di incoraggiamento: non preoccupatevi
se non capite completamente questo libro alla prima lettura. Non lo abbiamo
capito nemmeno noi alla prima scrittura!"
L'ho riportata
solo per esemplificare l'atteggiamento degli autori: gioviali, simpatici
e non "sul piedistallo". Il loro intento é quello di raccogliere
le loro esperienze sul riuso del software e trasmetterle. Si rendono conto
che le astrazioni spinte sono a volte difficili da comprendere (soprattutto
per programmatori molto legati ad un linguaggio ;-), ma cercano di mettervi
a vostro agio con molte esemplificazioni e con un linguaggio chiaro (e
con battute di spirito!). Un po' il contrario dell'atteggiamento "se non
capisci sei stupido" di molti informatici d'elite che parlano per
acronimi. ... e, come al solito, cercate su Internet.
|
|
MokaByte Web
1998 - www.mokabyte.it
MokaByte ricerca
nuovi collaboratori.
Chi volesse
mettersi in contatto con noi può farlo scrivendo a mokainfo@mokabyte.it
|
 |
