Nell'articolo
precedente abbiamo cominciato ad esaminare le caratteristiche dei database
a oggetti. In questo articolo concluderemo l'esame generale
e studieremo in modo specifico l'integrazione dei database ad oggetti con
il linguaggio di programmazione ospite.
Nella prima parte
di questa mini serie sui database ad oggetti, comparsa sul numero precedente
di CP, ho esposto le principali caratteristiche di questi e le differenze
fra i database ad oggetti e i database relazionali. In questa puntata concluderò
la panoramica ed esaminerò alcuni problemi inerenti il rapporto
fra persistenza e tipi.
Transazioni
e controllo della concorrenza
Una delle principali
caratteristiche che distingue un database da un sistema per la persistenza
dei dati è che supporta l'accesso da parte di più utenti
simultaneamente. Il problema in questa situazione è di mantenere
l'integrità del database. Questo problema è chiamato "controllo
del concorrenza"; il meccanismo di controllo della concorrenza tipico dei
database è quello delle transazioni.
Per consistenza
di un database si intende assicurare che il suo contenuto rispetti sempre
alcune regole di congruenza stabilite dall'applicazione. È noto
che la consistenza non può essere mantenuta a ogni singola azione
sul database [3].
Ciò che
si può chiedere è che la consistenza valga dopo un gruppo
di azioni che il database considera come un tutto unico. Un tale gruppo
di azioni è chiamato transazione. Una transazione è quindi
un insieme di operazioni che il DBMS tratta come un'entità atomica.
Prima e dopo una transazione si garantisce che il DB è in uno stato
globale consistente. Una transazione ha queste proprietà:
-
è compito
dell'applicazione stabilire quando inizia e quando termina una transazione.
Il database non è in grado di capirlo da solo;
-
una transazione
ha due esiti possibili: commit e abort. In caso di abort è come
se la transazione non fosse mai avvenuta: il database non viene modificato.
In caso di commit tutte le modifiche vengono apportate atomicamente. Sia
il commit che l'abort chiudono una transazione in modo irreversibile.
L'implementazione
di una transazione è del tutto naturale in un'architettura client
server: il client fa tutte le modifiche sulla sua copia locale dei dati
come mostrato in figura 1
| Figura 1:
start e proseguimento di una transazione |
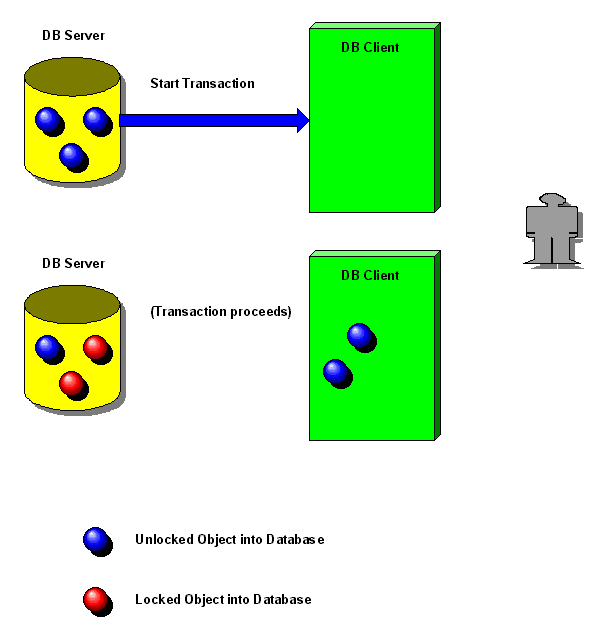 |
Quando ha terminato
felicemente (commit), dà ordine al database di trasferire in una
volta sola tutti i dati modificati sul server (vedi figura 2 ).
| Figura 2:
commit di una transazione |
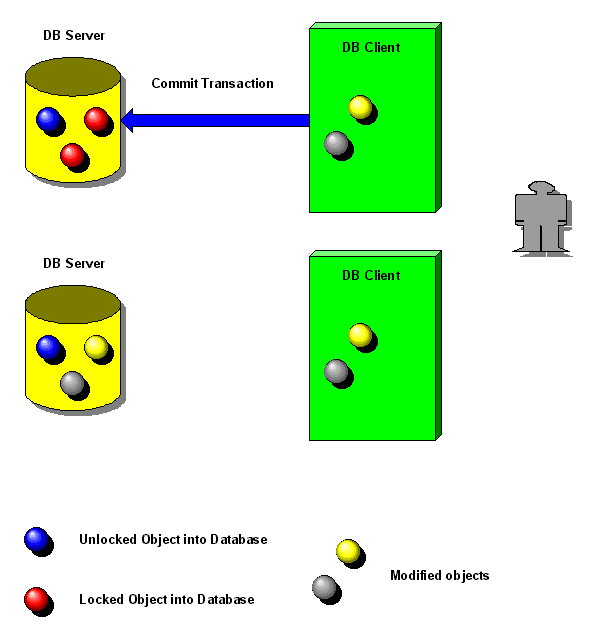 |
|
Se invece il
client chiede un abort, è sufficiente scaricare dalla memoria del
client i dati locali ed eventualmente sostituirli con una copia di quelli
originali, prelevata dal server (figura 3). Le cose si complicano un po'
quando i dati provengono da diversi database, ma esistono algoritmi in
grado di trattare anche questo problema, come il ben noto two phase commit.
| Figura 3:
abort di una transazione |
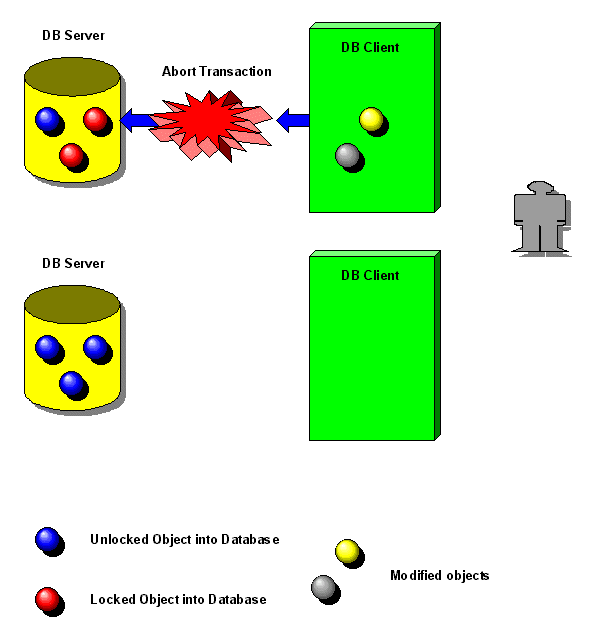 |
|
Un problema un
po' più spinoso è come garantire l'esecuzione atomica di
una transazione anche a fronte di guasti hardware: cosa succede, per esempio,
se il database va in crash dopo avere aggiornato A ma prima di aggiornare
B? Esistono diverse soluzioni a questo problema, diverse per costo ed efficacia
[3], anche se l'unico modo veramente sicuro è ricorrere a soluzioni
hardware (mirroring su dischi RAID). Il database deve dare a un'applicazione
le primitive per eseguire queste operazioni:
-
marcare l'inizio
della transazione (start transaction);
-
indicare al database
su quali dati si intende operare. Una transazione in corso ha diritto di
accesso esclusivo a questi dati (lock); se un'altra transazione cerca di
acquisire gli stessi dati, deve rinunciare oppure attendere che la prima
abbia terminato;
-
segnalare la terminazione
e l'esito della transazione (commit o abort). In ogni caso , la terminazione
della transazione implica il rilascio dei lock.
Per incrementare
il grado di parallelismo si possono distinguere i lock in lettura dai lock
in scrittura; su di un dato possono insistere contemporaneamente un numero
qualunque di lock in lettura ma un solo lock in scrittura. I lock possono
essere acquisiti tutti insieme all'inizio della transazione, oppure uno
alla volta quando se ne presenta la necessità; la seconda soluzione
permette un maggiore grado di parallelismo sul database, ma espone al rischio
di deadlock: il deadlock è la situazione di stallo che si ha quando
si crea una catena circolare di transazioni, ognuna delle quali deve aspettare
che la prossima termini per poter procedere. Una comoda funzionalità
in più è dare la possibilità di fare un commit senza
rilasciare i lock e senza terminare la transazione (checkpoint).
Transazioni
lunghe
Fino ad adesso
ho esposto solo un rapido riassunto del trattamento classico delle transazioni,
quale troviamo nei database relazionali. Cosa cambia in un database a oggetti?
La prima risposta
potrebbe essere: quasi nulla. Anziché mettere il lock su ennuple
e tabelle si mette il lock su oggetti e insiemi di oggetti e il gioco è
fatto. Linguaggi come il C++ offrono anche meccanismi eleganti per rappresentare
le transazioni e trattare le situazioni di emergenza: una transazione può
essere un oggetto locale C++; il commit() è un'operazione sull'oggetto
transazione. Quando una transazione esce di scope senza che sia stato fatto
un commit() si esegue un abort della transazione; in questo modo le eccezioni
C++ lasciano il database senza modifiche.
Ma nelle applicazioni
nelle quali si sono tradizionalmente impiegati i database a oggetti, cioè
prevalentemente applicazioni ingegneristiche e di supporto alla progettazione
(CAD, CAM, CASE, ecc.) il modello transazionale classico è eccessivamente
vincolante.
Ricordiamo che
una transazione blocca l'accesso a tutti i dati che sta utilizzando. Se
una transazione usa molti dati per molto tempo può arrivare a impedire
l'accesso al database a tutti gli altri client (oppure può restare
indefinitivamente in attesa di poter acquisire tutti i lock). È
quindi sottinteso che una transazione classica sia di breve durata. Alcuni
database permettono persino di assegnare un timeout oltre il quale ogni
transazione viene forzatamente abortita, nell'ipotesi che se una transazione
dura troppo vuol dire che il client è caduto oppure è in
deadlock. In ogni caso, una transazione non può mai durare più
a lungo del tempo di connessione di un singolo processo client al database
server (sessione). Per questo motivo le transazioni tradizionale sono chiamate
transazioni corte (short transactions) nella terminologia dei database
ad oggetti.
Se usiamo un
database per memorizzare un disegno CAD e avviamo una transazione appena
un disegnatore apre in scrittura il suo disegno, avremo invece una situazione
in cui la transazione dura per molto tempo, tipicamente per tutta la durata
della sessione. È anche possibile che il disegnatore non riesca
a fare tutte le modifiche in una sola giornata lavorativa. Fare un commit
al termine della sessione vorrebbe dire reimmettere nel database un disegno
incompiuto. I database a oggetti affrontano questa situazione attraverso
il meccanismo delle transazioni lunghe (long transactions).
Una transazione
lunga inizia con un check out degli oggetti su cui si intende operare.
Il termine check out ha esattamente lo stesso significato che nei sistemi
di controllo delle configurazioni, come RCS. Durante il check out gli oggetti
vengono trasferiti dal database server su un database locale al client.
Quindi il client può operare sui suoi dati locali liberamente, per
tutto il tempo che desidera (figura 4).
| Figura 4:
check-in e check-out di transazioni lunghe |
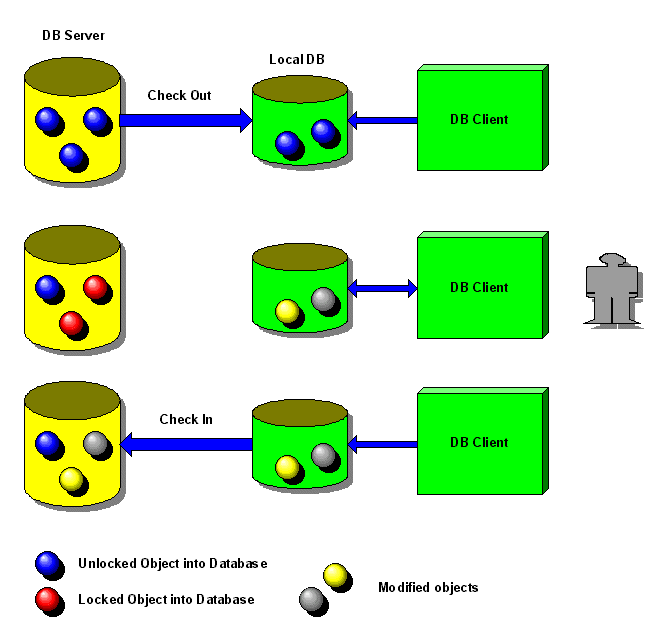 |
|
Una transazione
lunga è a sua volta un oggetto persistente nel database; il database
server tiene traccia di tutte le transazioni lunghe, e per ciascuna di
esse quali oggetti sono stati checked out e a quale client.
Quando un client
termina le modifiche, può eseguire un check in, che consiste nel
riportare indietro i dati sul database server, oppure chiedere l'abort
della transazione lunga.
All'interno
di una transazione lunga il client ha ancora la possibilità di eseguire
delle transazioni corte, soprattutto nel senso di eseguire dei checkpoint
oppure degli abort: queste operazioni implementano le funzioni di "Save"
e di "Undo" degli strumenti di disegno.
I dati checked
out tipicamente sono bloccati; ma è anche possibile permettere che
un oggetto venga checked out da più clienti contemporaneamente;
in questo caso il database deve offrire un sistema per la gestione delle
versioni e soprattutto un modo di riconciliare le versioni. Non molti database
a oggetti supportano la gestione delle versioni; quasi tutti però
supportano i dirty read: si ha un dirty read quando un client apre in scrittura
un oggetto, ma impone solo un read lock. Questo rende possibile ad altri
client leggere quell'oggetto, anche se esiste la possibilità che
cambi valore in seguito a una commit. I database che supportano i dirty
read danno la possibilità ai client di avere gli oggetti aperti
in dirty read automaticamente sincronizzati sulla loro master copy nel
database server mediante un meccanismo di notifiche e update più
o meno automatizzato; in alternativa, un client può periodicamente
chiedere l'aggiornamento (refresh) dei suoi dati al database server. Nel
mio articolo su Poet apparso sullo scorso numero di CP ho fatto vedere
un esempio di dirty read/refresh sul database a oggetti Poet; Poet, che
pure è uno dei database a oggetti più semplici ed economici,
supporta anche un meccanismo automatico di notifica e update. I database
a oggetti heavy weight supportano anche il versioning.
Il meccanismo
delle transazioni lunghe richiede che il client abbia le risorse di calcolo
necessarie a memorizzare e a gestire un piccolo database locale, ma questo,
con i Pentium venduti al supermercato, non è certo più un
ostacolo. Si deve piuttosto notare che le interazioni fra database locale
e database centrale in presenza di transazioni lunghe sono veramente semplici;
tutta la ricchezza delle funzionalità di un database a oggetti in
fatto di query e di integrazione con il client si concentra nel database
locale. Questo ha suggerito ad alcuni di usare come database server centrale
un database relazionale tradizionale, p.e. Oracle, di cui si vogliono sfruttare
le capacità di gestire in modo affidabile enormi quantità
di dati e l'interoperabilità con gli altri database relazionali.
Sulle stazioni locali di lavoro invece sono stati usati dei database a
oggetti, di cui si apprezzano l'efficienza e l'integrazione con un linguaggio
di programmazione a oggetti (figura 5).
| Figura 5:
architettura mista di database relazionale e a oggetti |
|
|
Il database centrale
viene trattato come la risorsa di backup e come un repository di dati corporate
(che spesso è un modo gentile di dire legacy); a intervalli regolari,
p.e. tutte le notti, i dati vengono copiati dai database a oggetti locali
al database centrale. Il mapping degli oggetti su tabelle relazionali ha
i soliti inconvenienti che già conosciamo, ma in questa architettura
ciò ha poca importanza perché i client vedono un database
a oggetti; il mapping perciò può essere affidato a uno strumento
CASE.
Questa soluzione
è stata adottata in alcune applicazioni bancarie di grandi dimensioni
e, secondo me, rappresenta un buon modo di integrare la tecnologia dei
database a oggetti in un ambiente relazionale.
Integrazione
con il linguaggio di programmazione
Tutto bene quindi?
Basta usare un ODBMS ed è la fine di tutti i problemi?
Se fosse così,
a quest'ora i RDBMS dovrebbero essere solo un ingombrante ricordo del passato.
Invece nuove applicazioni con RDBMS nascono tutti i giorni, senza che si
tratti solo di problemi di legacy o di riciclaggio di programmatori assuefatti
al COBOL.
Nell'avvicinarci
agli ODBMS ho seguito la strada di un tipico programmatore a oggetti. Un'altra
strada è quella del programmatore di applicazioni database. Purtroppo,
queste due categorie di utilizzatori hanno esigenze molto diverse.
Per un programmatore
a oggetti i problemi principali sono la persistenza, la gestione di basi
dati più grosse della memoria disponibile e l'efficienza nell'accesso.
Il database ideale è quello che non si vede: il programmatore vuole
potere usare il proprio prediletto linguaggio di programmazione, senza
passare per un altro linguaggio come SQL, e soprattutto non vuole differenze
fra i dati persistenti e quelli "transienti", cioè i normali dati
del suo programma.
Il programmatore
di database è invece disponibile a compromessi sul piano dell'efficienza
e della trasparenza in cambio di altre funzionalità: per esempio,
l'indipendenza dall'architettura della macchina, la possibilità
di eseguire interrogazioni, controlli di integrità, funzioni di
gestione e controllo degli accessi. Queste funzioni non hanno corrispettivo
nei linguaggi di programmazione, perciò è necessario estendere
in qualche modo il linguaggio di programmazione - ma estendere è
sinonimo di "farne un altro". Tutti i database a oggetti devono affrontare
questa contraddizione.
Non distinguere
i dati persistenti da quelli non persistenti vuol dire che la persistenza
non è associata al tipo di un dato. In termini tecnici, si dice
che "la persistenza è ortogonale al tipo"; imparate questa frase
e di esercitatevi a declamarla con espressione convinta e assorta. Fa fare
bella figura e scoraggia qualsiasi domanda, comprese quelle che potrebbero
rivelare che non vi ricordate cosa vuol dire, specie se assumete l'aria
un po' mesta di chi riferisce di una disgrazia ineluttabile, del tipo "tutte
le cose belle finiscono" o "mi è morto il gatto": così chi
vi ascolta non vi rattristerà ulteriormente con altre domande su
questo doloroso argomento. E quanto l'argomento dell'ortogonalità
sia doloroso per gli ODBMS lo vedremo fra poco.
Quale tipo
per gli oggetti persistenti?
La caratteristica
di un database è di rendere persistenti i dati. Il problema è
che i linguaggi di programmazione non hanno dati persistenti. I possibili
tipi di vita di un dato in un linguaggio di programmazione sono:
-
dati automatici
(parametri e variabili locali di una funzione): esistono per tutta la durata
della funzione a cui appartengono;
-
dati statici: esistono
per tutta la durata del programma a cui appartengono;
-
dati allocati dinamicamente:
la loro vita è determinata esplicitamente tramite operazioni di
allocazione e disallocazione, ma non può estendersi oltre la durata
del programma cui appartengono;
Se usiamo un DBMS
si aggiunge un nuovo tipo di vita:
-
dati persistenti:
la loro vita è determinata esplicitamente tramite operazioni di
allocazione e disallocazione e può estendersi oltre la durata del
programma cui appartengono.
Ci sono due modi
fondamentali per inserire i dati persistenti in un linguaggio di programmazione:
-
usare tipi di dati
distinti per i dati persistenti e per quelli non persistenti.
-
usare gli stessi
tipi di dati per i dati persistenti e per quelli non persistenti;
Il primo approccio
è quello dei DB relazionali, di cui abbiamo già detto tutto
il male possibile. Il secondo è quello della persistenza ortogonale
al tipo (visto come suona bene?). L'ortogonalità, come abbiamo visto,
è particolarmente apprezzata dai programmatori. Dire che la persistenza
è ortogonale al tipo implica la possibilità di avere un'istanza
non persistente, cioè transiente, di un tipo che ha anche istanze
persistenti. Questa sembra una conseguenza innocua, anzi utile perché
permette di costruire copie locali e temporanee di oggetti del database.
Infatti quasi tutti i database a oggetti permettono di costruire istanze
temporanee di classi persistenti e perciò dicono di supportare la
persistenza ortogonale al tipo.
La questione
è che chi usa un database non si accontenta della persistenza, se
no non avrebbe usato un database, ma un semplice file ISAM. Un database
a oggetti che si rispetti deve almeno fornire dei meccanismi per :
-
rappresentare e
mantenere le relazioni bidirezionali;
-
permettere query
sui dati;
-
le query devono
essere rapide, cioè devono essere risolte possibilmente senza scandire
uno per uno tutti i candidati;
Integrare queste
funzionalità in un linguaggio di programmazione, che non dispone
né di relazioni né di linguaggi di query, è un bel
grattacapo. Ci sono diverse soluzioni, le stesse che si usano per i relazionali:
-
si estende il linguaggio
con nuove keyword. Solo a sentire questa ipotesi i programmatori cominciano
a digrignare i denti: "come se il C++ non avesse già abbastanza
keyword !". Allora si tiene il linguaggio così com'è e:
-
si usa una API.
Peccato che una query SQL/OQL espressa come una serie di chiamate a una
API abbia la leggibilità del sanscrito. Allora si tiene la API ma:
-
si usa un preprocessore,
che traduce le query in chiamate alle API. È solo un palliativo:
il sanscrito salta fuori non appena si usa il debugger. Per di più,
spesso e volentieri il preprocessore riconosce solo un sottoinsieme del
linguaggio di programmazione. Tipici sono i preprocessori di query per
C++ che non riconoscono i template, le eccezioni e i namespace. Allora
si tiene la API, si butta via il preprocessore e:
-
si passano le query
come stringa a una funzione della API, chiamiamola ExecQuery(<string>).
A questo punto abbiamo toccato il fondo dell'abiezione perché trattiamo
il DBMS come un interprete. Poiché i tempi di esecuzione con questo
meccanismo si avvicinano ai tempi di una ricerca su Internet, si mette
un'inserzione sul giornale per cercare un bramino capace di programmare
il sanscrito della API del database.
Resta ancora il
problema della dichiarazione del modello dei dati: quali siano gli oggetti
persistenti, quali le relazioni e gli indici, eccetera. Alle quattro possibilità
di cui sopra se ne aggiunge un'altra, ancora più abominevole delle
query scritte nelle stringhe: la convenzione. Vuol dire che si usa uno
dei meccanismi nativi del linguaggio per segnalare di nascosto a un preprocessore
cosa si vuole fare e che non si potrebbe descrivere nel linguaggio. Per
esempio, si può seguire la convenzione che tutte e sole le classi
derivate da una classe certa base, diciamo Persistent_Object, debbano avere
un corrispettivo nel database. Oppure la convenzione che un certo template
indichi un estremo di una relazione. Devo riferire che qualcun altro sostiene
che non si tratta di turpe abominio, ma di un uso elegante, anzi poetico
del linguaggio di programmazione, perché gli si fa dire "fra le
righe" qualcosa che il linguaggio da solo non sarebbe stato capace di esprimere.
Risolto (si fa per dire) il problema delle query e della dichiarazione
dello schema, resta la questione della persistenza ortogonale al tipo:
-
i tipi noti al database,
come abbiamo appena visto, hanno una nutrita serie di interessanti proprietà;
-
ci sono, di questi
tipi, istanze temporanee, cioè sconosciute al database;
-
in virtù
dell'ortogonalità, anche queste istanze devono godere delle proprietà
delle istanze permanenti.
Pensiamo per esempio
a una query. Per accelerare la query il database può usare un indice.
Ma dovrebbe mettere nell'indice anche le istanze temporanee? Alcuni database
rinunciano a considerare gli oggetti temporanei nelle query. Altri rinunciano
agli indici. Qualcuno rinuncia alle query e lascia che se la sbrogli l'applicazione.
> E ancora: come fa il database a salvare oggetti persistenti che contengono
riferimenti a oggetti temporanei? Le risposte normali sono: proibire di
mettere riferimenti a oggetti transienti in oggetti persistenti (chiamala
ortogonalità!); lasciarli mettere, ma annullare silentemente quando
si salva l'oggetto persistente; rendere automaticamente persistente ogni
oggetto transiente referenziato da un oggetto persistente, così
da poterlo salvare. Quest'ultima soluzione sembra la più vantaggiosa,
ma ha un inconveniente: cosa succede se l'oggetto transiente ha una vita
limitata, per esempio se è una variabile automatica?
Il quesito ci
porta a una domanda ancora più importante, filosofica direi, visto
che parla della vita e della morte. Quando nasce un oggetto persistente
lo sappiamo: bisogna fare il new. Quand'è che muore? Alcuni propendono
per legare la vita di un oggetto nel database alla vita della sua controfigura
nella memoria dell'applicazione. Se per creare un oggetto si fa il new,
per distruggerlo si fa delete. Altri intendono che delete serva solo per
rimuovere un oggetto dallo spazio dati di un'applicazione, quando non serve
più; un oggetto persistente viene cancellato solo chiamando un metodo
speciale di destroy. Per la cronaca, ODMG propende per la prima alternativa,
il modello OMG di CORBA per la seconda, nonostante i due enti proclamino
di adottare lo stesso modello di oggetti. La prima soluzione sembra più
logica dal punto di vista del C++, ma la seconda è più facile
da applicare ai linguaggi dotati di garbage collection (GC), come Java
e Smalltalk: in questi linguaggi la delete è sostituita effettivamente
dalla GC, che rimuove gli oggetti non più referenziati. Il problema
è che in un database si può raggiungere un oggetto anche
quando non è più referenziato da nessuno: basta fare una
query. Gli oggetti persistenti devono perciò essere sottratti alla
GC e devono essere cancellati in modo esplicito. Ma allora chi cancella
le istanze temporanee dei tipi persistenti? Cancellare in modo esplicito
un oggetto temporaneo è esattamente il contrario di quanto uno si
aspetta di fare in un linguaggio dotato di GC; lasciare che la GC cancelli
gli oggetti temporanei, ma non quelli persistenti viola l'assunto dell'ortogonalità.
Altre domande
ancora più intriganti nascono quando consideriamo altre funzionalità
tipiche dei database: per esempio, le transazioni. Cosa succede quando
una transazione abortisce? Se la persistenza è ortogonale al tipo,
il database dovrebbe ripristinare lo stato di tutti gli oggetti coinvolti
nella transazione: compresi quelli transienti. In pratica nessun database
a oggetti tiene conto degli oggetti transienti nelle transazioni, con conseguenze
sull'allineamento fra i dati transienti e quelli persistenti che è
facile immaginare.
Ancora un argomento
sul quale riflettere: cosa succede agli oggetti transienti quando cambia
lo schema? Nei linguaggi di programmazione come il C++ il problema non
si pone perché non si può cambiare il tipo dei dati mentre
il programma sta girando. In un database invece si deve poter cambiare
il tipo di un dato senza spegnere il database, anzi ci si aspetta che il
database sia capace di convertire le istanze di quel tipo. Quasi tutti
i database a oggetti supportano la modifica in linea dello schema. Dovrebbe
il database convertire anche le istanze transienti? Questo può richiedere
di modificare la dimensione delle istanze ed è quindi impossibile
in linguaggi come il C++, perché alcune istanze possono trovarsi
nel bel mezzo dello stack. Per altri linguaggi, come Java e Smalltalk,
la conversione è possibile perché tutti gli oggetti sono
sullo heap, anzi in Smalltalk la modifica e run time delle classi è
prevista esplicitamente dall'ambiente di programmazione: un programmatore
Smalltalk non starebbe d'accordo se il suo database a oggetti gli impedisse
di fare sulle classi persistenti ciò che è abituato a fare
sulle classi non persistenti solo perché in C++ non si può
fare. Questo dovrebbe mettervi sull'avviso quando sentite parlare di database
a oggetti "language independent".
Altri esempi
di divergenze fra il punto di vista dei linguaggi di programmazione e quello
dei database sono riportati in [4]. Riassumendo, l'ortogonalità
fra tipo e persistenza è una cosa bellissima da dire, ma impossibile
da implementare fino in fondo.
I database a
oggetti reali si dispongono in diversi punti lungo la linea ideale che
va dai sistemi di persistenza ai "veri" DBMS; a un estremo troviamo ObjectStore,
che assomiglia a un sofisticato e super efficiente sistema di persistenza
basato sulla gestione della memoria virtuale; all'altro estremo troviamo
i database object-relational. Più o meno in mezzo al guado ci sono
la maggior parte dei restanti database a oggetti, compreso il modello standard
di database a oggetti ODMG.
Prestazioni
di un database
Il confronto
fra le prestazioni dei database a oggetti è un campo delicato. A
seconda delle situazioni, un database a oggetti può fornire prestazioni
ottime oppure deludenti. Esistono delle test suite standard, fra cui le
più note sono chiamate OO1 e OO7.
OO1 risale alla
fine degli anni 80 e aveva in origine lo scopo di studiare le differenze
di prestazioni fra database relazionali e database a oggetti in applicazioni
ingegneristiche interattive. Ciò che in effetti dimostrò
OO1 fu che i database a oggetti sono in grado di sfruttare molto meglio
dei database relazionali l'architettura dei sistemi su cui si trovano queste
applicazioni: client su workstation con buone risorse di RAM e di disco,
che accedono in modo intenso e per lunghi periodi a porzioni relativamente
limitate (4-40 Mb) del database. In queste situazioni la cache locale di
oggetti dei database a oggetti e l'accesso navigazionale agli oggetti fanno
miracoli rispetto ai database relazionali. OO1 non era stato studiato per
confrontare fra loro database a oggetti; è stato molto usato in
questo ruolo perché è semplice da implementare e da eseguire.
OO7 è
stato studiato per misurare le prestazioni dei database a oggetti in una
varietà di situazioni. Ha alcuni inconvenienti, fra cui il fatto
che è lungo da implementare e da eseguire e che fornisce moltissimi
dati che sono poi difficili da aggregare. Ciò che realmente mette
in evidenza OO7 è che non si può dire che un database a oggetti
abbia migliori prestazioni di un altro, almeno non nel senso in cui si
misurano le TPS (Transazioni Per Secondo) di un relazionale. Le prestazioni
di un database a oggetti dipendono in misura determinante da come è
stato usato dall'applicazione.
Rimando a [9]
per ulteriori approfondimenti sui benchmark standard. Preferisco invece
esaminare in dettaglio la principale categorizzazione architetturale dei
database a oggetti: la distinzione fra page server e object server. ObjectStore
e O2 sono tipici page server; Objectivity/DB e Poet sono object server.
Ognuno di questi due tipi di data base è adatto ad essere usato
in situazioni e in modi peculiari; le prestazioni saranno ottime o pessime
a seconda che si rispettino o no le caratteristiche del database.
Un page server
fornisce ai clienti pagine di memoria virtuale contenenti oggetti. Un object
server fornisce ai clienti oggetti singoli. Un page server fornisce pagine
di memoria, che di solito contengono ciascuna una certa quantità
di oggetti. In apparenza un object server dovrebbe essere sempre avvantaggiato,
perché trasferisce al client solo gli oggetti di cui ha bisogno,
mentre un page server trasferisce un'intera pagina anche quando il client
ha bisogno di un solo oggetto all'interno di quella pagina. In realtà
non sempre gli object server sono avvantaggiati.
È improbabile
che un'applicazione usi un solo oggetto alla volta.
Gli oggetti
tipicamente vivono in gruppi, con forti interazioni all'interno del gruppo
e poche al di fuori (si veda R.Martin [10] per questa caratteristica delle
architetture a oggetti e per le sue conseguenze sulle metriche di qualità
del software). Con un page server, se si usa una politica intelligente
di clustering, sia il numero di accessi al disco sul server che il numero
di trasferimenti di oggetti fra client e server risulta ridotta rispetto
a un object server. Inoltre, poiché il server di un page server
tiene traccia delle pagine trasferite nel client e non dei singoli oggetti,
consuma meno spazio in memoria. Questi vantaggi si perdono se il client
accede a oggetti molto dispersi; spesso però una buona politica
di clustering è semplicemente di raggruppare nella stessa pagina
gli oggetti collegati da relazioni di contenimento nel modello informativo.
Nei page server
le query devono essere processate sui client, mentre negli object server
le query possono essere processate sia sui client che sul server per ridurre
il traffico di rete. I page server sono quindi consigliabili quando ha
senso demandare molto lavoro al client, quando, cioè, il client
medio ha una notevole potenza di calcolo ed è collegato al server
su linee ad alta velocità. Per contro, un object server è
consigliabile quando il client è limitato (p.e. un PC) e/o la connessione
avviene su linee intasate o lente.
Un inconveniente
dei page server è che anche la granularità dei lock transazionali
è a livello di pagina: non si può mettere il lock su un oggetto
senza metterlo su tutti gli oggetti della pagina su cui risiede. A seconda
delle situazioni questo può essere un handicap o un vantaggio: in
alcuni casi riduce il grado di concorrenza e quindi le prestazioni, in
altre il lock a livello di pagina è vantaggiosa perché risparmia
di mettere lock singoli su un grande numero di piccoli oggetti. Questo
caso si verifica, ancora una volta, quando si fa accesso a pochi cluster
di dati; il caso opposto corrisponde di più alle condizioni d'uso
di un database relazionale. Le applicazioni che ricercano su ampie porzioni
del database, come i Decision Support Systems, fanno meglio a orientarsi
sugli object server. Infine, i page server supportano meglio la tecnica
del pointer swizzling; gli object server si coniugano meglio con i tradizionali
smart pointer.
La tecnica degli
smart pointer è ben nota ed è facile da implementare [5],
ma impone un overhead su ogni accesso ai dati. L'overhead è trascurabile
per applicazioni che cambino frequentemente i dati a cui accedono, perché
viene nascosto dal ben maggior overhead di accesso al server; può
essere meno trascurabile su applicazioni che, dopo aver prelevato i dati,
li mantengono a lungo in memoria per eseguire intense manipolazioni.
La tecnica del
pointer swizzling è stata descritta in [6]. È adottata da
diversi ODBMS di pubblico dominio, come Texas Persistent Store o Exodus,
e da un unico database commerciale: Object Store. Si tratta di una tecnica
molto efficiente e senza alcun overhead quando l'oggetto persistente è
già nella memoria del client.
Il funzionamento
di base è questo: l'intero database a oggetti viene trattato dal
server come un'area di memoria virtuale. Gli indirizzi degli oggetti sono
indirizzi in quest'area di memoria virtuale.
Quando una pagina
di oggetti viene portata nella memoria di un client, il database la scandisce
per cercare tutti i riferimenti a oggetti. Se il runtime del database trova
un riferimento a un oggetto non ancora in memoria, alloca un indirizzo
non ancora usato nella memoria del client e lo sostituisce al riferimento
ad oggetto, ma senza allocare memoria in modo che, quando questo riferimento
verrà dereferenziato, produrrà un page fault. Il procedimento
di sostituzione dei puntatori viene chiamato "pointer swizzling". Quando
il client dereferenzierà questo indirizzo, il sistema operativo
genererà un page fault, che verrà intercettato dal run time
del database e trasformato in una richiesta di pagina al page server. Successivi
riferimenti allo stesso indirizzo troveranno la pagina già in memoria.
Anche la nuova pagina viene scandita alla ricerca di indirizzi di oggetti
non ancora in memoria, e così via. Poiché tutto avviene come
parte del processamento di un page fault, l'intera tecnica è chiamata
"pointer swizzling at page fault time".
L'elemento cruciale
di questa tecnica è sapere riconoscere in modo efficiente e sicuro
gli indirizzi di oggetti in una pagina. Ciò è semplice in
architetture tagged come Lisp o Smalltalk, mentre lo è meno in architetture
come quella del C++. Della tecnica usata da Object Store si sa solo che
è simile a quelle impiegate nella garbage collection [7], ma i dettagli
non sono documentati e sono protetti da brevetto.
Un altro fattore
che influenza fortemente le prestazioni di un database sono gli indici.
Tutti i database, naturalmente, danno la possibilità di stabilire
indici su attributi, ma ci sono due possibilità a seconda che un
indice contenga o no anche gli oggetti delle classi derivate. Entrambe
le scelte hanno pregi e difetti; rimando a [8] per ulteriori ragguagli.
Conclusioni
Il maggiore svantaggio
degli ODBMS rispetto ai RDBMS è la mancanza di interoperabilità
reciproca. In effetti, gli ODBMS sono stati impiegati in settori in cui
l'interoperabilità non è un requisito importante, anche se
non è chiaro se questa sia più una causa o un effetto. Quasi
tutti gli ODBMS supportano invece un qualche gateway verso il modello relazionale:
perciò è possibile trasformare gli oggetti di un database
a oggetti in tabelle, importarli in un altro database a oggetti e poi di
nuovo trasformarli in oggetti; la maggior parte degli ODBMS hanno anche
dei tool per eseguire il mapping da e verso SQL in modo automatico.
Il fatto che
due database a oggetti si parlino fra di loro solo passando per un modello
relazionale può sembrare un controsenso, ma ha una motivazione profonda:
un oggetto incapsula uno stato (attributi) e un comportamento (metodi),
ma i database a oggetti per lo più sono in grado di memorizzare
solo lo stato e non il comportamento (cfr. [2]).
Il comportamento
degli oggetti di un ODBMS nella quasi totalità dei casi si trova
in librerie che vengono linkate all'applicazione client. Qualche database
usa librerie dinamiche (DLL su Windows, .so su Solaris) trasferite via
NFS dal server al client, ma si tratta solo di una variazione di implementazione.
Quando si trasferisce
un oggetto da un database a oggetti a un altro si può quindi trasferire
solo lo stato degli oggetti; passare per una tabella relazionale mette
in evidenza che l'unica parte di un database a oggetti che si può
condividere fra diversi ODBMS è quella che è possibile trasformare
in tabelle, cioè lo stato. Ciò che si ottiene dopo aver trasferito
un oggetto a un altro database è un oggetto che magari ha lo stesso
stato ma metodi diversi, cioè un altro oggetto.
Un problema
simile è quello di trovare un analogo delle stored procedure dei
database relazionali. Gli ODBMS in grado di eseguire metodi degli oggetti
persistenti sul server sono chiamati "database attivi" (gli altri, evidentemente,
sono database passivi). Ci sono degli ODBMS attivi: per esempio Itasca
e Gemstone, ma sono entrambi prodotti di nicchia: il primo è un
database per Lisp e il secondo è un database per Smalltalk. È
proprio il fatto di appoggiarsi a linguaggi interpretati che dà
loro la capacità di eseguire metodi sul server.
Le cose potrebbero
cambiare con Java, perché un oggetto Java può veramente essere
memorizzato in modo portabile su di un database, codice compreso, ed essere
quindi eseguito su qualsiasi client o server. Sono in corso ricerche molto
interessanti su questo argomento, ma non aspettatevi risultati immediati:
l'ortogonalità di tipo e persistenza è sempre in agguato.
Bibliografia
[1] Mary E.S.
Loomis, "OODBMS : The ODMG Object Model", JOOP, June 1993, 64-69.
[2] Jonathan
Wilcox, "Object Databases", Dr. Dobb's Journal, Nov. 1994, 26-34.
[3] Mary E.S.
Loomis, "Database Transactions", JOOP, Sept/Oct 1990, 54-61.
[4] Mary E.S.
Loomis, "Object Programming and Database Management", JOOP, May 1993, 31-34,
67.
[5] Danilo Dabbene
e Silverio Damiani, "Adding Persistence to Objects Using Smart Pointers",
JOOP, June 1995, 33-39.
[6] Kumar Vadaparty,
"Pointer Swizzling at Page-Fault Rime", JOOP Nov-Dec 1995, 12-20.
[7] Paul R.Wilson
et al., "Dynamic Storage Allocation : a Survey and Critical Review", Proc.
1995 Int.l Workshop on Memory Management, Kinross, Scotland, UK: Springer
Verlag.
[8] Won Kim,
"Architectural Issues in Object-Oriented Databases", JOOP March/April 1990,
29-38.
[9] Akmal Chaudri,
"Object DBMSs: To Benchmark or not to Benchmark?", Object Magazine, July
1996, 76-80.
[10] Robert
Martin, "Designing Object Oriented Applications Using the Booch Method",
Prentice Hall, 1995. |


