| Molto
spesso avrete avuto bisogno di un numero n di oggetti assolutamente identici
da usare nella vostra applicazione. Quando parlo di oggetti identici intendo
n istanze di una classe di cui si ha bisogno più volte, da parte
di diversi thread, nel corso dellesecuzione del programma, senza che vi
sia la necessità di modificare gli attributi della classe stessa.
Facciamo un esempio:
public
class ClasseQualsiasi {
private
String attributo1 = "";
private
int attributo2 = 0;
public
ClasseQualsiasi(String att1, int att2){
attributo1 = att1;
attributo2 = att2;
}
/*codice
.........................................
*/
}
Se
noi facciamo n istanze di ClasseQualsiasi(miaStringa,mioIntero) sempre
con gli stessi parametri passati al costruttore, ovvero se usiamo i metodi
della classe per impostare gli attributi sempre con gli stessi valori,
allora a volte è più desiderabile costruire prima gli oggetti
che ci servono e metterli in attesa allinterno di un contenitore. Quando
ci occorre, possiamo prelevare un oggetto dal contenitore, eseguire un
locking su di esso, usarlo e rimettrelo a disposizione di altri processi.
Se ClasseQualsiasi esegue operazioni complesse, come ad esempio una connessione
con base dati, che notoriamente è unoperazione dispendiosa in termini
di tempo e prestazioni (time consumig), allora la scelta di creare prima
e una volta sola i suoi oggetti diventa quasi obbligata, se vogliamo scrivere
un programma che abbia le migliori prestazioni. Inoltre, ci sono dei casi
nei quali lunica tecnica valida per fare qualcosa è proprio quella
dellobject pooling (ad esempio nel caso di servlet che devono connettersi
a basi dati).
Possiamo
quindi affermare che ci sono due fondamentali motivi per cui dovremmo scivere
un pool di oggetti:
-
Per migliorare
la performance della nostra applicazione
-
Per controllare
laccesso a risorse che sono limitate, e quindi gestirne luso.
La creazione
di un pool di oggetti è una delle migliori esercitazioni di scrittura
Object Oriented, e deve rispondere, a mio parere, ad alcuni requisiti:
-
Gli oggetti
che scriviamo devono essere riusabili (mi rendo conto che non è
una bella parola
)
-
Laccesso
agli attributi deve essere protetto, e deve essere filtrato da appositi
metodi
-
I metodi
suddetti devono ottenere un monitor sulloggetto, e quindi essere dichiarati
synchronized
NOTA:
un monitor è un oggetto che controlla laccesso ad una procedura,
cioè nel caso di Java ad un algoritmo contenuto in un metodo. Quando
un metodo è gestito da un monitor (quando cioè il metodo
viene dichiarato synchronized) questultimo consente ad un solo thread
alla volta di accedere ad esso. Quando il thread che sta eseguendo il metodo
finisce il suo lavoro, tutti gli altri thread in attesa vengono risvegliati
(avete presente notifyAll() ?) ed il monitor decide quale degli n thread
in attesa ha diritto di eseguire il metodo. Questa scelta dipende dalla
VM, che ha un comportamento diverso su piattaforme Unix e Win32 (anche
perché la gestione dei thread da parte della VM dipende comunque
dal sistema operativo). Comunque sarà solo uno il thread fortunato,
e la sua scelta sarà sempre gestita secondo gli stessi criteri,
ad esempio sempre FIFO (First In, First Out, che credo sia lo standard
per le VM sotto Sparc e Win32), oppure sempre LIFO (Last In, First Out).
Un
pool è costituito da un insieme non ordinato di sitanze dello stesso
oggetto. Lutilità come singoli oggetti di queste istanze non dipende
dal valore dei loro attributi, ma dal fatto sono uguali luno allaltro.
Nel caso di oggetti gestiti in pool, come le connessioni, ogni oggetto
rappresentante una connessione mantiene informazioni sul suo stato, come
ad esempio username e password, stringa di connessione, ecc., ma poiché
lo stato è uguale per tutti gli oggetti del pool, allora lo stato
degli oggetti è per noi un aspetto assolutamente irrilevante, come
se questi oggetti fossero istanze di classi che non hanno attributi, ma
solo metodi. Ora, ciò significa che se noi forniamo un modo per
creare n oggetti di volta in volta identici, ma il cui stato può
essere da noi stabilito al momento della creazione del pool, allora stiamo
implementando un pool di oggetti riusabili!
Vediamo
lesempio che segue.
public
class PoolableObject{
//variabili
istanza della classe
private
Object attributo1 = "";
private
int attributo2 = "";
private
boolean locked = false;
//
inseriamo un attributo che ci verrà utile
//
la prossima volta!!
private
long millis = 0;
/**
*
Costruttore: inizializza l'oggetto.<br>
*/
public
PoolableObject(Object obj, int n)
{
attributo1 = obj;
attributo2 = n;
locked = false;
}
/**
*
imposta il flag di controllo: serve per simulare
un lock sull'oggetto.<br>
*/
public
void setLock(boolean b)
{
locked = b;
}
/**
*
ottiene lo stato del lock, per vedere
se si può usare l'oggetto.<br>
*/
public
boolean getLock(){
return locked;
}
/**
*
chiude e/o distrugge loggetto.<br>
*/
public
void closePoolableObject(){
///istruzioni per chiudere e/o distruggere questo oggetto
}
}
La
classe appena descritta rappresenta un contenitore di attributi e metodi
per loggetto che noi vogliamo effettivamente mettere nel pool. Ad esempio,
se fosse un pool di connessioni, attributo1 sarebbe un oggetto Connection
e non un Object, e gli altri attributi sarebbero quelli necessari alla
istanza di una connesisone con una base dati(username, password, stringa
di connessione, ecc). Usando questa tecnica, è possibile memorizzare
insieme alloggetto principale (la connessione) tutti gli attributi per
tenere traccia della vita di questo oggetto (esempio: dopo essere stato
usato, è stato rimesso al suo posto? E se non lo è stato,
da quanto tempo è in uso?). Tutto ciò diverrà molto
più chiaro con gli esempi concreti.
Ora,
ciò che ci serve è una classe che faccia da gestore per gli
oggetti del nostro pool, ovvero che rappresenti il pool stesso!
public
class PoolOfPoolableObject
{
//definisco
le variabili istanza
private
java.util.Vector pool = null;
private
int poolSize = 0;
private
Object attribute1 = null;
private
int attribute2 = 0;
/**
*
Il costruttore inizializza la dimensione del Pool.<br>
*/
public
PoolOfPoolableObject(int poolSize){
this.poolSize = poolSize;
}
.............
Dopo
il costruttore, sarebbe il caso di scrivere dei metodi accessori che valorizzino
e leggano gli attributi di PoolableObject. Comunque il codice completo
è disponibile negli esempi allegati
Concentriamoci
ora sul momento in cui il pool viene effettivamente creato:
/**
*
Questo metodo crea di fatto il pool, inseremdo delle istanze<br>
*
dell'oggetto in un vettore di dimensioni iniziali poolSize.<br>
*/
public
synchronized void createPool(){
if(pool == null){
pool = new java.util.Vector(poolSize);
}
for (int i=0;i < poolSize; i++){
PoolableObject po = new PoolableObject(attribute1, attribute2);
pool.add(i,po);
}
}
Vorrei
evidenziare la semplicità insita in questo approccio: lunica cosa
che ci serve è un vettore! Semplice da gestire, flessibile, leggero.
Tutte le informazioni utili sono contenute negli oggetti PoolableObject.
In questa maniera, il pool fa semplicemente...il pool: gestisce la distribuzione
delle risorse e lallocazione della memoria in modo da soddisfare le nostre
esigenze, e non deve preoccuparsi di mantenere alcuna informazione sullo
stato degli oggetti del pool. Il vettore rappresenta il pool vero e proprio:
tutti i metodi di questa classe servono solo alla sua gestione!
NOTA:
sarebbe anche possibile scrivere PoolOfPoolableObjects come classe astratta,
con alcuni dei suoi metodi solamente firmati, senza corpo. Questo permetterebbe
di usare la classe come una pietra angolare per i vostri pool, che non
dovrebbero far altro se non estenderla, e ridefinire i metodi nella maniera
appropriata.
Dopo
aver creato il pool è necessario fornire un sistema con cui la nostra
applicazione possa ottenere un oggetto quando ne ha bisogno.
/**
*
Il
metodo estrae dal pool il primo oggetto non in uso, impostando il suo lock.<br>
*/
public
synchronized PoolableObject getFromPool(){
PoolableObject po = null;
for (int i = 0; i< pool.size(); i++){
po = (PoolableObject)pool.elementAt(i);
if(!po.getLock()){
po.setLock(true);
break;
}
}
return po;
}
Poi,
una volta terminato luso da parte dellapplicazione, dobbiamo provvedere
un sistema robusto attraverso il quale essa possa rilasciare gli oggetti
al pool quando ha finito di usarli, in modo da renderli nuovamente disponibili.
/**
*
Il metodo rilascia l'oggetto in uso rimettendolo nel pool
*
a disposizione, impostando il suo lock a false.<br>
*/
public
void releaseObject(PoolableObject po){
for (int i = 0; i< pool.size(); i++){
if(po == (PoolableObject)pool.elementAt(i)){
po.setLock(false);
break;
}
}
}
Ritengo
sia necessario soffermarci in maniera un po più diffusa su cosa
fanno e come funzionano questi due metodi, che sono il cuore della gestione
del pool, e sono anche particolarmente critici (soprattutto il secondo).
Il punto critico si trova, secondo me, nellapplicazione client, e consiste
nel pericolo che una risorsa del pool si trovi nella condizione di non
poter più essere rilasciata. Una tale situazione potrebbe verificarsi
in seguito a due diversi accadimenti:
-
In fase
di runtime, uneccezione mal gestita provoca un blocco del codice senza
che sia previsto il rilascio delloggetto al pool.
-
In fase
di scrittura del codice viene commesso dal programmatore un errore dovuto
alla inconsapevolezza di alcuni meccanismi.
Riguardo
al primo caso, supponiamo che venga scritto un blocco try/catch contenente
diverse istruzioni delle quali non ci interessa la natura, ma solo che
possono sollevare uneccezione:
try{
//
istruzioni .....
//ottengo
logetto dal pool
PoolableObject po = pool.getFromPool();
//istruzioni
.....
//istruzioni
.....
//rilascio loggetto al pool
pool.releaseObject(po);
}
catch(Exception
e){
//gestisco
leccezione
}
Ora,
è facile notare come, se nel blocco di codice tra getFromPool e
releaseObject si verifica una eccezione qualsiasi, releaseObject non verrà
mai eseguito. Ovvero non ci sarà più occasione, durante la
vita dellapplicazione, di rilasciare loggetto cui fa riferimento po.
Questo perché tale oggetto, non essendo stato rimesso in stato di
libero con la chiamata a setLock(false), non verrà mai più
rilasciato a nessun thread che ne faccia richiesta! Inoltre, è facile
che si verifichino comunque degli errori nellapplicazione.
È
anche facile, tuttavia, evitare questo problema, attraverso una corretta
gestione delle eccezioni. Bisogna chiedersi qual è il punto migliore
nel flusso del codice per rilasciare loggetto. Trattandosi di un blocco
try/catch, e dovendo noi in ogni caso invocare pool.releaseObject(po),
il posto migliore è senza dubbio allinterno di una clausola finally.
try{
//
istruzioni .....
//ottengo
logetto dal pool
PoolableObject po = pool.getFromPool();
//istruzioni
.....
//istruzioni
.....
}
catch(Exception
e){
//gestisco
leccezione
}
finally{
//rilascio
loggetto al pool
pool.releaseObject(po);
}
Noterete
che parlando delloggetto del pool, ho detto che po è il riferimento
della nostra applicazione a quelloggetto. Questo perché getFromPool
restituisce una copia del riferimento alloggetto (reference), e non una
copia delloggetto stesso. Vorrei sottolineare che questo è il modo
di lavorare di Java. Una volta creato un oggetto x, scrivere y = x significa
che y è un nuovo riferimento a quelloggetto, e non una sua copia
(è ovviamente possibile fare anche delle copie degli oggetti, ma
questo aspetto esula per adesso dallargomento, per cui non verrà
trattato).
Premesso
tutto ciò, arriviamo al secondo caso in cui un oggetto può
rimanere appeso senza la possibilità di ritornare libero. Se per
qualsiasi motivo noi dovessimo cambiare il puntamento del nostro reference,
il metodo releaseObject non sarebbe più in grado di invocare setLock(false)
sulloggetto PoolableObject che avevamo ottenuto in precedenza da getFromPool.
Vediamo in pratica:
PoolabledObject
po = pool.getFromPool();
.....
.....
//ottengo
un oggetto di tipo PoolableObject po2
......
po
= po2;
//rilascio
loggetto che avevo ottenuto dal pool
pool.releaseObject(po);
quando
viene invocato releaseObject, il reference di po è cambiato, e non
è più quello alloggetto PoolableObject ottenuto da getFromPool.
Quindi, il ciclo dentro al metodo releaseObject terminerà senza
che il lock delloggetto originale venga riportato in stato di libero.
Quelloggetto non potrà più essere ceduto ad alcun thread,
ma resterà inutilizzato nel pool.
Quindi,
è opportuno fare molta attenzione a come si usano questi meccanismi,
perché le conseguenze sono semplicemente imprevedibili. Inoltre
non esistono tecniche specifiche ed eleganti per ovviare a priori alla
nascita di tali inconvenienti! Lunico sistema è quello di usare
un time-out, cioè di creare uno o più thread il cui unico
compito è quello di monitorare da quanto tempo un oggetto si trova
in stato di blocco, e se è il caso di forzarne il rilascio. Questa
tecnica (piuttosto rozza, ma senza alternative, almeno per ora) sarà
esaminata nel prossimo articolo. Possiamo dire, quindi, che il metodo releaseObject
visto in precedenza non è assolutamente da considerarsi valido dal
punto di vista pratico, e il mese prossimo avrete modo di notare come questo
metodo, inserito in un esempio concreto, sarà abbastanza cambiato!
Dopo
aver provveduto un sistema di accesso al pool (prelevo un oggetto) ed un
sistema di uscita (restituisco loggetto), manca solo da considerare che
la vita del pool non è infinita, ma è pari a quella dellapplicazione
che ne fa uso. Tuttavia, bisogna prevedere un modo per ripulire esplicitamente
tutti gli oggetti allocati dal pool.
/**
*
Il metodo rilascia gli oggetti del pool<br>
*
distruggendo poi il pool stesso.<br>
*/
public
synchronized void destroyPool(){
for (int i = 0; i< pool.size(); i++){
PoolableObject po = (PoolableObject)pool.elementAt(i);
po.closePoolabelObject();
}
pool = null;
System.runFinalization();
}
}
Anche
questo metodo è un po diverso nelluso pratico: dovrebbe prevedere
un sistema per ripulire il pool avendo cura di controllare che degli oggetti
non siano ancora in uso da parte di qualche thread, per evitare di provocare
errori nelle applicazioni client.
Dal
punto di vista grafico, il nostro pool si potrebbe rappresentare con la
figura che segue:
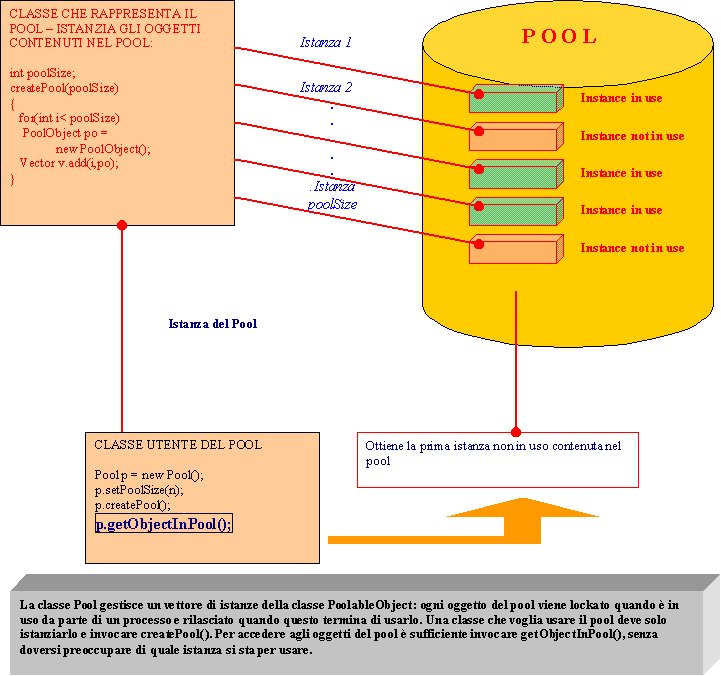
(clicca
per ingrandire)
Allinizio
della nostra dissertazione si diceva che uno dei punti fondamentali da
tenere sotto controllo è quello della sincronizzazione dellaccesso
alle variabili istanza dei vari oggetti nel pool. Ipotizzate di avere creato
un pool nellinit() di una servlet. Ogni volta che il metodo service()
della vostra servlet viene invocato (cioè ogni volta che arriva
una richiesta) viene generato ed avviato un nuovo thread con il compito
di gestire la richiesta (a meno che la servlet non implementi SingleThreadModel,
nel qual caso però il pool di connessioni è inutile, come
vedremo nel prossimo articolo). Quando questo thread richiede una risorsa
del pool, deve invocare un metodo sulloggetto pool, e questo metodo deve
essere controllato da un monitor sulloggetto, cioè deve rispettare
la precedenza di altri thread che sono in fila per modificare o leggere
le variabili istanza (ad esempio il boolean lock), e non tentare laccesso
in concorrenza di altri thread. Potrebbe sembrare un aspetto di secondaria
importanza
ma non è così. Un errore nel valutare limpatto
sullapplicazione di aspetti così semplici eppure tanto strategici
e critici avrà conseguenze disastrose.
Gli
oggetti nel pool sono gestiti dal pool stesso, per cui sarà sufficiente
provvedere un robusto meccanismo di sincronizzazione nella classe che gestisce
il pool! In particolare, un pool di oggetti viene creato quando si vuole
consentire a più processi (thread o anche diverse applicazioni)
laccesso contemporaneo alle sue risorse! Questo aspetto è fondamentale.
Se
abbiamo ad esempio un oggetto Connection, e abbiamo studiato larchitettura
della nostra applicazione in modo tale che luso di quelloggetto sia sempre
sequenziale, cioè che non esista la possibilità da parte
di più di un processo di usarlo nello stesso momento, è evidente
che istanziare un pool sarebbe assolutamente inutile! Esiste un solo oggetto,
e viene usato da un thread per volta (quello che succede se una servlet
implementa SingleThreadModel, appunto). Ma, se i processi che vogliono
connettersi alla base di dati possono essere più di uno nello stesso
istante, allora noi dobbiamo fare in modo che essi ottengano dal pool
n
connessioni contemporaneamente. Tuttavia, se è vero che gli oggetti
del pool sono n, è anche vero che il pool è uno solo!! Quindi,
lavverbio contemporaneamente non descrive esattamente quello che avviene.
Ci
sono due aspetti distinti: il primo è che più processi possono
usare oggetti del pool senza curarsi del fatto che altri processi stiano
anchessi usando degli oggetti dello stesso pool. Quindi, ad esempio, le
connessioni alla base dati possono sovrapporsi. Il secondo è che
il pool preleva e gestisce comunque un solo oggetto per volta. Quindi,
luso degli oggetti del pool può avvenire in contemporanea da parte
di più processi, ma il pool consente ad un solo processo per volta
di ottenere un oggetto. La figura che segue dovrebbe essere esplicativa:
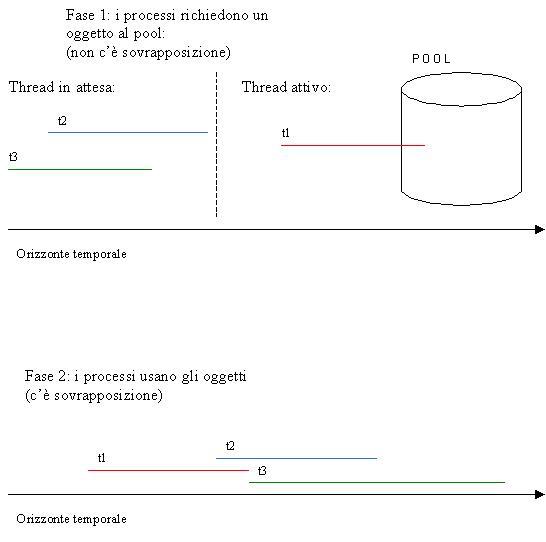
Ora
non resta che chiederci un paio di cosucce non proprio marginali:
-
Come possiamo
evitare che, in caso di errore, un oggetto rimanga appeso per tutta la
sua esistenza? (ne abbiamo già accennato).
-
Se il
pool contiene n oggetti, che risposta daremo alln+1esimo processo che
richiede un oggetto quando i primi n sono già occupati? Dovrà
aspettare che se ne liberi uno? Oppure faremo in modo di creare una nuova
istanza on the fly (al volo, giuro che si dice proprio così)?
E in questultimo caso, quante ne potremo creare? E cosa dobbiamo fare
delle istanze in più che abbiamo creato dopo che queste sono state
usate e il livello di utilizzo del pool è tornato a livelli normali?
Queste
domande, e forse anche alcune altre, non rimarranno senza risposta, ma
intanto potete cominciare a pensarci!
Nella
prossima puntata presenterò un esempio completo di pool di Connessioni
a basi di dati nellambito di unapplicazione web, e un piccolo esempio
di thread pooling (piccolo, perché il thread pooling è un
argomento di straordinaria complessità).
|


